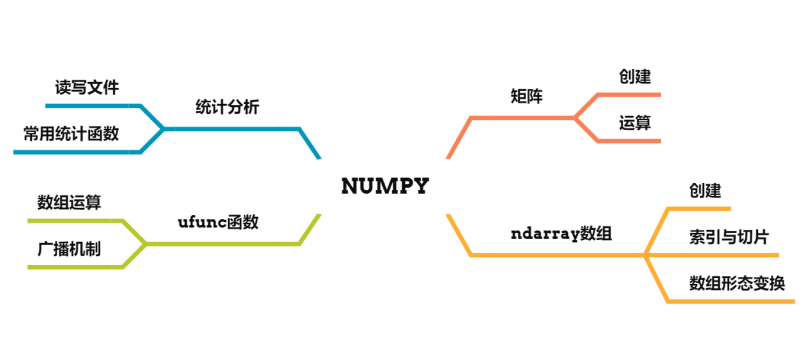
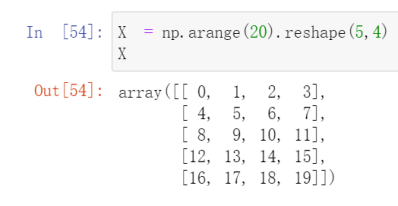
NumPy(Numerical Python)是一个高性能科学计算和数据分析的基础包。
便捷:对于同样的数值计算任务,使用NumPy要比直接编写Python代码便捷得多。
高效:NumPy的大部分代码都是用C语言写成的,这使得NumPy比纯Python代码高效得多。
NumPy的引用:import numpy as np(虽然别名可以自己命名,但是强烈建议使用约定的别名np)
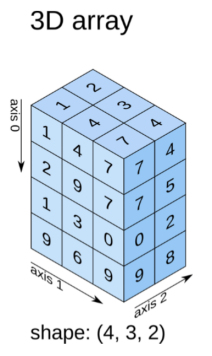
NumPy数组对象ndarray
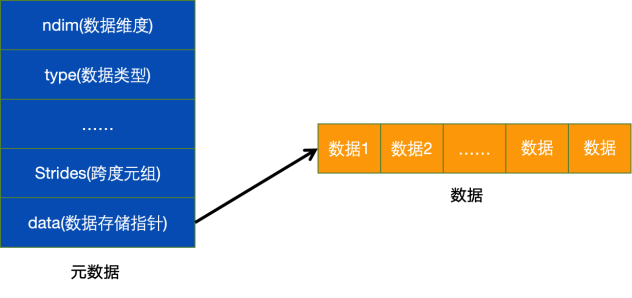
ndarray概述
ndarray是存储单一数据类型的多维数组,由两部分构成:
1.实际的数据2. 描述这些数据的元数据(数据维度、数据类型等)
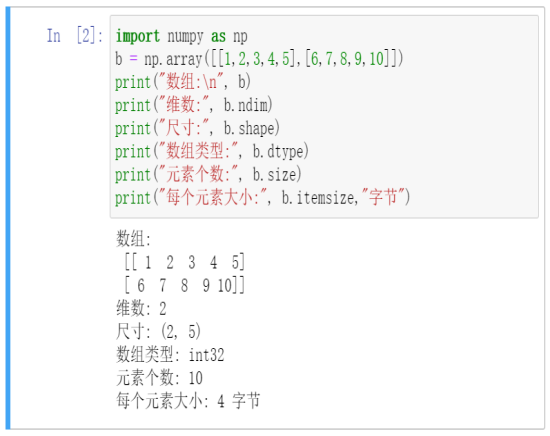
ndarray数组属性
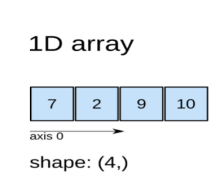
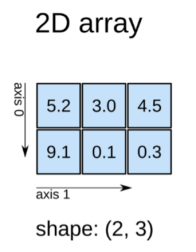
ndim:维数
shape:尺寸
dtype:数据类型
size:元素个数
Itemsize:元素大小
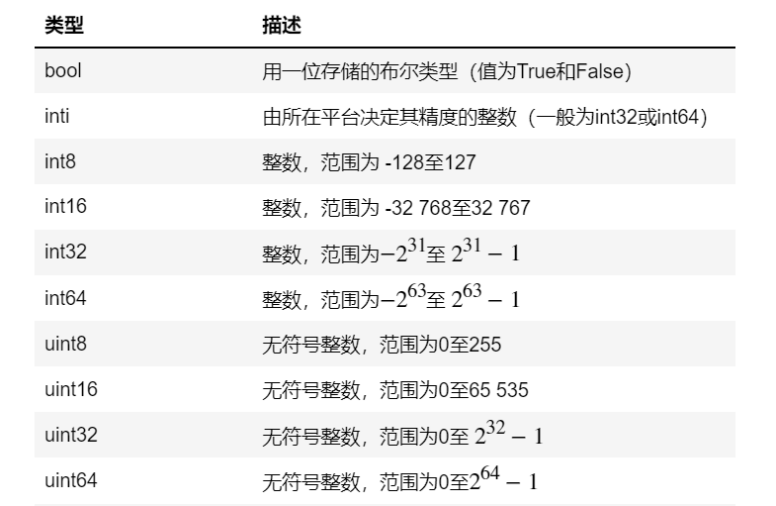
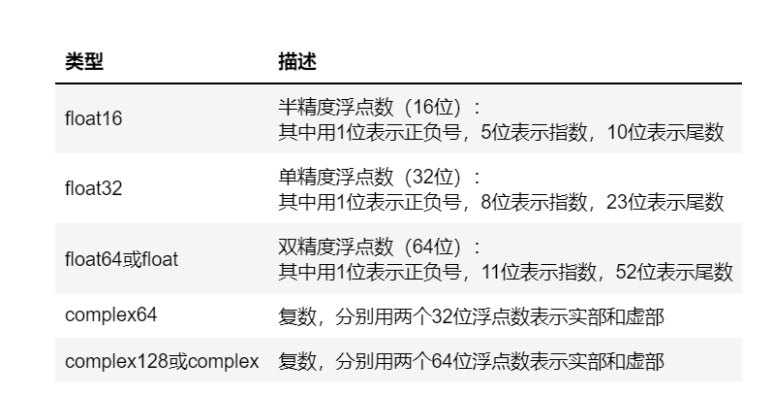
ndarray的数据类型
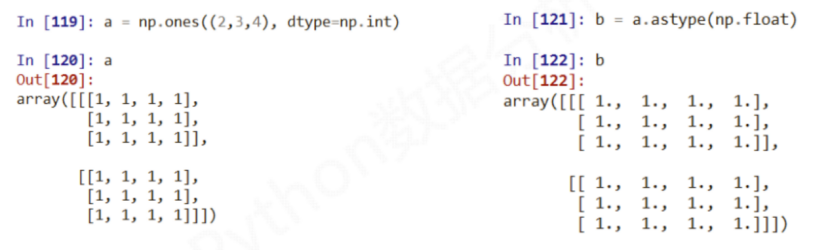
ndarray数组的类型转换:new_a = a.astype(new_type)
创建ndarry数组
1.使用array函数来创建数组
a = np.array((1,2,3))
b = np.array([[1,2,3],[4,5,6]])
2.使用内置函数创建数组
arange:通过指定开始值、终值和步长来创建一维数组
a = np.arange (0,2,0.5)
0.0.51.1.5
linspace:通过指定开始值、终值和元素个数来创建一维数组
a = np.linspace (0, 3, 4)
0.1.2.3.
logspace:构建等比数组
a = np.logspace (0,2,3)
010100
zeros:创建一个用指定形状用0填充的数组
a = np.zeros ((2, 3))
0.0.0.
0.0.0.
eye:创建一个主对角线为1,其它为0的数组
a = np.eye (2,3)
1.0.0.
0.1.0.
diag:创建一个除对角线全为0的数组
a = np.diag ([1,2, 3])
1.0.0.
0.2.0.
0.0.3.
ones:创建一个用指定形状用1填充的数组
a = np.ones ((2,3))
1.1.1.
1.1.1.
3.通过生成随机数的np.random模块构建
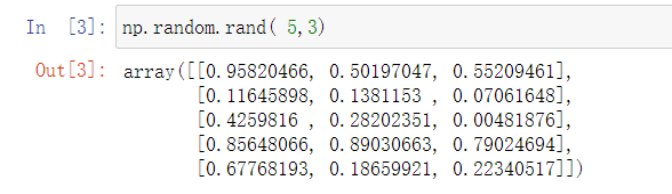
rand:生成均匀分布的随机数数组
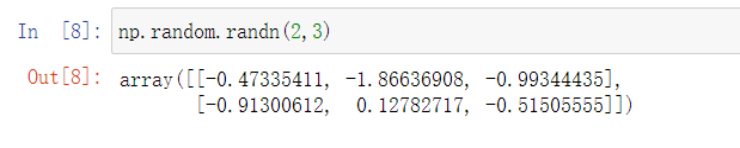
randn:生成一个符合标准正态分布的数组(均值0,方差1)
randint:生成一个给定上下限范围的随机数数组
random模块常用随机数生成函数
其中,函数shuffle与permutation都可以打乱数组元素顺序,区别在于:
shuffle:直接在原来的数组上进行操作;
permutation:不直接在原来的数组上操作,会返回一个新的打乱顺序的数组。
【例】
import numpy as np
x = np.array([1,2,3,4,5,6,7,8,9])
y = np.random.permutation(x) # x的数据不动,把随机打乱后的数据返给y
np.shuffle(x) # 直接随机打乱数组x的数据
索引与切片
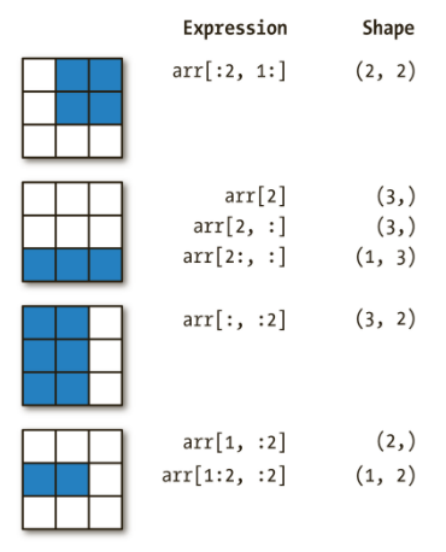
1.基础索引
一维数组的索引与Python的列表索引功能一致
多维数组的索引:多维数组每一个维度有一个索引,各个维度之间用逗号隔开
üarr[r1:r2, c1:c2]
üarr[1,1] 等价 arr[1][1]
ü[:] 代表某个维度的数据
2.整数序列索引
利用整数数组进行索引
3.布尔索引
布尔值多维数组arr[condition],condition可以是多个条件组合
注意,多个条件组合要使用& |,而不是and or
变换数组形态
改变数组形状
1. reshape(shape, order='C'):在不改变数据的情况下为数组赋予新的形状
2. resize(shape):改变自身数组的形态
reshape(shape)不改变数组元素,返回一个shape形状的数组,原数组不变
resize(shape)与.reshape()功能一致,但修改原数组
数组展平
numpy中的ravel()、flatten()都有将多维数组转换为一维数组的功能
reshape(-1)也可以“拉平”多维数组
当指定order=‘F’表示纵向展开
ravel():如果没有必要,不会产生源数据的副本
flatten():返回源数据的副本
数组组合
1. hstack:数组横向组合
该函数相当于沿第一个轴连接(axis=1),除了一维数组的组合可以是不同长度外,其它数组组合时,除了第二个轴的长度可以不同外,其它轴的长度必须相同。
2. vstack:数组纵向组合
该函数相当于沿第一个轴连接(axis=0),除了一维数组的组合可以是不同长度外,其它数组组合时,除了第二个轴的长度可以不同外,其它轴的长度必须相同。
3. concatenate((tup),axis)实现数组的横向组合和纵向组合
axis = 1时,等同于 np.hstack
axis = 0时,等用于 np.vstack
数组分割
1. hsplit将数组横向分割成大小相同的子数组
2. vsplit将数组纵向分割成大小相同的子数组
NumPy矩阵与通用函数
创建与组合矩阵
调用mat函数、或matrix函数创建矩阵是等价的。如:
(1)使用mat函数创建矩阵:
matr1 = np.mat("1 2 3;4 5 6;7 8 9")
或matr1 = np.mat([[1,2,3],[4,5,6],[7,8,9]])
(2)使用matrix函数创建矩阵:
matr2 = np.matrix([[1,2,3],[4,5,6],[7,8,9]])
或matr2 = np.matrix("1 2 3;4 5 6;7 8 9")
(3)使用bmat函数合成矩阵:
np.bmat("matr1 matr2; matr1 matr2")
或np.bmat("matr1 matr2")
矩阵的运算
²矩阵与数相乘:matr1*3
²矩阵相加减:matr1±matr2
²矩阵对应元素相乘:matr1*matr2或np.multiply(matr1,matr2)
²矩阵乘法(点积运算):np.dot(mat1, mat2)或mat1 @ mat2
注:其运算机制相当于两个矩阵的乘法运算,第1个数组的列数必需等于第2个数组的行数。
²矩阵特有属性:
线性代数运算
(1)求方阵的逆矩阵:np.linalg.inv(A)
(2)求广义逆矩阵:np.linalg.pinv(A)
(3)求矩阵的行列式:np.linalg.det(A)
(4)求矩阵的特征值:np.linalg.eigvals(A)
(5)求特征值和特征向量:np.linalg.eig(A)
(6)svd分解(矩阵的奇异值分解):np.linalg.svd(A)
(7)求数组x的范数:np.linalg.norm(x, ord=None, axis=None, keepdims=False)
【例】
x = np.array([3, 4])
np.linalg.norm(x) # 向量x的范数(默认为2),输出 5
np.linalg.norm(x, ord=2) # 向量x的2范数,输出 5
np.linalg.norm(x, ord=1) # 向量x的2范数,输出 7
np.linalg.norm(x, ord=np.inf) # 向量x的无穷大范数,输出 4
ufunc函数:全称通用函数(universal function object),是一种能够对数组中所有元素进行操作的函数。
Ø四则运算:加(+)、减(-)、乘(*)、除(/)、幂(**)。数组间的四则运算表示对每个数组中的元素分别进行四则运算,所以形状必须相同。
Ø比较运算:>、<、==、>=、<=、!=。比较运算返回的结果是一个布尔数组,每个元素为每个数组对应元素的比较结果。
Ø逻辑运算:np.any函数表示逻辑“or”,np.all函数表示逻辑“and”。运算结果返回布尔值。
常用的通用函数
ceil(),向上最接近的整数
floor(),向下最接近的整数
rint(),四舍五入
isnan(),判断元素是否为 NaN(Not a Number)
multiply(),元素相乘,等同于数组的* 操作(注意,不是矩阵的乘法操作)
divide(),元素相除,等同于数组的 / 操作
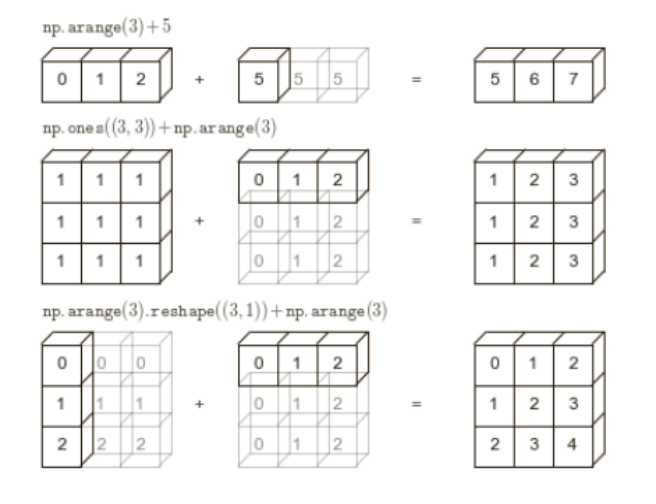
广播机制
广播(broadcasting)是指不同形状的数组之间执行算术运算的方式。需要遵循4个原则:
1.让所有输入数组都向其中shape最长的数组看齐,shape中不足的部分都通过在前面加1补齐。
2.输出数组的shape是输入数组shape的各个轴上的最大值。
3.如果输入数组的某个轴和输出数组的对应轴的长度相同或者其长度为1时,这个数组能够用来计算,否则出错。
4.当输入数组的某个轴的长度为1时,沿着此轴运算时都用此轴上的第一组值。
列表、矩阵、数组之间的转换
(1)将列表转为数组、矩阵:np.array(list)、np.mat(list)
import numpy as np
list1 =[[1,2,3],[4,5,6]] # 列表
list1 # [[1, 2, 3], [4, 5, 6]]
arr2 = np.array(list1) # 列表 -----> 数组
arr2 # array([[1, 2, 3],[4, 5, 6]])
mat3 = np.mat(list1) # 列表 ----> 矩阵
mat3 # matrix([[1, 2, 3],[4, 5, 6]])
(2)将矩阵、数组转为列表:矩阵变量.tolist()、数组变量.tolist()
list2 = mat3.tolist() # 矩阵 ---> 列表
list2 # [[1, 2, 3], [4, 5, 6]]
list2 == list1 # 输出:True
list3 = list(arr2) # 数组 ---> 列表
list3 # [array([1, 2, 3]), array([4, 5, 6])]
list4 = arr2.tolist()# 数组 ---> 列表,内部数组也转换成列表
list4 # [[1, 2, 3], [4, 5, 6]]
arr3 = np.array(mat3) # 矩阵 ---> 数组
arr3 # array([[1, 2, 3], [4, 5, 6]])
mat5 = np.mat(arr2) # 数组 ---> 矩阵
mat5 # matrix([[1, 2, 3], [4, 5, 6]])
(3)在一维情况下,矩阵---> 数组---> 矩阵结果不同
a1 =[1,2,3,4,5,6] # 列表:[1, 2, 3, 4, 5, 6]
a3 = np.mat(a1) # 列表 --> 矩阵: matrix([[1, 2, 3, 4, 5, 6]])
a4 = a3.tolist() # 矩阵 -> 列表(一个元素的列表):[[1, 2, 3, 4, 5, 6]]
(4)在一维情况下,列表---> 矩阵 ---> 列表结果不同
a4[0] # [1, 2, 3, 4, 5, 6]
a5 = np.mat(np.array(a1)) # 数组 ---> 矩阵 :matrix([[1, 2, 3, 4, 5, 6]])
a6 = np.array(a5) # 矩阵 ---> 数组
a6 # array([[1, 2, 3, 4, 5, 6]])
利用NumPy进行统计分析
读写文件(略)
NumPy文件读写主要有二进制的文件读写和文件列表形式的数据读写两种形式
(1)用load()、save()读写*.npy或 *.npz 文件。这是Numpy数组专用的二进制文件,其中npz(NumPy Zipped Data)属于NumPy数据压缩文件。
(2)用loadtxt()、savetxt()读写*.txt或 *.csv 文本文件。其中*.csv是一种通过逗号分隔的文本文件。函数 genfromtxt() 和函数 loadtxt() 相似,区别在于它面向的是结构化数组和缺失数据。
另外,Numpy本身不能读写Excel文件,需要用xlrd 第三方库。基本思路:
(1)打开文件,返回workbook对象;
(2)通过索引号,或sheet名称,获得sheet;
(3)操作sheet下的列、行,获取行、列数据,返回给列表,然后对列表进行切片操作,获得所需要的数据。
排序
直接排序
sort函数是最常用的排序方法。arr.sort()
sort函数也可以指定一个axis参数,使得sort函数可以沿着指定轴对数据集进行排序。axis=1为沿横轴排序;axis=0为沿纵轴排序。
间接排序
argsort函数返回值为重新排序值的下标。arr.argsort()
lexsort函数返回值是按照最后一个传入数据排序的。
np.lexsort((a,b,c))返回排序后序号,顺序c,b,a
【例】
import numpy as np
arr = np.array([[8, -2, 3, 1],[2, 5, 0, 7], [7, 4, 9, 6]])
A = arr.argsort() # 排序后这个位置的元素原来的位置索引
在数组中插入一行(或一列)
(1)在数组a_array的第row_m行前,插入一行,其值为b_array
语法:np.insert(a_array,row_m,values=b_array,axis=0)
(2)在数组a_array的第col_m列前,插入一列,其值为b_array
语法:np.insert(a_array, col_m, values=b_array, axis=1)
去重与重复数据
去重:
通过unique函数可以找出数组中的唯一值并返回已排序的结果。
重复:
1.对数组进行重复操作:np.tile(a,reps)
tile函数主要有两个参数,参数“a”指定重复的数组,参数“reps”指定重复的次数。
2.对数组中的每个元素进行重复操作:np.repeat(a, repeats, axis=None)
repeat函数主要有三个参数,参数“a”是需要重复的数组元素,参数“repeats”是重复次数,参数“axis”指定沿着哪个轴进行重复,axis = 0表示按行进行元素重复;axis = 1表示按列进行元素重复。
常用的统计方法
求均值:np.mean()
求和:np.sum()
求最大:np.max()
求最小:np.min()
求标准差:np.std()
求方差:np.var()
求最大值的索引:np.argmax()
求最小值的索引:np.argmin()
求累加:np.cumsum()
求累乘:np.cumprod()
是否所有元素满足条件:np.all()
是否至少一个元素满足条件:np.any()
注意:
•默认是全部维度上做统计
•多维数组要指定统计的维度