「Python 时间序列预测」从统计学、机器学习单变量单步预测模型到循环神经网络与时空图神经网络
👇扫码关注Python深度学习&图神经网络&物理信息神经网络专项学习群👇
👇免费加群,每周都有【Python深度学习】免费公开课程👇
| 微信(ILoveHF2016) | QQ(1061241906) |
| |
经过一段时间的准备,并根据本公众号关于时间序列预测问题的相关总结,我们开发了专门用于处理时间序列预测问题的自动化平台--TSNexus (Python) V1.0.0,支持统计学、机器学习以及深度学习(RNN\LSTM\GRU\Transformer\GNN等)等多种模型的训练、推理和评估,提供统一的接口和配置管理。
如果你正在学习时间序列预测相关的内容,大概都会经历一个阶段:从刚开始的 ARIMA、SVR、随机森林,后来开始写 RNN、LSTM,再后来接触 Transformer、TFT,直到有一天,你发现自己在复现 MTGNN、StemGNN 这类时空图神经网络。模型越来越复杂,但有一个问题一直没变——每多一个模型,就要重写一套数据处理、训练流程和评估逻辑。
这个项目,其实就是从这个痛点出发的。我想做的不是“又一个模型 demo”,而是一个统一的时间序列预测实验框架:不管你用的是统计模型、传统机器学习、循环神经网络,还是时空图神经网络,都能在同一个项目里,用同一种方式跑起来、对比起来、复现起来。
命令行驱动 + 自动化的时间序列预测框架
整个项目从一开始就是围绕实验流程来设计的。你只需要在命令行里告诉它三件事:数据在哪、用什么模型、用哪份配置。
例如,如何进行单个模型的测试:
# 训练 ARIMA 模型
python -m tsf.cli run --data data/TestData_00.pkl --model arima --config configs/model/arima.yaml
# 训练 SVR 模型
python -m tsf.cli run --data data/TestData_00.pkl --model svr --config configs/model/svr.yaml
# 训练随机森林模型
python -m tsf.cli run --data data/TestData_00.pkl --model rf --config configs/model/rf.yaml
# 训练 MTGNN 模型
python -m tsf.cli run --data data/TestData_00.pkl --model mtgnn --config configs/model/mtgnn.yaml
# 训练 StemGNN 模型
python -m tsf.cli run --data data/TestData_00.pkl --model stemgnn --config configs/model/stemgnn.yaml
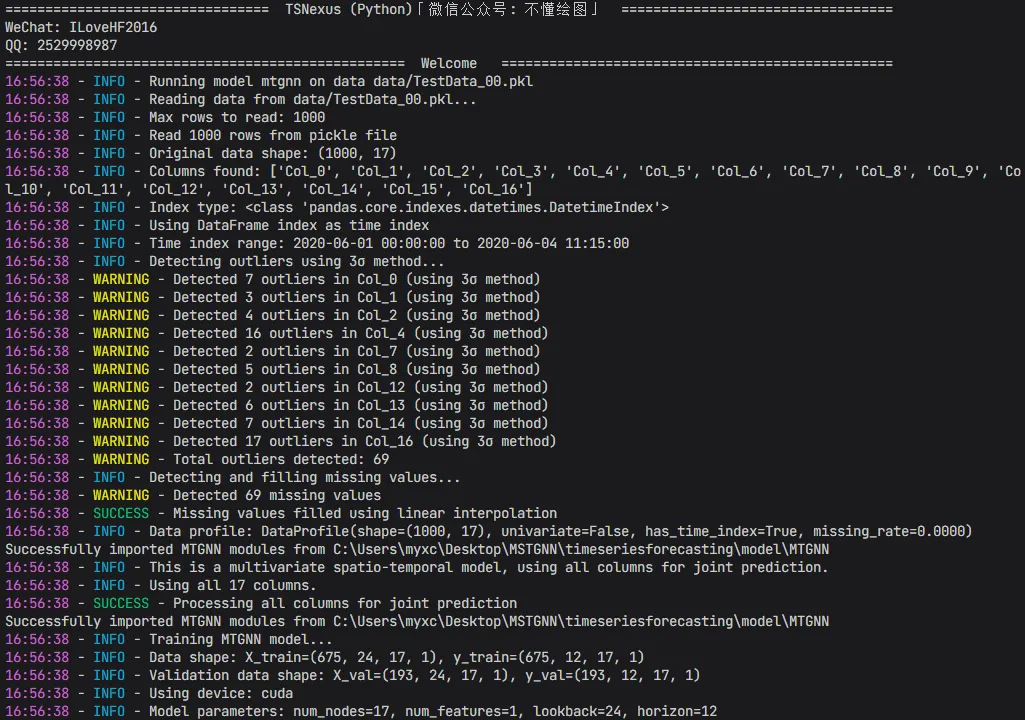
剩下的事情——数据读取、格式判断、异常值处理、缺失值填充、特征构建、窗口切分、归一化、训练、预测、评估、结果保存——全部由框架自动完成。
数据不需要“规规矩矩”,框架会先替你“看懂它”
时间序列项目里最烦的一件事,其实不是模型,而是数据。
- CSV、Excel、Pickle、H5、NPZ,各种格式混在一起;
- 有的是单变量,有的是多变量,有的甚至已经是时空结构数据。
在这个项目里,数据不会直接被送进模型,而是先经过一整套自动检查与分析流程:
所有模型,都被包装成同一种“行为模式”
在这个框架里,ARIMA、SVR、随机森林、LSTM、GRU、MTGNN、StemGNN,看起来是完全不同的东西,但在系统内部,它们都遵循同一套逻辑:
给我数据 → 训练 → 预测 → 评估 → 输出结果
你不用关心某个模型内部是 statsmodels、scikit-learn 还是 PyTorch,更不用为外部源码单独写一套训练脚本。
尤其是 MTGNN 和 StemGNN 这种复杂模型,项目内通过 Adapter / Wrapper 的方式,把它们接入到统一框架里:
这样做的好处只有一个:这个项目以后还可以不断接新的模型,而不会越写越乱。
这是一个“会持续更新”的项目
目前,这个框架已经完整支持了:
接下来,我会在这个框架里持续加入新的模型类型:
同时,也会把这个项目作为一个教学与科研双用的工程案例,逐步拆解其中的设计思路、代码结构和工程取舍。
后续更新
这个项目目前还处在初步测试阶段,我会持续更新(模型会继续补齐 Transformer、TFT 的更完整支持,数据解析和图模型适配也会不断增强)。非常欢迎大家拿自己手头不同格式、不同结构的数据来“折腾”它:你越是用一些奇怪的文件、特殊的时间列、或者更复杂的多变量结构去跑(但是要遵循最基础的输入数据要求),越容易把隐藏的边界情况和 bug 暴露出来。
最后,如果你担心“框架是有了,但不知道怎么用、怎么调参、怎么做批量对比”,这块我也会配套做一套完整的视频课:从虚拟环境创建与深度学习环境配置部署开始,到数据读取与自动识别规则讲清楚;再到每一个模型的调用方式、关键参数含义、调参策略与常见坑;最后把批量化测试(sweep/commands 实验清单)怎么写、怎么复现实验、怎么汇总对比指标这一整条链路都走一遍。目标不是让你看懂代码,而是让你能直接把它当成自己的实验底座,用最少的学习成本跑出一套干净的对比结果。
👇扫码关注Python深度学习&图神经网络&物理信息神经网络专项学习群👇
👇免费加群,每周都有【Python深度学习】免费公开课程👇
| 微信(ILoveHF2016) | QQ(1061241906) |
| |