Python学习
一、学前花絮
我们已经陆陆续续输出关于python学习的100多篇文章了,内容包括计算机基础知识、二进制介绍及python的基础功能、高级功能等等。
随着python学习的深入,我们也介绍并示例了python的很多内置、第三方模块,也完成自定义模块。是不是感觉python的模块太多了?这既是python的一大优势,说明维护、使用python的人很多,形成正向反馈。反之,如果一门语言少有人用,也会逐渐从历史中退出。
如果对计算机特别是软件熟悉的话,早期有很多当时流行的语言如Pascal、Visual Basic、Basic、Cobol、Perl等已经少有人用,甚至可以说退出了历史舞台。至于原因,篇幅限制不作展开。但总而言之,计算机语言与社会上其他物品是一样的,如果以10年时间为跨度,你也可以想想身边有多少物品消失了?具体原因不作探讨,最简单的回答就是不需要了!
为什么不需要了呢?那肯定是有更好的东西替代了。这就是一种选择,当有了更好用的东西之后,肯定会抛弃不好用的物品。
回到主题,我们在学习python的时候,无论涉及哪个方面,感觉python都有很多的解决办法,因为它太受欢迎了。即便最开始不好用的功能,也会随着版本迭代,更新到好用的版本。
我们今天想细化的collections模块就是如此。
二、Python 模块的三大阵营介绍并详述collections模块
2.1 python的模块是什么?
Python 模块本质上就是一个以 .py 结尾的文件,里面封装了变量、函数或类,目的是为了被其他程序导入和复用。
1. 模块的“物理形态”与“逻辑形态”
构成模块的 .py 文件是它的物理形态(它在硬盘上就是一个文件);而从代码逻辑上看,它是一个命名空间(Namespace)。
l物理上:就是一个文本文件,比如 math_utils.py。
l逻辑上:当你导入这个文件时,Python 会执行里面的代码,并把它里面定义的所有名字(函数名、变量名)打包在一个特定的名字空间里。这就像给这些名字加了一个“前缀”,防止它们和你当前代码里的名字发生冲突(避免“命名冲突”)。
2. 模块里通常放什么?
除了类(Class)和函数(Function),模块通常还包含以下内容:
l变量/常量:比如配置信息、数学常数(如 math.pi)。
l可执行的代码:虽然模块主要用来定义功能,但你也可以在模块里写一些顶层代码(比如初始化操作)。不过通常我们会用一个特殊的判断来控制这些代码只在模块被直接运行时才执行(比如用来做测试),而在被 import 时只定义功能不执行代码。
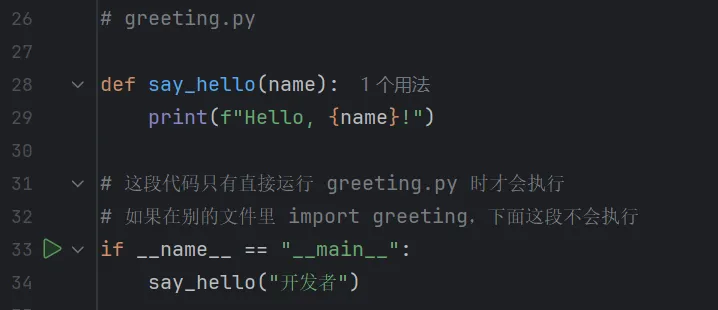
3. 一个非常重要的细节:__name__
为了让模块既能被别人导入,又能自己独立运行(比如用来做演示或测试),Python 提供了一个特殊的变量 __name__。
l当你直接运行这个 .py 文件时:__name__ 的值是 "__main__"。
l当它被 import 时:__name__ 的值是模块的文件名(不含.py)。
示例代码:
上面的简短程序说明了__name__的作用,这也是初学者容易困惑的。如果是单个文件,那么有没有这行都能执行,只有在模块导入的时候才起作用。
针对模块功能的总结:
可以把 Python 模块想象成一个“工具箱”:
l它是一个文件(.py)。
l里面装了工具(函数、类、变量)。
l如果你想用这个工具箱,就得先 import 它。
l它能防止你的工具名字和别人的工具名字撞车。
2.2 Python 模块的三大阵营介绍
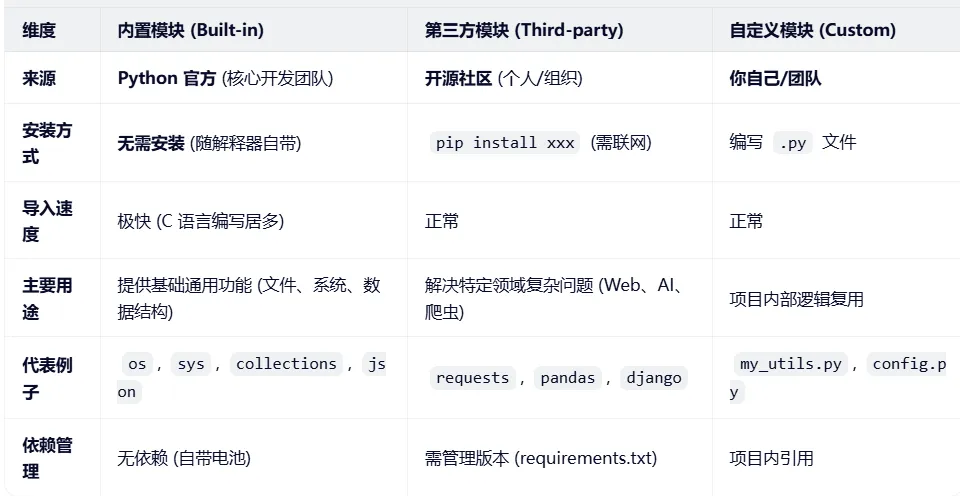
2.2.1 内置模块(原生/官方标准库)
代号: “出厂自带”
l定义:随 Python 解释器一起安装的模块。只要装了 Python,这些模块立马就能用,不需要联网下载。
l特点:稳定性极高,跨平台兼容性好,是 Python 的“核心装备”。
l形象比喻:手机出厂自带的原厂应用(如计算器、电话本)。
l典型例子:
① os / sys:操作系统交互、解释器参数。
② collections / itertools:数据结构增强工具。
③ json / re:数据序列化、正则表达式。
④ datetime / time:时间处理。
2.2.2第三方模块(社区贡献)
代号: “应用商店下载”
l定义:由 Python 社区开发者或组织开发,存储在 Python 包索引(PyPI)上。你需要使用 pip install 命令显式安装才能使用。
l特点:数量庞大(数十万),专注于特定领域(如 Web、AI、爬虫),更新迭代快。
l形象比喻:从 App Store 或安卓市场下载的微信、抖音、王者荣耀。
l典型例子:
① Web 开发:Django(重量级框架)、Flask(轻量级框架)、FastAPI(现代高性能 API 框架)。
② 数据分析/AI:Numpy(科学计算基础)、Pandas(数据分析)、TensorFlow / PyTorch(深度学习)。
③ 网络爬虫:Requests(HTTP 库)、Scrapy(爬虫框架)。
④ 可视化:Matplotlib、Seaborn、Plotly。
2.2.3 自定义模块(用户自己写)
代号: “自己写的备忘录”
l定义:你自己或者你的团队在项目中编写的 .py 文件。
l特点:代码复用,将复杂逻辑封装起来供项目内部调用。
l形象比喻:你自己写的笔记 App 或者 Excel 记账表格。
l典型例子:
你自己写的 utils.py(工具函数)、config.py(配置文件)、mymodule.py。
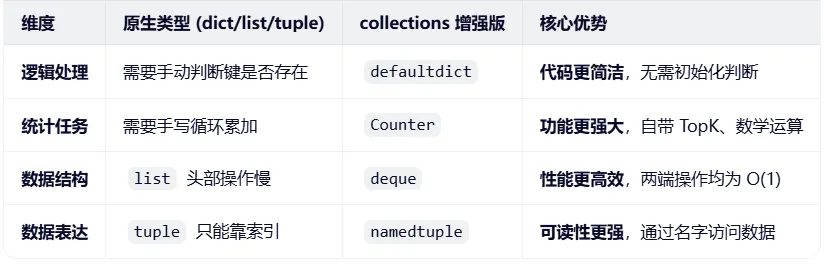
一张表看懂区别
以上内容总结:
Python 的这种架构设计非常优秀:
l内置模块让你“开箱即用”,处理基础逻辑。
l第三方模块让你“站在巨人的肩膀上”,不用重复造轮子(比如不用自己写神经网络算法)。
l自定义模块让你专注于业务逻辑,保持代码整洁。
你在写代码时,通常的导入顺序也是:先导入内置模块,再导入第三方模块,最后导入自定义模块。
2.3 python的高性能工具箱collections
collections 模块是 Python 的“高性能容器工具箱”,而且这个模块绝对属于 Python 的原生(标准库)功能,不是第三方社区贡献的。它为内置的 dict、list 和 tuple 提供了针对特定场景(如计数、队列、默认值等)优化的“超级增强版”,让你的代码更简洁、更高效。
collections 是 Python 官方为了弥补内置类型(dict/list/tuple)在某些特定场景下的不足(如性能瓶颈、代码繁琐),而直接内置在解释器里的官方解决方案。你可以把它看作是 Python 给你配发的“原厂升级配件”。
下面我们采用“原生写法(自带功能)” VS “collections 写法”的对比方式,带你看看它是如何通过“强力扩展”来解决原生类型痛点的。
1. defaultdict:告别繁琐的键值初始化
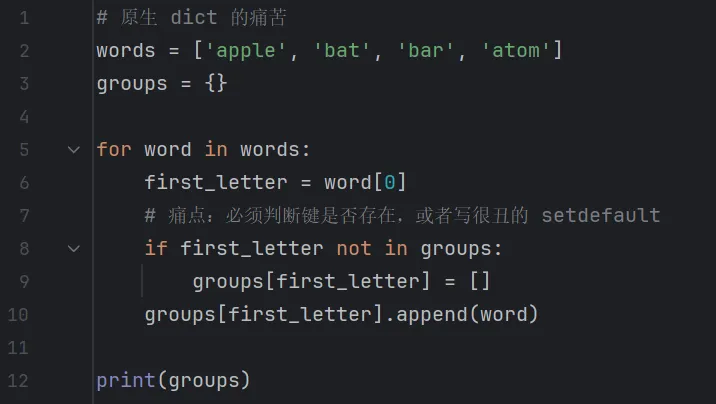
场景:将列表中的单词按首字母分组。
原生 dict 写法(繁琐且易错)
使用原生字典时,你必须时刻担心键是否存在,否则会报 KeyError。通常需要配合 if 判断或 setdefault。
输出结果:
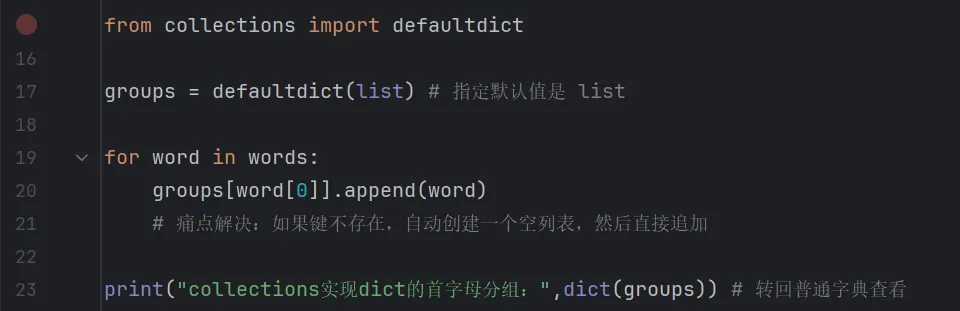
collections 写法(优雅且高效)
defaultdict 在创建时就指定了“默认工厂”(比如 list)。当你访问不存在的键时,它会自动调用工厂函数生成默认值,完全省去了 if 判断。
输出结果:
其实,我们从输出结果看,二者是一样的。但在书写代码的过程中,我们才知道collections模块的强大,并让代码非常优雅!
2. Counter:专为“计数”而生
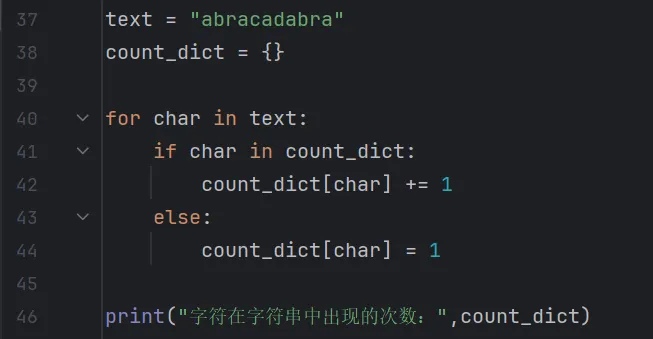
场景:统计字符串中每个字符出现的次数。
原生 dict 写法(基础循环)
你需要手动遍历,手动判断键是否存在,手动加 1。
输出结果:
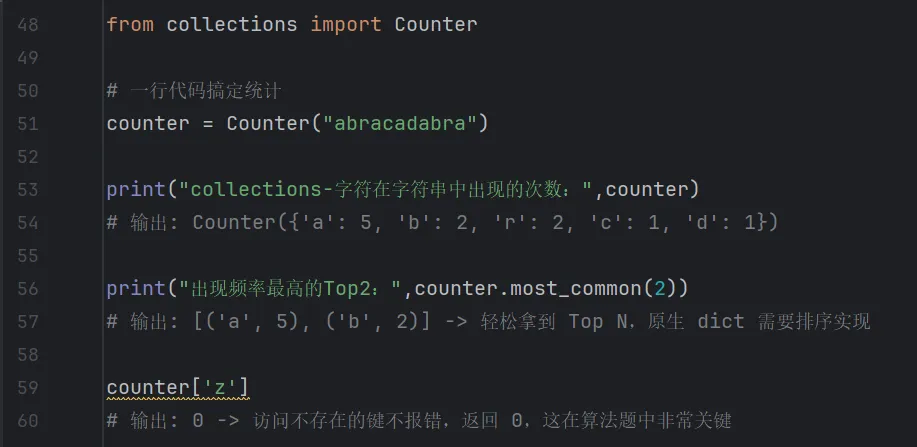
collections 写法(一行统计)
Counter 不仅自动处理了初始化(不存在的键返回 0),还提供了强大的辅助方法。
输出结果:
对比结论:Counter 是 dict 的专业化补充,它是为“统计频率”这一单一任务而优化的“瑞士军刀”。
3. deque:解决 list 的性能瓶颈
场景:实现一个队列(先进先出),或者维护一个固定长度的历史记录。
原生 list 写法(性能陷阱)
list 在尾部操作(append/pop)很快,但在头部插入或删除(insert(0, v) 或 pop(0))非常慢!因为需要移动后面所有的元素(时间复杂度 O(n))。
输出结果:
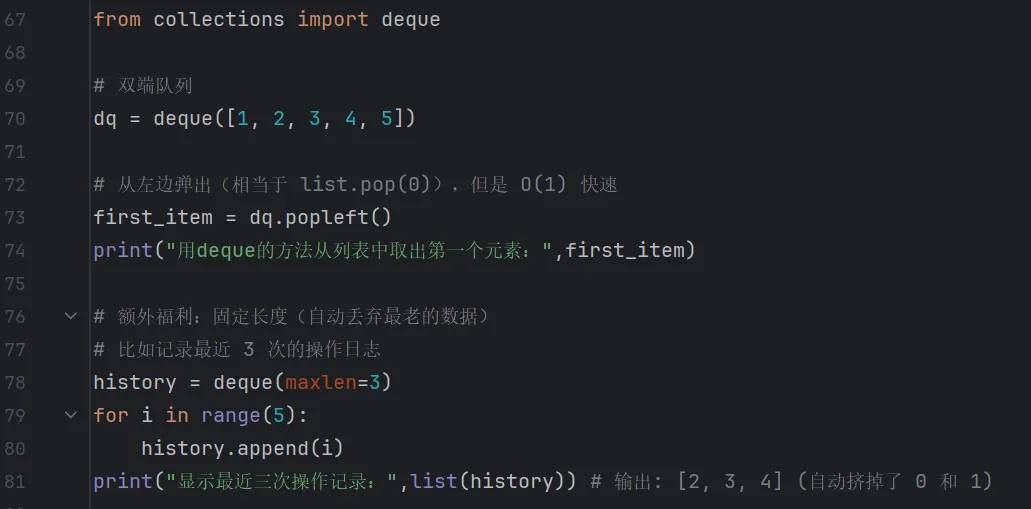
collections 写法(性能王者)
deque(双端队列)基于双向链表实现,在头部和尾部操作速度一样快(时间复杂度 O(1))。
输出结果:
对比结论:deque 是对 list 的性能扩展。当你需要频繁在序列两端操作时,必须用它替代 list。
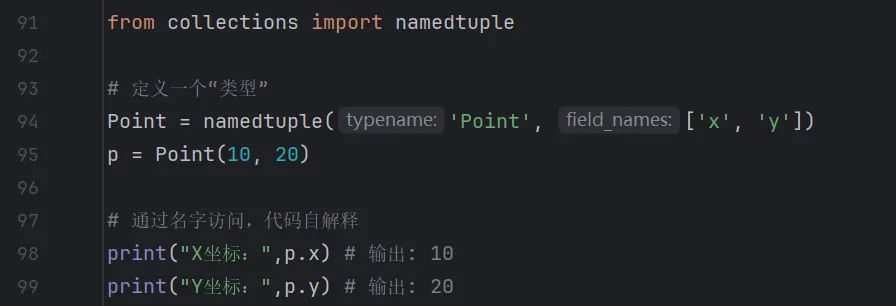
4. namedtuple:让 tuple 更像“数据类”
场景:表示一个坐标点 (x, y)。
原生 tuple 写法(可读性差)
虽然元组轻量,但访问元素只能靠索引,代码含义不清晰。
输出结果:
collections 写法(语义清晰)
namedtuple 让你像访问对象属性一样访问元组元素,既保持了元组的不可变性和内存高效,又增加了可读性。
输出结果:
对比结论:namedtuple 是对 tuple 的功能扩展,它填补了“轻量级不可变数据对象”的空白。
总结:collections 的核心价值
三、小结
通过了解python三种类型模块的使用规则,我们再次深入了解了python中众多模块的含义。而collections模块是对python内置数据类型list、tuple、dict的强大补充,所有新增功能为了在编写程序的时候有更多的工具选择。就如同我们写文章一样,如果手里有更多的工具或说是素材,写起来就更顺畅。
让我们保持学习热情,多做练习。我们下期再见!