ALL in Python:如何使用 PyFixest 进行实证分析
本文基于 PyFixest 0.40+ 官方文档,并系统性地对照 Stata reghdfe 语法。
1. 为什么要切换到 Python?
Stata 的闭源架构与单核限制,限制了其处理数据分析的能力边界。与此同时,越来越多的主流计量方法,正优先在 Python 与 R 这类开源、高效的生态中落地。
尽管当前 Python 对于部分实证命令,如 psm shapley2 等,仍缺乏完全一致的替代。但是,从长期角度来看,学习 Python 实证的方法对于跟进计量发展趋势具有裨益。
本篇文章将围绕当前已经成熟的一个 Python 实证项目库 PyFixest 进行全面介绍。
PyFixest 的核心优势:
- 公式语法几乎等价于 R 的
fixest——如果你读过任何使用 fixest 的论文,会发现 PyFixest 的语法完全一致,学习成本极低。 - 高维固定效应的高效求解——底层采用与
reghdfe 相同的迭代去均值(alternating projection)算法,支持任意多维固定效应。 - 完整的推断工具箱——HC1–HC3、CRV1/CRV3 聚类、Wild Bootstrap、随机化推断(Randomization Inference)、Romano-Wolf 多重检验校正,全部内置。
- 与 Python 数据科学生态无缝衔接——Pandas 数据框进出,matplotlib / lets-plot 可视化,Jupyter Notebook 交互式分析。
- GPU 加速——通过 CuPy 或 JAX 后端,大数据集可获得数倍加速。
- 完全免费、开源——MIT 许可证,无 license 费用。
2. 安装与数据准备
安装
pip install pyfixest
# Wild Bootstrap / Romano-Wolf 需要额外安装:
pip install wildboottest
加载与准备数据
import numpy as np
import pandas as pd
import pyfixest as pf
# 加载 PyFixest 内置的模拟数据集
data = pf.get_data()
data.head()
该数据集包含:因变量 Y、Y2,自变量 X1、X2,固定效应变量 f1、f2、f3,分组变量 group_id,工具变量 Z1、Z2,以及权重 weights。部分列含缺失值,PyFixest 会自动处理 (listwise deletion)。
Stata 对照: 如果你想在 Stata 中使用完全相同的数据:
* 先在 Python 中保存
* import os
* data.to_stata(os.path.join(os.path.expanduser("~"), "pyfixest-data.dta"))
cd ~
use pyfixest-data.dta, clear
describe
快速验证
下面复现 Causal Inference for the Brave and True 第 14 章的经典面板回归案例。
# 加载工资面板数据
data_url = "https://raw.githubusercontent.com/bashtage/linearmodels/main/linearmodels/datasets/wage_panel/wage_panel.csv.bz2"
wage = pd.read_csv(data_url)
# 估计模型:婚姻对工资的影响,控制工作经验平方、工会、工时
# 固定效应:个体 (nr) + 时间 (year)
# 聚类:个体 + 时间 双维聚类
panel_fit = pf.feols(
"lwage ~ expersq + union + married + hours | nr + year",
data=wage,
vcov={"CRV1": "nr + year"},
)
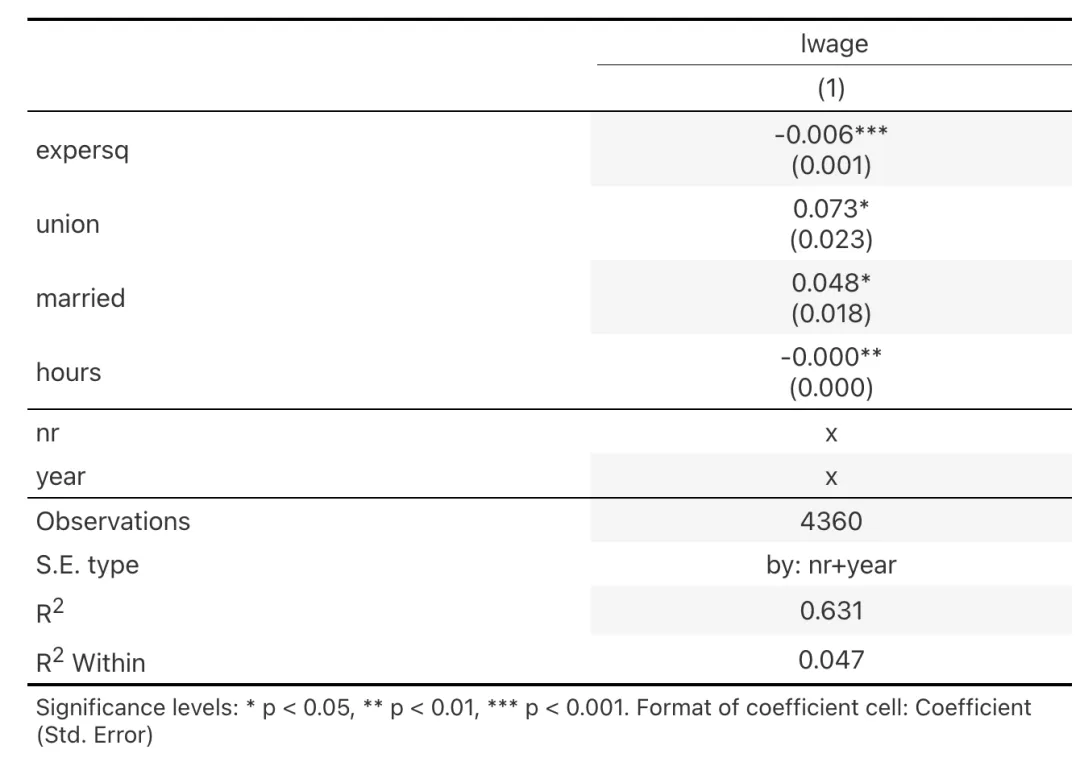
pf.etable(panel_fit)
Stata 完整对照:
* ssc install bcuse
bcuse wagepan, clear
* 双维固定效应 + 双维聚类
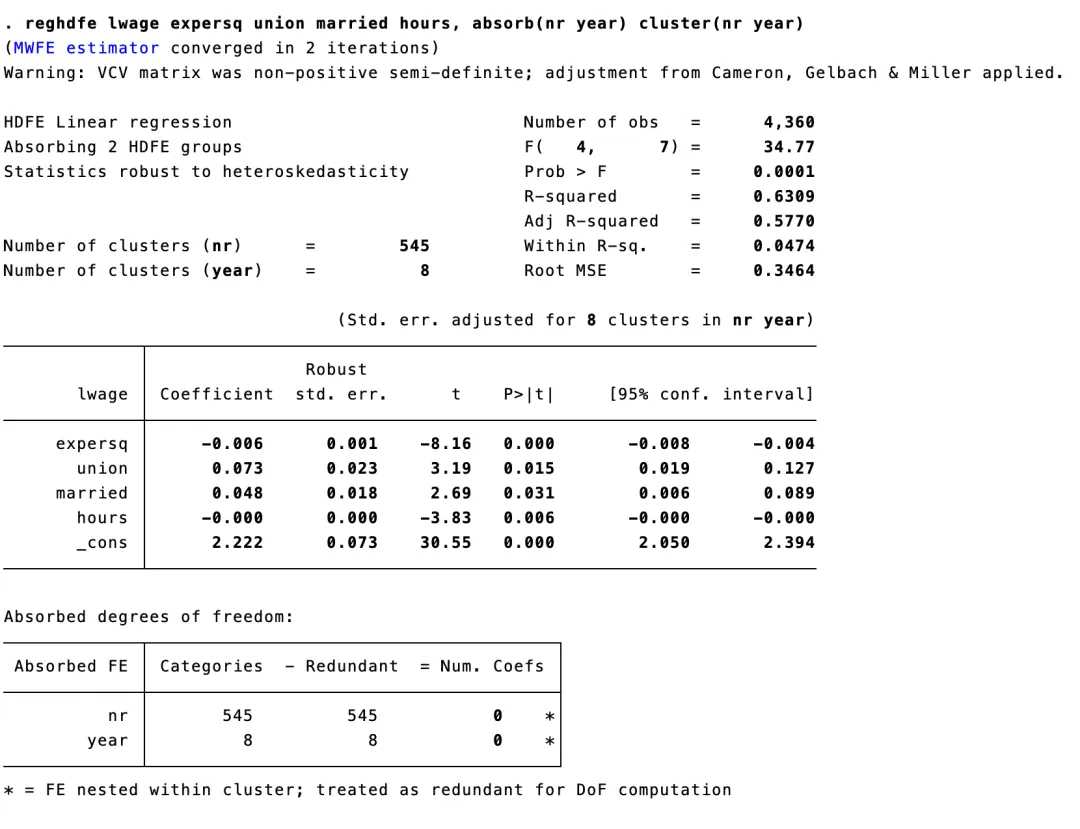
reghdfe lwage expersq union married hours, absorb(nr year) cluster(nr year)
3. 基础 OLS 回归
简单 OLS
PyFixest:
fit1 = pf.feols("Y ~ X1", data=data)
fit2 = pf.feols("Y ~ X1 + X2", data=data)
pf.etable([fit1, fit2])
Stata 对照:
reg Y X1
reg Y X1 X2
* 或等价的 reghdfe 语法:
reghdfe Y X1, noabsorb
reghdfe Y X1 X2, noabsorb
对齐说明: PyFixest 的 feols() 在底层对齐的是 reghdfe(Sergio Correia 的包),不是 reg 或 xtreg。在无固定效应的纯 OLS 场景下,reg 和 reghdfe 结果完全一致,所以用哪个都行。但本文统一推荐 reghdfe 语法,因为你写论文时大概率全程用它。
查看结果
PyFixest 的结果不会自动打印(不像 Stata),你需要主动调用方法:
fit1.summary() # 类似 Stata 回归输出的完整摘要
fit1.tidy() # 返回 tidy 格式的 DataFrame(系数、标准误、t值、p值、置信区间)
fit1.coef() # 系数向量
fit1.se() # 标准误向量
fit1.tstat() # t 统计量
fit1.pvalue() # p 值
fit1.confint() # 置信区间
fit1.resid() # 残差
fit1.predict() # 拟合值
Stata 对照(回归后取结果):
reghdfe Y X1, noabsorb
matrix list e(b) // 系数
matrix list e(V) // 方差协方差矩阵
predict yhat, xb // 拟合值
predict res, residuals // 残差
4. 高维固定效应
这是 PyFixest 的核心能力。固定效应写在公式的 | 右侧。
单维固定效应
PyFixest:
fit_fe1 = pf.feols("Y ~ X1 + X2 | f1", data=data)
fit_fe1.summary()
Stata 对照:
reghdfe Y X1 X2, absorb(f1)
⚠️ 关于 xtreg, fe: PyFixest 对齐的是 reghdfe,不是xtreg。两者的点估计一致,但标准误可能不同——xtreg 在自由度计算中将所有固定效应水平计为已估计参数(等价于 PyFixest 的 k_fixef="full"),而 reghdfe 和 PyFixest 默认不计入(k_fixef="none")。如果你在对比 PyFixest 和 Stata 结果时发现标准误有微小差异,请确认你在 Stata 端用的是 reghdfe 而非 xtreg。
多维固定效应
PyFixest:
fit_fe2 = pf.feols("Y ~ X1 + X2 | f1 + f2", data=data)
fit_fe2.summary()
Stata 对照:
reghdfe Y X1 X2, absorb(f1 f2)
三维及更多固定效应
PyFixest:
fit_fe3 = pf.feols("Y ~ X1 + X2 | f1 + f2 + f3", data=data)
Stata 对照:
reghdfe Y X1 X2, absorb(f1 f2 f3)
语法完全平行:PyFixest 用 + 连接多个固定效应,Stata 在 absorb() 中用空格分隔。
固定效应的直觉
PyFixest 底层执行的是迭代去均值 (iterative demeaning) 算法——与 reghdfe 完全一致。也就是说,Y ~ X1 | f1 等价于对 Y 和 X1 分别按 f1 组别去均值后做 OLS。这一点可以手动验证:
# 手动去均值
def demean(df, col, by):
return df[col] - df.groupby(by)[col].transform("mean")
data_dm = data.assign(
Y_dm = lambda d: demean(d, "Y", "group_id"),
X1_dm = lambda d: demean(d, "X1", "group_id"),
)
fit_manual = pf.feols("Y_dm ~ X1_dm", data=data_dm)
# 系数与 feols("Y ~ X1 | group_id", ...) 完全一致
5. 标准误的完整菜单
标准误通过 vcov 参数指定,也可以在估计后通过 .vcov() 方法动态切换(无需重新估计模型)。
5.1 同方差标准误 (iid)
PyFixest:
fit = pf.feols("Y ~ X1 + X2 | f1", data=data, vcov="iid")
Stata 对照:
reghdfe Y X1 X2, absorb(f1)
* Stata 默认就是 iid(不加 robust 或 cluster 选项时)
5.2 异方差稳健标准误 (HC1)
PyFixest:
fit = pf.feols("Y ~ X1 + X2", data=data, vcov="HC1")
Stata 对照:
reghdfe Y X1 X2, noabsorb vce(robust)
PyFixest 还支持 HC2 和 HC3(仅限无吸收固定效应的模型,见踩坑指南 16.2):
fit_hc3 = pf.feols("Y ~ X1 + X2", data=data, vcov="HC3")
reg Y X1 X2, vce(hc3)
注意小样本校正的差异: PyFixest 默认的 HC3 应用了两个小样本校正 (k-adjustment 和 N-adjustment),而 Stata 只用了一个。如果需要精确复现 Stata 结果,传入 ssc=pf.ssc(k_adj=False):
fit_hc3_stata = pf.feols("Y ~ X1 + X2", data=data, vcov="HC3",
ssc=pf.ssc(k_adj=False))
5.3 聚类稳健标准误 (CRV1)
PyFixest:
# 单维聚类
fit = pf.feols("Y ~ X1 + X2 | f1", data=data, vcov={"CRV1": "f1"})
# 双维聚类
fit = pf.feols("Y ~ X1 + X2 | f1", data=data, vcov={"CRV1": "f1 + f2"})
Stata 对照:
reghdfe Y X1 X2, absorb(f1) cluster(f1)
reghdfe Y X1 X2, absorb(f1) cluster(f1 f2)
双维聚类的 ssc 差异: PyFixest 默认按最小聚类维度调整所有维度的自由度,Stata 按各维度自身聚类数调整。要复现 Stata:
fit = pf.feols("Y ~ X1 + X2", data=data,
vcov={"CRV1": "f1 + f2"},
ssc=pf.ssc(G_df="conventional"))
5.4 CRV3 聚类标准误
PyFixest:
fit.vcov({"CRV3": "group_id"}).summary()
CRV3 是基于 jackknife 的聚类稳健标准误,在聚类数量较少时表现优于 CRV1。Stata 中没有直接等价命令,需要手动编程或使用外部包。
5.5 动态切换标准误
这是 PyFixest 的一大亮点——估计一次模型,标准误可以随时换:
fit = pf.feols("Y ~ X1 | f1", data=data)
fit.vcov("iid").summary() # 同方差
fit.vcov("HC1").summary() # 异方差稳健
fit.vcov({"CRV1": "group_id"}).summary() # 聚类
fit.vcov({"CRV1": "group_id + f2"}).summary() # 双维聚类
Stata 中做不到这一点——每换一种标准误你就要重跑一次 reghdfe。
5.6 Wild Bootstrap 推断
PyFixest:
fit = pf.feols("Y ~ X1", data=data, vcov={"CRV1": "group_id"})
fit.wildboottest(param="X1", reps=999)
Stata 对照:
* 需安装 boottest
* ssc install boottest
reghdfe Y X1, noabsorb cluster(group_id)
boottest X1, reps(999)
5.7 随机化推断 (Randomization Inference)
PyFixest:
fit.ritest(resampvar="X1=0", reps=1000, cluster="group_id")
Stata 对照:
* 需安装 ritest
* ssc install ritest
ritest X1 _b[X1], reps(1000) cluster(group_id): reg Y X1
* 注:ritest 内部命令可用 reg 或 reghdfe,无 FE 时结果一致
5.8 Causal Cluster Variance Estimator (CCV)
基于 Abadie et al. (QJE, 2023),当处理变量的变异部分来自聚类内部时,标准 CRV1 会过度保守。PyFixest 内置了该估计量:
fit = pf.feols("ln_earnings ~ college", vcov={"CRV1": "state"}, data=df)
fit.ccv(treatment="college", pk=0.05, n_splits=2, seed=929)
Stata 中目前没有官方实现。
6. 工具变量估计 (IV/2SLS)
语法
IV 模型的公式结构为:depvar ~ exog_vars | fixed_effects | endog_var ~ instruments
PyFixest:
# 有固定效应的 IV
iv_fit = pf.feols("Y2 ~ 1 | f1 + f2 | X1 ~ Z1 + Z2", data=data)
iv_fit.summary()
# 无固定效应的 IV
iv_fit_no_fe = pf.feols("Y ~ 1 | X1 ~ Z1 + Z2", data=data)
Stata 对照:
* 有固定效应
ivreghdfe Y2 (X1 = Z1 Z2), absorb(f1 f2)
* 无固定效应
ivregress 2sls Y (X1 = Z1 Z2)
* 或
ivreg2 Y (X1 = Z1 Z2)
第一阶段结果与 F 统计量
# 查看第一阶段
pf.etable([iv_fit._model_1st_stage, iv_fit])
# 第一阶段 F 统计量
print(iv_fit._f_stat_1st_stage)
# Olea & Pflueger (2013) 有效 F 统计量
iv_fit.IV_Diag()
print(iv_fit._eff_F)
Stata 对照:
ivreghdfe Y2 (X1 = Z1 Z2), absorb(f1 f2) first
* 第一阶段 F 统计量自动报告
* 有效 F 统计量
* 需使用 weakivtest 包
* ssc install weakivtest
7. 泊松回归 (Poisson/PPML)
对应 Stata 的 ppmlhdfe,用于计数数据或引力模型。
PyFixest:
pois_data = pf.get_data(model="Fepois")
pois_fit = pf.fepois("Y ~ X1 | group_id", data=pois_data, vcov={"CRV1": "group_id"})
pois_fit.summary()
Stata 对照:
ppmlhdfe Y X1, absorb(group_id) cluster(group_id)
8. 广义线性模型 (GLM):Logit、Probit
PyFixest 通过 feglm() 支持 GLM 估计。
⚠️ 重要提示 (v0.40):feglm() 当前版本不支持| 语法吸收固定效应。如需控制固定效应,请使用 C() 生成哑变量。官方文档展示的 | f1 语法是未来版本的计划功能。
PyFixest:
# 准备二值因变量
data_glm = pf.get_data()
data_glm["Y"] = np.where(data_glm["Y"] > 0, 1, 0)
# Logit(使用 C() 控制固定效应)
fit_logit = pf.feglm("Y ~ X1 + X2 + C(f1)", data=data_glm, family="logit")
# Probit
fit_probit = pf.feglm("Y ~ X1 + X2 + C(f1)", data=data_glm, family="probit")
# Gaussian(作为对照)
fit_gauss = pf.feglm("Y ~ X1 + X2 + C(f1)", data=data_glm, family="gaussian")
pf.etable([fit_gauss, fit_logit, fit_probit])
Stata 对照:
* 生成二值变量
gen Y_bin = (Y > 0)
* Logit with categorical dummies
logit Y_bin X1 X2 i.f1
预测与边际效应
# 预测
fit_logit.predict(type="response") # 概率尺度
fit_logit.predict(type="link") # 线性预测值
# 平均边际效应(需安装 marginaleffects)
from marginaleffects import avg_slopes
avg_slopes(fit_logit, variables="X1")
Stata 对照:
logit Y_bin X1 X2
margins, dydx(X1)
9. 分位数回归
PyFixest:
fit_qr = pf.quantreg("Y ~ X1 + X2", data=data, quantile=[0.1, 0.25, 0.5, 0.75, 0.9])
# 可视化各分位数系数
pf.qplot(fit_qr)
Stata 对照:
qreg Y X1 X2, quantile(0.5)
sqreg Y X1 X2, quantile(0.1 0.25 0.5 0.75 0.9)
注意:PyFixest 的分位数回归目前不支持固定效应,与 Stata 的 qreg 一样。
10. 多模型批量估计语法
这是 PyFixest 从 R fixest 继承的杀手级特性。一行公式,自动跑多个模型。
csw0() — 累积逐步加入变量
PyFixest:
# 一行代码跑三个模型:
# (1) Y ~ X1
# (2) Y ~ X1 | f1
# (3) Y ~ X1 | f1 + f2
multi_fit = pf.feols("Y ~ X1 | csw0(f1, f2)", data=data, vcov="HC1")
multi_fit.etable()
Stata 对照(需要手动写三次):
reghdfe Y X1, noabsorb vce(robust)
eststo m1
reghdfe Y X1, absorb(f1) vce(robust)
eststo m2
reghdfe Y X1, absorb(f1 f2) vce(robust)
eststo m3
esttab m1 m2 m3
sw() / sw0() — 逐个替换变量
# sw: Y ~ X1 + X2 和 Y ~ X1 + C(f1)
fit_sw = pf.feols("Y ~ X1 + sw(X2, C(f1))", data=data)
# sw0: 先跑空的(仅 X1),再依次替换
fit_sw0 = pf.feols("Y ~ X1 + sw0(X2, C(f1))", data=data)
csw() — 累积加入(不含空基准)
# Y ~ X1 + X2 和 Y ~ X1 + X2 + C(f1)
fit_csw = pf.feols("Y ~ X1 + csw(X2, C(f1))", data=data)
多因变量
# 同时对 Y 和 Y2 回归
fit_multi_dep = pf.feols("Y + Y2 ~ X1 | f1", data=data)
fit_multi_dep.etable()
样本拆分
# 按 f1 分组跑回归
fit_split = pf.feols("Y ~ X1", data=data, split="f1")
访问单个模型
# 按公式名称
multi_fit.all_fitted_models["Y ~ X1"]
# 按索引
multi_fit.fetch_model(0)
# 批量更新标准误
multi_fit.vcov("iid").summary()
11. 假设检验进阶
11.1 Wald 联合检验
PyFixest:
fit = pf.feols("Y ~ X1 + X2 | f1", data=data)
# H0: X1 = 0 且 X2 = 0
fit.wald_test(R=np.eye(2))
# H0: X1 + 2*X2 = 2 且 X2 = 1
R = np.array([[1, 2], [0, 1]])
q = np.array([2.0, 1.0])
fit.wald_test(R=R, q=q)
Stata 对照:
reghdfe Y X1 X2, absorb(f1)
test X1 X2 // 联合 F 检验
test X1 + 2*X2 = 2 // 线性约束检验
11.2 Bonferroni 校正
fit1 = pf.feols("Y ~ X1 | f1", data=data)
fit2 = pf.feols("Y ~ X1", data=data)
pf.bonferroni([fit1, fit2], param="X1")
11.3 Romano-Wolf 校正
pf.rwolf([fit1, fit2], param="X1", reps=9999, seed=1234)
Stata 对照:
* 需安装 rwolf
* ssc install rwolf
rwolf Y, indepvar(X1) method(reg) reps(9999) seed(1234)
11.4 Westfall-Young 校正
pf.wyoung([fit1, fit2], param="X1", reps=9999, seed=1234)
11.5 联合置信区间
fit = pf.feols("Y ~ X1 + C(f1)", data=data)
fit.confint(joint=True)
12. DID 与事件研究设计
PyFixest 提供三种 DID/事件研究估计器:TWFE、Gardner's DID2S、以及 Local Projections DID (lpdid)。
12.1 TWFE 事件研究
PyFixest:
url = "https://raw.githubusercontent.com/py-econometrics/pyfixest/master/pyfixest/did/data/df_het.csv"
df_het = pd.read_csv(url)
# TWFE
fit_twfe = pf.feols(
"dep_var ~ i(rel_year, ref=-1.0) | state + year",
data=df_het,
vcov={"CRV1": "state"},
)
Stata 对照:
* 使用 reghdfe + i. 语法
reghdfe dep_var ib(-1).rel_year, absorb(state year) cluster(state)
* 或使用 eventdd / eventstudyinteract
12.2 Gardner's DID2S(两步法)
PyFixest:
fit_did2s = pf.did2s(
df_het,
yname="dep_var",
first_stage="~ 0 | state + year",
second_stage="~i(rel_year, ref=-1.0)",
treatment="treat",
cluster="state",
)
Stata 对照:
* 需安装 did2s
* ssc install did2s
did2s dep_var, first_stage(i.state i.year) second_stage(ib(-1).rel_year) ///
treatment(treat) cluster(state)
12.3 统一 API:event_study()
# TWFE
fit_twfe = pf.event_study(
data=df_het, yname="dep_var", idname="state",
tname="year", gname="g", estimator="twfe",
)
# DID2S
fit_did2s = pf.event_study(
data=df_het, yname="dep_var", idname="state",
tname="year", gname="g", estimator="did2s",
)
# 比较两种估计器
pf.etable([fit_twfe, fit_did2s])
12.4 事件研究图
pf.iplot(
[fit_did2s, fit_twfe],
coord_flip=False,
figsize=(900, 400),
title="TWFE vs DID2S",
)
12.5 面板数据可视化
pf.panelview(df_het, unit="state", time="year", treat="treat")
13. 回归表输出与可视化
13.1 etable() — 发表级回归表
etable() 是 PyFixest 的回归表生成器,可高度自定义。
fit1 = pf.feols("Y ~ X1 | f1", data=data)
fit2 = pf.feols("Y ~ X1 + X2 | f1", data=data)
pf.etable(
[fit1, fit2],
labels={"Y": "Log Wage", "X1": "Experience", "X2": "Education"},
felabels={"f1": "Industry FE"},
caption="Baseline Regression Results",
)
Stata 对照:
eststo clear
reghdfe Y X1, absorb(f1)
eststo m1
reghdfe Y X1 X2, absorb(f1)
eststo m2
esttab m1 m2, ///
label b(3) se(3) star(* 0.05 ** 0.01 *** 0.001) ///
title("Baseline Regression Results") ///
mtitles("(1)" "(2)")
13.2 dtable() — 描述性统计表
pf.dtable(data, vars=["Y", "X1", "X2"], stats=["mean", "sd", "min", "max", "count"])
Stata 对照:
summarize Y X1 X2
* 或
estpost summarize Y X1 X2
esttab, cells("mean sd min max count")
13.3 系数图
# 单模型系数图
fit.coefplot()
# 多模型系数图
pf.coefplot([fit1, fit2])
Stata 对照:
coefplot m1 m2, xline(0)
13.4 事件研究图 (iplot)
# 专为 i() 交互项设计的事件研究图
pf.iplot(fit_twfe, coord_flip=False)
Stata 对照:
event_plot, stub_lag(...) stub_lead(...)
* 或 coefplot 手动配置
14. 速查对照表
| | |
|---|
| reghdfe Y X1 X2, noabsorb | pf.feols("Y ~ X1 + X2", data=df) |
| reghdfe Y X1, noabsorb vce(robust) | pf.feols("Y ~ X1", data=df, vcov="HC1") |
| reghdfe Y X1, noabsorb vce(cluster id) | pf.feols("Y ~ X1", data=df, vcov={"CRV1":"id"}) |
| reghdfe Y X1, absorb(id) | pf.feols("Y ~ X1 | id", data=df) |
| reghdfe Y X1, absorb(id year) | pf.feols("Y ~ X1 | id + year", data=df) |
| reghdfe Y X1, absorb(id) cluster(id) | pf.feols("Y ~ X1 | id", data=df, vcov={"CRV1":"id"}) |
| ivreghdfe Y (X1=Z1 Z2), absorb(id) | pf.feols("Y ~ 1 | id | X1 ~ Z1 + Z2", data=df) |
| ppmlhdfe Y X1, absorb(id) | pf.fepois("Y ~ X1 | id", data=df) |
| logit Y X1 i.id | pf.feglm("Y ~ X1 + C(id)", data=df, family="logit") |
| qreg Y X1, q(0.5) | pf.quantreg("Y ~ X1", data=df, quantile=0.5) |
| boottest X1 | fit.wildboottest(param="X1", reps=999) |
| ritest X1 _b[X1]: reg Y X1 | fit.ritest(resampvar="X1=0", reps=1000) |
| did2s dep_var, ... | pf.did2s(df, yname=..., ...) |
| esttab m1 m2 | pf.etable([fit1, fit2]) |
| coefplot m1 m2 | pf.coefplot([fit1, fit2]) |
| summarize Y X1 X2 | pf.dtable(df, vars=["Y","X1","X2"]) |
| | pf.feols("Y ~ X1 | csw0(f1,f2)", data=df) |
| | pf.bonferroni([fit1,fit2], param="X1") |
| rwolf Y, ... | pf.rwolf([fit1,fit2], param="X1", reps=9999) |
| test X1 X2 | fit.wald_test(R=np.eye(2)) |
| | fit.vcov("HC1") / fit.vcov({"CRV1":"id"}) |
15. 踩坑指南:一些实际处理中的bug
15.1 feglm() 不支持 | 吸收固定效应
这是最容易中招的一个。官方 Quickstart 文档展示了 feglm("Y ~ X1 | f1", family="logit") 语法,但在 v0.40 中运行会直接报 NotImplementedError。
# ❌ 报错:NotImplementedError: Fixed effects are not yet supported for GLMs.
pf.feglm("Y ~ X1 + X2 | f1", data=df, family="logit")
# ✅ 正确做法:用 C() 生成哑变量
pf.feglm("Y ~ X1 + X2 + C(f1)", data=df, family="logit")
这意味着 feglm() 目前无法高效处理高维固定效应(如个体 FE)。如果 FE 维度很高(>1000 个水平),考虑使用 fepois() 替代(Poisson 支持 | FE),或者等待未来版本更新。
15.2 HC2/HC3 不兼容吸收固定效应
# ❌ 报错:VcovTypeNotSupportedError
pf.feols("Y ~ X1 | f1", data=df, vcov="HC3")
# ✅ 替代方案 1:使用 CRV3(基于 jackknife 的聚类稳健标准误)
pf.feols("Y ~ X1 | f1", data=df, vcov={"CRV3": "f1"})
# ✅ 替代方案 2:用 C() 而非 | ,就可以用 HC3
pf.feols("Y ~ X1 + C(f1)", data=df.dropna(subset=["f1"]), vcov="HC3")
在 Stata 中,reghdfe Y X1, absorb(f1) vce(robust) 只对应 HC1,不是 HC3。所以这个限制在实际研究中影响不大——大多数实证论文使用 CRV1 或 HC1。
15.3 聚类变量不能含缺失值
Stata 会静默丢弃聚类变量中的缺失值;PyFixest 会直接报错。
# ❌ 如果 f1 有 NaN,会报错
pf.feols("Y ~ X1", data=df, vcov={"CRV1": "f1"})
# ✅ 先手动丢弃
df_clean = df.dropna(subset=["f1"])
pf.feols("Y ~ X1", data=df_clean, vcov={"CRV1": "f1"})
15.4 C() 不能嵌套在 sw() / csw() 里
公式解析器会将 C() 的括号当作 sw() 分组的一部分,导致语法错误。
# ❌ 报错:FormulaSyntaxError
pf.feols("Y ~ X1 + sw0(X2, C(f1))", data=df)
# ✅ 解决方案:预先生成哑变量列
df = pd.get_dummies(df, columns=["f1"], prefix="f1", drop_first=True)
# 然后在公式中直接引用哑变量列名
或者更优雅的方式——把带 C() 的模型单独跑,不走 sw() 语法。
15.5 wildboottest() 和 rwolf() 需要单独安装依赖
pip install wildboottest
没有安装时,fit.wildboottest() 和 pf.rwolf() 会抛出 UnboundLocalError,而不是一个清晰的"缺少依赖"错误提示。
15.6 IV 公式中无外生变量时必须写 1
# ❌ 语法错误——Part 1 不能为空
pf.feols("Y ~ | f1 | X1 ~ Z1", data=df)
# ✅ 用 1 作为占位
pf.feols("Y ~ 1 | f1 | X1 ~ Z1", data=df)
15.7 i() 的 ref 必须匹配数据类型
如果你的相对时间变量是 float64(从 Stata .dta 读入常见此情况),ref 也必须是浮点数:
# ❌ 如果 rel_year 是 float 类型,ref=-1 (int) 不匹配 → 所有系数都会被估计
pf.feols("Y ~ i(rel_year, ref=-1) | id + year", data=df)
# ✅ 使用 float
pf.feols("Y ~ i(rel_year, ref=-1.0) | id + year", data=df)
# ✅ 或者先转换类型
df["rel_year"] = df["rel_year"].astype(int)
pf.feols("Y ~ i(rel_year, ref=-1) | id + year", data=df)
15.8 小样本校正 (SSC) 默认值与 Stata 不同
这不是 bug,但会让你在比对结果时困惑。两个关键差异:
| | | |
|---|
| k_adj=True | k_adj=False | ssc=pf.ssc(k_adj=False) |
| G_df="min" | G_df="conventional" | ssc=pf.ssc(G_df="conventional") |
单维聚类 (CRV1) 和 HC1 的默认值与 Stata 完全一致,无需调整。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
