Python必知必会:Pandas 方法链详解——构建流畅的数据管道!
- 2026-06-29 16:32:24

Pandas 是一个开源的 Python 库,为当今大量的数据加载、清洗、处理和分析提供了支持。它入门简单,但初学者编写的代码虽然能运行,却感觉“笨拙”。我指的是代码中充斥着临时变量、重复步骤和难以理解的转换。提升代码水平最有效的方法之一是掌握方法链 ,从循序渐进的修改方式转变为流畅、富有表现力的管道式操作。
本文将带你了解让 pandas 代码流畅而非支离破碎的核心技巧。你将看到 .pipe() 模式如何让您直接将自定义函数插入到链式调用中而不会中断代码流程——这对于保持复杂逻辑的可读性和模块化至关重要。
你还将学习一些链式调用的最佳实践,例如如何将管道结构化为每行一个方法,如何决定何时使用内联 lambda 表达式,何时使用命名辅助函数,以及如何识别哪些方法自然而然地适合放入链中。而且,由于 pandas 只有在实际应用中才能真正“领悟”,我们将通过实际案例来讲解:使用富有表现力的自上而下的管道来过滤、重塑和清理杂乱的数据集,你可以复制、修改并在此基础上进行扩展。
本文假设你已经具备一些关于 Python 和 pandas 的基本知识。
1. 传统 Pandas 风格的问题
在探讨链式调用之前,让我们先来了解一下典型的初学者工作流程。
在这种情况下,我们将加载销售数据的 CSV 文件,创建一个筛选到“西部”地区的 DataFrame (df),添加一个“收入”新列,按类别对收入求和,并按收入对 DataFrame 进行排序。
这是 CSV 文件:
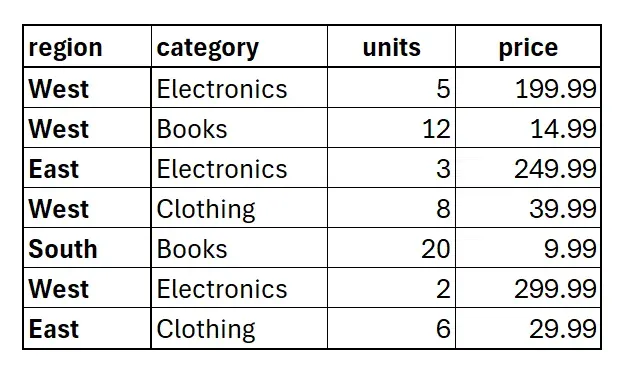
以下是“传统”代码:
import pandas as pddf = pd.read_csv("sales.csv")df = df[df["region"] == "West"]df["revenue"] = df["units"] * df["price"]df = df.groupby("category", as_index=False)["revenue"].sum()df = df.sort_values("revenue", ascending=False)df = df.reset_index(drop=True)df.head()以下是输出结果:
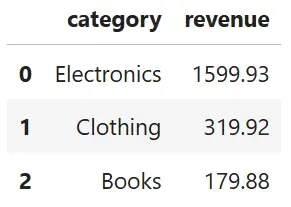
虽然这段代码可以运行,但它存在一些缺点:
df2. 流畅思维:方法链
方法链的核心思想在于,pandas 中返回 DataFrame 的方法可以堆叠成易于理解的管道 。以下两节将分别介绍使用 lambda 函数和使用辅助函数的方法。实际上,你可以在同一个管道中混合使用这两种方法。
2.1 Lambda 方法
我们用方法链式调用重写前面的例子:
( pd.read_csv("sales.csv") .query("region == 'West'") .assign(revenue=lambda d: d["units"] * d["price"]) .groupby("category", as_index=False)["revenue"].sum() .sort_values("revenue", ascending=False) .reset_index(drop=True))这样会得到同样的结果。
然而,使用链式方法,优点如下:
2.2 辅助函数方法
之前的链式方法仍有改进空间。按照目前的写法,逻辑被埋没在 lambda 函数内部。我们不妨将其提升到可重用的辅助函数中:
def compute_revenue(df): return df.assign(revenue=df["units"] * df["price"])def top_by_revenue(df): return df.sort_values("revenue", ascending=False)( pd.read_csv("sales.csv") .query("region == 'West'") .pipe(compute_revenue) .groupby("category", as_index=False)["revenue"].sum() .pipe(top_by_revenue) .reset_index(drop=True))这样一来,整个流程读起来就像一个故事,同时又能产生相同的结果。虽然我们需要编写更多代码,但 .pipe() 通过将 DataFrame 作为第一个参数传递给函数来保持流程的简洁性,因此您可以将其直接融入到流程中,而不会破坏垂直的节奏。
每个辅助函数都可以单独进行测试,这有助于代码模块化。如果需要重复执行某个操作,它们也可以重用。
一般来说,嵌入式 lambda 函数非常适合处理简短、直观、仅使用一次且能自然融入流程链的情况。而辅助函数加上 .pipe() 则非常适合处理概念性、可重用或多步骤的操作。
所谓概念性任务,指的是诸如计算收入、筛选前 N 个结果或清理列名之类的任务。此外,当逻辑过于复杂,无法用 lambda 表达式实现且又不影响代码可读性时,辅助函数是更佳的选择。它们允许您根据需要“扩展”代码。
2.3 核心链接工具包
虽然 pandas 包含数百种方法,但以下方法是方法链工作流中最常用的方法之一。
.assign()
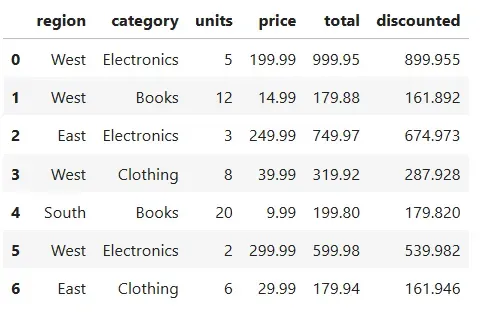
.assign() 方法用于添加或转换列。它可以避免就地改现有数据,并保持逻辑清晰可见。这里,我们生成“总计”和“折扣”列:
df = pd.read_csv("sales.csv") # reload the datasetdf.assign(total=lambda d: d.units * d.price, discounted=lambda d: d.total * 0.9 )以下是添加了新列的 DataFrame:
.query()
.query() 方法允许使用类似白话文的筛选语句。这里,我们筛选出价格超过 12 美元的书籍:
df.query("category == 'Books' and price > 12")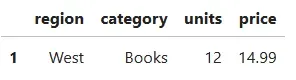
.pipe()
.pipe() 方法允许你通过将自定义函数插入链中来实现自定义逻辑。这里,我们返回收入最高的三行数据:
def top_n(df, n=5): return df.nlargest(n, "revenue")( df .assign(revenue=lambda d: d.units * d.price) .pipe(top_n, n=3))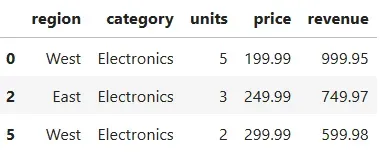
2.4 链式重塑
rename 、 melt 、 pivot_table 和 filter 方法允许链式地重塑 DataFrame。以下示例将列名全部设置为大写:
( df .rename(columns=str.upper))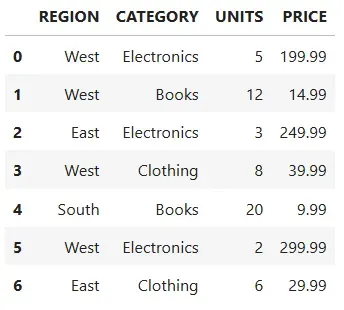
并非所有方法都可以链式调用,有些方法还存在危险的“陷阱”。这些陷阱涉及方法是否会创建新的 DataFrame,以及是否会返回 DataFrame。接下来我们将探讨这些问题。
2.5 应对可变性问题
如果你曾经短暂地使用过 pandas,你可能已经遇到过它最危险的可变性陷阱之一:你以为自己创建的是一个全新的 DataFrame,但实际上你修改的是原来的 DataFrame。这和许多人第一次接触 Python 列表时遇到的情况类似。
这种通常发生在两种场景下:使用支持 inplace=True 参数的方法,或者将值赋给一个恰好是视图而非副本的列。以下是一个无意中修改原始 DataFrame 的经典示例:
df = pd.read_csv("sales.csv") # 加载数据# 你以为你创建的是一个过滤副本west = df[df["region"] == "West"]# ...但你没有意识到你实际上在修改原始的 DataFramewest["revenue"] = west["units"] * west["price"]很容易认为 west 是一个完全独立的 DataFrame,向 west 添加列不会影响 df 。但根据 pandas 内部的视图/副本规则, west 可能是 df 的一个视图,而不是副本。如果是这样,那么这行代码:
west["revenue"] = ...也会修改原始的 DataFrame,哪怕用户再也没有修改过 df。这是 pandas 中最常见的“静默变异”漏洞之一。
注意:视图指的是与原始 pandas DataFrame 或 Series 共享内存的数据子集。对视图所做的更改会影响原始数据,反之亦然。判断某个操作返回的是视图还是副本可能具有不可预测性,并且取决于底层内存布局。
以下是一个未意识到后果而使用 inplace=True 的例子:
df = pd.read_csv("sales.csv")# 你认为你是在独立地转换 df2...df2 = df# ...但实际上这个操作会同时修改 df2 和 df:df2.drop(columns=["price"], inplace=True)与 Python 中许多变量赋值一样,df2 = df 并不会创建副本;相反,它会创建对同一个对象的第二个引用。因此,inplace=True 会修改共享的底层 DataFrame。
避免这种变异问题的一种方法是进行显式复制:
west = df[df["region"] == "West"].copy()west["revenue"] = west["units"] * west["price"]现在,west 是一个独立的 DataFrame。但是请注意嵌套括号的笨拙语法(df[df[“region”])。它既不方便又难以阅读。
幸运的是,链式调用通常可以同时解决原地修改和代码可读性问题。链式调用之所以有效, 是因为这些方法会返回新的 DataFrame。每一步都将一个新的 DataFrame 传递给下一步,从而创建了一个简洁的函数式编程流程。
然而,并非所有方法都适合链式调用。我们将在接下来的章节中探讨这个问题。
2.6 返回新 DataFrame 的方法(可安全链式调用)
链式调用风格返回一个新 DataFrame 的部分核心方法:
.query():返回一个包含符合查询条件的行的新 DataFrame。.assign():专为链式调用而设计;它返回一个添加或修改列的新 DataFrame,同时保留原始 DataFrame。.sort_values():返回一个新的已排序的 DataFrame。.rename()(不带 inplace=True):返回一个带有修改后标签的新 DataFrame。.drop()(不带 inplace=True):返回一个删除了指定行/列的新 DataFrame。.filter():根据标签返回 DataFrame 的新子集。.melt():重塑数据并返回一个新的 DataFrame。.pivot_table():将数据聚合并重塑为一个新的“电子表格样式” 的DataFrame。.groupby(...).agg(...) 或 .sum() 或 .mean():这些聚合方法返回一个新对象(通常是 DataFrame 或 Series),表示简化后的数据。.reset_index():返回一个具有默认整数索引的新 DataFrame。.set_index():返回一个新的 DataFrame,其中以一个或多个列作为索引。.pipe():一个专门用于链式调用的实用工具,它将一个函数应用于 DataFrame 并返回结果(通常是修改后的新 DataFrame)。这些是 pandas 的“函数式”方法——它们从不修改原始数据 ,总是返回一个全新的 DataFrame。这就是链式调用如此高效的原因。
2.7 可能改变原始数据的方法(小心!)
某些 pandas 方法支持 inplace=True 参数。默认情况下,该参数设置为 False。如果将该参数更改为 True,该方法会就地修改原始 DataFrame 并返回 None,这会破坏链式调用。
请注意,其中一些在之前的列表中,但有以下注意事项:(没有 inplace=True )。
例如:
.drop(inplace=True).rename(inplace=True).sort_values(inplace=True).fillna(inplace=True).replace(inplace=True)如果你尝试在这些函数之后进行链式调用,你会收到一个报错,因为链式调用会接收到 None。
如果不使用 inplace=True,这些方法将返回一个新的 DataFrame,并且可以完全链式调用。
2.8 不返回 DataFrame 的方法(不可链式调用)
有些方法返回的不是 DataFrame:
.plot():返回一个 Matplotlib Axes 对象。.to_csv():返回 None 。.describe():返回一个 DataFrame,但通常用作终端步骤。.value_counts():返回一个 Series。.unique():返回一个 NumPy 数组。.isna():返回一个布尔值的 DataFrame(可链式调用,但并没有多大意义)。这些数据不适合进行 DataFrame 到 DataFrame 的管道连接。
2.9 链式调用的经验法则
Pandas 拥有数百个方法,从技术上讲,任何返回 DataFrame 的方法都可以成为链式调用的一部分。以下原则定义了链式调用:
• 如果一个方法返回一个 DataFrame ,那么它就可以链式调用。 • 如果它就地发生变化或返回其他值 ,那就不能进行链式调用。
大多数用于数据清洗和转换的 pandas 方法都会返回新的 DataFrame,因此可以安全地链式调用。如果某个方法提供了 inplace 参数,非必要最好不要将其设置为 True,因为这会破坏链式调用,引入副作用,并且不会带来任何性能提升。
如果一个方法返回的不是 DataFrame,那么它一定位于链的末尾 ,因为它会改变流经管道的对象类型。
3. 方法链小项目
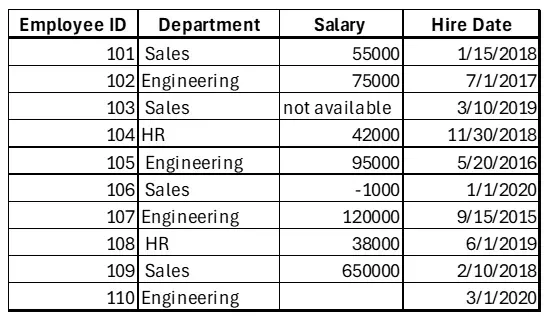
为了强调我们目前所学的内容,让我们使用方法链来修复一个小型且混乱的员工数据集。输入的 CSV 文件存在列名混乱、缺失值、数据类型混杂、冗余空格以及异常值(例如负薪资和远高于其他薪资的薪资)等问题。
文件中的数据如下:
以下是使用方法链实现的清洗代码:
import pandas as pdclean = ( pd.read_csv("employees.csv") # 1. 清洗列名: .rename(columns=lambda c: c.strip().lower().replace(" ", "_")) # 2. 修复数据类型并去除空格: .assign( salary=lambda d: pd.to_numeric(d.salary, errors="coerce"), department=lambda d: d.department.str.strip() ) # 3. 删除薪水为空或无效薪水的行: .dropna(subset=["salary"]) .query("salary > 0") # 4. 移除极端异常值 (薪水 top 1%): .pipe(lambda d: d[d.salary < d.salary.quantile(0.99)]) # 5. 最后对清洗结果重置索引(恢复默认索引): .reset_index(drop=True))clean.head()以下是清洗后的 DataFrame 的前五行:
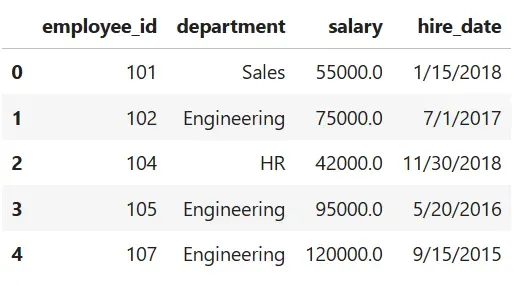
如果我们查看每个步骤,在加载 CSV 文件后,管道使用 .strip() 去除开头/结尾的空格(" Department " → "Department")。然后, .lower() 方法强制统一命名("Employee ID" → "employee id"),而 .replace(" ", "_") 将空格转换为下划线("employee id" → "employee_id")。
你不会看到单独的“列清洗”模块;它只是管道中的第一个过滤器。接下来的步骤现在可以依赖于可预测的列名,例如 employee_id、department 和 salary。
接下来,管道会修复数据类型和空格问题。pd.to_numeric(..., errors="coerce") 行会将 salary 列中看起来像数字的字符串转换为数字。诸如 "not available" 或空白之类的无效值会被转换为 NaN (“非数字”),以避免代码崩溃。在部门列中,.str.strip() 会移除空格(" Sales " → "Sales")。
通过在管道中使用 .assign,我们可以将所有列“修复”逻辑集中在一起,而不是分散在各处。lambda 函数接收 DataFrame d,因此您可以在一个连贯的步骤中应用多个转换。而且,由于这是链式调用,每个 .assign 都会返回一个新的、更简洁的 DataFrame。
下一步是移除缺失值和无效的薪资值。使用 .dropna(subset=["salary"]) 可以移除薪资值为 NaN 行。使用 .query("salary > 0") 可以移除负数或零薪资值( 例如 -1000)。这很好地展示了数据验证如何自然地融入到链式调用中。此外,.query("salary > 0") 读起来几乎像英语一样,比布尔括号更友好。
我们现在使用分位数来移除极端异常值。d.salary.quantile(0.99) 计算薪资的第 99 个百分位数,而 d[d.salary < ...] 只保留低于该阈值的行。这样可以有效地移除像 650000 这样的极端值,同时保留其余值。
虽然这里我们调用了 .pipe() 来处理 lambda 表达式,但为了更清晰、更具可扩展性,你也可以替换为辅助函数:
def remove_salary_outliers(df, q=0.99): cutoff = df.salary.quantile(q) return df[df.salary < cutoff])clean = ( pd.read_csv("employees.csv") .rename(...) .assign(...) .dropna(subset=["salary"]) .query("salary > 0") .pipe(remove_salary_outliers, q=0.99) .reset_index(drop=True))希望你能体会到这条链式调用读起来就像一份食谱:
没有噪声中间数据(df1、df2、df3),只有一个数据流。调整起来也很方便。如果想把分位数从 0.99 改成 0.95, 只需修改一行代码。如果需要禁用异常值移除步骤,也只需注释掉一行代码。
在链式调用的末端,我们并没有对任何对象进行原地修改,也没有将逻辑分散到五个不同的变量中。我们只是对数据进行了一系列简单易读的转换,直到它准备好进行分析。
4. 方法链的缺点
链式调用会在每一步创建新的 DataFrame,从而使流程可预测并避免意外修改。但缺点是需要额外的内存和对象创建。对于大多数工作流程而言,这种清晰度和安全性是值得的,但对于大型数据集或极长的流程,您可能需要打破链式调用或优化特定步骤。
4.1 内存开销
由于链式操作中的每一步都会生成一个新的 DataFrame,因此在 groupby、sort、melt 等操作期间,可能会出现多个中间对象、重复的列块以及临时分配。当你处理以下情况时,这可能会造成问题:
4.2 性能开销
创建新的 DataFrame 会涉及到更多的对象创建、索引重新计算和垃圾回收。实际上,这些开销通常远小于操作本身的成本。但是,如果你要对一个庞大的数据集执行数十个步骤,这些开销才有可能体现出来。在大多数情况下,除非性能至关重要,否则可读性高的流程比性能更重要。
4.3 质量控制
链式调用鼓励“流程化”,但也使得检查中间结果变得更加困难。唯一的选择是中断链式调用或使用 .pipe() 插入调试钩子。这些额外的步骤可能会削弱链式调用本身带来的优势。
4.4 依赖于副作用的转换
对于依赖 副作用 的转换,链式调用并非理想之选。链式调用假定每一步都是纯粹的、确定性的且独立的。如果你的逻辑依赖于修改外部状态、更新共享对象或在流水线中途写入磁盘,那么链式调用可能会变得笨拙且容易产生误导。
4.5 其他问题
链式调用功能强大,但过长的链式调用会变得难以阅读,lambda 表达式会隐藏复杂性,如果链式调用变成代码墙,调试就会变得更加困难。
5. 提高可读性和调试技巧
以下是一些使管道更易读、更易于调试的技巧:
以链式方式重写旧脚本是提高链式编程技巧的好方法(光看不够,你需要实战)。
总结
pandas 中的方法链提供了一种强大的方式,可以编写更简洁、更具表现力且更可靠的数据转换代码。它摒弃了将逻辑分散在临时变量中或直接修改 DataFrame 的做法,鼓励采用函数式编程风格:每一步都接收一个 DataFrame 作为输入,并返回一个经过进一步优化的新版本。这种自上而下的流程与我们思考数据清洗的方式相呼应——读取、过滤、修复、重塑、验证和最终确定。
日常数据工作中常用的绝大多数方法,例如 query、assign、rename、drop、sort_values、reset_index、merge、melt 等等,都会返回新的 DataFrame,并且自然而然地可以链式调用。当一个方法提供 inplace 参数时,将其保留为默认值(inplace=False)可以保持管道的纯净,避免隐藏的副作用,从而提高调试的难度。此外,当转换过程在概念上变得有意义或涉及多个步骤时,.pipe() 提供了一种简洁的方式来引入辅助函数,而不会中断流程。
链式调用不仅仅是一种风格偏好。它能减少意外修改,使中间逻辑更易于理解,并生成可扩展的代码,从简单的 Jupyter Notebook 探索到生产级数据管道都能胜任。尽管每一步都会创建一个新的 DataFrame,但对于大多数实际数据集而言,由此带来的清晰度和可预测性远远超过了这点微小的开销。
然而,链式调用并非万能。当转换过于复杂,无法使用内联 lambda 表达式或简单的辅助函数时,当代码可读性受到影响时,或者当需要重用中间结果时,应避免使用链式调用。
链式调用通过一条清晰易读的管道,将杂乱无章、不一致的数据转化为可供分析的表格。更重要的是,它背后蕴含着一种思维模式:如果一个方法返回的是 DataFrame,那么它就可以沿着链式调用继续执行;如果它就地修改数据或返回其他类型,那么它就应该放在链的末尾——或者完全退出链式调用。 掌握了这一原则,你就可以构建流畅可靠的 pandas 工作流,让它们读起来和写起来一样自然。
Thanks for your reading!
Enjoying coding, my friends! 🧑💻🧑💻🧑💻💯💯💯
推荐阅读👇👇👇
🌟 如果你觉得这篇文章对你有帮助,并且愿意支持我的话,你可以: 🌟
• 👍 点赞,让文章获得系统推荐 • ⤴️ 分享,把内容传递给身边的伙伴 • ❤️ 推荐,让文章影响到更多人 • 👏 欢迎留言交流,一起拓展技术的边界

👇👇👇 Follow me,获取更多高质量干货分享,我们下期再见!
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- Python 的 subprocess 模块:运维脚本的瑞士军刀,比 os.system 强在哪?
- 2025路飞Python全栈开发中级课程
- Python70个练手项目
- Python多线程编程
- GIL 锁是什么?为什么我的 Python 脚本在多核 CPU 上跑不快?
- 【Arduino第七课】【编程核心概念⑩】逻辑运算符:让Arduino“深思熟虑”,处理复杂条件!
- Python并发与 asyncio 1.2 什么是 I/O 密集型,什么是 CPU 密集型?
- 揭秘Python随机实验中的"9.5%魔咒":概率机制的数学解析
- 学习Python第一步 花一周记住这些单词
- 机械工程师进阶提升期第70天:Python 进阶:自动化数据分析(项目成本统计)
