用 Python 的 tkinter搭建一个可视化界面,来实现 Excel 自动化操作(比如读取、写入、修改 Excel 等)。
实现这个需求的核心是:用 tkinter 做可视化交互界面,用 openpyxl 库处理 .xlsx 格式的 Excel 文件(openpyxl 是处理 Excel 最常用的库之一,支持读写 .xlsx,不支持 .xls 格式)。
第一步:前置准备(安装依赖)
首先需要安装两个必要的库,打开终端执行以下命令:
pip install tkinter # 注意:多数 Python 环境(如 Python 3.7+)已自带 tkinter,若提示缺失再安装pip install openpyxl
第二步:完整实现代码
下面提供一个完整的示例,实现了 3 个核心 Excel 自动化功能(可视化界面操作):
import tkinter as tkfrom tkinter import filedialog, messagebox, scrolledtextfrom openpyxl import Workbook, load_workbookimport os# 定义主窗口类classExcelAutomationGUI:def__init__(self, root):# 初始化主窗口 self.root = root self.root.title("Excel 自动化工具(tkinter + openpyxl)") self.root.geometry("800x600") # 窗口大小# 初始化变量(存储Excel文件路径) self.excel_path = tk.StringVar()# 构建界面控件 self._create_widgets()def_create_widgets(self):"""构建tkinter界面控件"""# 1. 文件选择区域 frame_file = tk.Frame(self.root, padx=10, pady=10) frame_file.pack(fill=tk.X, anchor=tk.W) tk.Label(frame_file, text="Excel 文件路径:").pack(side=tk.LEFT) tk.Entry(frame_file, textvariable=self.excel_path, width=60).pack(side=tk.LEFT, padx=5) tk.Button(frame_file, text="选择文件", command=self._select_excel).pack(side=tk.LEFT)# 2. 功能按钮区域 frame_func = tk.Frame(self.root, padx=10, pady=10) frame_func.pack(fill=tk.X, anchor=tk.W) tk.Button(frame_func, text="1. 读取Excel并展示", command=self._read_excel, width=20).pack(side=tk.LEFT, padx=5) tk.Button(frame_func, text="2. 新建Excel并写入", command=self._create_excel, width=20).pack(side=tk.LEFT, padx=5) tk.Button(frame_func, text="3. 追加数据到Excel", command=self._append_excel, width=20).pack(side=tk.LEFT, padx=5)# 3. 内容展示区域(带滚动条) frame_show = tk.Frame(self.root, padx=10, pady=10) frame_show.pack(fill=tk.BOTH, expand=True) tk.Label(frame_show, text="操作结果/Excel内容展示:").pack(anchor=tk.W) self.result_text = scrolledtext.ScrolledText(frame_show, width=100, height=30) self.result_text.pack(fill=tk.BOTH, expand=True)def_select_excel(self):"""选择Excel文件(.xlsx格式)""" file_path = filedialog.askopenfilename( title="选择Excel文件", filetypes=[("Excel文件", "*.xlsx"), ("所有文件", "*.*")] )if file_path: self.excel_path.set(file_path) self.result_text.insert(tk.END, f"已选择文件:{file_path}\n") self.result_text.see(tk.END)def_read_excel(self):"""读取Excel文件内容并展示""" file_path = self.excel_path.get()ifnot file_path ornot os.path.exists(file_path): messagebox.showerror("错误", "请先选择有效的Excel文件!")returntry:# 加载Excel工作簿 wb = load_workbook(file_path)# 获取第一个工作表 ws = wb.active# 清空之前的展示内容 self.result_text.delete(1.0, tk.END) self.result_text.insert(tk.END, f"正在读取文件:{file_path}\n") self.result_text.insert(tk.END, f"当前工作表名称:{ws.title}\n") self.result_text.insert(tk.END, "Excel内容如下:\n")# 读取所有行和列(遍历工作表)for row in ws.iter_rows(values_only=True):# 格式化每行数据,去除None值 row_data = [str(cell) if cell isnotNoneelse""for cell in row] self.result_text.insert(tk.END, "\t".join(row_data) + "\n") wb.close() self.result_text.insert(tk.END, "\n读取完成!\n")except Exception as e: messagebox.showerror("读取错误", f"读取失败:{str(e)}") self.result_text.insert(tk.END, f"读取失败:{str(e)}\n")finally: self.result_text.see(tk.END)def_create_excel(self):"""新建Excel文件并写入测试数据"""# 选择保存路径 save_path = filedialog.asksaveasfilename( title="保存新建Excel文件", defaultextension=".xlsx", filetypes=[("Excel文件", "*.xlsx"), ("所有文件", "*.*")] )ifnot save_path:returntry:# 创建新的工作簿 wb = Workbook() ws = wb.active ws.title = "测试数据"# 修改工作表名称# 写入表头 headers = ["姓名", "年龄", "性别", "职业"] ws.append(headers)# 写入测试数据 test_data = [ ["张三", 25, "男", "工程师"], ["李四", 30, "女", "设计师"], ["王五", 28, "男", "产品经理"] ]for data in test_data: ws.append(data)# 保存Excel文件 wb.save(save_path) wb.close()# 展示结果 self.result_text.delete(1.0, tk.END) self.result_text.insert(tk.END, f"已成功新建Excel文件:{save_path}\n") self.result_text.insert(tk.END, "写入的数据如下:\n") self.result_text.insert(tk.END, "\t".join(headers) + "\n")for data in test_data: self.result_text.insert(tk.END, "\t".join([str(i) for i in data]) + "\n") messagebox.showinfo("成功", "Excel文件新建并写入数据完成!")except Exception as e: messagebox.showerror("创建错误", f"创建失败:{str(e)}") self.result_text.insert(tk.END, f"创建失败:{str(e)}\n")finally: self.result_text.see(tk.END)def_append_excel(self):"""向已存在的Excel文件追加数据""" file_path = self.excel_path.get()ifnot file_path ornot os.path.exists(file_path): messagebox.showerror("错误", "请先选择有效的Excel文件!")returntry:# 加载Excel工作簿(支持写入) wb = load_workbook(file_path) ws = wb.active# 定义要追加的数据 append_data = [ ["赵六", 32, "男", "运营"], ["钱七", 27, "女", "市场"] ]# 追加数据到工作表末尾for data in append_data: ws.append(data)# 保存修改 wb.save(file_path) wb.close()# 展示结果 self.result_text.insert(tk.END, f"\n已成功向 {file_path} 追加数据:\n")for data in append_data: self.result_text.insert(tk.END, "\t".join([str(i) for i in data]) + "\n") messagebox.showinfo("成功", "数据追加完成!")except Exception as e: messagebox.showerror("追加错误", f"追加失败:{str(e)}") self.result_text.insert(tk.END, f"追加失败:{str(e)}\n")finally: self.result_text.see(tk.END)# 程序入口if __name__ == "__main__": root = tk.Tk() app = ExcelAutomationGUI(root) root.mainloop()
第三步:代码关键部分解释
- 用
tkinter.Frame 划分区域(文件选择、功能按钮、结果展示),让界面更整洁。 - 用
scrolledtext.ScrolledText 实现带滚动条的文本展示,方便查看大量 Excel 内容。 - 用
filedialog 实现文件选择和保存的弹窗,提升交互体验。
Workbook():创建新的 Excel 工作簿。load_workbook(file_path):加载已存在的 Excel 工作簿。wb.active:获取工作簿中当前激活的(默认第一个)工作表。ws.append(data):向工作表末尾追加一行数据(最常用的写入方式)。ws.iter_rows(values_only=True):遍历工作表所有行,返回每行的单元格值(values_only=True 直接返回值,而非单元格对象)。wb.save(file_path):保存工作簿(新建文件时直接保存,修改文件时覆盖保存)。
- 增加了文件存在性判断,避免用户选择无效文件导致报错。
- 用
try...except 捕获 Excel 操作中的异常,并通过 messagebox 给出友好提示。
第四步:运行效果说明
- 选择文件:点击「选择文件」,可选取本地 .xlsx 格式的 Excel 文件。
- 读取 Excel:点击「1. 读取Excel并展示」,会在下方文本框中显示 Excel 的工作表名称和所有内容。
- 新建 Excel:点击「2. 新建Excel并写入」,会弹出保存弹窗,选择保存路径后,会生成一个包含测试数据的 Excel 文件。
- 追加数据:选择已存在的 Excel 文件后,点击「3. 追加数据到Excel」,会向该文件末尾追加两行新数据。
第五步:扩展功能建议
如果需要更复杂的 Excel 自动化,可以基于此代码扩展:
- 支持 Excel 单元格格式设置(字体、颜色、合并单元格等)。
- 支持 .xls 格式(需额外安装
xlrd 和 xlwt 库)。
总结
- 实现
tkinter + Excel 自动化的核心是tkinter 做界面交互,openpyxl 处理 Excel 读写。 - 关键依赖是
openpyxl 库,仅支持 .xlsx 格式,运行前需提前安装。 - 核心操作包括
load_workbook()(读取)、Workbook()(新建)、ws.append()(写入)、wb.save()(保存),在此基础上可扩展更复杂的 Excel 功能。
你希望用 Python 的 tkinter(注意拼写:是 tkinter 不是 kinter)搭建一个可视化 GUI 工具,来实现 PDF 相关处理功能。
首先,tkinter 仅负责构建图形界面,PDF 处理需要依赖专门的第三方库:
PyPDF2:轻量易用,支持 PDF 合并、拆分、页面提取、旋转等核心功能(本次示例核心依赖)。pdfplumber:可选,如需提取 PDF 中的文字、表格,精度更高(本次不做重点演示)。reportlab:可选,如需生成新 PDF(本次不做重点演示)。
下面我将实现一个 简易的 PDF 处理 GUI 工具,包含两个常用功能:PDF 合并、PDF 按页面拆分,你可以在此基础上扩展其他功能。
第一步:安装依赖库
先打开终端/命令提示符,安装所需库:
pip install tkinter PyPDF2 # tkinter 多数 Python 环境自带,若缺失可单独安装(Windows 一般自带,Linux 需安装 python3-tk)
第二步:完整代码实现(PDF 处理 GUI 工具)
import tkinter as tkfrom tkinter import filedialog, messagebox, ttkimport PyPDF2import osclassPDFProcessorGUI:def__init__(self, root):# 初始化主窗口 self.root = root self.root.title("简易 PDF 处理工具") self.root.geometry("600x400") # 窗口大小# 存储选择的 PDF 文件路径 self.pdf_files = []# 构建 GUI 界面 self.create_widgets()defcreate_widgets(self):"""创建所有 GUI 组件"""# 1. 标题标签 title_label = ttk.Label(self.root, text="PDF 处理工具(合并/拆分)", font=("Arial", 16)) title_label.pack(pady=20)# 2. 功能选择框架 func_frame = ttk.Frame(self.root) func_frame.pack(pady=10, fill=tk.X, padx=50)# 2.1 PDF 合并相关组件 merge_btn = ttk.Button(func_frame, text="选择要合并的 PDF 文件", command=self.select_pdf_files) merge_btn.grid(row=0, column=0, padx=10, pady=5) self.merge_exec_btn = ttk.Button(func_frame, text="执行 PDF 合并", command=self.merge_pdfs, state=tk.DISABLED) self.merge_exec_btn.grid(row=0, column=1, padx=10, pady=5)# 2.2 PDF 拆分相关组件 split_btn = ttk.Button(func_frame, text="选择要拆分的 PDF 文件", command=self.select_single_pdf) split_btn.grid(row=1, column=0, padx=10, pady=5) self.split_exec_btn = ttk.Button(func_frame, text="按页面拆分(每页1个PDF)", command=self.split_pdf, state=tk.DISABLED) self.split_exec_btn.grid(row=1, column=1, padx=10, pady=5)# 3. 已选择文件列表框(显示选择的 PDF) self.file_listbox = tk.Listbox(self.root, width=80, height=10) self.file_listbox.pack(pady=15, padx=20)# 4. 状态标签(显示处理进度/结果) self.status_label = ttk.Label(self.root, text="状态:未选择任何 PDF 文件", font=("Arial", 10)) self.status_label.pack(pady=10)defselect_pdf_files(self):"""选择多个要合并的 PDF 文件"""# 打开文件选择对话框,支持多选 PDF files = filedialog.askopenfilenames( title="选择要合并的 PDF 文件", filetypes=(("PDF 文件", "*.pdf"), ("所有文件", "*.*")) )if files: self.pdf_files = list(files) # 存储选择的文件路径# 更新列表框,显示已选择的 PDF 文件名 self.file_listbox.delete(0, tk.END) # 清空原有内容for file_path in self.pdf_files: file_name = os.path.basename(file_path) self.file_listbox.insert(tk.END, f"✅ {file_name}")# 启用合并按钮,更新状态 self.merge_exec_btn.config(state=tk.NORMAL) self.split_exec_btn.config(state=tk.DISABLED) self.status_label.config(text=f"状态:已选择 {len(self.pdf_files)} 个 PDF 文件(待合并)")defselect_single_pdf(self):"""选择单个要拆分的 PDF 文件"""# 打开文件选择对话框,仅支持单选 PDF file_path = filedialog.askopenfilename( title="选择要拆分的 PDF 文件", filetypes=(("PDF 文件", "*.pdf"), ("所有文件", "*.*")) )if file_path: self.pdf_files = [file_path] # 存储单个文件路径# 更新列表框,显示已选择的 PDF 文件名 self.file_listbox.delete(0, tk.END) file_name = os.path.basename(file_path) self.file_listbox.insert(tk.END, f"🔧 {file_name}")# 启用拆分按钮,更新状态 self.split_exec_btn.config(state=tk.NORMAL) self.merge_exec_btn.config(state=tk.DISABLED) self.status_label.config(text=f"状态:已选择 1 个 PDF 文件(待拆分)")defmerge_pdfs(self):"""执行 PDF 合并功能"""ifnot self.pdf_files: messagebox.showwarning("警告", "请先选择要合并的 PDF 文件!")return# 让用户选择合并后的 PDF 保存路径和文件名 output_file = filedialog.asksaveasfilename( title="保存合并后的 PDF 文件", defaultextension=".pdf", filetypes=(("PDF 文件", "*.pdf"), ("所有文件", "*.*")) )ifnot output_file:return# 用户取消保存try:# 初始化 PDF 写入器 pdf_writer = PyPDF2.PdfWriter()# 遍历所有选择的 PDF 文件,合并页面for pdf_path in self.pdf_files:with open(pdf_path, "rb") as pdf_file: pdf_reader = PyPDF2.PdfReader(pdf_file)# 遍历当前 PDF 的所有页面,添加到写入器中for page in pdf_reader.pages: pdf_writer.add_page(page)# 写入合并后的 PDF 文件with open(output_file, "wb") as output_pdf: pdf_writer.write(output_pdf)# 提示成功,更新状态 messagebox.showinfo("成功", f"PDF 合并完成!\n保存路径:{output_file}") self.status_label.config(text=f"状态:PDF 合并成功,已保存至 {os.path.basename(output_file)}")except Exception as e: messagebox.showerror("错误", f"PDF 合并失败!\n错误信息:{str(e)}") self.status_label.config(text="状态:PDF 合并失败")defsplit_pdf(self):"""执行 PDF 拆分功能(每页拆分为一个独立 PDF)"""ifnot self.pdf_files or len(self.pdf_files) != 1: messagebox.showwarning("警告", "请先选择单个要拆分的 PDF 文件!")return pdf_path = self.pdf_files[0]# 让用户选择拆分后的文件保存目录 output_dir = filedialog.askdirectory(title="选择拆分后 PDF 的保存目录")ifnot output_dir:return# 用户取消选择目录try:# 读取要拆分的 PDF 文件with open(pdf_path, "rb") as pdf_file: pdf_reader = PyPDF2.PdfReader(pdf_file) total_pages = len(pdf_reader.pages) pdf_base_name = os.path.splitext(os.path.basename(pdf_path))[0]# 遍历每一页,拆分并保存for page_num in range(total_pages): pdf_writer = PyPDF2.PdfWriter() pdf_writer.add_page(pdf_reader.pages[page_num])# 构建单个拆分文件的路径(格式:原文件名_第X页.pdf) output_file = os.path.join(output_dir, f"{pdf_base_name}_第{page_num+1}页.pdf")with open(output_file, "wb") as output_pdf: pdf_writer.write(output_pdf)# 更新状态标签,显示进度 self.status_label.config(text=f"状态:正在拆分第 {page_num+1}/{total_pages} 页") self.root.update_idletasks() # 刷新 GUI,显示实时进度# 提示成功,更新状态 messagebox.showinfo("成功", f"PDF 拆分完成!\n共拆分 {total_pages} 页,保存至:{output_dir}") self.status_label.config(text=f"状态:PDF 拆分成功,共生成 {total_pages} 个文件")except Exception as e: messagebox.showerror("错误", f"PDF 拆分失败!\n错误信息:{str(e)}") self.status_label.config(text="状态:PDF 拆分失败")if __name__ == "__main__":# 启动 GUI 程序 root = tk.Tk() app = PDFProcessorGUI(root) root.mainloop()
第三步:代码说明与使用方法
1. 核心功能说明
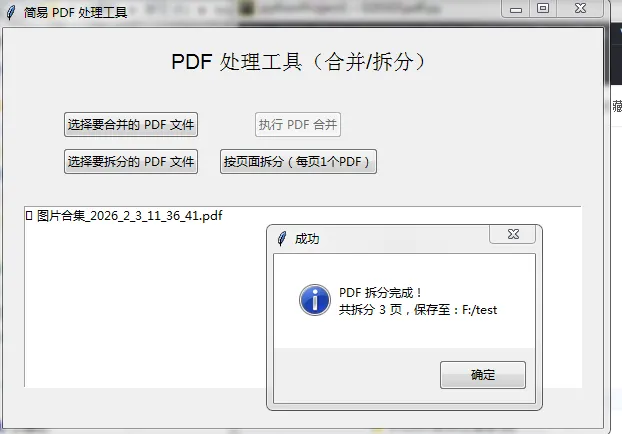
- GUI 界面:包含文件选择按钮、执行按钮、文件列表框、状态提示标签,布局简洁直观。
- PDF 合并:支持选择多个 PDF 文件,合并后由用户指定保存路径,保留所有页面的原始内容。
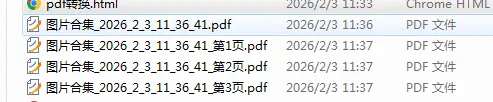
- PDF 拆分:支持选择单个 PDF 文件,按每页拆分(每页生成一个独立 PDF),拆分后保存到用户指定目录。
- 异常处理:包含弹窗提示(成功/警告/错误),避免程序崩溃,同时显示详细信息。
- 状态实时更新:拆分大 PDF 时,会实时显示当前拆分进度。
2. 使用步骤
- 点击「选择要合并的 PDF 文件」,多选需要合并的 PDF(按住
Ctrl 键可多选)。 - 选中后,列表框会显示已选择的文件,「执行 PDF 合并」按钮变为可用。
- 点击「执行 PDF 合并」,选择保存路径和文件名,等待完成即可。
- 点击「选择要拆分的 PDF 文件」,选择单个需要拆分的 PDF。
- 选中后,「按页面拆分(每页1个PDF)」按钮变为可用。
- 点击该按钮,选择拆分文件的保存目录,等待拆分完成即可。
3. 可扩展功能
如果需要更多 PDF 处理功能,可以基于此框架扩展:
- 页面旋转:使用
page.rotate(90)(支持 90/180/270 度)。 - 提取指定页面:让用户输入起始/结束页码,仅提取对应页面。
- PDF 文字提取:集成
pdfplumber,添加「提取 PDF 文字」按钮。 - PDF 加密/解密:使用
pdf_writer.encrypt("密码") 加密,pdf_reader.decrypt("密码") 解密。
第四步:注意事项
- 支持的 PDF 格式:仅支持标准 PDF 文件,加密或损坏的 PDF 可能处理失败。
- 中文路径:代码已兼容中文文件路径和目录,可正常使用。
- 依赖版本:若
PyPDF2 版本过高/过低出现报错,可安装指定版本:pip install PyPDF2==2.12.1。 tkinter 缺失:Linux 系统可能需要手动安装 tkinter,命令:sudo apt-get install python3-tk。
总结
- 本次实现的核心是**
tkinter 构建 GUI + PyPDF2 处理 PDF**,两者分工明确,可快速实现可视化 PDF 工具。 - 核心功能的关键步骤:PDF 合并(
PdfWriter + 遍历添加页面)、PDF 拆分(遍历单页 + 单独写入文件)。 - 该框架具备可扩展性,可基于此添加更多 PDF 处理功能,满足更复杂的需求。