在第 1 章中,我们讨论了在 multiprocessing 中,每个进程都有自己的内存,与其他进程分离。这在我们有共享状态需要跟踪时带来了挑战。那么,如果它们的内存空间各不相同,我们如何在进程之间共享数据?
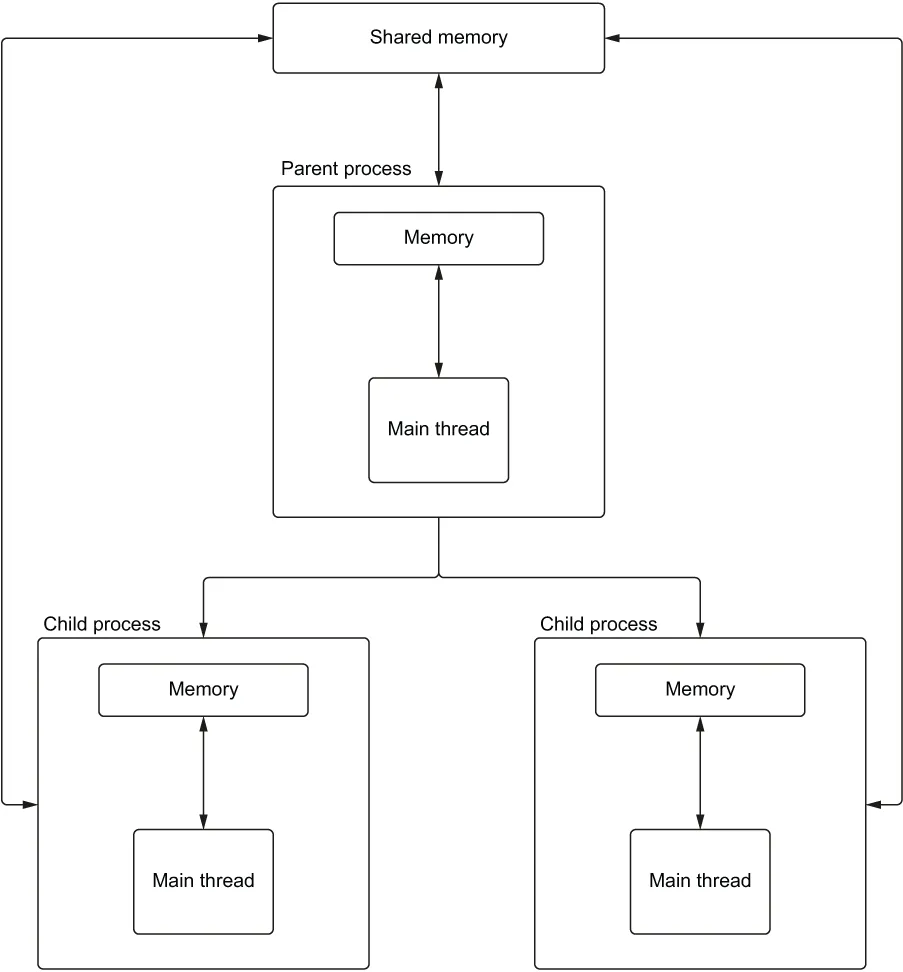
Multiprocessing 支持一种称为“共享内存对象”的概念。共享内存对象是一块分配的内存,一组独立的进程可以访问。如图 6.2 所示,每个进程都可以根据需要读取和写入该内存空间。
共享状态很复杂,如果实施不当,会导致难以重现的错误。通常最好避免共享状态。不过,有时确实有必要引入共享状态。一个这样的例子是共享计数器。
为了更深入地了解共享数据,我们将以上面的 MapReduce 例子为基础,保持一个已完成映射操作的计数器。然后,我们定期输出这个数字,以显示用户当前的进度。
Multiprocessing 支持两种类型的共享数据:值和数组。一个“值”是一个单一的值,比如一个整数或浮点数。一个“数组”是一个单一值的数组。我们可以在内存中共享的数据类型受到 Python 数组模块中定义的类型的限制,可在 https://docs.python.org/3/library/array.html#module-array(https://docs.python.org/3/library/array.html#module-array) 找到。
要创建一个值或数组,我们首先需要使用数组模块的 typecode,它只是一个字符。让我们创建两个共享的数据项——一个整数值和一个整数数组。然后,我们将创建两个进程来并行增加这两个共享数据项。
from multiprocessing import Process, Value, Arraydef increment_value(shared_int: Value): shared_int.value = shared_int.value + 1def increment_array(shared_array: Array): for index, integer in enumerate(shared_array): shared_array[index] = integer + 1if __name__ == '__main__': integer = Value('i', 0) integer_array = Array('i', [0, 0]) procs = [Process(target=increment_value, args=(integer,)), Process(target=increment_array, args=(integer_array,))] [p.start() for p in procs] [p.join() for p in procs] print(integer.value) print(integer_array[:])
在上面的代码中,我们创建了两个进程——一个用于增加我们的共享整数值,另一个用于增加我们共享数组中的每个元素。一旦两个子进程完成,我们就打印出数据。
由于我们的两块数据从未被不同进程触碰,这段代码运行得很好。如果多个进程修改同一个共享数据,这段代码还能继续工作吗?让我们通过创建两个进程来并行增加一个共享整数值来测试一下。我们将在这段代码上反复运行一个循环,以查看结果是否一致。由于我们有两个进程,每个都把共享计数器加一,一旦进程完成,我们期望共享值始终为二。
from multiprocessing import Process, Valuedef increment_value(shared_int: Value): shared_int.value = shared_int.value + 1if __name__ == '__main__': for _ in range(100): integer = Value('i', 0) procs = [Process(target=increment_value, args=(integer,)), Process(target=increment_value, args=(integer,))] [p.start() for p in procs] [p.join() for p in procs] print(integer.value) assert(integer.value == 2)
虽然你会看到不同的输出,因为这个问题是非确定性的,但在某个时候,你应该会看到结果并不总是 2。
222断言错误 (AssertionError)1
有时候我们的结果是 1!为什么会这样?我们遇到的问题叫做“竞态条件”。竞态条件发生在一组操作的结果依赖于哪个操作先完成时。你可以想象这些操作在彼此竞争;如果操作以正确的顺序赢得比赛,一切都会正常。如果它们以错误的顺序赢得比赛,就会出现奇怪的行为。
那么,我们的例子中竞态在哪里发生?问题在于增加一个值涉及读取和写入操作。要增加一个值,我们首先需要读取该值,加一,然后将结果写回内存。每个进程在共享数据中看到的值完全取决于它读取共享值的时间。
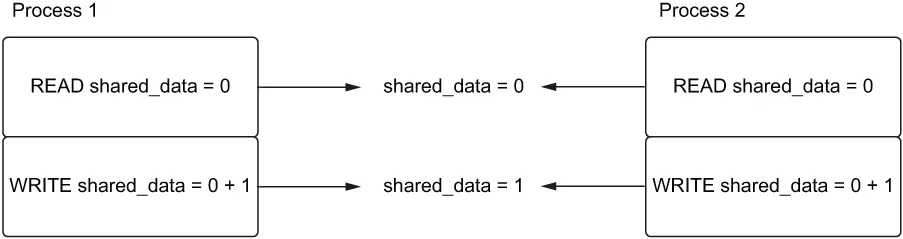
如果进程以以下顺序运行,一切都会正常,如图 6.3 所示。
在这种情况下,进程 1 在进程 2 读取之前增加了值,并赢得了比赛。由于进程 2 是第二个完成的,这意味着它会看到正确的值 1,并加上去,从而产生正确的最终值。
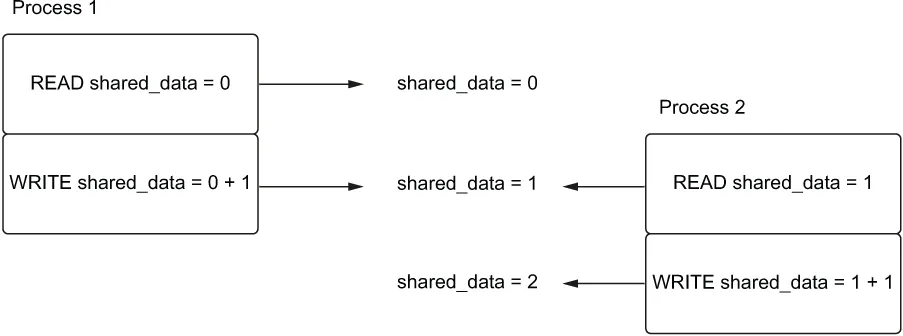
如果我们的虚拟比赛中出现平局怎么办?请看图 6.4。
在这种情况下,进程 1 和进程 2 都读取了初始值 0。然后它们都将该值增加到 1,并同时写回,产生了错误的值。
你可能会问:“但我们的代码只有一行。为什么会有两个操作!?” 在底层,增加是作为两个操作编写的,这导致了这个问题。这使得它“非原子”或“非线程安全”。这不容易弄清楚。有关哪些操作是原子的,哪些是非原子的解释,可在 http://mng.bz/5Kj4(http://mng.bz/5Kj4) 找到。
这类错误很难,因为它们往往难以重现。它们不像普通错误,因为它们依赖于操作系统运行事物的顺序,而这在使用 multiprocessing 时是不受我们控制的。那么,我们该如何修复这个烦人的错误呢?
我们可以避免竞态条件,通过“同步”对任何我们想要修改的共享数据的访问。所谓同步访问是什么意思?重新审视我们的竞态例子,这意味着我们控制对任何共享数据的访问,使得任何操作都能以一种合理的方式完成比赛。如果一个情况可能发生两个操作之间的平局,我们明确阻止第二个操作运行,直到第一个完成,确保操作以一致的方式完成比赛。你可以想象这就像终点线上的裁判,看到平局即将发生,告诉跑者:“稍等一下。一次一个!” 并挑选一个跑者等待,让另一个跑者冲过终点线。
一种同步访问共享数据的机制是“锁”,也称为“互斥锁”(mutex)(意为“互斥”)。这些结构允许一个进程“锁定”一段代码,防止其他进程运行该代码。被锁定的代码段通常被称为“临界区”。这意味着如果一个进程正在执行被锁定的代码段,而另一个进程试图访问该代码,第二个进程将需要等待(被裁判阻止),直到第一个进程完成对该锁定段的执行。
锁支持两个主要操作:获取和释放。当一个进程获取锁时,它保证自己是唯一运行该代码段的进程。一旦需要同步访问的代码段完成,我们就释放锁。这允许其他进程获取锁并运行临界区中的任何代码。如果一个进程尝试运行被另一个进程锁定的代码,获取锁将阻塞,直到另一个进程释放该锁。
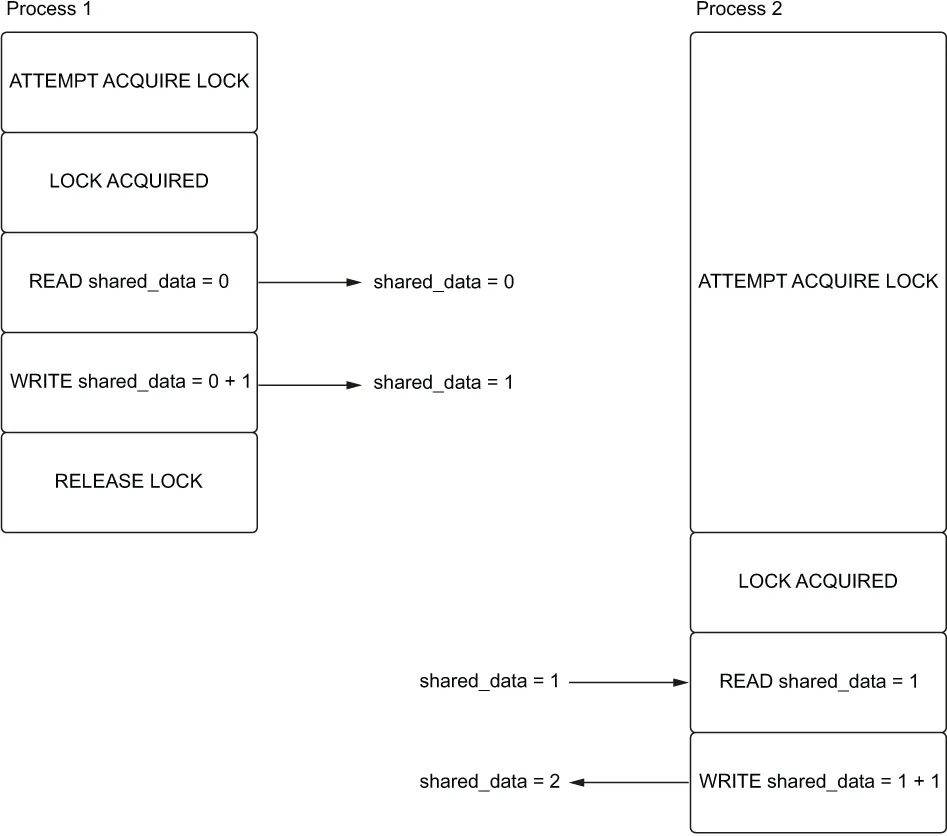
重新审视我们的计数器竞态条件示例,并参考图 6.5,让我们可视化当两个进程几乎同时尝试获取锁时会发生什么。然后,让我们看看它如何防止计数器获得错误的值。
图 6.5 进程 2 被阻塞,直到进程 1 释放锁才能读取共享数据。
在该图中,进程 1 首先成功获取锁,读取并增加共享数据。第二个进程尝试获取锁,但被阻止,无法进一步推进,直到第一个进程释放锁。一旦第一个进程释放锁,第二个进程就可以成功获取锁并增加共享数据。这防止了竞态条件,因为锁防止了多个进程同时读取和写入共享数据。
那么,我们如何用我们的共享数据实现这种同步?multiprocessing API 的开发者想到了这一点,并很好地包含了获取值和数组锁的方法。要获取锁,我们调用 get_lock().acquire(),要释放锁,我们调用 get_lock().release()。使用列表 6.12,让我们将这应用于我们之前的例子以修复我们的错误。
from multiprocessing import Process, Valuedef increment_value(shared_int: Value): shared_int.get_lock().acquire() shared_int.value = shared_int.value + 1 shared_int.get_lock().release()if __name__ == '__main__': for _ in range(100): integer = Value('i', 0) procs = [Process(target=increment_value, args=(integer,)), Process(target=increment_value, args=(integer,))] [p.start() for p in procs] [p.join() for p in procs] print(integer.value) assert (integer.value == 2)
当我们运行这段代码时,我们得到的每个值都应该是 2。我们已经修复了竞态条件!请注意,锁也是上下文管理器,为了清理代码,我们可以使用 with 块来编写 increment_value 函数。这将为我们自动获取和释放锁:
def increment_value(shared_int: Value): with shared_int.get_lock(): shared_int.value = shared_int.value + 1
请注意,我们已经将并发代码强制变为顺序执行,这抵消了并行运行的价值。这是一个重要的观察,也是并发中同步和共享数据的一个警告。为了避免竞态条件,我们必须使我们的并行代码在关键部分顺序执行。这可能会损害我们的 multiprocessing 代码的性能。必须仔细权衡,只锁定绝对必要的部分,以便应用程序的其他部分可以并发执行。面对竞态条件错误时,很容易用锁保护所有代码。这将“修复”问题,但很可能降低应用程序的性能。
我们刚刚看到了如何在几个进程中共享数据,那么如何将这些知识应用到进程池中呢?进程池的操作方式与手动创建进程略有不同,这给共享数据带来了挑战。为什么是这样?
当我们向进程池提交一个任务时,它可能不会立即运行,因为池中的进程可能正忙于其他任务。进程池是如何处理这个问题的?在后台,进程池执行器会维护一个任务队列来管理这一点。当我们向进程池提交一个任务时,它的参数会被序列化(腌制)并放入任务队列。然后,每个工作进程在准备好工作时,会从队列中请求一个任务。当一个工作进程从队列中取出一个任务时,它会反序列化(解腌制)参数并开始执行任务。
共享数据从定义上讲是在工作进程之间共享的。因此,来回发送它进行腌制和解腌制毫无意义。事实上,Value 和 Array 对象都无法被腌制,所以如果我们像以前一样将共享数据作为参数传递给函数,我们会收到类似 can't pickle Value objects 的错误。
为了解决这个问题,我们需要将我们的共享计数器放在一个全局变量中,并以某种方式让我们的工作进程知道它。我们可以使用“进程池初始化器”来做到这一点。这些是特殊函数,当池中的每个进程启动时都会被调用。通过这种方式,我们可以创建一个引用,指向父进程创建的共享内存。我们可以在创建进程池时传入这个函数。为了看看它是如何工作的,让我们创建一个简单的例子来增加一个计数器。
from concurrent.futures import ProcessPoolExecutorimport asynciofrom multiprocessing import Valueshared_counter: Valuedef init(counter: Value): global shared_counter shared_counter = counterdef increment(): with shared_counter.get_lock(): shared_counter.value += 1async def main(): counter = Value('d', 0) with ProcessPoolExecutor(initializer=init, initargs=(counter,)) as pool: # ❶ await asyncio.get_running_loop().run_in_executor(pool, increment) print(counter.value)if __name__ == "__main__": asyncio.run(main())
- ❶ 这告诉池为每个进程执行函数
init,并传入参数 counter。
我们首先定义一个全局变量 shared_counter,它将包含对创建的共享 Value 对象的引用。在我们的 init 函数中,我们接收一个 Value 并将 shared_counter 初始化为该值。然后,在主协程中,我们创建计数器并将其初始化为 0,然后将我们的 init 函数和计数器传入 initializer 和 initargs 参数,以创建进程池。init 函数将为进程池创建的每个进程调用一次,正确地将我们的 shared_counter 初始化为我们在主协程中创建的那个。
你可能会问:“为什么我们要费这么多事?难道我们不能直接将全局变量初始化为 shared_counter: Value = Value('d', 0) 而不是让它为空吗?” 我们不能这样做的原因是,当每个进程被创建时,我们创建它的脚本会被再次运行,每个进程都如此。这意味着每个启动的进程都会执行 shared_counter: Value = Value('d', 0),这意味着如果有 100 个进程,我们会得到 100 个 shared_counter 值,每个都设置为 0,导致一些奇怪的行为。
现在我们知道如何使用进程池正确初始化共享数据,让我们看看如何将其应用到我们的 MapReduce 应用程序中。我们将创建一个共享计数器,每次映射操作完成时就增加一次。我们还将创建一个 progress_reporter 任务,它将在后台运行,每秒向控制台输出一次进度。为了这个例子,我们将导入一些围绕分区和减少的代码,以避免重复。
from concurrent.futures import ProcessPoolExecutorimport functoolsimport asynciofrom multiprocessing import Valuefrom typing import List, Dictfrom chapter_06.listing_6_8 import partition, merge_dictionariesmap_progress: Valuedef init(progress: Value): global map_progress map_progress = progressdef map_frequencies(chunk: List[str]) -> Dict[str, int]: counter = {} for line in chunk: word, _, count, _ = line.split('\t') if counter.get(word): counter[word] = counter[word] + int(count) else: counter[word] = int(count) with map_progress.get_lock(): map_progress.value += 1 return counterasync def progress_reporter(total_partitions: int): while map_progress.value < total_partitions: print(f'已完成 {map_progress.value}/{total_partitions} 个映射操作') await asyncio.sleep(1)async def main(partiton_size: int): global map_progress with open('googlebooks-eng-all-1gram-20120701-a', encoding='utf-8') as f: contents = f.readlines() loop = asyncio.get_running_loop() tasks = [] map_progress = Value('i', 0) with ProcessPoolExecutor(initializer=init, initargs=(map_progress,)) as pool: total_partitions = len(contents) // partiton_size reporter = asyncio.create_task(progress_reporter(total_partitions)) for chunk in partition(contents, partiton_size): tasks.append(loop.run_in_executor(pool, functools.partial(map_frequencies, chunk))) counters = await asyncio.gather(*tasks) await reporter final_result = functools.reduce(merge_dictionaries, counters) print(f'Aardvark 出现了 {final_result["Aardvark"]} 次。')if __name__ == "__main__": asyncio.run(main(partiton_size=60000))
除了初始化共享计数器之外,与我们原始的 MapReduce 实现相比,主要的变化在于我们的 map_frequencies 函数内部。在完成该块中所有单词的计数后,我们获取共享计数器的锁并增加它。我们还添加了一个 progress_reporter 协程,它将在后台运行,并每秒报告一次我们完成了多少个任务。运行此代码时,你应该会看到类似以下的输出:
已完成 17/1443 个映射操作已完成 144/1443 个映射操作已完成 281/1443 个映射操作已完成 419/1443 个映射操作已完成 560/1443 个映射操作已完成 701/1443 个映射操作已完成 839/1443 个映射操作已完成 976/1443 个映射操作已完成 1099/1443 个映射操作已完成 1230/1443 个映射操作已完成 1353/1443 个映射操作Aardvark 出现了 15209 次。
现在我们知道如何使用 multiprocessing 与 asyncio 来提升计算密集型工作的性能。如果我们的工作负载既有大量的计算密集型操作,又有 I/O 密集型操作,该怎么办?我们可以使用 multiprocessing,但有没有办法结合 multiprocessing 和单线程并发模型来进一步提升性能?