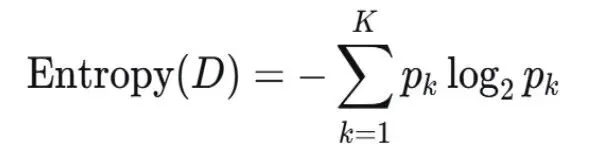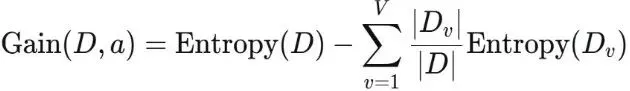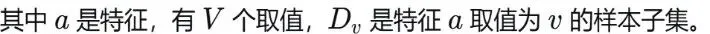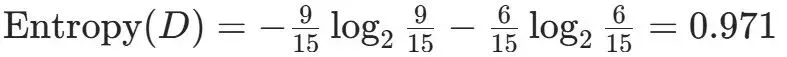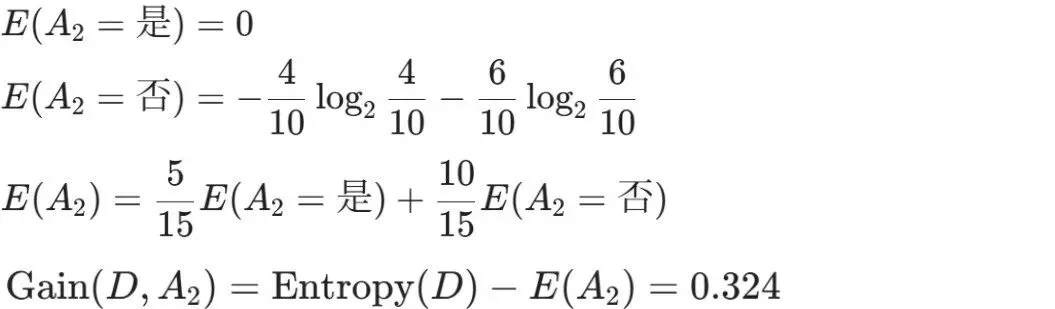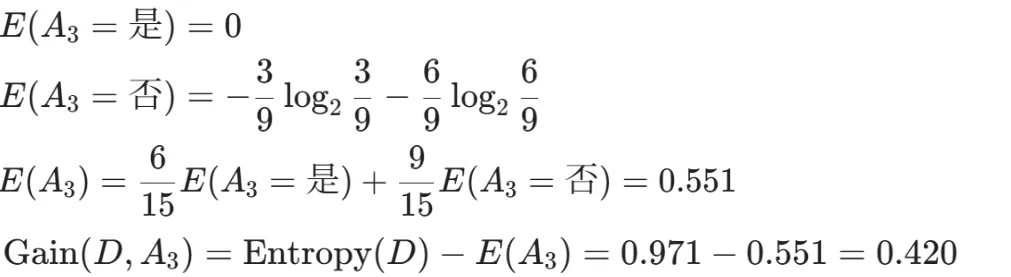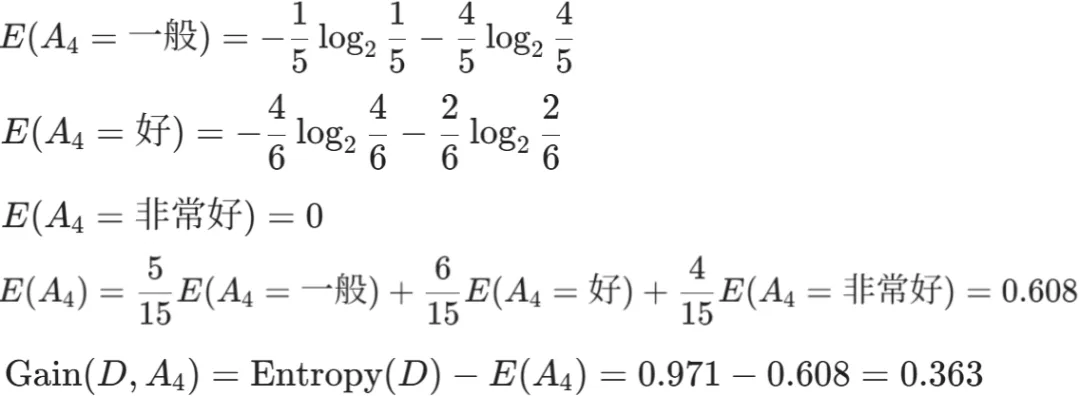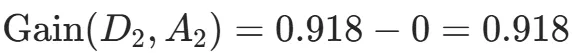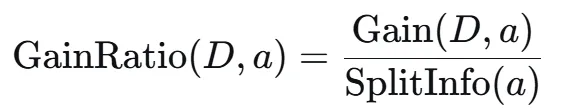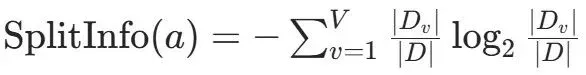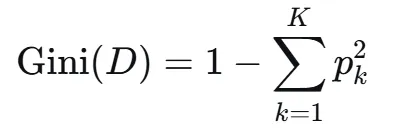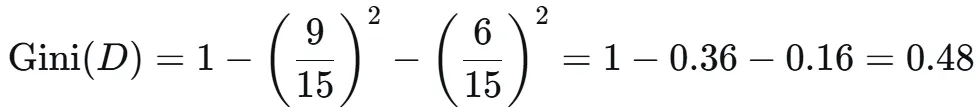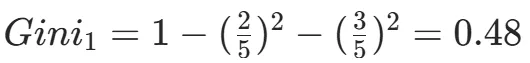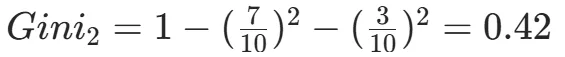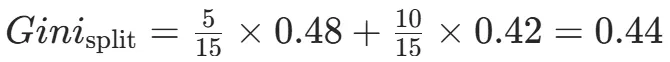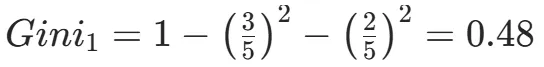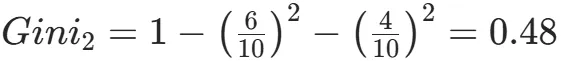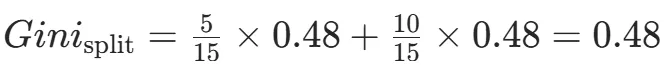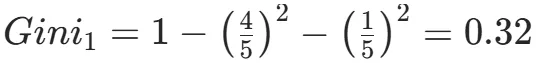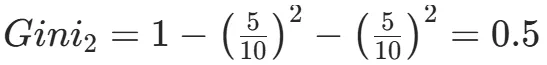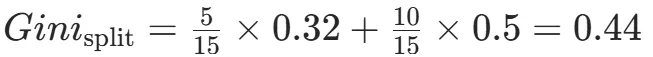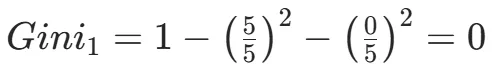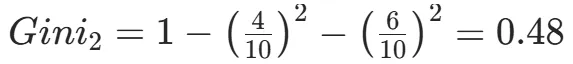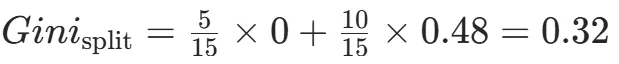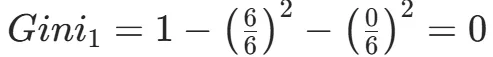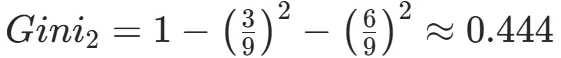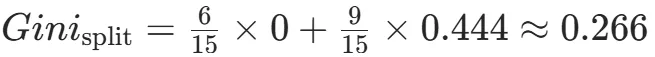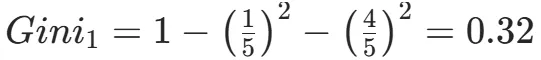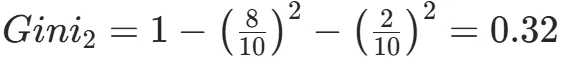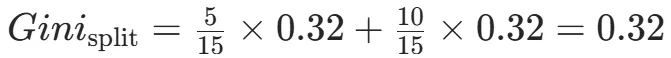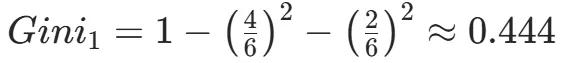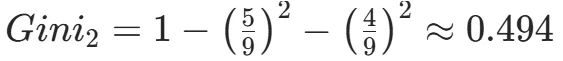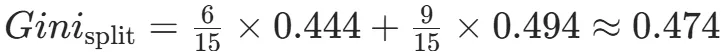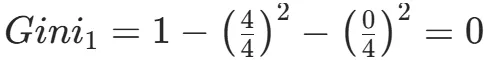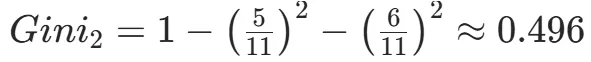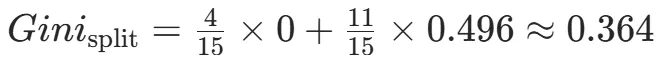朋友们,大家好,我是小静。
公众号很久没有更新了,因为近几个月一直在实习。之前一直在更新SQL系列,想学习SQL的朋友可以暂时先阅读之前的文章,基本可以应对日常工作。接下来我准备更新一些机器学习中的经典算法,先从树模型进行更新。
在机器学习算法家族中,有一个模型既古老又现代,既简单又强大——它就是决策树。从金融风控的信用评估,到医疗诊断的辅助决策;从电商推荐的用户分层,到工业质检的缺陷识别——决策树以其可解释性强、无需特征缩放、能处理混合类型数据等独特优势,成为无数AI解决方案的基石。
今天这篇文章中,将从核心思想到三大经典算法的详细讲解,再到鸢尾花数据集的python完整实战,一起完成决策树的学习,文章中附有案例的完整代码,感兴趣的朋友不妨亲自实践一下。
决策树的核心思想
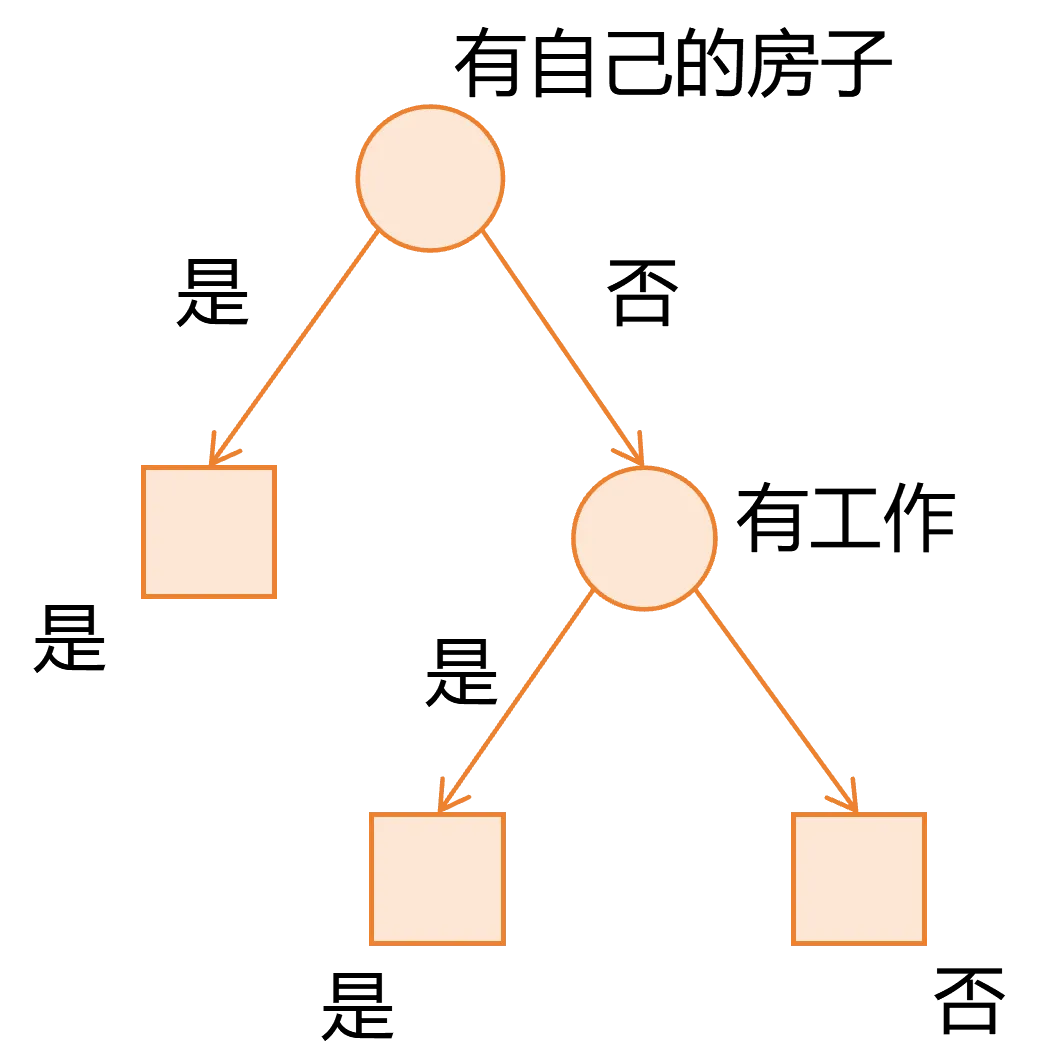
想象一下你决定是否去户外打高尔夫球的过程:
这个层层递进的判断流程,天然形成了一棵树:每个内部节点是一个条件判断,每个分支是判断结果,每个叶子节点是最终决策。
决策树算法正是模仿了这种人类的决策思维:
以全部训练数据为根节点,每一步选择一个“最优特征”对数据进行划分;在划分后的子节点上递归执行“选最优特征-划分数据”的操作;直到满足停止条件,比如所有样本属于同一类别、特征用尽、树深度达到预设值、样本数少于阈值等,停止递归并将最终子节点设为叶节点。
决策树的核心难题——如何定义“最优特征”,即如何进行特征选择。
不同的算法采用了不同的度量标准进行特征选择,这也造就了ID3、C4.5、CART三大经典算法。
三大经典算法
这里介绍核心思想和简单的公式,若想对原理公式详细了解,可以阅读李航老师的《统计学习方法》第二版。| ID3算法:信息增益最大化
ID3(Iterative Dichotomiser 3)算法是使用信息增益作为特征选择准则,信息增益衡量的是划分前后数据集纯度的提升程度。- 信息熵:衡量一个系统的混乱程度,即不纯度的度量,公式为
Entropy(D)的值越大代表该节点中D的混乱程度越高,纯度越低。- 信息增益:数据集D划分前后的信息熵的变化,这一差值称为“信息增益”,公式为
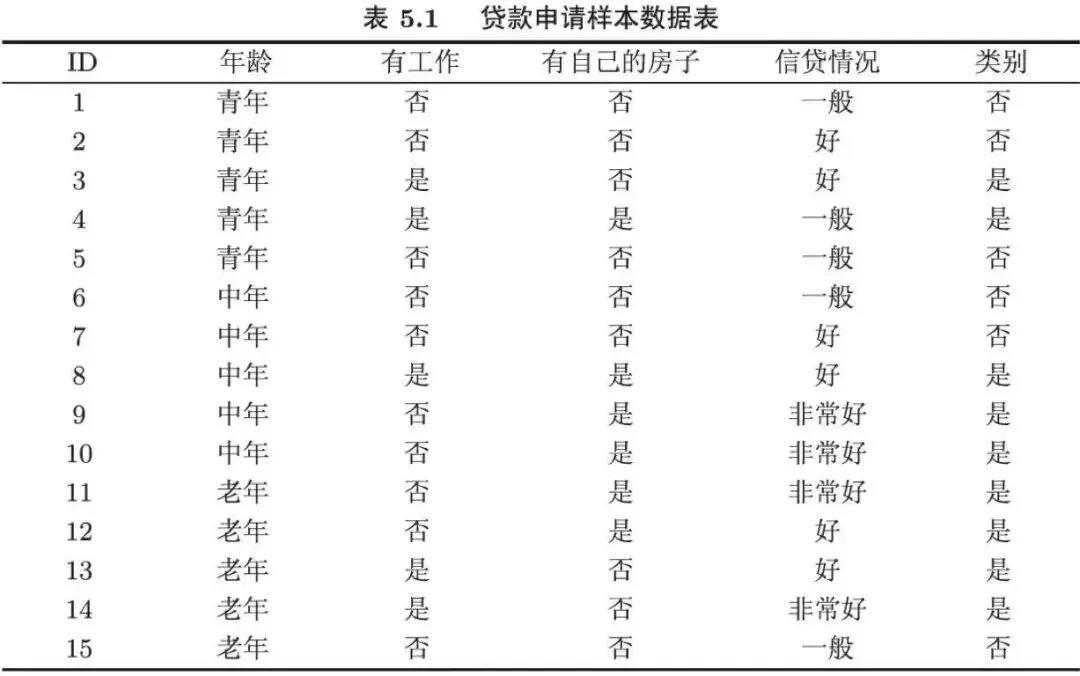
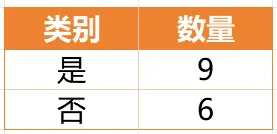
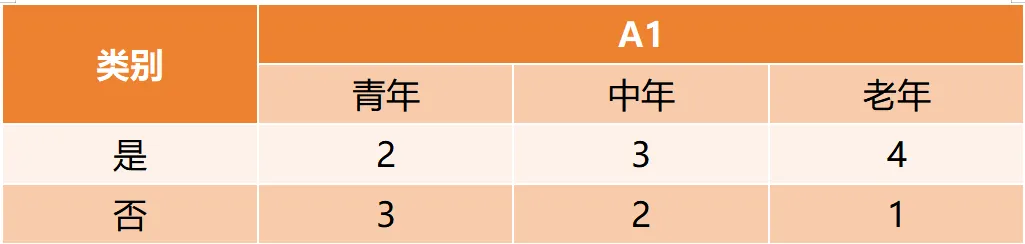
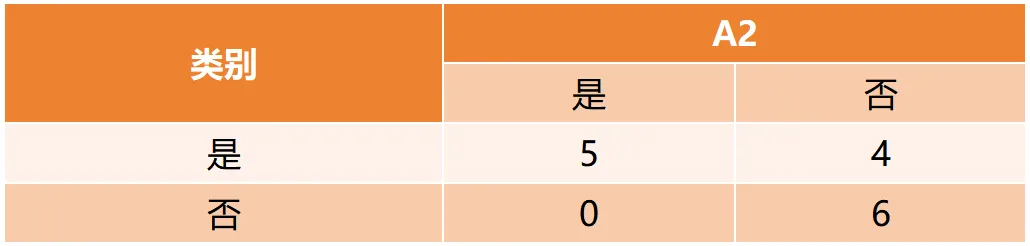
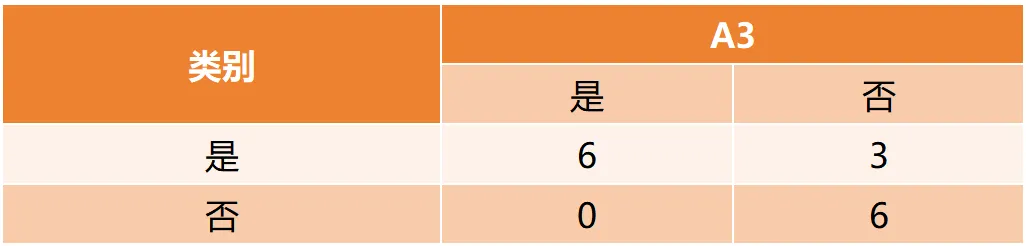
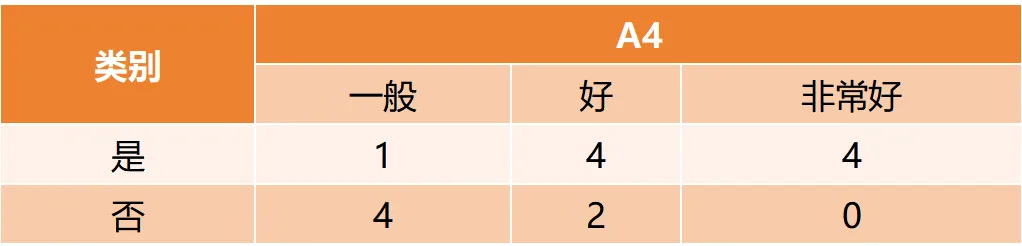
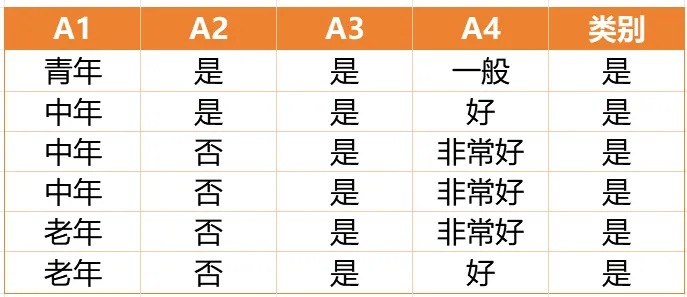
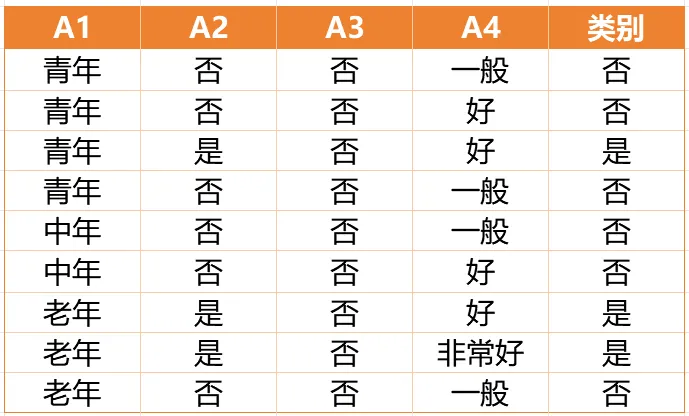
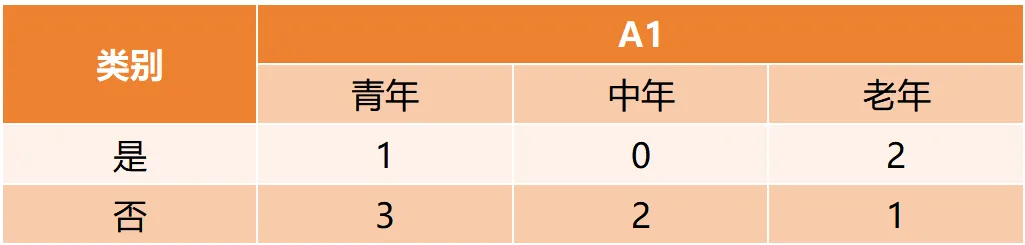
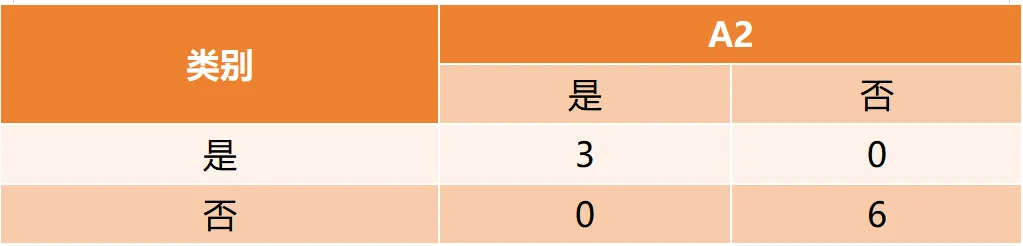
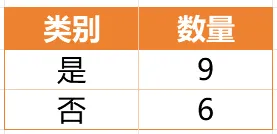
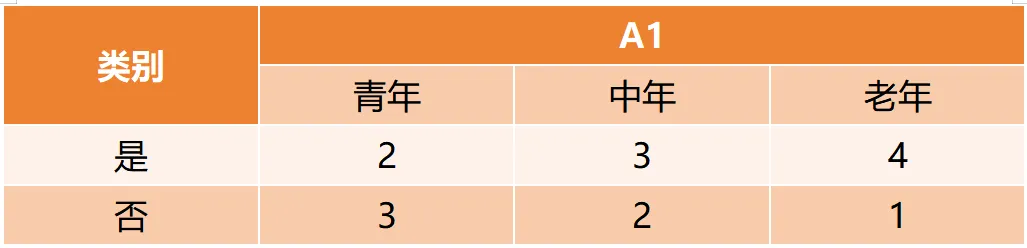
Gain(D,a)越大,表示通过该特征划分数据集后所带来的整体的信息熵下降程度越大,也就是数据集纯度的越大。所以ID3算法选择信息增益最大的特征作为当前节点的分裂特征。ID3算法使用信息增益来度量该特征的分类能力,信息增益越大,使用该特征划分数据集后的纯度提升程度越大,说明该特征的分类能力越强。这里以李航老师的《统计学习方法》第二版中的贷款申请样本数据集为例进行演算。自变量是贷款申请人的4个特征,因变量是类别列,即是否同意贷款。这里用A1表示年龄,A2表示有工作,A3表示有自己的房子,A4表示信贷情况。由上可知,Gain(D,A3)>Gain(D,A4)>Gain(D,A2)>Gain(D,A1),所以选择A3作为最优特征。选择A3作为根节点特征后,数据集D被拆分为两个子集D1和D2。由上可知,该子集的类别均为“是”,无需进一步划分。针对数据集D2,由于最终的类别并不唯一,可在A1、A2和A4中进一步选择信息增益最大的特征进行拆分。由上可知,Gain(D2,A2)>Gain(D2,A4)>Gain(D2,A1),所以选择A2进行进一步划分。当A2=“是”时,类别均为“是”,所以该节点是一个叶节点;当A2=“否”时,类别均为“否”,故该节点也是一个叶节点。偏好取值多的特征。因为该特征取值越多,信息增益容易偏大。若将ID作为一个特征,则产生与样本量相同的数据子集,且每个子集仅有一个数据,不纯度为0,信息增益最大化。为了避免这一问题,提出了C4.5算法。| C4.5算法:信息增益率最大化
C4.5是ID3的改进版,使用信息增益率来克服对多值特征的偏好,并引入连续特征处理、缺失值处理和剪枝。其中,SplitInfo(a)为分裂信息,衡量特征取值分散程度。生成多叉树,通过二分法离散化以支持连续特征,可处理缺失值,引入后剪枝。| CART算法:基尼指数最小化
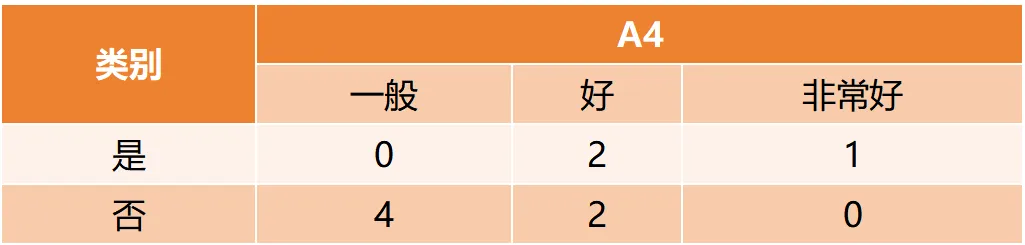
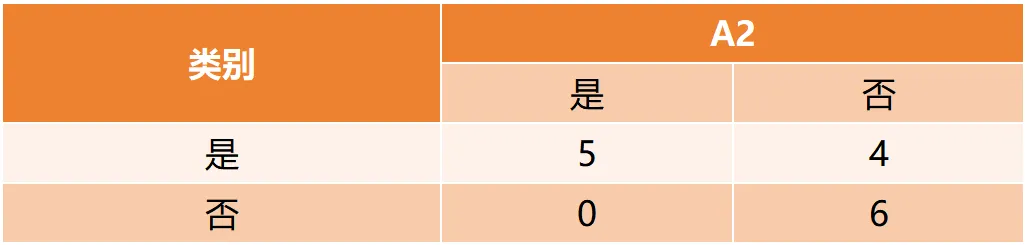
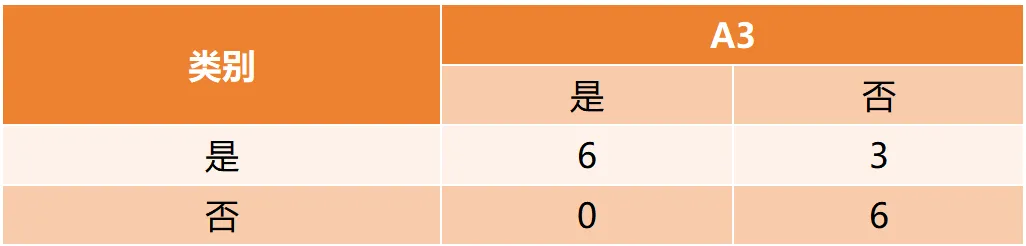
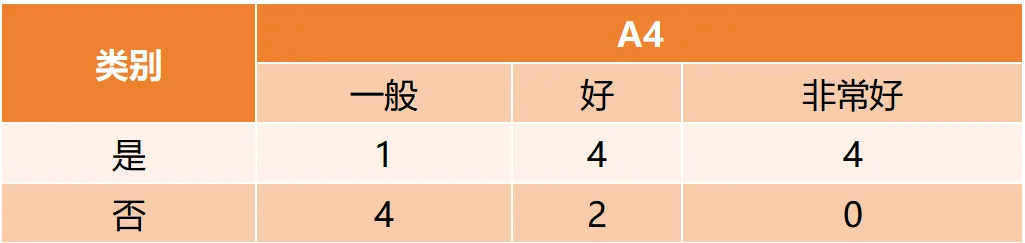
CART(Classification and Regression Tree)由Breiman等人在1984年提出,对分类树使用基尼指数最小化准则,对回归树使用均方误差最小化作为划分准则,且生成的是二叉树。基尼指数值越大,样本集合的不确定性越大,这⼀点与熵相似。若所有样本均属于同一个类别,则基尼指数为0。当样本均匀分布在各个类别时,基尼指数最大,此时数据集的不纯度最高,不确定性最大。继续使用上述的贷款申请样本,用CART算法生成决策树。由于CART是二叉树结构,当变量有多个属性时需要合并成2个,因此年龄变量的属性共有3种二分方式。由上可知,年龄的最佳基尼为0.44,方式一和三均可。由上可知,信贷情况的最佳基尼为0.32,二分方式一最佳。总体来看,特征A3(有自己的房子)的基尼指数最小,所以选择A3为最优特征。生成两个节点,A3=“是”的节点类别均为“是”,所以该节点为叶节点,A3=“否”的节点类别包含3个“是”和6个“否”,需进一步划分。将A3=“否”的数据集划分为两个子集,然后按照上述思路在A1、A2和A4中寻找最优特征。这里不再详细列出过程,感兴趣的同学可以自己试着推理下。最终结果是特征A2的基尼指数最小。形成的决策树和前面的ID3算法是一样的。生成二叉树,可处理连续特征,内置剪枝,广泛应用于随机森林和GBDT。决策树的剪枝
在决策树的生成过程中,很容易过拟合,因为在训练集上为了尽可能将更多样本正确分类,可能会将样本数已经很小的数据子集进一步细分。从而可能生长得过于复杂,把噪声也学习了进去。剪枝是防止过拟合的主要手段,分为预剪枝和后剪枝。| 预剪枝
在决策树生长过程中,提前停止分裂。通过设定阈值(如最大深度、节点最小样本数、最小信息增益等),当不满足条件时,当前节点不再分裂,直接作为叶节点。
缺点:可能过早停止,导致欠拟合,且阈值需人工设定。| 后剪枝
先让决策树完全生长,然后自底向上对内部节点进行考察,用验证集判断将某个子树替换为叶节点是否能提升泛化性能,若是则剪枝。两者都是避免过拟合的重要手段,通常可以先做简单预剪枝,如限制树深度等,再用后剪枝做精细优化,兼顾效率和效果。完整案例
1. 环境准备
2. 数据集加载
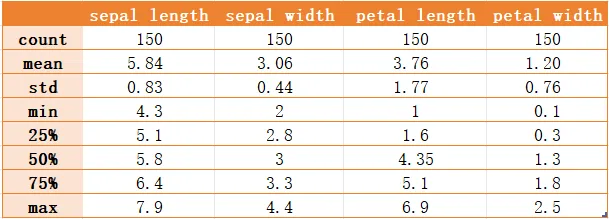
共有150个样本数据,每个样本包含4个特征变量,单位均为cm,具体特征如下:花萼长度(sepal length)、花萼宽度(sepal width)、花瓣长度(petal length)、花瓣宽度(petal width)。
类别共3类:山鸢尾(setosa)、杂色鸢尾(versicolor)、维吉尼亚鸢尾(virginica),每类各有50个样本数据。
3. 描述性统计
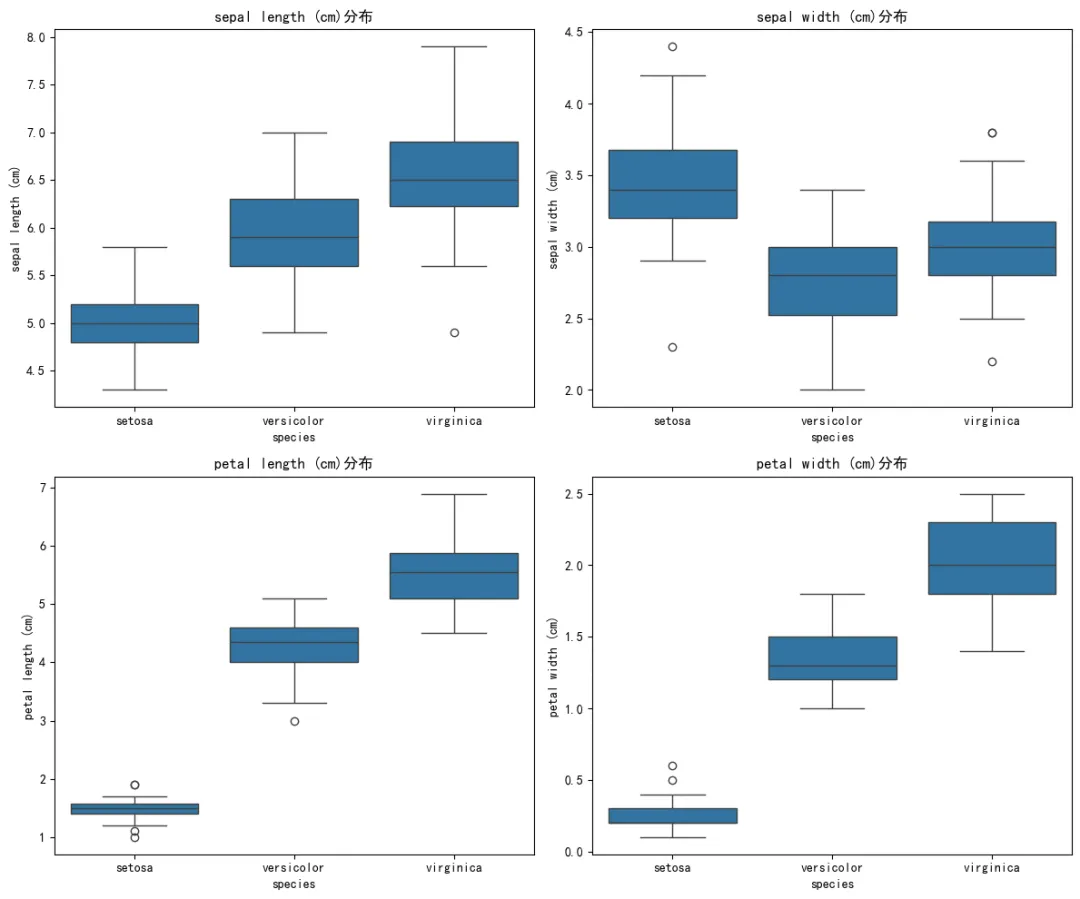
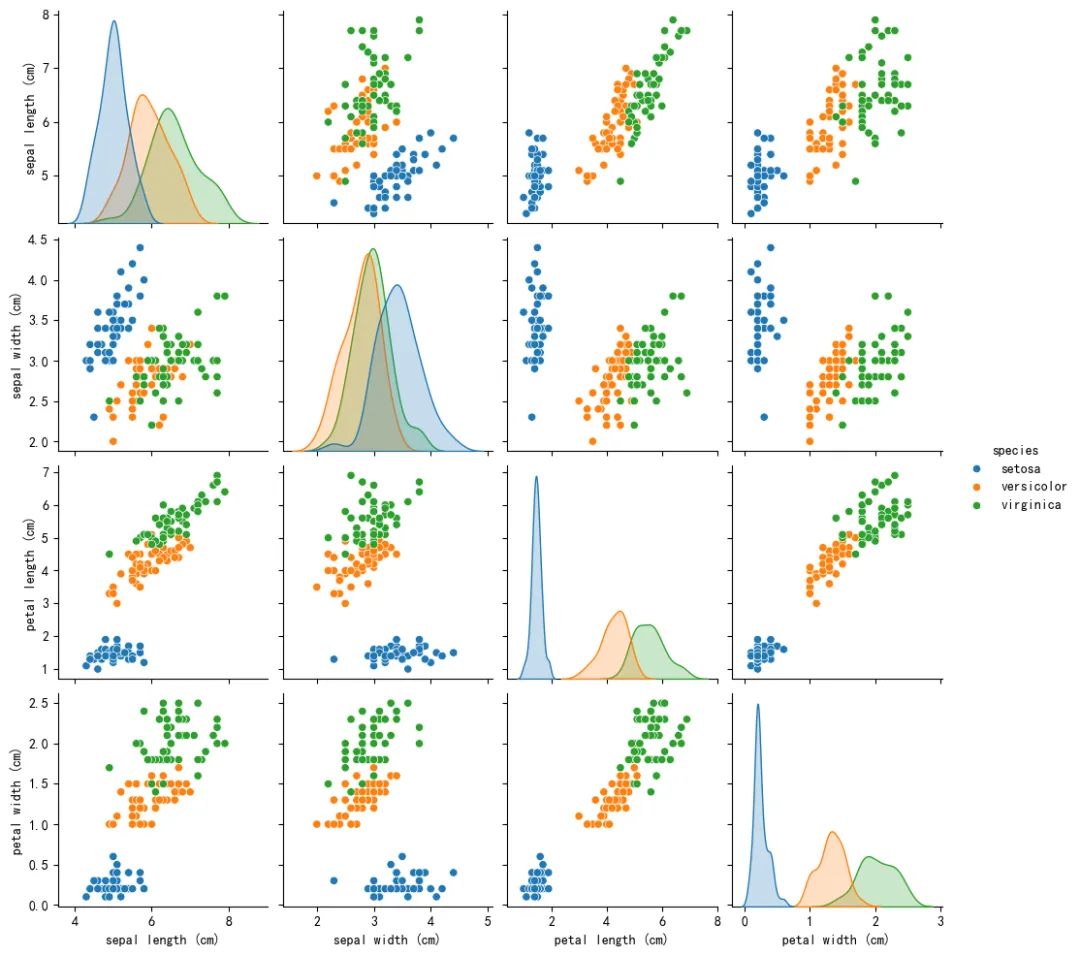
花瓣特征:是区分鸢尾品种的最强特征,setosa与另外两类几乎完全分离,versicolor和virginica也有明显分界。花萼特征:花萼长度可区分setosa与另外两类,但versicolor和virginica重叠较多;花萼宽度则是setosa更宽,另外两类更窄。异常值:各特征均存在少量异常值,对整体分布影响较小。这是鸢尾花数据集的特征两两对比图,对角线为单变量分布密度曲线,非对角线为特征间散点图,用于直观展示特征相关性和类别可分性。特征重要性:花瓣长度/宽度是区分鸢尾品种的核心特征,花萼特征辅助作用有限。类别可分性:setosa(山鸢尾)可通过任意花瓣特征完全区分,versicolor(变色鸢尾)和virginica(维吉尼亚鸢尾)在花瓣特征上可较好分离,在花萼特征上重叠较多。4. 划分训练集和测试集
按照7:3的比例划分训练集和测试集,即训练集105个,测试集45个。5. 训练决策树模型
采用CART算法训练决策树模型,并设置最大深度为3的预剪枝策略,防止过拟合。6. 模型评估
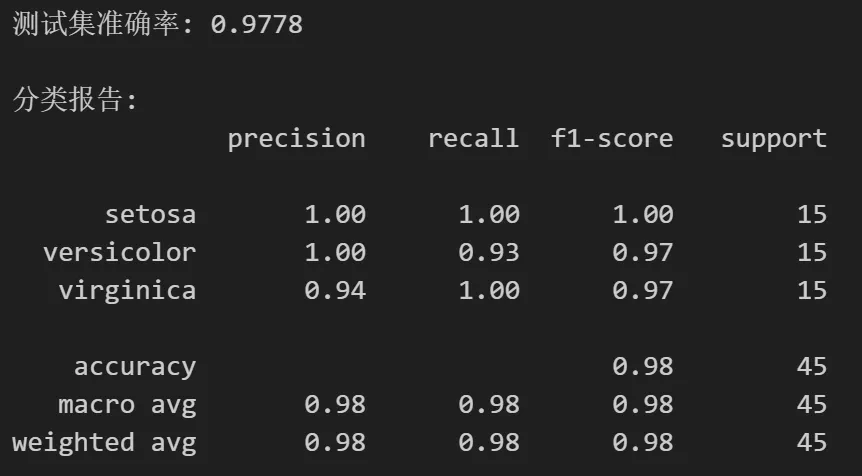
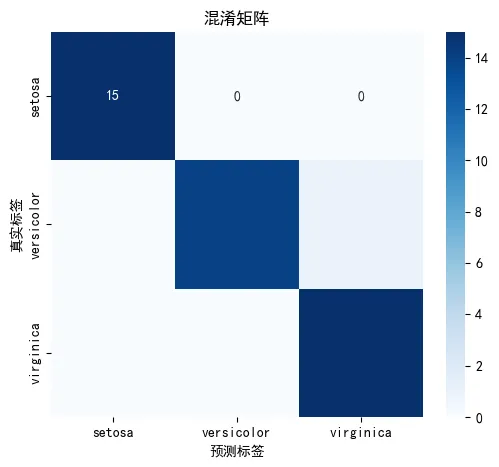
① 准确率与分类报告
测试集准确率:0.9778,这意味着在45个测试样本中,只有1个样本被误分类,分类效果很好。setosa:完全正确,精准率和召回率均为1.00,说明该类别与另外两类区分度极高。versicolor:召回率为0.93,表示有1个真实的versicolor样本被误判为virginica;精准率为1.00,意味着所有被预测为versicolor的样本都是正确的。virginica:精准率为0.94,说明有1个被预测为virginica的样本实际是versicolor;召回率为1.00,表明所有真实的virginica均被正确识别。仅有的1个错误发生在versicolor与virginica之间,这也是鸢尾花分类中最常见的混淆情况,因为这两个物种在花瓣特征上有部分重叠。模型在setosa上的分类完全正确,符合预期,因为setosa的花瓣特征与其他两类差异明显。② ROC曲线与AUC
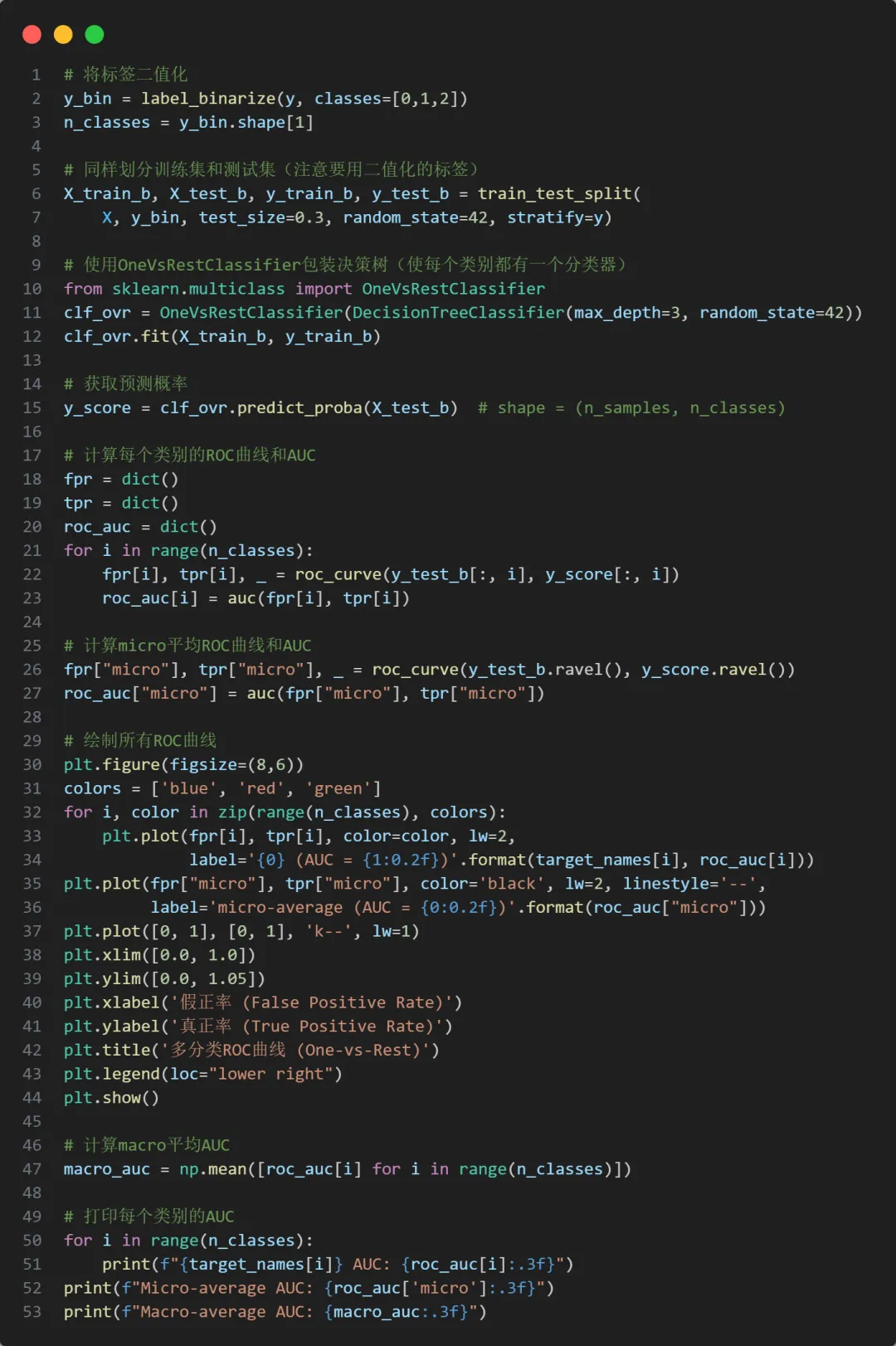
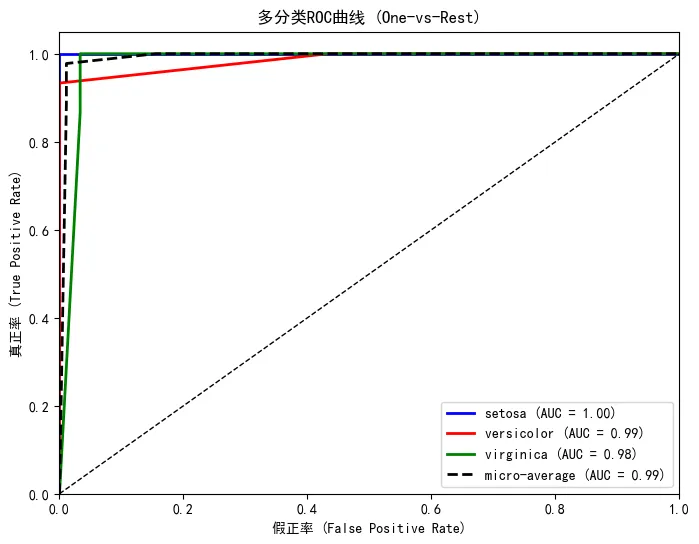
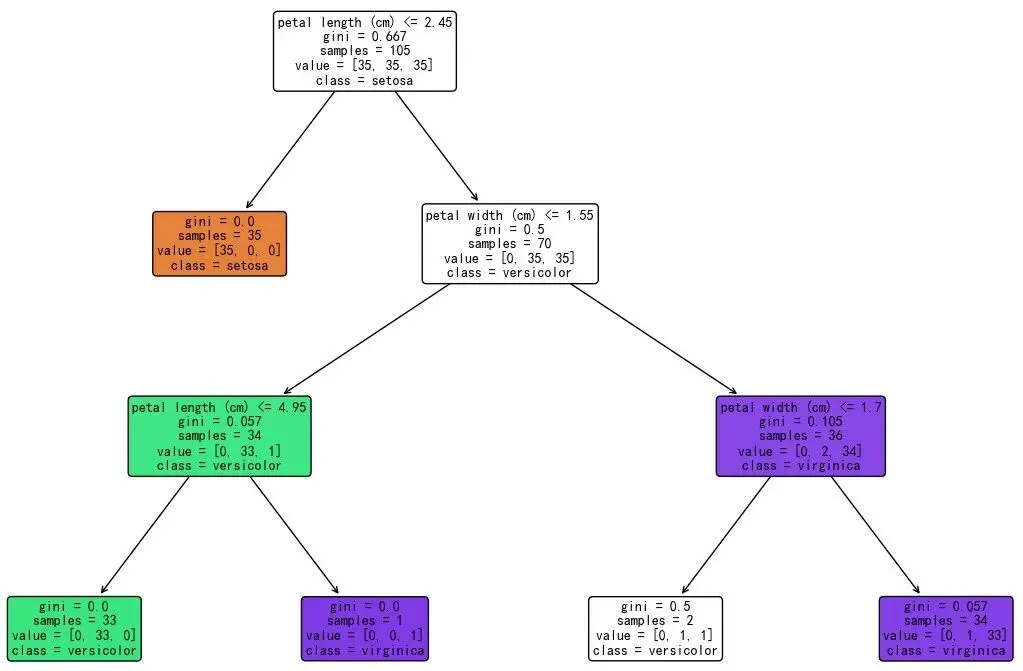
对于多分类问题,我们采用“一对多”(One-vs-Rest)策略,为每个类别绘制ROC曲线,并计算micro和macro平均AUC。横轴(FPR):假正率 = 被误判为正类的负样本 / 所有负样本纵轴(TPR):真正率 = 被正确识别的正样本 / 所有正样本对角线(随机猜测线):AUC=0.5,代表无区分能力曲线越靠近左上角,模型区分能力越强;AUC值越接近1.0,性能越好Micro-average AUC(微平均):将所有子问题的真阳性(TP)、假阳性(FP)、真阴性(TN)、假阴性(FN)等统计量全局汇总,然后基于这些汇总的统计量计算整体的TPR和FPR,从而得到一条综合的ROC曲线和对应的AUC。Macro-average AUC(宏平均):先计算每个类别的AUC,再取算术平均。对每个类别一视同仁,不关心各类别样本数量的差异。当各类别样本分布均衡时,macro平均能很好地反映模型在每个类别上的平均区分能力。整体来看,模型具有极佳的泛化能力,所有类别均被高置信度区分,仅versicolor与virginica之间存在轻微重叠。微平均和宏平均AUC均大于0.98,模型在多分类任务上表现出色。7. 决策树可视化
8. 特征重要性
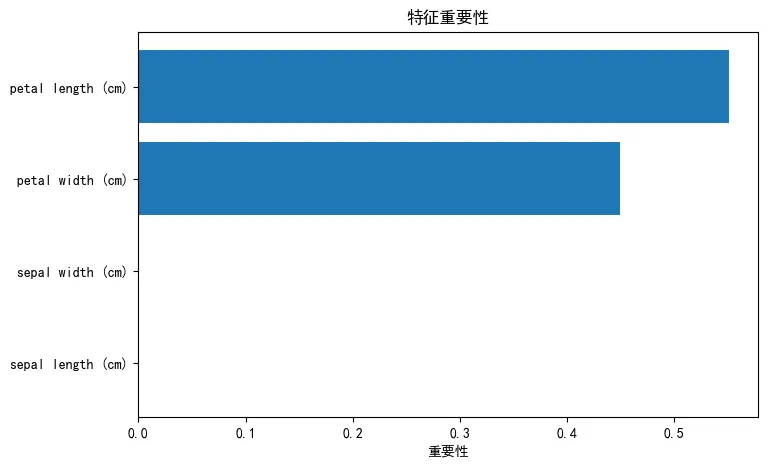
特征选择:模型仅依赖花瓣长度和宽度两个特征,即可完成高精度分类,花萼特征无贡献;分类逻辑:决策树结构清晰,先分离易区分的setosa,再通过多层分裂细分versicolor和virginica;模型可解释性:CART决策树提供了直观的“if-else”分类规则,可解释性极强,适合业务场景落地。决策树的优缺点
| 优点
解释性极强:决策树的结构直观,可通过可视化清晰展示决策路径,非技术人员也能理解预测逻辑;无需大量数据预处理:对特征尺度不敏感(无需标准化/归一化),能容忍一定程度的缺失值,且能同时处理离散型和连续型特征;自动捕捉非线性关系:决策树属于非线性模型,能自动挖掘特征与目标变量之间的复杂交互作用,无需人为指定函数形式;训练和预测效率较高:基于贪心递归划分,计算复杂度较低,适合快速建模。| 缺点
易过拟合:如果不加剪枝或限制树深度,决策树会过度拟合训练数据中的噪声,导致泛化能力下降;模型稳定性差:对训练数据的微小变化敏感,数据集的微小变动可能导致树结构发生较大变化。非全局最优:贪心算法每次只选择当前最优分裂,得到的树是局部最优而非全局最优;对类别不平衡数据敏感:当类别分布严重不平衡时,决策树可能偏向多数类,需配合采样或代价敏感学习。本篇总结
本篇首先介绍了决策树模型的核心思想,然后是三大经典算法的原理,从ID3到C4.5再到CART,随后通过一个鸢尾花的完整案例了解了决策树在分类中的应用,并学习了精准率、召回率、ROC曲线、AUC值等分类模型评价指标,最后介绍了决策树模型的优缺点。
如果这篇内容对您有帮助,欢迎转发、收藏,有任何问题也欢迎在评论区交流讨论~
注:以上内容仅供学习交流,侵权删.