Linux服务器卡顿时,这六步就能找到罪魁祸首,新手建议收藏!
- 2026-06-25 23:33:33
今天分享一下Linux服务器卡顿了如何排查,这是运维新手的必修课,建议认真读完,建立整个排查思路非常重要。
生产环境验证过的 Linux 卡顿六步定位法:系统负载--》CPU--》内存--》磁盘IO--》磁盘空间--》网络
排查之前,自己心里必须现有一个模型。Linux 性能,本质上是由CPU,内存,磁盘IO,磁盘空间,网络五种资源决定,所有卡顿,必然来自其中一个,所以排查时就只需要一层层排查,很快就能找到问题。
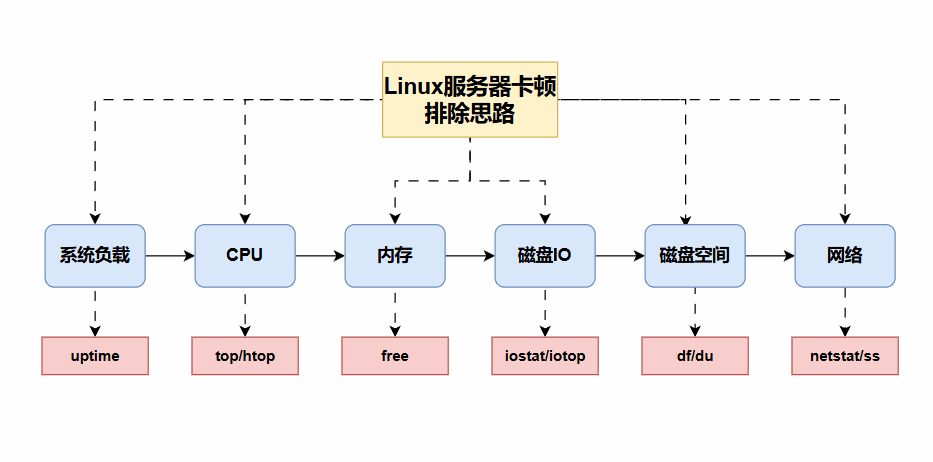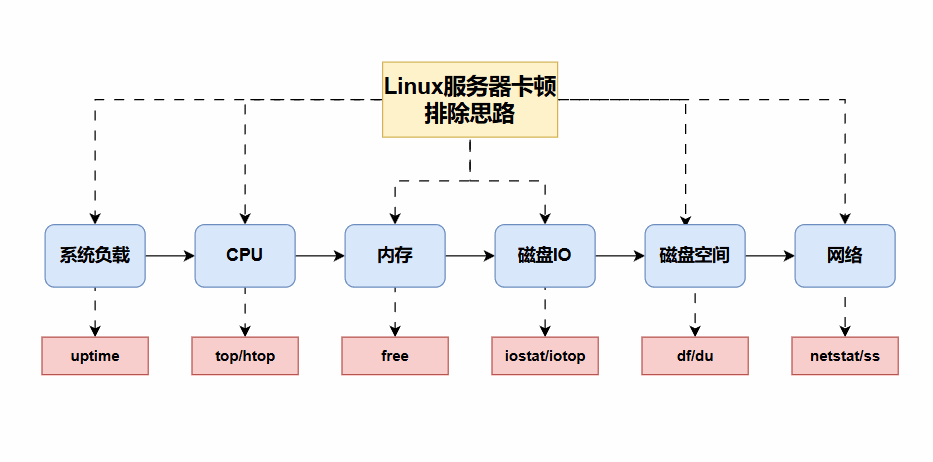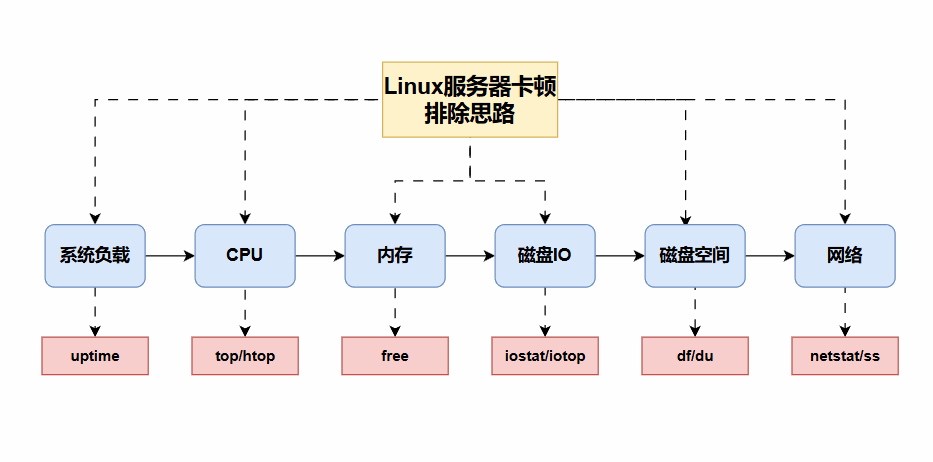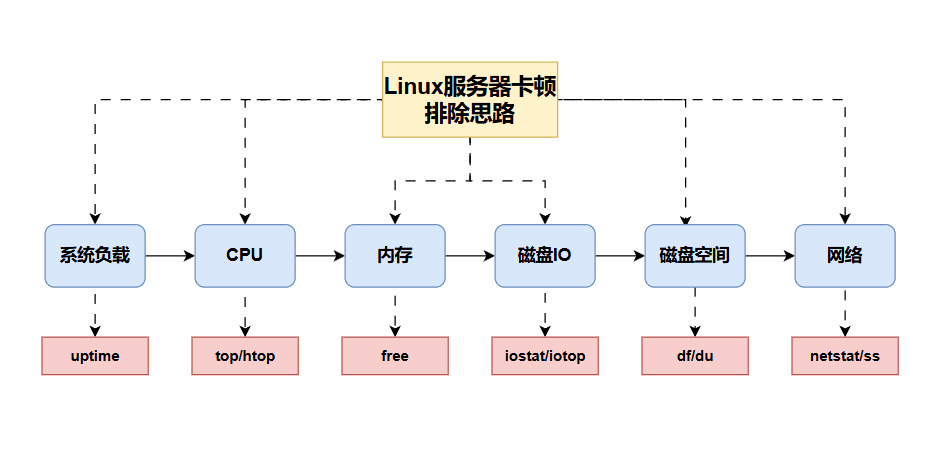
1 先看 Load
如果遇到系统卡顿,第一就应该想到系统负载
uptime
输出有三个值,分别是过去1分钟,5分钟,15分钟平均负载情况。
负载Load 表示:
正在运行 + 等待 CPU + 等待 IO 的进程数
它反映的是:系统排队程度,但它不是CPU使用率,别搞错了。
如何判断异常?
假设服务器有 4 核CPU:
Load < 4 :表示正常 Load ≈ 4 :系统有点压力 Load >> 4 :系统拥堵
如果 Load 不高,系统整体资源没问题。你需要查的是应用层和网络的问题。
如果 Load 很高,说明资源出现瓶颈。接下来就需要判断是CPU还是IO有问题。
2 查看CPU情况
CPU一般用top命令查看,也可以用htop
top需要关注4 个指标:
us 用户态 sy 内核态 id 空闲 wa IO等待
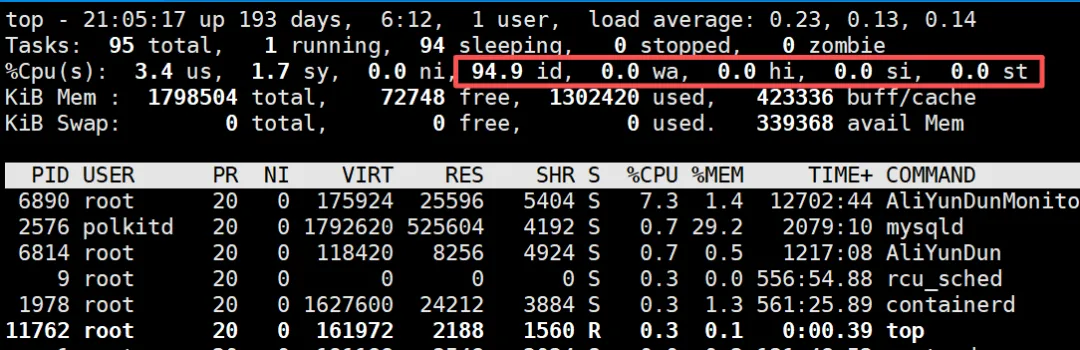
情况 1:CPU 打满
如果出现下面这些数字
us 95%id 1%wa 0%这是算力不足。这种情况其实不多见。
记住不要去看%CPU这个值,这个值的百分比并不能实际体现CPU使用情况,需要看机器配置是多少的。
情况 2:CPU 很闲,但 Load 很高
us 15%id 50%wa 35%注意:如果wa 很高。
这说明:进程在等磁盘。
这种情况,占生产环境卡顿的 60% 以上。
判断磁盘 IO
执行:
iostat -x 1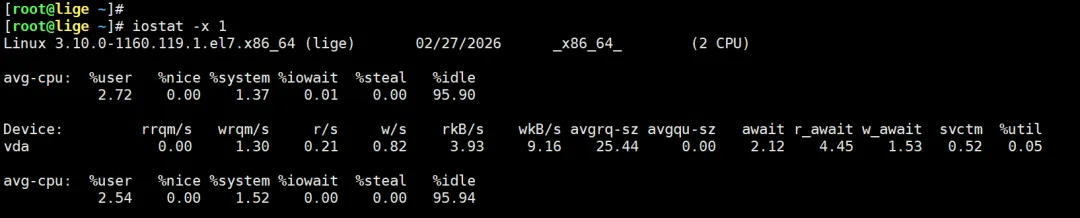 重点看两个指标:
重点看两个指标:
%util await
判断逻辑
正常 SSD:1~5ms
如果 100ms 以上,系统一定卡。
接下来找是谁刷盘:判断哪个程序在占用IO
iotop
有可能是下面这些情况:
日志疯狂写入 数据库 checkpoint Docker overlay2 程序死循环写文件
4 内存抖动
这种算是隐形杀手,偶尔也会遇到
vmstat 1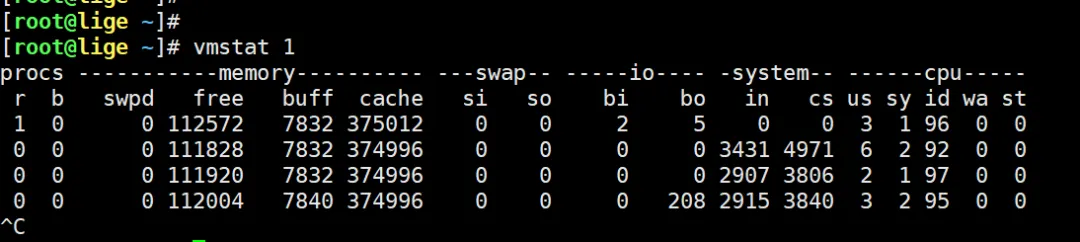 重点关注:
重点关注:
si so
如果持续 > 0。说明系统在交换内存。这叫内存抖动。
可能表现为CPU不高,但是机器卡,响应慢。
5 磁盘空间写满
还有可能是磁盘满了,导致一些业务异常或堵塞,服务器卡死之类的。
df -hdf -i满了就及时处理就行了。
6 别忽略网络
还有可能是网络问题,一般表现SSH卡,web慢,ping正常但访问慢之类。
ss -s如果连接数暴涨。
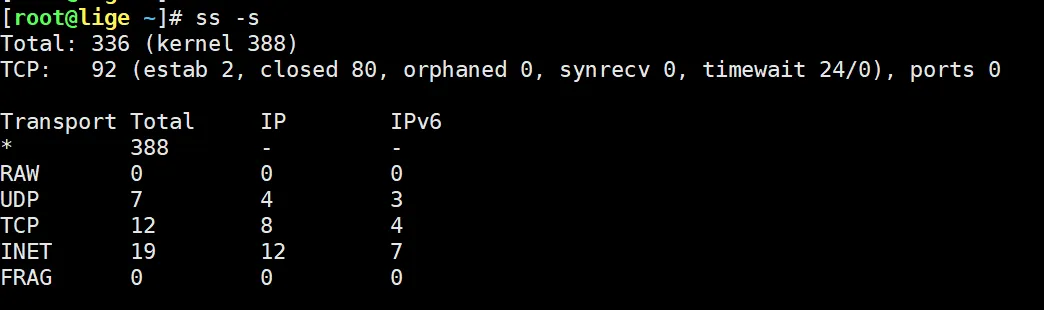
或者:
netstat -s | grep retrans出现大量重传,说明网络异常。
如果你掌握了上面几个命令和参数,基本可以判断那么的Linux卡在哪一步。
如果有错漏,敬请斧正!如果觉得有用,帮忙点点赞和关注一下!

END

关注我,后台回复【666】获取海量Linux运维资料包,资料持续更新!
如果需要提供技术支持或添加交流群,加V:lige_linux
往期推荐
1 | |
2 | |
3 |
4 | |
5 | |
6 |
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 我用Python接了个私单,赚了200块,亏了三天觉
- 【Python课程学习资料】Python语言基础与应用课程学习(含数据类型+计算与控制流+高级特性等)
- 春招学考社团_python专题_zt3_斐波那契数列.py
- 我用Python算了一笔账,发现自己月薪4千还不敢辞职的原因
- 6python之服务器报错处理及测试completion
- Python:上下文管理协议
- Supabase Python 客户端库新手入门:快速上手数据库开发
- 【小沐学Python】Python扩展类型(三)
- Linux进阶 | Nginx 服务安装与配置(二):安装与目录结构详解
- 深入解析 Linux 内核 8250 串口驱动(8250_port.c):功能实现与设计理念
