CDA数据分析师授权讲师
帆软数据应用研究院专家
广州大数据行业协会智库专家
计算机软件与理论硕士研究生,华为工作十年,五项国家专利,在华为工作期间获得华为数项奖项,对大数据分析与应用有深入的研究。
培训十年,服务的客户遍及通信、金融、交通、制造、政府等行业,其中包括中国银行、招商银行、平安集团、移动、华为、施耐德、富士康、西部航空、广州地铁、东风日产、广州税务、良品铺子、中冶赛迪、埃森哲、海天集团、正泰电器、徐工集团等公司和单位。
傅老师专注于大数据分析与挖掘、机器学习等应用技术。旨在将大数据的数据分析、数据挖掘、数据建模应用于行业及商业领域,解决行业实际的问题。
- 让管理更高效:将大数据应用于企业管理,用大数据探索企业发展规律和行业发展趋势,有效预判市场变化和需求,基于规律和预判来进行管理决策,并实现组织架构演变、人才新技能培养、生产流程优化,以及服务效率提升,最终匹配市场未来的变化需要,提升企业管理效率。
- 让决策更科学:将大数据应用于运营决策,用大数据呈现企业整体经营状况,诊断运营问题和风险,找到业务短板,全面理解组织、产品、人员、营销、财务等要素间的相关性,实现企业资源的最优化配置,提升科学决策能力。
- 让营销更精准:将大数据应用于市场营销,解决营销中的用户群细分和品牌定位,客户价值评估,分析用户需求,产品设计优化,产品最优定价等实际问题,实现精准营销和精准推荐,以最小的营销成本实现最大化的营销效果。
出版书籍
傅一航出版的书籍有:《商业分析思维与实践--用数据分析解决商业问题》,北京大学出版社,2024年1月上架。
课程特色
傅老师目前致力于将大数据技术应用于通信、金融、电商、互联网、制造业、政府等领域。傅老师的课程最大特色:实战性强!“围绕业务问题+搭建分析框架+运用分析方法+建立分析模型+熟悉分析工具+形成业务策略”。
以商业目标为起点,基于实际的业务应用场景(明确目的),搭建全面系统的业务框架和分析维度(分析思路),选择最合适的方法(分析方法),深入浅出的理论讲解(分析模型),使用简单实用的工具操作(分析工具),对分析结果进行有效的解读(数据可视化),最终形成具体的业务建议,实现业务分析/数据分析的闭环。
ž重思路:数据思维+分析框架;
ž重体系:分析过程+分析阶段;
ž重实战:分析方法+分析模型+分析工具;
ž重落地:可视化+数据解读+业务策略。
课程主题
大数据的培训主题有:
董事长总经理高管的课程:
《数字化战略与数字化变革》
《大数据思维与应用创新》
《大数据思维与商业模式创新,赋能企业增长》
《大数据思维与大数据决策,提升决策能力》
大数据市场营销的课程:
《大数据时代的精准营销》
《数说营销----大数据营销分析实战与沙盘》
《市场营销大数据分析实战培训》
《大数据助力市场营销与服务提升》
大数据分析应用类的课程:
《大数据分析综合能力提升实战》
《大数据建模与模型优化实战培训》
《大数据挖掘之SPSS工具入门与提高》
《金融行业风险预测模式实战培训》
《数据分析及生产运营实际应用》
大数据分析语言Python课程:
《Python开发基础实战培训》
《Python数据分析与可视化实战》
《Python数据建模与模型评估实战》
《Python模型优化与特征优化实战》
《Python机器学习算法实战》
《Python RPA办公流程自动化》
《大数据建模大赛实战辅导》
Python数据建模及模型优化实战
【课程目标】
本课程专注于金融行业的数据建模,包括客户行为预测模型、风控识别与风险预测模型、信用评分卡模型,面向数据分析部等专门负责数据分析与建模的人士。
本课程主要讲解如何利用Python进行数据建模,建立数学模型,来探索业务的各个要素之间的关系,并实现业务目标拟合(回归)或者区分事物所归属的类别(分类)。
主要内容包括:模型选择、特征工程、模型原理、算法实现、模型评估、模型优化、模型解读及模型应用。
通过本课程的学习,达到如下目的:
1、掌握数据分析和数据建模的基本过程和步骤
2、掌握数据分析框架的搭建,及常用分析方法
3、掌握业务的影响因素分析常用的方法
4、掌握常用客户行为预测模型,包括逻辑回归、决策树、神经网络等等
5、掌握模型优化的思路及措施,包括特征优化、超参优化、集成优化等
6、掌握金融行业信用评分卡模型,构建信用评分模型
本课程突出数据挖掘的实际应用,结合行业的典型应用特点,从实际问题入手,引出相关知识,进行大数据的收集与处理;探索数据之间的规律及关联性,帮助学员掌握系统的数据预处理方法;介绍常用的模型,训练模型,并优化模型,以达到最优分析结果。
【授课时间】
2-5天时间,或者根据培训需求选择组合(每天6个小时)
时间 | | 主题 | 主要内容 |
第一天 | 上午 | 数据建模过程 数据分析框架 | 建模六个步骤 搭建用户违约分析框架 |
下午 | 探索性分析篇 | 相关分析/相关系数 |
第二天 | 上午 | 探索性分析篇 客户行为预测 模型质量评估 | 方差分析/卡方检验 线性回归回归、逻辑回归、 评估指标、评估方法、过拟合评估 |
下午 | 客户行为预测 超参优化方法 | 决策树、神经网络 网络/随机/贝叶斯搜索 |
第三天 | 上午 | 集成算法优化 | 集成优化思想 Bagging与随机森林 |
下午 | 集成算法优化 | Boosting与GBDT/XGBoost/LightGBM Stacking:XGBoost+LR/SVR |
第四天 | 上午 | 特征工程优化 | 缺失值填充、样本均衡、 特征选择、因子合并、 标准化、变量派生 |
下午 | 管道技术实现 建模实战练习 | Pipeline, columntransformer, FeatureUnion |
第五天 | 上午 | 异常数据识别 | 异常数据识别方法 |
下午 | 信用评分卡 | 信用评分卡模型 |
【授课对象】
风险控制部、金融科技部、IT系统部、数据分析部等对数据建模有较高要求的相关领域人员。
【学员要求】
要求熟悉Python语言,熟悉numpy/pandas/sklearn库的使用。
1、每个学员自备一台便携机(必须)
2、环境要求:Python3.10版本以上(建议ananconda+VsCode)
注:讲师可以提供课堂上演示使用数据源及代码
【授课方式】
理论框架+落地措施+实战训练
【课程大纲】
第一部分: 数据建模过程—建模步骤篇
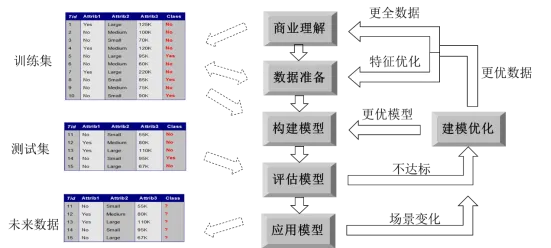
1、预测建模六步法
Ø选择模型:基于业务选择恰当的数据模型
Ø特征工程:选择对目标变量有显著影响的属性来建模
Ø训练模型:采用合适的算法对模型进行训练,寻找到最优参数
Ø评估模型:进行评估模型的质量,判断模型是否可用
Ø优化模型:如果评估结果不理想,则需要对模型进行优化
Ø应用模型:如果评估结果满足要求,则可应用模型于业务场景
2、数据挖掘常用的模型
Ø定量预测模型:回归预测、时序预测等
Ø定性预测模型:逻辑回归、决策树、神经网络、支持向量机等
Ø市场细分:聚类、RFM、PCA等
Ø产品推荐:关联分析、协同过滤等
Ø产品优化:回归、随机效用等
Ø产品定价:定价策略/最优定价等
3、特征工程/特征选择/变量降维
Ø基于变量本身特征
Ø基于相关性判断
Ø因子合并(PCA等)
ØIV值筛选(评分卡使用)
Ø基于信息增益判断(决策树使用)
4、模型评估
Ø模型质量评估指标:R^2、正确率/查全率/查准率/特异性等
Ø预测值评估指标:MAD、MSE/RMSE、MAPE、概率等
Ø模型评估方法:留出法、K拆交叉验证、自助法等
Ø其它评估:过拟合评估、残差检验
5、模型优化
Ø优化模型:选择新模型/修改模型
Ø优化数据:新增显著自变量
Ø优化公式:采用新的计算公式
Ø集成思想:Bagging/Boosting/Stacking
6、常用预测模型介绍:回归、时序、分类
第二部分: 数据分析框架—业务模型篇
1、数据分析思路来源于业务模型
2、分析框架来源于业务模型
Ø商业目标(粗粒度)
Ø分析维度/关键步骤
Ø业务问题(细粒度)
Ø涉及数据/关键指标
3、常用的业务模型:PEST/5W2H/SWOT/PDCA/AARRR…
案例:搭建精准营销的分析框架(6R)
Ø如何寻找目标客户群
Ø如何匹配合适的产品
Ø如何确定推荐的最佳时机
Ø如何判断合理的价格
Ø……
案例:搭建用户购买行为分析框架(5W2H)
第三部分: 探索性分析法—统计分析篇
问题:数据分析方法的种类?分析方法的不同应用场景?
1、业务分析的三个阶段
Ø现状分析:通过企业运营指标来发现规律及短板
Ø原因分析:查找数据相关性,探寻目标影响因素
Ø预测分析:合理配置资源,预判业务未来的趋势
2、常用的数据分析方法五大种类
3、统计分析基础(类别à指标)
4、描述性分析法(现状分析)
Ø对比分析(查看数据差距,发现事物变化)
演练:分析理财产品受欢迎情况及贡献大小
演练:用户消费水平差异分析,提取优质客户特征
Ø分布分析(查看数据分布,探索业务层次)
案例:银行用户的消费层次/消费档次分析
演练:客户年龄分布/收入分布分析
Ø结构分析(查看指标构成,评估结构合理性)
案例:收入结构分析/成本结构分析
案例:动态结构分析
Ø趋势分析(查看变化趋势,了解季节周期性)
案例:营业厅客流量规律与排班
案例:用户活跃时间规律/产品销量的淡旺季分析
演练:产品订单的季节周期性规律
5、相关性分析(原因分析)
Ø相关分析(衡量两变量间的相关程度,三种相关系数)
Ø方差分析(判断影响目标变量的关键要素,适用场景)
Ø卡方检验(从多个维度的数据指标分析)
演练:不同客户的产品偏好分析
演练:银行用户违约的影响因素分析
第四部分: 客户行为预测—分类模型篇
问题:如何评估客户购买产品的可能性?如何预测客户的购买行为?如何提取某类客户的典型特征?如何向客户精准推荐产品或业务?
1、分类模型概述及其应用场景
2、常见分类预测模型
3、逻辑回归(LR)
Ø逻辑回归的适用场景
Ø逻辑回归的模型原理
Ø逻辑回归分类的几何意义
Ø逻辑回归的种类:二项、多项
Ø如何解读逻辑回归方程
Ø逻辑回归算法的实现及优化
²迭代样本的随机选择
²变化的学习率
²逻辑回归+正则项
²求解算法与惩罚项的互斥有关系
Ø带分类自变量的逻辑回归分析
Ø多项逻辑回归/多分类逻辑回归
²ovo, ovr
案例:用sklearn库实现银行贷款违约预测
案例:订阅者用户的典型特征(二元逻辑回归)
案例:通信套餐的用户画像(多元逻辑回归)
4、分类决策树(DT)
问题:如何预测客户行为?如何识别潜在客户?
风控:如何识别欠贷者的特征,以及预测欠贷概率?
客户保有:如何识别流失客户特征,以及预测客户流失概率?
Ø决策树分类简介
演练:识别银行欠货风险,提取欠贷者的特征
Ø决策树分类的几何意义
Ø决策树算法(三个关键问题)
²如何选择最佳属性来构建节点:熵/基尼系数、信息增益
²如何分裂变量:多元/二元划分、最优切割点
²修剪决策树:剪枝原则、预剪枝与后剪枝
Ø决策树的解读
Ø决策树的超参优化
案例:商场用户的典型特征提取
案例:客户流失预警与客户挽留
案例:识别拖欠银行货款者的特征,避免不良货款
Ø多分类决策树
案例:识别不同理财客户的典型特征,实现精准推荐
5、人工神经网络(ANN)
Ø神经网络的结构
Ø神经网络基本原理
²加法器,激活函数
Ø神经网络分类的几何意义
Ø神经网络的结构
²隐藏层数量
²神经元个数
Ø神经网络实现算法
案例:评估银行用户拖欠货款的概率
6、支持向量机(SVM)
ØSVM基本原理
Ø线性可分问题:最大边界超平面
Ø线性不可分问题:特征空间的转换
Ø维灾难与核函数
第五部分: 客户行为预测—模型评估篇
1、三个方面评估:指标、方法、过拟合
2、两大矩阵
Ø混淆矩阵
Ø代价矩阵
3、六大指标
Ø正确率Accuracy
Ø查准率Precision
Ø查全率Recall
Ø特异度Specify
ØF度量值(/)
Ø提升指标lift
4、三条曲线
ØROC曲线和AUC
ØPR曲线和BEP
ØKS曲线和KS值
5、多分类模型评估指标
Ø宏指标:macro_P, macro_R
Ø宏指标:micro_P, micro_R
6、模型评估方法
Ø原始评估法
Ø留出法(Hold-Out)
Ø交叉验证法(k-fold cross validation)
Ø自助采样法(Bootstrapping)
7、其它评估
Ø过拟合评估:学习曲线
Ø模型差异性评估
Ø残差评估:白噪声评估
第六部分: 预测模型优化—超参优化篇
1、模型优化的三大方向
Ø超参优化
Ø特征工程
Ø集成优化
2、超参优化的方法比较
Ø交叉验证类(RidgeCV/LassoCV/LogisticRegressionCV/…)
Ø网格搜索GridSearchCV
Ø随机搜索RandomizedSearchCV
Ø贝叶斯搜索BayesSearchCV
3、超参调优策略
第七部分: 预测模型优化—特征工程篇
1、数据清洗技巧
Ø异常数据的处理方式
Ø缺失值的填充方式
Ø不同填充方式对模型效果的影响
2、降维的两大方式:特征选择和因子合并
3、特征选择的模式
Ø基于变量本身的重要性筛选
ØFilter式(特征选择与模型分离)
ØWrapper式(利用模型结果进行特征选择)
ØEmbedded式(模型自带特征重要性评估)
Ø确定特征选择的变量个数
案例:客户流失预测的特征选择
4、因子合并(将多数变量合并成少数几个因子)
Ø因子分析(FactorAnalysis):原理、适用场景、载荷矩阵
Ø主成份分析PCA:原理、几何含义、扩展KernelCA/ICA/…
案例:汽车油效预测
5、变量变换
Ø为何需要变量变换
Ø因变量变换对模型质量的影响
Ø特征标准化:作用、不同模型对标准化的要求、不同标准化对模型的影响
Ø其它变换:正态化、正则化等
6、变量派生:基于业务经验的派生、多项式派生
7、特征工程的管道实现
Ø管道类Pipeline
Ø列转换类ColumnTransformer
Ø特征合并类FeatureUnion
第八部分: 预测模型优化—集成优化篇
1、模型的优化思路
2、集成算法基本原理
Ø单独构建多个弱分类器
Ø多个弱分类器组合投票,决定预测结果
3、集成方法的种类:Bagging、Boosting、Stacking
4、Bagging集成:随机森林RF
Ø数据/属性重抽样
Ø决策依据:少数服从多数
5、Boosting集成:AdaBoost模型
Ø基于误分数据建模
Ø样本选择权重更新公式
Ø决策依据:加权投票
6、高级模型介绍与实现
ØGBDT梯度提升决策树
ØXGBoost
ØLightGBM
第九部分: 用户风险识别—异常数据篇
1、反欺诈识别的重点内容
Ø如何识别异常数据
Ø如何查找影响因素
Ø如何提取欺诈用户的特征
Ø如何预测用户的欺诈行为
2、异常数据的定义
3、异常数据的检测方法
Ø基于统计法:标准差法、四分位距法、离群点检测算法
Ø基于机器学习:回归、聚类等
4、异常数据处理方法
演练:各种异常数据识别
第十部分: XGBoost模型详解及优化
1、基本参数配置
Ø框架基本参数: n_estimators, objective
Ø性能相关参数: learning_rate
Ø模型复杂度参数:max_depth,min_child_weight,gamma
Ø生长策略参数: grow_policy, tree_method, max_bin
Ø随机性参数:subsample,colsample_bytree
Ø正则项参数:reg_alpha,reg_lambda
Ø样本不均衡参数: scale_pos_weight
2、早期停止与基类个数优化(n_estimators、early_stopping_rounds)
3、样本不平衡处理
Ø欠抽样与过抽样
Øscale_pos_weight=neg_num/pos_num
4、XGBoost模型欠拟合优化措施
Ø增维,派生新特征
²非线性检验
²相互作用检验
Ø降噪,剔除噪声数据
²剔除不显著影响因素
²剔除预测离群值(仅回归)
²多重共线性检验(仅回归)
Ø变量变换
²自变量标准化
²残差项检验与因变量变换
Ø增加树的深度与复杂度
²增大max_depth
²减小min_child_weight, gamma等
Ø禁止正则项生效
5、特征重要性评估与自动特征选择
6、超参优化策略:
Ø分组调参:参数分组分别调优
Ø分层调参:先粗调再细调
7、XGBoost模型过拟合优化措施
Ø降维,减少特征数量
Ø限制树的深度和复杂度
²减小max_depth
²增大min_child_weight,gamma等
Ø采用dart模型来控制过拟合(引入dropout技术)
Ø启用正则项惩罚:reg_alpha,reg_lambda等
Ø启用随机采样:subsample,colsample_bytree等
8、Stacking模式:XGBoost+LR、XGBoost+RF等
9、XGBoost的优化模型:LightGBM
第十一部分: 客户信用评分卡模型
1、信用评分卡模型简介
2、评分卡的关键问题
3、信用评分卡建立过程
Ø筛选重要属性
Ø数据集转化
Ø建立分类模型
Ø计算属性分值
Ø确定审批阈值
4、筛选重要属性
Ø属性分段
Ø基本概念:WOE、IV
Ø属性重要性评估
5、数据集转化
Ø连续属性最优分段
Ø计算属性取值的WOE
6、建立分类模型
Ø训练逻辑回归模型
Ø评估模型
Ø得到字段系数
7、计算属性分值
Ø计算补偿与刻度值
Ø计算各字段得分
Ø生成评分卡
8、确定审批阈值
Ø画K-S曲线
Ø计算K-S值
Ø获取最优阈值
案例:构建银行小额贷款的用户信用模型
第十二部分: 数据建模实战篇
1、电信业客户流失预警和客户挽留模型实战
2、银行欠贷风险预测模型实战
3、银行信用卡评分模型实战
结束:课程总结与问题答疑。





 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
