从 JDK 1.7 开始,引入了一种新的 Fork/Join线程池框架。它可以将一个大任务拆分成多个小任务并行执行,最后聚合执行结果。
比如,如果你现在想计算一个数组的和,最简单的方式就是在一个线程中使用循环来完成。但是,当数组非常大时,这种方式的执行效率会比较差,如下面的示例代码所示。
long sum = 0;for (int i = 0; i < array.length; i++) { sum += array[i];}System.out.println("result: " + sum);
还有一种方式,就是对数组进行拆分。例如,将其分成 4 部分,用 4 个线程并行执行。每一部分单独计算,最后聚合结果。这样,执行效率会有显著提升。
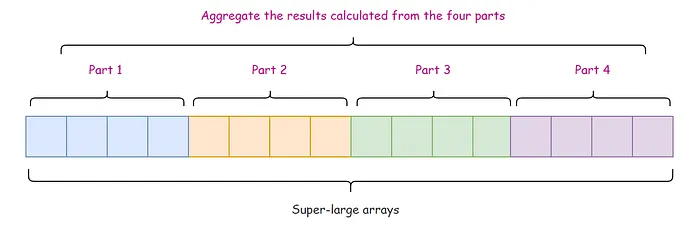
如果拆分后的部分仍然很大,可以继续拆分,直到满足最小粒度,然后再进行计算。这个过程可以反复“裂变”成一系列小任务,这就是 Fork/Join的工作原理。
Fork/Join采用了“分而治之”的基本思想。“分而治之”是指将一个复杂的任务按照指定的阈值分解成多个简单的小任务,然后聚合并返回这些小任务的执行结果,从而得到最终的执行结果。
现在让我们一起来看看 Fork/Join的具体用法。
ForkJoin 的用法
以并行计算一个由 100,000 个数字组成的数组的和为例,Fork/Join的一个简单应用示例如下:
publicclassForkJoinTest{publicstaticvoidmain(String[] args)throws Exception {// 创建一个由 100,000 个数字组成的数组。long[] array = newlong[100000];// 记录在 for 循环中聚合计算的值。long sourceSum = 0;for (int i = 0; i < array.length; i++) { array[i] = i; sourceSum += array[i]; } System.out.println("在 for 循环中聚合计算的值: " + sourceSum); System.out.println("---------------");// 使用 fork/join 框架计算并聚合的值。 ForkJoinPool forkJoinPool = new ForkJoinPool(); ForkJoinTask<Long> taskFuture = forkJoinPool.submit(new SumTask(array, 0, array.length)); System.out.println("使用 fork/join 框架计算并聚合的值: " + taskFuture.get()); }staticclassSumTaskextendsRecursiveTask<Long> {/** * 最小任务数组的最大容量。 */privatestaticfinalint THRESHOLD = 25000;privatelong[] array;privateint start;privateint end;publicSumTask(long[] array, int start, int end){this.array = array;this.start = start;this.end = end; }@Overrideprotected Long compute(){// 检查任务是否足够小。如果是,直接计算。if (end - start <= THRESHOLD) {long sum = 0;for (int i = start; i < end; i++) { sum += this.array[i]; }return sum; }// 任务太大,将其拆分为二。int middle = (end + start) / 2;// 拆分并执行。 SumTask leftTask = new SumTask(this.array, start, middle); leftTask.fork(); SumTask rightTask = new SumTask(this.array, middle, end); rightTask.fork(); System.out.println("拆分任务,并确定 leftTask 的数组范围: " + start + "," + middle + ", rightTask 的数组范围: " + middle + "," + end);// 聚合结果。return leftTask.join() + rightTask.join(); } }}
输出:
在 for 循环中聚合计算的值:4999950000---------------拆分任务,并确定 leftTask 的数组范围:0,25000, rightTask 的数组范围:25000,50000拆分任务,并确定 leftTask 的数组范围:50000,75000, rightTask 的数组范围:75000,100000拆分任务,并确定 leftTask 的数组范围:0,50000, rightTask 的数组范围:50000,100000使用 fork/join 框架计算并聚合的值:4999950000
从日志中可以清楚地看出,for 循环方式聚合计算的结果与 Fork/Join方式的结果是一致的。
由于最小任务数组的最大容量设置为 25000,Fork/Join 框架将数组拆分了三次。过程如下:
- 第一次拆分,将
0 到 100000的数组拆分为 0 到 50000和 50000 到 100000的数组。 - 第二次拆分,将
0 到 50000的数组拆分为 0 到 25000和 25000 到 50000的数组。 - 第二次拆分,将
50000 到 100000的数组拆分为 50000 到 75000和 75000 到 100000的数组。 - 最后进行合并计算,将拆分的最小任务的计算结果进行合并处理,返回最终结果。
当数组中的数据量较大时,使用 Fork/Join方式计算,程序执行效率的优势非常明显。
ForkJoin 框架的原理
从上面的用例可以看出,Fork/Join框架的使用涉及两个核心类:ForkJoinPool和 ForkJoinTask,它们的分工如下:
ForkJoinPool是一个负责执行任务的线程池。它内部使用一个无界队列来保存待执行的任务。执行任务的线程数量通过构造函数传递。如果没有传递具体的线程数量,默认取当前计算机的可用 CPU 核心数。ForkJoinTask是一个负责拆分任务和合并计算结果的抽象类。通过它,可以将一个大任务分解成多个小任务进行计算,最后聚合处理每个任务的执行结果。
如前所述,Fork/Join框架采用了“分而治之”的思想。它会将一个极大的任务分解,按照设定的阈值分解成多个小任务计算,最后聚合各种计算结果。它有很多应用场景,如大整数乘法、二分查找、大数组快速排序等。
有一点可能需要注意。ForkJoinPool线程池和 ThreadPoolExecutor线程池的实现原理是不同的。
最明显的区别在于:在 ThreadPoolExecutor中,一个线程在等待任务完成时,无法向任务队列添加另一个任务并继续执行;而 ForkJoinPool可以实现这一点。它允许其中的线程创建新任务并将其添加到队列中,挂起当前任务。此时,线程继续从队列中选择子任务执行。
关于 ThreadPoolExecutor的详细内容,我将在下一篇文章中专门介绍。
因此,在 JDK 1.7 中,ForkJoinPool线程池的实现是一个全新的类,它没有复用 ThreadPoolExecutor线程池的实现逻辑。两者的用途不同。
1. ForkJoinPool
ForkJoinPool是 Fork/Join框架中负责任务执行的线程池。其核心构造方法的源码如下:
/** * 核心构造方法。 * @param parallelism 并行执行的线程数。 * @param factory 创建线程的工厂。 * @param handler 异常捕获处理器。 * @param asyncMode 任务队列模式。true: 先进先出 (FIFO) 工作模式; false: 后进先出 (LIFO) 工作模式。 */publicForkJoinPool(int parallelism, ForkJoinWorkerThreadFactory factory, UncaughtExceptionHandler handler,boolean asyncMode){this(checkParallelism(parallelism), checkFactory(factory), handler, asyncMode? FIFO_QUEUE : LIFO_QUEUE,"ForkJoinPool-" + nextPoolId() + "-worker-"); checkPermission();}
默认无参构造函数的源码如下:
publicForkJoinPool(){this(Math.min(MAX_CAP, Runtime.getRuntime().availableProcessors()), defaultForkJoinWorkerThreadFactory, null, false);}
使用默认构造函数创建 ForkJoinPool线程池时,关键参数设置如下:
- parallelism:取当前计算机的可用 CPU 数量。
factory: 采用默认的 DefaultForkJoinWorkerThreadFactory类。其中,ForkJoinWorkerThread是 Fork/Join框架中负责实际执行任务的线程。asyncMode: 参数设置为 false,表示队列中的任务以“后进先出”的方式工作。
其次,也可以使用 Executors 工具类创建 ForkJoinPool,例如通过以下方式:
// 创建一个 ForkJoinPool 线程池ExecutorService forkJoinPool = Executors.newWorkStealingPool();
与 ThreadPoolExecutor线程池一样,ForkJoinPool也实现了 Executor 和 ExecutorService 接口,支持通过 execute()和 submit()等方法提交任务。
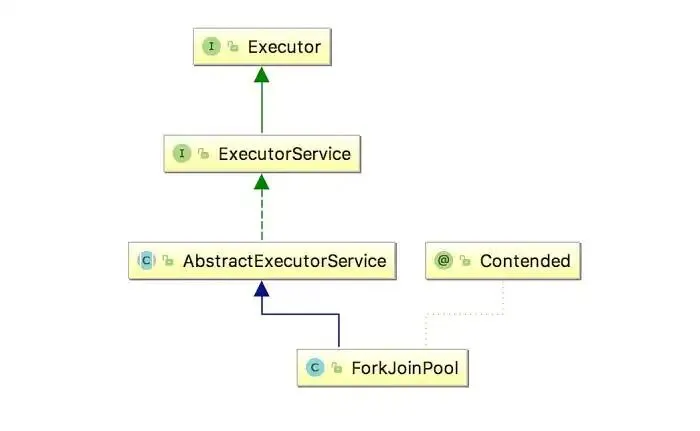
但是,如前所述,ForkJoinPool和 ThreadPoolExecutor的实现是不同的:
- 在
ThreadPoolExecutor中,多个线程共享一个阻塞任务队列。 - 在
ForkJoinPool中,每个线程都有自己的任务队列。当一个线程发现自己的队列中没有任务时,它会去其他线程的队列中获取任务执行。
这种设计的主要目的是充分利用线程以达到并行计算的效果,并减少线程间的竞争。
例如,线程 A 负责处理队列 A 中的任务,线程 B 负责处理队列 B 中的任务。如果两个队列中的任务数量相近,它们在执行过程中不会互相干扰,此时的计算性能是最好的。如果线程 A 的任务已经完成,通过检查发现线程 B 的队列中还有一半的任务未执行,线程 A 会主动从线程 B 的队列中获取任务执行。
此时,它们会同时访问同一个队列。为了减少线程 A 和线程 B 之间的竞争,通常使用双端队列。线程 B 从双端队列的头部获取任务执行,而线程 A 从双端队列的尾部获取任务执行,确保它们不会从同一端获取任务,这可以显著加快任务的执行速度。
以下是 Fork/Join框架中负责执行任务的线程 ForkJoinWorkerThread的部分源码:
publicclassForkJoinWorkerThreadextendsThread{// 该线程所属的线程池。final ForkJoinPool pool;// 当前线程的任务队列。final ForkJoinPool.WorkQueue workQueue;// 用于初始化的构造方法。protectedForkJoinWorkerThread(ForkJoinPool pool){// 使用占位符,直到可以在 registerWorker 中设置有用的名称super("aForkJoinWorkerThread");this.pool = pool;this.workQueue = pool.registerWorker(this); }}
2. ForkJoinTask
ForkJoinTask是 Fork/Join框架中负责任务分解和合并计算的抽象类。它实现了 Future 接口,因此可以直接作为任务类提交给线程池。
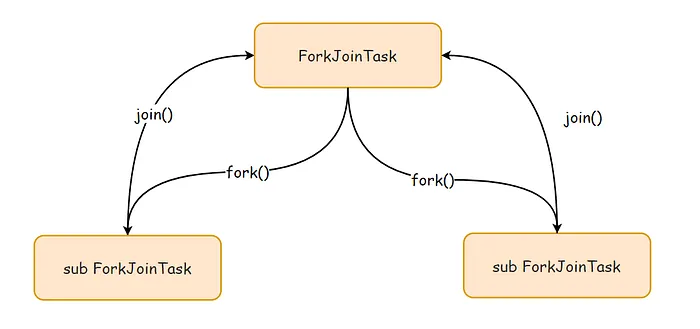
同时,它也包含两个主要方法:fork()和 join(),分别代表任务的拆分和合并。
这个过程可以用下图来表示。
ForkJoinTask的部分方法源码如下:
publicabstractclassForkJoinTask<V> implementsFuture<V>, Serializable{// 将任务推入任务队列。publicfinal ForkJoinTask<V> fork(){ Thread t;if ((t = Thread.currentThread()) instanceof ForkJoinWorkerThread) ((ForkJoinWorkerThread) t).workQueue.push(this);else ForkJoinPool.common.externalPush(this);returnthis; }// 等待任务的执行结果。publicfinal V join(){int s;if ((s = doJoin() & DONE_MASK)!= NORMAL) reportException(s);return getRawResult(); }}
在 JDK 中,ForkJoinTask有三个常用的子类实现如下:
RecursiveAction: 用于没有返回结果的任务。RecursiveTask: 用于有返回结果的任务。CountedCompleter: 任务执行完成后触发自定义钩子函数。
我们在开头介绍的用例使用的是 RecursiveTask子类,它通常用于带返回值的任务计算。
实际上,ForkJoinTask利用递归算法实现了任务拆分。它将拆分的子任务提交给线程池的任务队列执行,最后聚合每个拆分任务的计算结果,从而得到最终的任务结果。
总结
Fork/Join框架是一种基于“分而治之”的算法:它分解任务,并行执行,最后合并结果以获得最终结果。
其中,ForkJoinPool可以看作是 ThreadPoolExecutor线程池的有效补充。它的工作线程中有一个任务队列,可以充分利用线程进行并行计算,从而进一步增强线程的并发执行性能。
当 ForkJoinPool与 ForkJoinTask结合使用时,可以将极大的计算任务分解为多个独立的小任务,然后将这些小任务提交给线程池进行计算。最后,聚合处理每个小任务的计算结果,得到的结果与单线程执行的结果一致。而且,计算任务的规模越大,Fork/Join框架执行任务的效率优势就越显著。
然而,并非所有任务都适合由 Fork/Join框架处理。例如,读写数据文件等 IO 密集型任务就不适合,因为磁盘 IO 和网络 IO 的运行特性需要等待,而这种等待极有可能造成线程阻塞。

