Python 如何用Python在30分钟内读完一本书
- 2026-06-27 17:31:21

阅读的低效与AI的局限
传统阅读方式跟不上现在的节奏。一本300页的书,按正常阅读速度,至少需要6-8小时。而且,人的注意力有限,翻到后面可能忘了前面的内容。那用AI直接总结呢?也有问题。GPT-4很强大,但它有上下文窗口限制。不能直接把整本书丢给它,超过一定长度就会报错或丢失信息。而且,全部用GPT-4处理,成本也高得离谱。
这就是现实困境:手动慢,AI有限制,成本还高。但问题总有解决办法。
往期阅读>>>
Python 自动化管理Jenkins的15个实用脚本,提升效率
App2Docker:如何无需编写Dockerfile也可以创建容器镜像
Python 自动化识别Nginx配置并导出为excel文件,提升Nginx管理效率
核心思路:用Python破解上下文限制
策略很简单:分而治之。
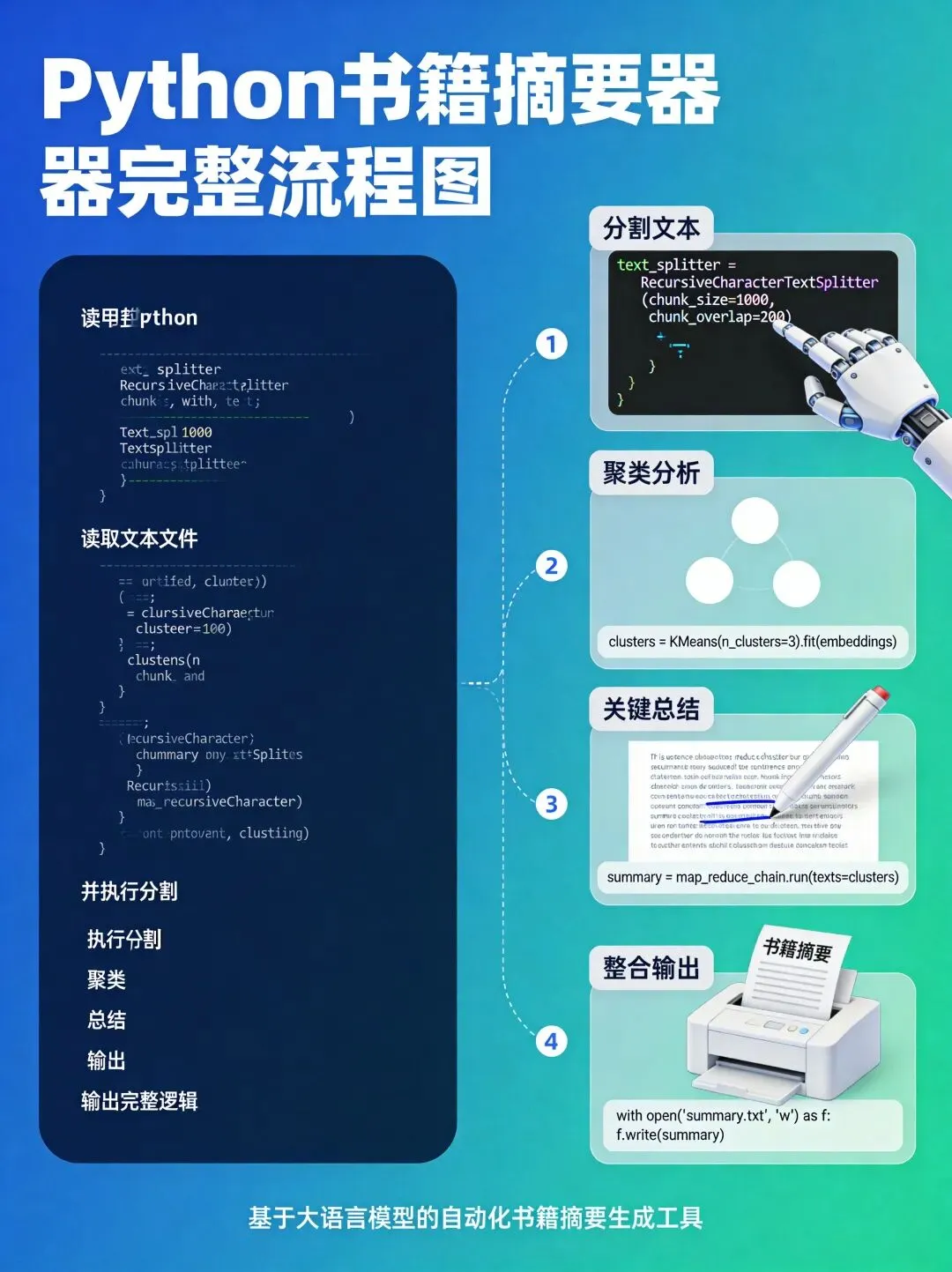
具体来说,就是四步:
分割:把整本书切成小块
聚类:找出最有代表性的部分
总结:用便宜的GPT-3.5总结关键块
整合:用GPT-4拼成流畅的最终摘要
只在最后一步用GPT-4,前面都用GPT-3.5,这样成本能降到原来的十分之一。聚类算法帮我们自动找出书中最重要的部分,不会错过核心内容。
与传统AI工具的区别
市面上很多AI阅读工具,大多采用“顺序摘要”的方式。按章节顺序,逐章总结,最后拼在一起。问题在哪?
信息冗余:有些章节内容重复,总结时重复处理
重点遗漏:关键章节可能只占10%,但顺序摘要一视同仁
成本浪费:把80%的篇幅都用昂贵的模型处理
本文的方法不一样。通过聚类自动识别书中的“核心章节”,优先处理最有代表性的内容。这就好比,传统方法是“把整本书都读一遍”,本文的方法是“先找精华部分,再细读”。效果上,不仅节省时间和成本,而且总结质量更高,因为真正聚焦在核心内容上。
动手实现:完整的Python代码
步骤一:加载书籍内容
首先,我们需要读取PDF或EPUB格式的书籍。
importosimporttempfilefromlangchain.document_loadersimportPyPDFLoader, UnstructuredEPubLoaderdefload_book(file_obj, file_extension):text = ""withtempfile.NamedTemporaryFile(delete=False, suffix=file_extension) astemp_file:temp_file.write(file_obj.read())iffile_extension == ".pdf":loader = PyPDFLoader(temp_file.name)pages = loader.load()text = "".join(page.page_contentforpageinpages)eliffile_extension == ".epub":loader = UnstructuredEPubLoader(temp_file.name)data = loader.load()text = "\n".join(element.page_contentforelementindata)else:raiseValueError(f"不支持的文件格式: {file_extension}")os.remove(temp_file.name)text = text.replace('\t', ' ')returntext
这段代码会自动识别PDF或EPUB格式,提取纯文本内容。
步骤二:分割文本并生成嵌入
接下来,把大文本切成小块,再转换成向量。
fromlangchain.text_splitterimportRecursiveCharacterTextSplitterfromlangchain.embeddingsimportOpenAIEmbeddingsdefsplit_and_embed(text, openai_api_key):text_splitter = RecursiveCharacterTextSplitter(separators=["\n\n", "\n", "\t"],chunk_size=10000,chunk_overlap=3000 )docs = text_splitter.create_documents([text])embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)vectors = embeddings.embed_documents([x.page_contentforxindocs])returndocs, vectors
这里的关键是chunk_overlap=3000,确保相邻块有重叠,避免丢失上下文。
步骤三:聚类找出核心章节
用KMeans算法聚类,找出最具代表性的文本块。
fromsklearn.clusterimportKMeansimportnumpyasnpdefcluster_embeddings(vectors, num_clusters):kmeans = KMeans(n_clusters=num_clusters, random_state=42).fit(vectors)# 找到每个聚类中心的最近点closest_indices = [np.argmin(np.linalg.norm(vectors-center, axis=1))forcenterinkmeans.cluster_centers_ ]returnsorted(closest_indices)
num_clusters=11是根据经验值,对于大多数书籍来说,11个聚类能很好地覆盖核心内容。你可以根据书的内容调整这个参数。
步骤四:总结关键块
用GPT-3.5总结选中的关键块。
fromlangchain.chains.summarizeimportload_summarize_chainfromlangchain.chat_modelsimportChatOpenAIfromlangchain.promptsimportPromptTemplatedefsummarize_chunks(docs, selected_indices, openai_api_key):llm3_turbo = ChatOpenAI(temperature=0,openai_api_key=openai_api_key,max_tokens=1000,model='gpt-3.5-turbo-16k' )map_prompt = """ 你是一个书籍摘要专家。请对下面的书籍片段进行全面总结。 确保准确性,不要添加原文中没有的解释或额外细节。 摘要至少包含三个段落,完整捕捉片段的核心内容。 书籍片段: ```{text}``` 摘要: """map_prompt_template = PromptTemplate(template=map_prompt, input_variables=["text"])selected_docs = [docs[i] foriinselected_indices]summary_list = []fordocinselected_docs:chunk_summary = load_summarize_chain(llm=llm3_turbo,chain_type="stuff",prompt=map_prompt_template ).run([doc])summary_list.append(chunk_summary)return"\n".join(summary_list)
这里用的是GPT-3.5-turbo-16k,它的上下文窗口足够大,而且价格便宜,适合批量处理。
步骤五:整合成最终摘要
用GPT-4把所有摘要整合成一个流畅的整体。
fromlangchain.schemaimportDocumentdefcreate_final_summary(summaries, openai_api_key):llm4 = ChatOpenAI(temperature=0,openai_api_key=openai_api_key,max_tokens=3000,model='gpt-4',request_timeout=120 )combine_prompt = """ 你是一个专业的书籍编辑。请把下面的书籍章节摘要整合成一个连贯、详细的总体摘要。 读者应该能够通过你的摘要理解书中的主要事件或观点。 确保内容的准确性,并以清晰、引人入胜的方式呈现。 章节摘要: ```{text}``` 连贯摘要: """combine_prompt_template = PromptTemplate(template=combine_prompt, input_variables=["text"])reduce_chain = load_summarize_chain(llm=llm4,chain_type="stuff",prompt=combine_prompt_template )final_summary = reduce_chain.run([Document(page_content=summaries)])returnfinal_summary
这一步是关键,GPT-4负责把分散的摘要“缝合”成一个整体,确保逻辑连贯。
完整使用示例
把所有步骤整合起来:
defgenerate_summary(uploaded_file, openai_api_key, num_clusters=11):file_extension = os.path.splitext(uploaded_file.name)[1].lower()text = load_book(uploaded_file, file_extension)docs, vectors = split_and_embed(text, openai_api_key)selected_indices = cluster_embeddings(vectors, num_clusters)summaries = summarize_chunks(docs, selected_indices, openai_api_key)final_summary = create_final_summary(summaries, openai_api_key)returnfinal_summaryif__name__ == '__main__':importosfromdotenvimportload_dotenvload_dotenv()openai_api_key = os.getenv('OPENAI_API_KEY')book_path = "你的书籍文件.epub"withopen(book_path, 'rb') asuploaded_file:summary = generate_summary(uploaded_file, openai_api_key)print(summary)
就这么简单,30分钟内搞定一本书的完整摘要。
总结本文方法的优势:
1. 突破上下文限制
把整本书分成小块,再智能整合
不用担心AI处理不了长文本
2. 大幅降低成本
主要用便宜的GPT-3.5
只在最后整合时用一次GPT-4
成本不到传统方法的1/10
3. 保证内容质量
聚类算法自动找出核心章节
不会错过重要内容
也不会在无关章节上浪费时间
4. 高度可定制
调整num_clusters参数控制详细程度
自定义提示词适应不同类型书籍
支持PDF和EPUB等多种格式

想高效学习Python?下面三本精选好书满足你的不同需求!
《流畅的Python(第2版)》——Python进阶必读!深入讲解高级特性与最佳实践,适合想精进的开发者。
《Python从新手到高手》:初学者首选,系统学习全栈技能。
《Python数据分析:从零基础入门到案例实战》——数据科学利器!手把手教你用Python处理数据,实战案例学完就能用。
三本书均支持先用后付、运费险和7天无理由退货,放心购买!点击“购买”按钮,立即开启你的Python学习之旅吧!
https://ima.qq.com/wiki/?shareId=f2628818f0874da17b71ffa0e5e8408114e7dbad46f1745bbd1cc1365277631c


