Python学习【125】:以python的视角看哈希的本质:从密码学到大数据存储的同一把钥匙
Python学习
一、学前花絮
我们之前的文章提到了hash算法,而我们在不同的领域都能够看到hash。比如前面提到的加密算法中用到哈希,在大数据基础组件HDFS分布式文件系统和HBASE列存数据库中也用到了hash。二、Python的视角看hash:从密码学到大数据存储
2.1 一个震撼的事实:密码学和大数据用的是同一套哈希函数
- 在大数据里:决定HBase的RowKey存在哪个Region,计算HDFS数据块的校验和
- 在大数据里:Cassandra的一致性哈希、CDH发行版的校验文件
- 在大数据里:HBase的RowKey哈希、Redis集群分片
关键洞察:不是“哈希函数家族分为密码类和大数据类”,而是“同一类数学工具,根据不同的安全需求,选择了不同的参数”。2.2 哈希的本质:三个层次的“压缩”哲学
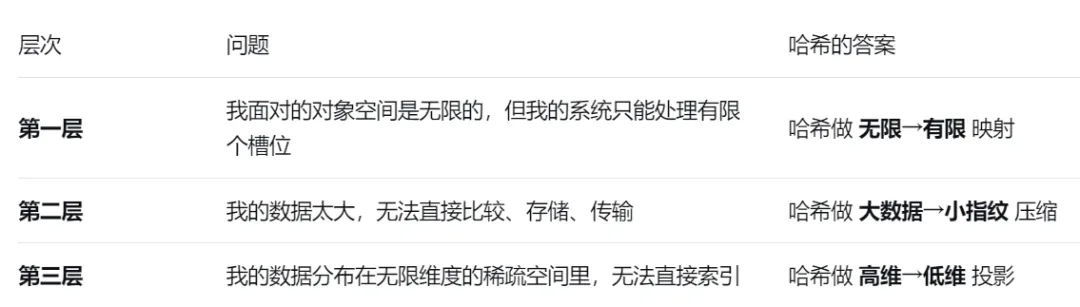
要理解哈希为什么能横跨两大领域,必须拆解它的本质——哈希的本质是“压缩”,但这个“压缩”有三个层次,每一层对应一类应用场景。- 输入空间:无限大(任意长度的字符串、文件、数据流)
- 输出空间:有限小(160位、256位、32位整数)
无论你用哈希做什么,第一步永远是“把无限世界的任意对象,压缩成有限编号空间的某一个点”。就像全中国14亿人,每个人都有一个身份证号——18位数字有限,但足够标识所有人。这就是哈希能同时服务密码学和大数据的根本原因:两个领域都需要处理“无限世界里的有限标识”。这个压缩是单向的——你可以从电影算出32字节指纹,但无法从指纹还原电影。两个领域的共同需求:我们需要一种方法,把巨大的、可变长度的数据,变成小巧的、固定长度的、可比较的、可索引的摘要。这是哈希最抽象、也最强大的本质。它压缩的不是数据体积,而是数据的“可能性空间维度”。- 你要找一份文件,必须在所有可能的文件名这个无限高维空间里遍历
- 你要存一个键值对,必须在所有可能的键这个无限集合里维护索引
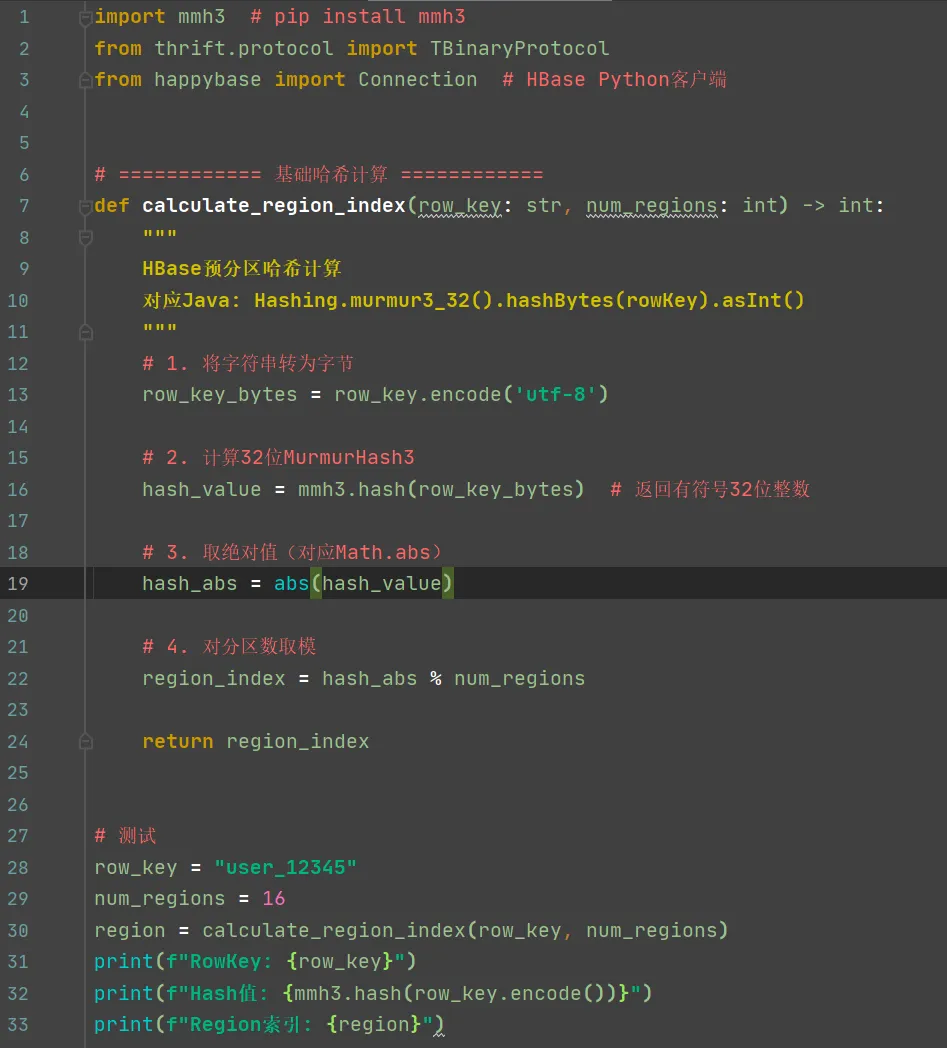
- RowKey → Region编号(HBase分区)
- 密码学噩梦:攻击者在无限空间里寻找碰撞——哈希把无限压缩成有限,让碰撞概率足够低
- 大数据噩梦:数据在无限空间里稀疏分布——哈希把无限压缩成有限,让索引和路由成为可能
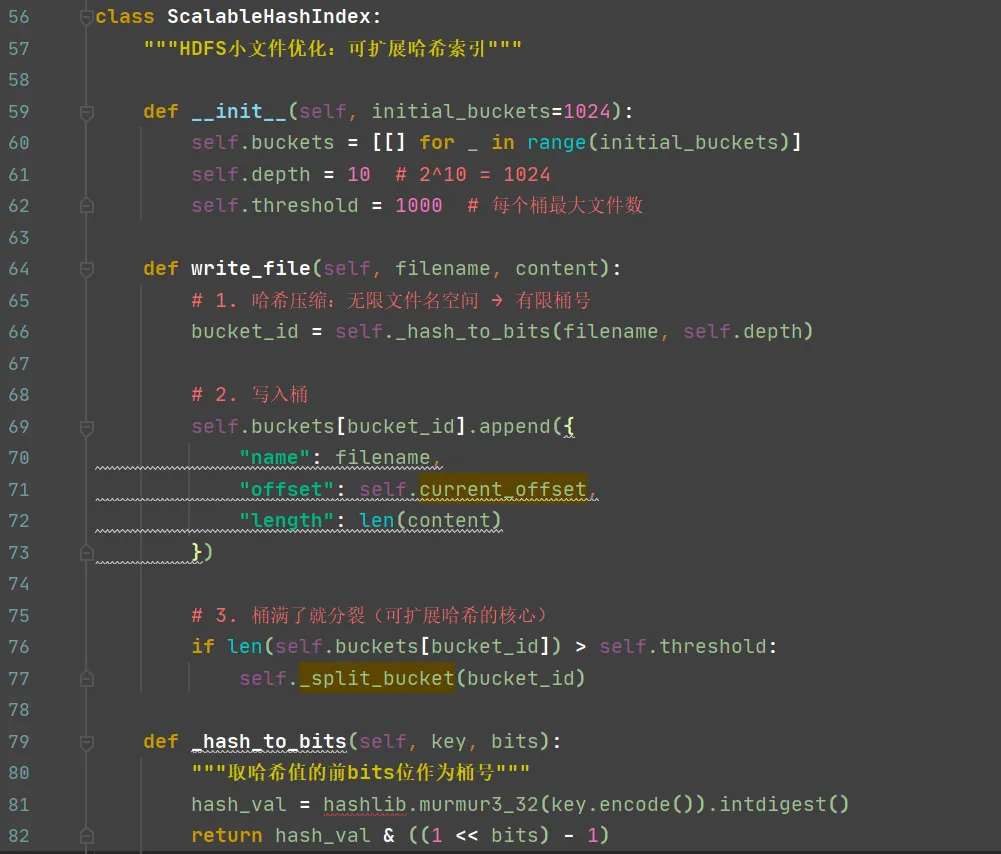
2.3 哈希在HBase/HDFS中的具体应用:压缩本质的三种体现
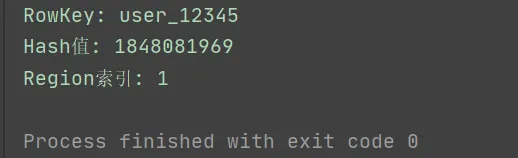
应用一:数据分布——把无限RowKey压缩成有限Region
HBase的核心问题:RowKey是字符串,可以是任意值——“user_0001”、“2026-02-11_log”、“photo_12345.jpg”。这是一个无限稀疏的空间。- HBase的Region数量是有限的(几十到几千)
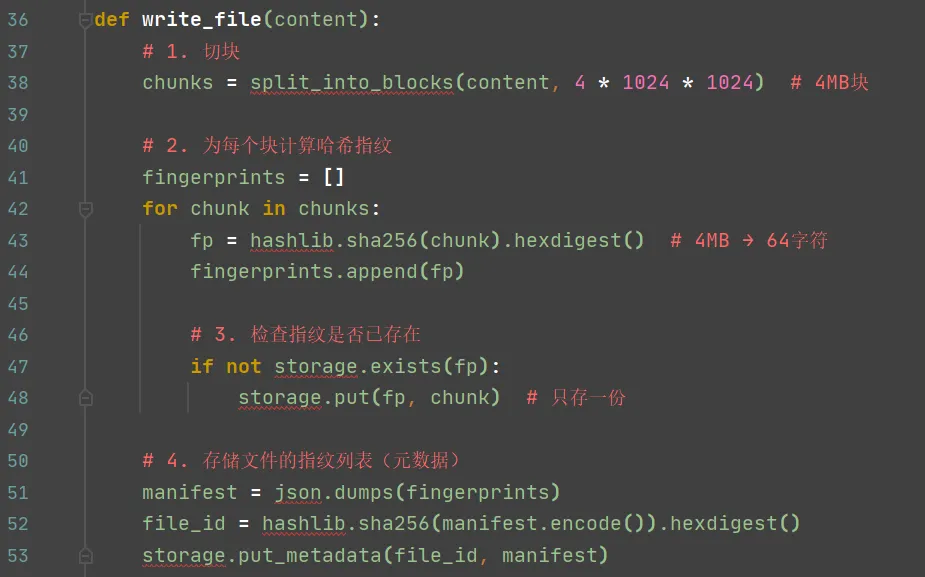
应用二:数据去重——把大文件块压缩成小指纹
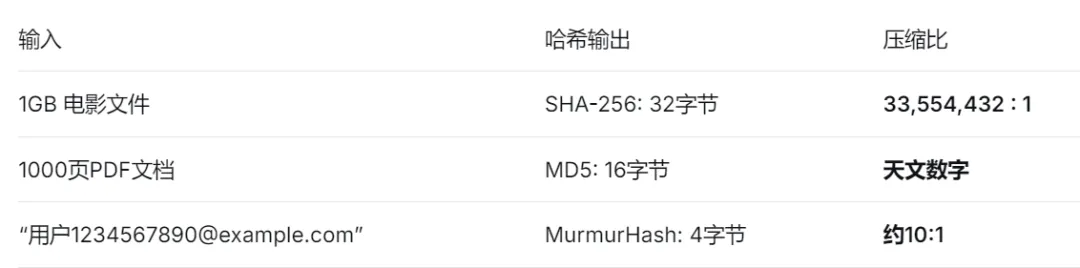
HDFS/对象存储的核心问题:多个用户上传同一个文件,或者同一文件的不同版本。直接存储造成巨大的空间浪费。- 4MB数据块 → 32字节哈希指纹(压缩比131,072:1)
应用三:元数据索引——把高维稀疏命名空间压缩成低维稠密桶
HDFS NameNode的核心问题:10亿个小文件,每个文件名是几十字节的字符串。在无限维度的文件名空间里维护索引,内存爆炸。- 文件名空间是高维稀疏的——每个字符串都是一个维度,绝大部分维度值为0
- 桶编号空间是低维稠密的——0~1023,每个数字都被使用
- 哈希函数把高维稀疏向量(文件名)压缩成低维稠密标量(桶号)
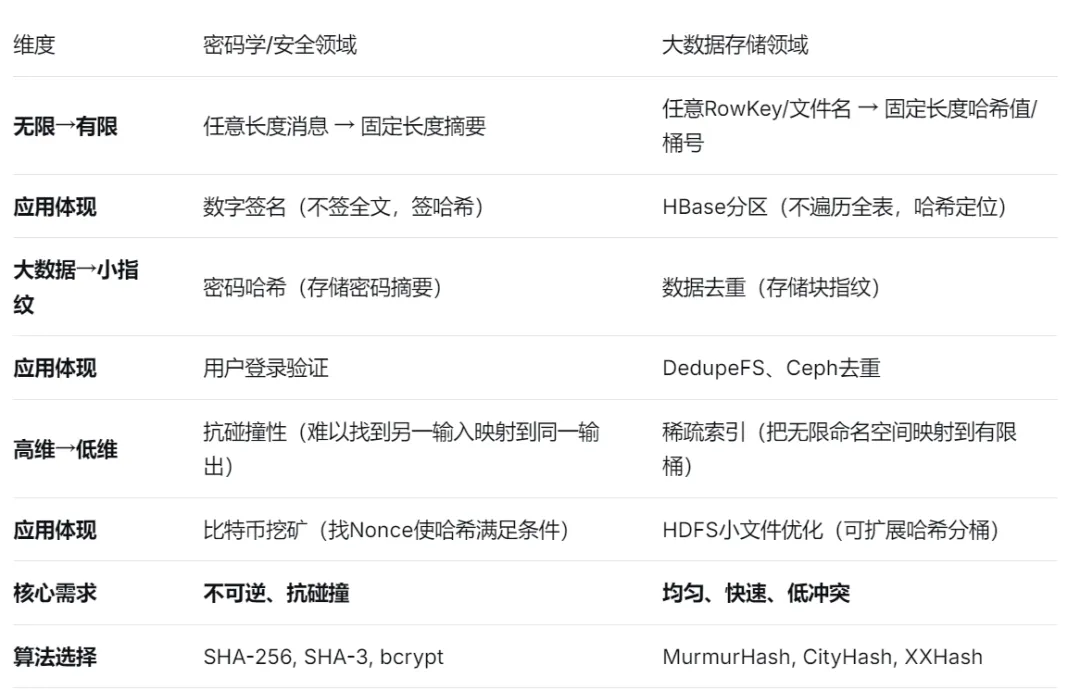
2.4 对比表格:同一本质,两个战场
2.5 最深刻的洞察:哈希是“降维打击”的数学化身
因为密码学和大数据存储,本质上面对的是同一个数学困境:我们活在一个无限维度的世界里,却只有有限维度的工具。哈希不是两个领域的工具,它是两个领域共同的“降维打击”武器:哈希函数,就是那个把“无限”压缩成“有限”,把“高维”投影到“低维”,把“大数据”凝练成“小指纹”的数学魔法。它在密码学里叫“摘要”——因为你把整个消息的精华压缩成一滴;它在大数据里叫“分布”——因为你把整个数据空间的坐标压缩成一个点。2.6 给开发者的终极理解框架
我们遇到哈希,无论它用在哪个领域,都可以用这个三维框架来定位:HBASE/HDFS用哈希,用的是第一层和第三层;2.7 以上内容的总结
哈希从来没有分裂成“密码学哈希”和“大数据哈希”。它一直是那个从无限中抓取有限,从混沌中建立秩序,从巨大中提取精华的数学工具。这是哈希最迷人的地方,也是它最强大的地方:一个数学思想,征服了两个世界。三、小结
本文针对哈希(hash)算法进行了深入的分析,我们了解到哈希本质上是一种数学思想。只不过可以用于加密和分布式存储两个完全不同的技术领域。简单理解一个加减乘除的数学公式是不分行业的,都可以应用,尽管哈希算法要比这个例子复杂很多,但本质上是一样的。