阿里掀桌子了!凌晨突发新编程模型,训练范式大变天!3B激活参数硬刚Sonnet4.5!无缝集成CC、OpenClaw,训练阶段就能懂如何修改BUG!
- 2026-07-04 21:43:03


编辑 | 云昭
刚刚,阿里把“写代码这件事”掀桌子了!
今天凌晨,阿里开源了一款最新的编程模型:Qwen3-Coder-Next,引起了业界的注意。
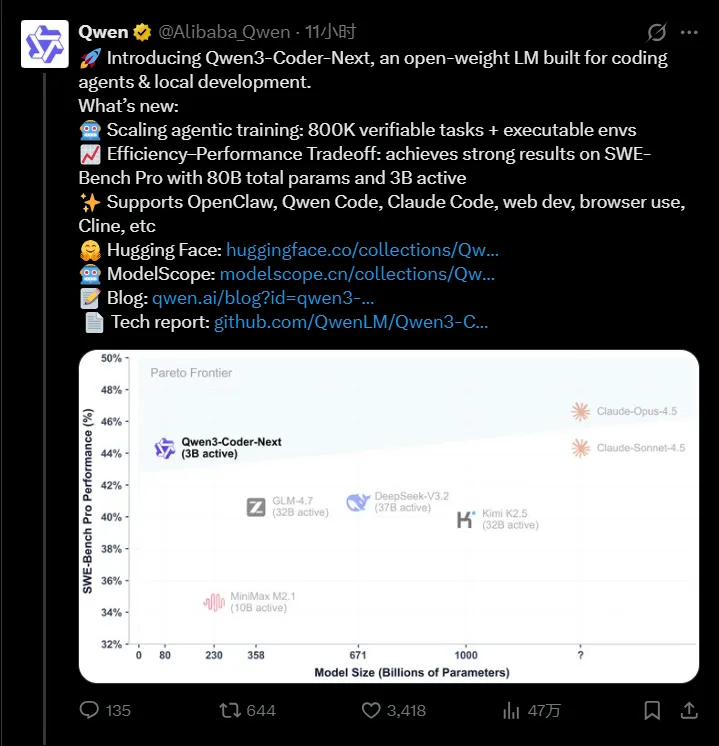
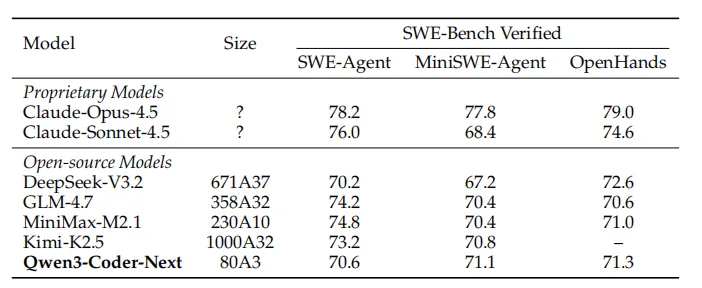
让人最感到最震撼的地方在于:一个激活参数只有 3B 的模型就可以做到 Claude Opus 4.5 这样顶级模型的水平。
在 Qwen团队同步公开的技术报告中给出了一个反行业直觉的结论:
“扩展智能体训练规模,而非仅仅扩大模型规模,才是提升现实世界编码智能体能力的关键驱动力。”
阿里Qwen团队用这款新作证明新的可能性:用极少激活参数的模型,一样可以有效应对现实世界软件工程的复杂性,推动 Agentic Coding 的普及。

先来看下成绩,在能力方面,令人印象深刻的有以下三点:
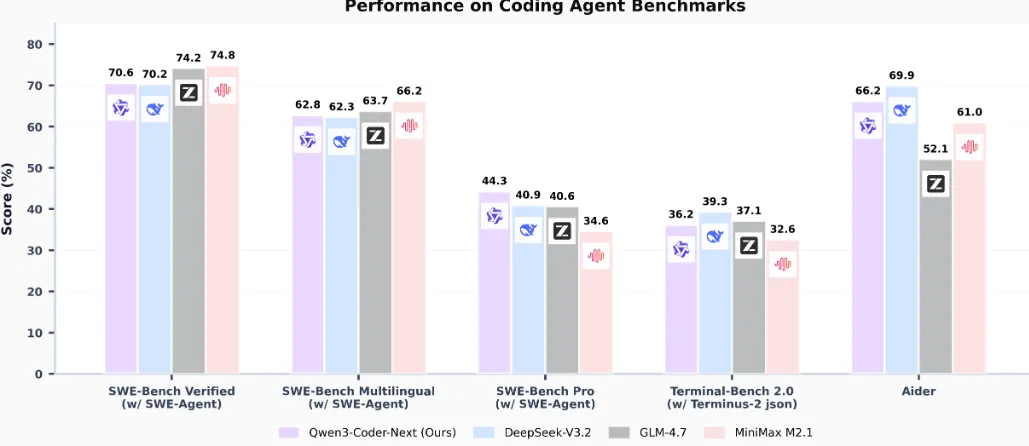

专为编程Agent、本地化开发设计
首先,一个很大的不同的是,阿里对于 Qwen3-Coder-Next 的定位。它是一款专为 Coding Agents 与本地化开发场景设计的开源模型。
这无疑也是 Coding 赛道日趋明显的发展趋势。
过去几天,如果你最近在关注 AI 编程,一定会有一种强烈的推背感。全球 AI Coding 赛道正在迅速升级到 Agentic 与“本地化”的赛点。
从Anthropic 的 Claude Code 的Task更新显著提升效率,再到上周大火的开源框架 OpenClaw,再到昨天凌晨 OpenAI 发布的桌面版 Codex App,主打的都是这两点。
对于编程智能体方面,Qwen 团队指出:
之前仅依赖静态“代码-文本对”数据的训练范式,已经无法满足现在的需求了。
这本质上仍只是一种“只读式教育”!
“现代编程智能体需要具备长时间跨度的推理能力,能够与真实执行环境交互,并在多步骤过程中从级联失败中恢复。”
现在的训练需求已经变成了:大规模、可验证、可执行且交互密集的训练信号。
而在本地化部署方面,80B的参数规模,仅用了 3B 参数激活,将极大地降低本地部署的成本。

代码模型训练范式的转变:扩展智能体训练
Qwen3-Coder-Next 的核心技术突破,在于智能体训练(agentic training)的可扩展性上。
过去,代码模型主要基于静态的“代码-文本对”进行训练,本质上是一种“只读式”教育。而 Qwen3-Coder-Next 则通过大规模的智能体训练流水线构建。
重点来了,想到“智能体训练扩展”这个方向并不难,难的是如何做到!
Qwen团队为了在中期训练与强化学习两个阶段同时扩展到大规模,攻克了两大核心挑战:
第一,需要一条可靠的任务合成流水线,能够生成可验证的任务,并配套完全可执行的环境。
第二,需要一套高吞吐的执行基础设施,可以并行运行海量任务,并高效返回环境反馈。
大规模任务合成方面,Qwen团队提出来两种互补的方法,用于生成带有可执行环境的可验证任务。
第一种:以真实软件工程问题为基础,通过挖掘 GitHub Pull Request(PR),并为其构建对应的可运行环境。
第二种:基于已有的开源数据集,这些数据集本身已提供可执行环境,我们在其基础上进一步合成新的任务实例。
注意,是将这两种方法结合起来,确保在保持一致的执行级验证机制下,实现大规模、多样化的任务生成。
值得注意的是,Qwen团队还引入了一种自动化检测机制,用于识别并过滤不可用的验证器,并训练了一个专用模型来提升环境构建质量,来缓解智能体的一个痼疾:容易出现利用表面验证捷径的失败模式。
此外,团队还引入了“质量保障智能体”,用以自动识别并移除语义模糊的任务、不一致的执行环境以及测试目标不匹配的样本。
经过这些工作,就可以得到一个基于最新的 GitHub 数据生成的、规模可观、环境以可复用 Docker 镜像形式存储的软件工程任务语料库。
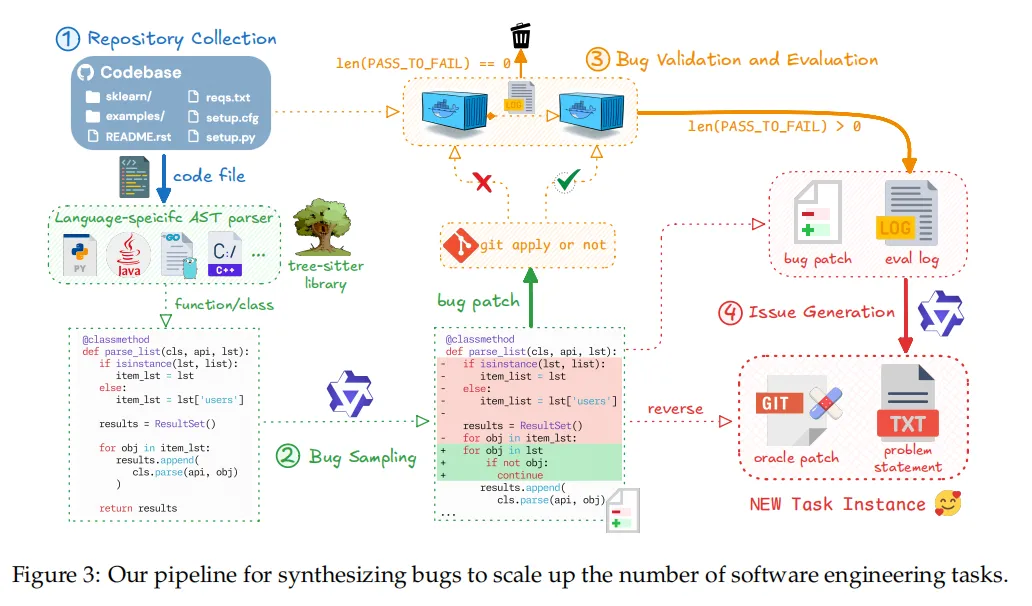
利用既有研究中积累的一批高质量的种子任务,Qwen 团队继续扩展并生成了一个规模更大、覆盖面更广的可验证软件工程问题集合。具体流程这里就不再赘述了。感兴趣的朋友可以仔细阅读技术报告。
传送门:
https://github.com/QwenLM/Qwen3-Coder/blob/main/qwen3_coder_next_tech_report.pdf
最终,该流程共生成约 80 万个可验证的软件工程任务实例,覆盖 9 种以上编程语言。

三阶段工作流:模型从环境中完成闭环式训练
基础设施方面,阿里内部开发了内部编排系统MegaFlow,用以支持大规模并行执行以及完全可复现的执行环境。
在 MegaFlow 中,每个智能体任务被建模为三阶段工作流:智能体 rollout、评估和后处理。在 rollout 阶段,模型需要与真实的容器化环境交互;如果生成的代码无法通过单元测试或导致容器崩溃,模型会在训练中途通过强化学习获得即时反馈。
这种“闭环式”训练方式,让模型学会从环境反馈中修正错误、实时迭代方案,而不仅仅是生成表面上“看起来合理”的代码。
有了高质量的模拟真实功臣任务的合成训练数据,加上强大高效的训练基础设施,Coder3-Coder-Next 才能取得如此成果。
架构核心突破:
解决超长上下文内存墙问题
再来看 Qwen3-Coder-Next 的另一个突破点:
提出了一套专为规避传统 Transformer 二次复杂度问题而设计的混合架构。
其实近两年,很多模型都宣称支持“超长上下文”,但平心而论,大多是只能说是“PPT 能力”。
真正的问题不在“能不能放进去”,而在于:算不算得动。
传统 Transformer 在长上下文的情况下会遭遇“内存墙”:计算成本是平方级爆炸的。看得越多,越慢,越贵。
而 Qwen3-Coder-Next 用了一套 Gated DeltaNet 与 Gated Attention 相结合的混合架构,把这个老问题绕开了:
Gated DeltaNet 处理长记忆:作为 softmax attention 的线性复杂度替代方案,使模型能够在 25 万 token 级别的上下文窗口中维持状态,而不会引入长时推理常见的指数级延迟。
Gated Attention 保留关键信息。
再叠加超稀疏 MoE:在理论上,相比参数规模相近的稠密模型,它在仓库级任务上的吞吐量可提升10 倍。
最终效果跑下来,一个 Agent 可以“读完”整个 Python 库或复杂的 JavaScript 框架,却只需 30 亿参数模型的响应速度,同时具备 800 亿参数系统级别的结构理解能力。
这对工程场景而言,可以称得上是一种质变。
此外,为避免训练过程中的上下文幻觉,团队还引入了 Best-Fit Packing(BFP) 策略,在保持效率的同时,规避了传统文档拼接方式中常见的截断误差。
安全能力,直接写进“肌肉记忆”
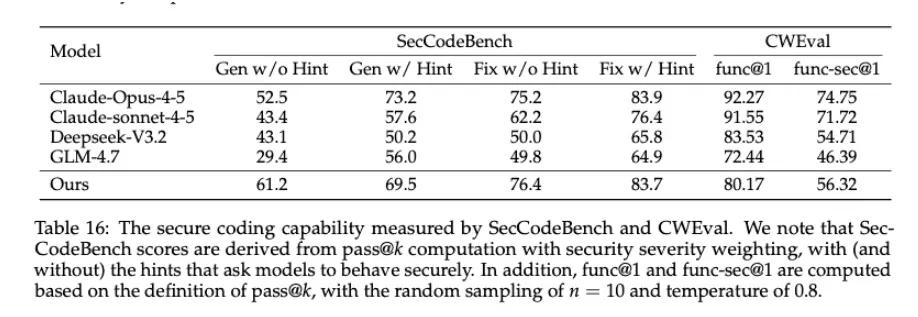
还有一点值得一提,很多编程模型的安全能力,本质是外挂规则。而 Qwen3-Coder-Next 在安全评测里的表现有点反直觉:
在没有任何安全提示的情况下,依然能主动修复漏洞
SecCodeBench 超过 Claude-Opus-4.5
原因很简单:它在训练时,就被反复惩罚过“跑不安全代码”的后果。
这是一种工程直觉,而不是规则背诵。
下一步:继续追赶顶级闭源,引入视觉能力
取得上述重大进展的同时,Qwen团队也坦承了相较于顶级闭源模型的局限性。
比如:因为采用了显著更小的激活参数和算力投入,虽然部署更加高效,但不可避免地带来了能力方面的权衡。
再比如,在指令遵循等方面,面对高度复杂、超大规模人软件工程任务时,仍有差距。团队计划在后续工作中,通过在预训练阶段引入更高难度、更贴近真实世界的软件项目,来逐步缩小这一差距。
此外,在部分复杂任务中,模型可能需要更多交互轮次才能收敛到正确解。对此,团队表示将进一步通过强化学习与更优的长时序规划机制来提升推理效率。
与此同时,前端与 UI 相关能力仍是一个有待加强的方向。
Qwen团队计划通过在未来的智能体模型中引入视觉能力,使模型能够直接评估渲染结果与交互行为,从而改善在前端与用户体验相关任务中的表现。
写在最后:训练范式从实验室转向生产环境
小编看来,Qwen3-Coder-Next 的发布的确挺意外的。它向业界释放了一个新的信号。
编程模型的训练方式,正在开启新的篇章。
Qwen3-Coder-Next 并没有延续过去两年“喂更多代码、猜补全”那一套,而是直接把模型丢进真实任务环境中:
一、80 万个真实 GitHub Bug 修复任务,每个任务都有可执行环境;
二、写完就跑,跑挂就修,修不好就继续学。
这也就意味着,模型在训练阶段,就已经经历过真实世界中常见故障,比如:测试失败、容器崩溃、环境报错等等。
这或许就是所谓的“失败本身也是有价值的”。
而就从这份“失败的价值”中,智能体编程模型真正学习到了一点:写出来的代码,是要负责的。
总之,以前那种“纯生成代码”的训练时代即将结束,接下来将是面向智能体行为的、面向现实工程任务的模型训练时代!
而面向智能体的模型训练,必然不可绕开是三个杠杆:长上下文、吞吐量、真实环境训练。
Qwen3-Coder-Next 很好的意识并解决了这些问题:
能够在几秒内处理代码库中的 262k 个 token 并在 Docker 容器中验证自身工作的模型,
这一点可以说是与其他模型真正拉开差距的地方,也是阿里Qwen团队不按常理丢出的一张牌。
更重要的是,这也是“开源模型代表”提出的一种新的面向智能体的 Scaling Law!
参考链接:
https://qwen.ai/blog?id=qwen3-coder-next
https://x.com/Alibaba_Qwen/status/2018718453570707465
https://venturebeat.com/technology/qwen3-coder-next-offers-vibe-coders-a-powerful-open-source-ultra-sparse