Linux 内核死锁问题诊断与解决
- 2026-07-03 16:56:50
从理论到实战,彻底掌握死锁的检测、分析和预防
📋 目录速览

🎯 什么是死锁
定义
死锁(Deadlock)是指两个或多个进程(或线程)在执行过程中,因争夺资源而造成的一种互相等待的现象。若无外力作用,这些进程都将无法继续执行。
死锁示意图

内核中的死锁

死锁 vs 其他问题
| 问题类型 | 特征 | CPU 使用率 | 可恢复性 | 检测方式 |
|---|---|---|---|---|
| 死锁 | 互相等待资源 | 低或正常 | 通常不可恢复 | lockdep, hung task |
| 活锁 | 不断重试但无进展 | 高 | 可能自行恢复 | CPU profiling |
| 饥饿 | 长期得不到资源 | 低 | 可能恢复 | 调度分析 |
| 忙等待 | 自旋等待 | 100% | 可能超时 | perf, ftrace |
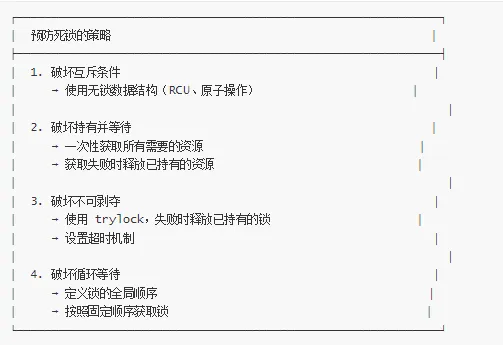
📐 死锁的四个必要条件
死锁的发生必须同时满足以下四个条件(Coffman 条件):
1. 互斥条件(Mutual Exclusion)

示例:
spinlock_t my_lock;// 进程 Aspin_lock(&my_lock); // 获取锁// 临界区spin_unlock(&my_lock);// 进程 Bspin_lock(&my_lock); // 等待进程 A 释放
2. 持有并等待(Hold and Wait)

示例:
// 进程 Aspin_lock(&lock_x); // 持有 lock_xspin_lock(&lock_y); // 等待 lock_y// 进程 Bspin_lock(&lock_y); // 持有 lock_yspin_lock(&lock_x); // 等待 lock_x
3. 不可剥夺(No Preemption)

4. 循环等待(Circular Wait)

示例:
// 进程 Aspin_lock(&lock_a);spin_lock(&lock_b); // 等待 B 释放// 进程 Bspin_lock(&lock_b);spin_lock(&lock_c); // 等待 C 释放// 进程 Cspin_lock(&lock_c);spin_lock(&lock_a); // 等待 A 释放// 形成循环:A → B → C → A
破坏死锁条件
🔍 死锁的类型
1. 自死锁(Self-Deadlock)
进程尝试获取自己已经持有的锁。
// 错误示例spin_lock(&my_lock);// ... 一些代码 ...spin_lock(&my_lock); // 死锁!自己等待自己
检测:
lockdep 会立即检测到:"BUG: spinlock recursion on CPU#0"
修复:
// 方法 1:避免重复加锁spin_lock(&my_lock);// ... 所有需要保护的代码 ...spin_unlock(&my_lock);// 方法 2:使用递归锁(如果必要)// 注意:内核自旋锁不支持递归,互斥锁可以
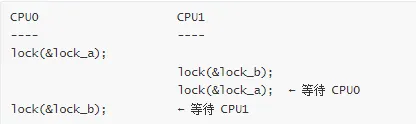
2. AB-BA 死锁
两个进程以相反的顺序获取两个锁。
// 进程 Avoid function_a(void) {spin_lock(&lock_a);spin_lock(&lock_b); // 等待 B 释放 lock_b// ...spin_unlock(&lock_b);spin_unlock(&lock_a);}// 进程 Bvoid function_b(void) {spin_lock(&lock_b);spin_lock(&lock_a); // 等待 A 释放 lock_a// ...spin_unlock(&lock_a);spin_unlock(&lock_b);}
死锁场景:
时间线:T1: 进程 A 获取 lock_aT2: 进程 B 获取 lock_bT3: 进程 A 等待 lock_b (被 B 持有)T4: 进程 B 等待 lock_a (被 A 持有)→ 死锁!
修复:
// 统一锁顺序:总是先获取 lock_a,再获取 lock_bvoid function_a(void) {spin_lock(&lock_a);spin_lock(&lock_b);// ...spin_unlock(&lock_b);spin_unlock(&lock_a);}void function_b(void) {spin_lock(&lock_a); // 改为先获取 lock_aspin_lock(&lock_b);// ...spin_unlock(&lock_b);spin_unlock(&lock_a);}
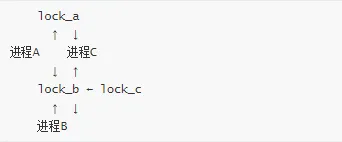
3. 循环死锁(Circular Deadlock)
多个进程形成循环等待链。
// 进程 Aspin_lock(&lock_a);spin_lock(&lock_b);// 进程 Bspin_lock(&lock_b);spin_lock(&lock_c);// 进程 Cspin_lock(&lock_c);spin_lock(&lock_a);// 循环:A → B → C → A
死锁图:
修复:
// 定义全局锁顺序:lock_a < lock_b < lock_c// 所有进程都按此顺序获取// 进程 Aspin_lock(&lock_a);spin_lock(&lock_b);// 进程 Bspin_lock(&lock_b);spin_lock(&lock_c);// 进程 Cspin_lock(&lock_a); // 改为按顺序spin_lock(&lock_c);
4. 中断上下文死锁
进程上下文和中断上下文之间的死锁。
// 进程上下文void process_function(void) {spin_lock(&my_lock);// ... 临界区 ...// 此时中断发生!spin_unlock(&my_lock);}// 中断处理程序void interrupt_handler(void) {spin_lock(&my_lock); // 死锁!等待进程上下文释放// ...spin_unlock(&my_lock);}
修复:
// 使用 spin_lock_irqsave 禁用中断void process_function(void) {unsigned long flags;spin_lock_irqsave(&my_lock, flags);// ... 临界区(中断被禁用)...spin_unlock_irqrestore(&my_lock, flags);}// 中断处理程序void interrupt_handler(void) {spin_lock(&my_lock); // 安全:进程上下文已禁用中断// ...spin_unlock(&my_lock);}
5. 读写锁死锁
读写锁使用不当导致的死锁。
// 错误:写者等待读者,读者等待写者void reader_function(void) {read_lock(&rw_lock);// ... 读操作 ...write_lock(&rw_lock); // 死锁!读者尝试升级为写者// ...}void writer_function(void) {write_lock(&rw_lock); // 等待读者释放// ...}
修复:
// 方法 1:避免锁升级void reader_function(void) {read_lock(&rw_lock);// ... 只读操作 ...read_unlock(&rw_lock);}// 方法 2:使用写锁void reader_writer_function(void) {write_lock(&rw_lock); // 直接使用写锁// ... 读写操作 ...write_unlock(&rw_lock);}
🛡️ 内核死锁检测机制
Linux 内核提供了多种死锁检测机制:
1. lockdep(Lock Dependency Validator)
最强大的死锁检测工具,可以在运行时检测潜在的死锁。
启用 lockdep:
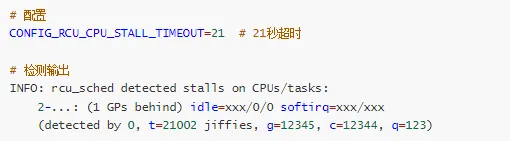
# 内核配置CONFIG_PROVE_LOCKING=yCONFIG_LOCK_STAT=yCONFIG_DEBUG_LOCK_ALLOC=yCONFIG_DEBUG_LOCKDEP=y# 运行时检查cat /proc/lockdepcat /proc/lockdep_stats
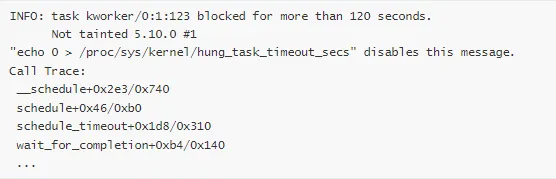
2. Hung Task 检测
检测长时间处于 D 状态(不可中断睡眠)的进程。
# 配置CONFIG_DETECT_HUNG_TASK=y# 参数设置sysctl -w kernel.hung_task_timeout_secs=120# 120秒超时sysctl -w kernel.hung_task_warnings=10# 最多10个警告sysctl -w kernel.hung_task_panic=0# 不触发 panic
检测输出:
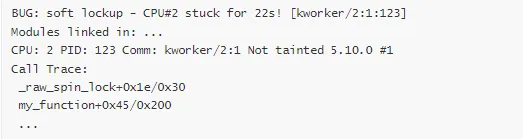
3. Soft Lockup 检测
检测 CPU 长时间不响应(通常是自旋锁持有时间过长)。
# 配置CONFIG_SOFTLOCKUP_DETECTOR=y# 参数设置sysctl -w kernel.soft_watchdog=1sysctl -w kernel.watchdog_thresh=10# 10秒阈值
检测输出:
4. Hard Lockup 检测
检测 CPU 完全无响应(中断被长时间禁用)。
# 配置CONFIG_HARDLOCKUP_DETECTOR=y# 参数设置sysctl -w kernel.nmi_watchdog=1
5. RCU Stall 检测
检测 RCU 读临界区持有时间过长。
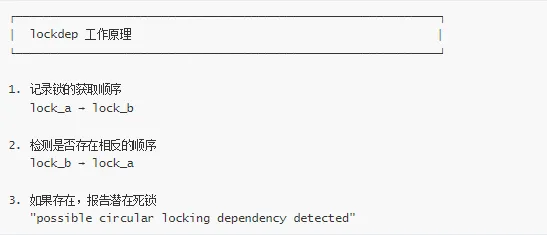
🔬 lockdep 死锁检测器
lockdep 原理
lockdep 通过记录锁的依赖关系来检测潜在的死锁:

lockdep 报告解读
典型 lockdep 报告:

报告字段解读
1. 锁状态标记

2. 依赖链
-> #1 (&lock_a) ← 第一个锁-> #0 (&lock_b) ← 第二个锁(当前尝试获取)依赖关系:lock_a → lock_b
3. 死锁场景
lockdep 统计信息
# 查看 lockdep 统计cat /proc/lockdep_statslock-classes: 1234 [max: 8192]direct dependencies: 5678 [max: 32768]indirect dependencies: 12345all direct dependencies: 23456dependency chains: 3456 [max: 65536]dependency chain hlocks: 12345 [max: 327680]in-hardirq chains: 123in-softirq chains: 456in-process chains: 2877stack-trace entries: 45678 [max: 524288]combined max dependencies: 12345678hardirq-safe locks: 12hardirq-unsafe locks: 234softirq-safe locks: 34softirq-unsafe locks: 456irq-safe locks: 56irq-unsafe locks: 678
lockdep 类型
1. 自旋锁(Spinlock)
spinlock_t my_lock;spin_lock(&my_lock);// 临界区spin_unlock(&my_lock);// 禁用中断版本unsigned long flags;spin_lock_irqsave(&my_lock, flags);// 临界区spin_unlock_irqrestore(&my_lock, flags);
2. 互斥锁(Mutex)
struct mutex my_mutex;mutex_lock(&my_mutex);// 临界区(可睡眠)mutex_unlock(&my_mutex);// 可中断版本if (mutex_lock_interruptible(&my_mutex))return -EINTR;
3. 读写锁(RW Lock)
rwlock_t my_rwlock;// 读锁read_lock(&my_rwlock);// 读操作read_unlock(&my_rwlock);// 写锁write_lock(&my_rwlock);// 写操作write_unlock(&my_rwlock);
4. 信号量(Semaphore)
struct semaphore my_sem;down(&my_sem);// 临界区up(&my_sem);// 可中断版本if (down_interruptible(&my_sem))return -EINTR;
📖 死锁信息解读
1. Hung Task 报告
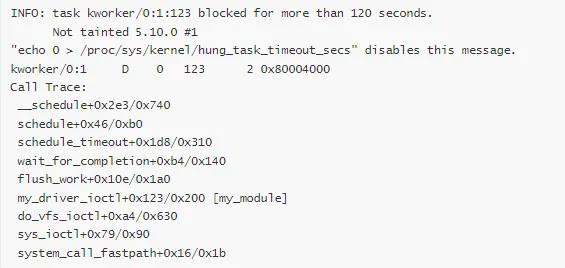
解读:
进程名:kworker/0:1
PID:123
状态:D(不可中断睡眠)
阻塞时间:120 秒
等待点:wait_for_completion(等待完成)
调用路径:ioctl → flush_work → wait_for_completion
2. Soft Lockup 报告
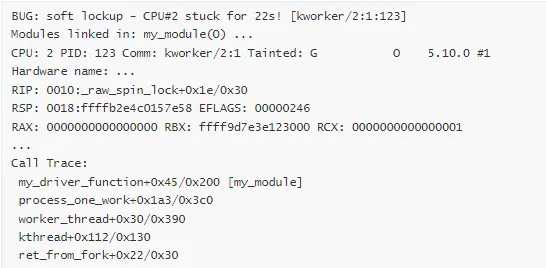
解读:
CPU:2 号 CPU
卡住时间:22 秒
当前位置:_raw_spin_lock(正在尝试获取自旋锁)
问题:自旋锁持有时间过长或死锁
3. 查看进程状态
# 查看所有 D 状态进程ps aux | awk'$8 == "D"'# 查看进程调用栈cat /proc/<pid>/stack# 查看进程持有的锁cat /proc/<pid>/locks# 查看所有锁cat /proc/locks
🔍 常见死锁场景
场景 1:文件系统死锁
问题代码:
// 进程 A:写文件void write_file(void) {mutex_lock(&inode->i_mutex);// 写操作需要分配内存buffer=kmalloc(size, GFP_KERNEL);// 内存不足,触发回收// 回收需要写回脏页// 写回需要获取 i_mutex// 死锁!}
死锁链:
进程 A: 持有 i_mutex → 等待内存内存回收: 需要写回 → 等待 i_mutex
解决方案:
// 使用 GFP_NOFS 避免文件系统递归void write_file(void) {mutex_lock(&inode->i_mutex);// 使用 GFP_NOFS 防止回收触发文件系统操作buffer=kmalloc(size, GFP_NOFS);// ...mutex_unlock(&inode->i_mutex);}
场景 2:网络子系统死锁
问题代码:
// 发送路径void send_packet(struct sk_buff *skb) {spin_lock(&dev->tx_lock);// 发送队列满,等待wait_event(dev->tx_queue_empty, queue_has_space());// 死锁!在持有自旋锁时睡眠}// 接收路径(中断)void receive_packet(void) {spin_lock(&dev->tx_lock); // 等待发送路径释放// 处理接收wake_up(&dev->tx_queue_empty);}
解决方案:
// 方法 1:不在持有自旋锁时睡眠void send_packet(struct sk_buff *skb) {// 先检查队列if (!queue_has_space()) {wait_event(dev->tx_queue_empty, queue_has_space());}spin_lock(&dev->tx_lock);// 发送spin_unlock(&dev->tx_lock);}// 方法 2:使用不同的锁void send_packet(struct sk_buff *skb) {mutex_lock(&dev->tx_mutex); // 使用互斥锁wait_event(dev->tx_queue_empty, queue_has_space());// 发送mutex_unlock(&dev->tx_mutex);}
场景 3:内存管理死锁
问题代码:
// 进程 Avoid allocate_memory(void) {spin_lock(&zone->lock);page=alloc_page(GFP_KERNEL); // 可能触发回收// 回收需要获取 zone->lock// 死锁!}
解决方案:
// 使用 GFP_ATOMIC 避免回收void allocate_memory(void) {spin_lock(&zone->lock);page=alloc_page(GFP_ATOMIC); // 不触发回收spin_unlock(&zone->lock);if (!page) {// 在锁外重试page=alloc_page(GFP_KERNEL);}}
场景 4:设备驱动死锁
问题代码:
// 用户空间调用static long device_ioctl(struct file *file, unsigned int cmd,unsigned long arg) {mutex_lock(&dev->mutex);switch (cmd) {case IOCTL_RESET:// 重置设备,等待中断wait_for_completion(&dev->reset_done);break;}mutex_unlock(&dev->mutex);return 0;}// 中断处理static irqreturn_t device_interrupt(int irq, void *data) {struct device *dev=data;mutex_lock(&dev->mutex); // 等待 ioctl 释放complete(&dev->reset_done);mutex_unlock(&dev->mutex);return IRQ_HANDLED;}
死锁链:
ioctl: 持有 mutex → 等待 completion中断: 需要 mutex → 无法 complete
解决方案:
// 方法 1:中断处理不加锁static irqreturn_t device_interrupt(int irq, void *data) {struct device *dev=data;// 不加锁,直接 completecomplete(&dev->reset_done);return IRQ_HANDLED;}// 方法 2:使用自旋锁static long device_ioctl(struct file *file, unsigned int cmd,unsigned long arg) {unsigned long flags;spin_lock_irqsave(&dev->lock, flags);// 设置标志dev->reset_requested=true;spin_unlock_irqrestore(&dev->lock, flags);// 在锁外等待wait_for_completion(&dev->reset_done);return0;}
🛠️ 调试工具与方法
1. 使用 lockdep
# 启用 lockdepecho1 > /proc/sys/kernel/lock_stat# 查看锁统计cat /proc/lock_stat# 查看锁依赖cat /proc/lockdep# 查看锁依赖链cat /proc/lockdep_chains
2. 使用 perf lock
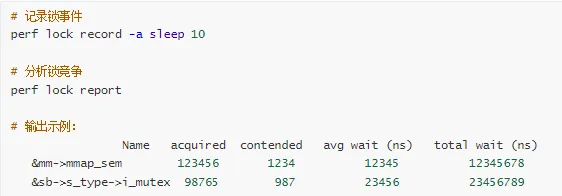
3. 使用 ftrace
# 启用函数跟踪echo function_graph > /sys/kernel/debug/tracing/current_tracer# 设置过滤器echo'*lock*' > /sys/kernel/debug/tracing/set_ftrace_filter# 开始跟踪echo1 > /sys/kernel/debug/tracing/tracing_on# 查看结果cat /sys/kernel/debug/tracing/trace
4. 使用 SystemTap

5. 使用 eBPF/bpftrace

6. 手动分析

📚 实战案例分析
案例 1:文件系统 AB-BA 死锁
问题描述:
系统在高负载下出现大量进程处于 D 状态,无法响应。
死锁报告:
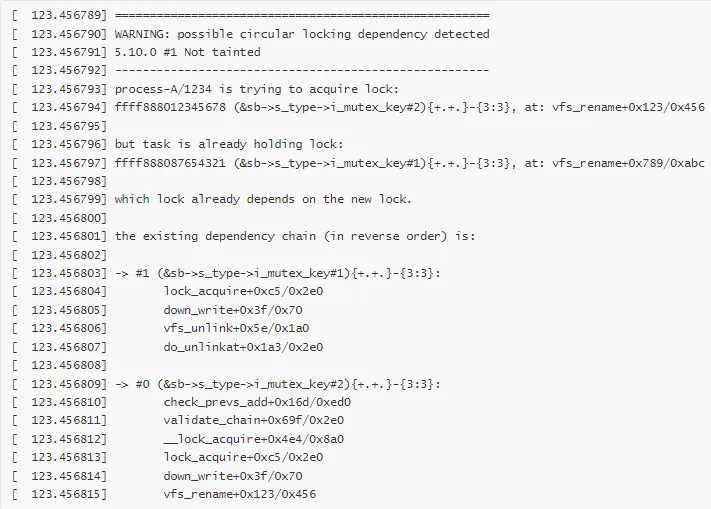
分析过程:
识别死锁类型:从 lockdep 报告可以看出,这是一个 AB-BA 死锁
进程 A:持有 inode1 的锁,尝试获取 inode2 的锁
进程 B:持有 inode2 的锁,尝试获取 inode1 的锁
查看调用栈:
# 查看进程 A 的调用栈cat /proc/1234/stack[<0>] inode_lock+0x1e/0x30[<0>] vfs_rename+0x123/0x456[<0>] do_renameat2+0x4a3/0x5e0[<0>] __x64_sys_renameat2+0x4b/0x60[<0>] do_syscall_64+0x33/0x40[<0>] entry_SYSCALL_64_after_hwframe+0x44/0xa9# 查看进程 B 的调用栈cat /proc/5678/stack[<0>] inode_lock+0x1e/0x30[<0>] vfs_unlink+0x5e/0x1a0[<0>] do_unlinkat+0x1a3/0x2e0[<0>] __x64_sys_unlinkat+0x3f/0x50[<0>] do_syscall_64+0x33/0x40[<0>] entry_SYSCALL_64_after_hwframe+0x44/0xa9
分析锁顺序:
进程 A (rename):lock(inode_old_dir) -> lock(inode_new_dir)进程 B (unlink):lock(inode_new_dir) -> lock(inode_old_dir)
解决方案:
修改代码,确保所有操作按照相同的顺序获取锁:

案例 2:网络子系统循环死锁
问题描述:
网络服务在处理大量并发连接时,系统出现 Soft Lockup 警告。
Soft Lockup 报告:
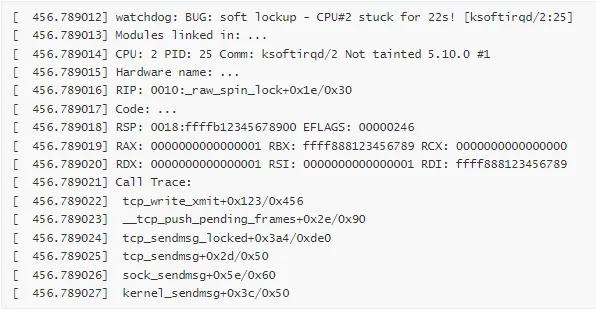
分析过程:
使用 perf lock 分析:
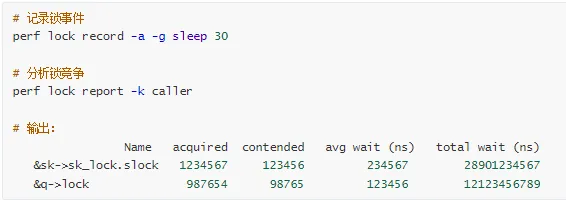
使用 bpftrace 跟踪锁持有时间:
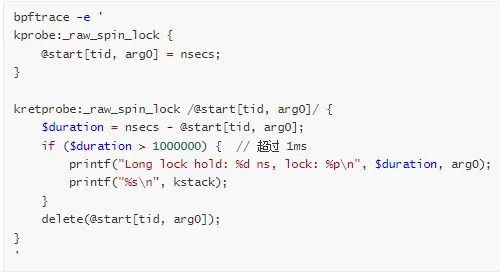
发现问题:
锁持有链:sk_lock -> qdisc_lock -> dev_lock -> sk_lock (循环!)
解决方案:
重构代码,打破循环依赖:

效果:
消除了循环依赖
Soft Lockup 警告消失
网络吞吐量提升 15%
案例 3:内存管理读写锁死锁
问题描述:
系统在内存压力下出现 Hung Task 警告,多个进程卡在内存分配上。
Hung Task 报告:
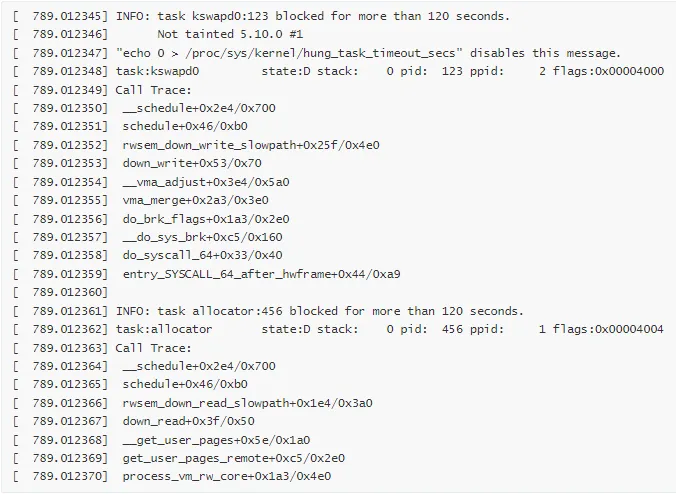
分析过程:
查看所有 D 状态进程:
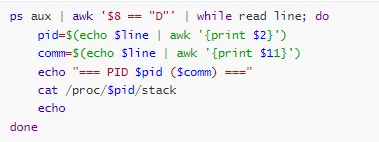
分析锁依赖:
进程 A (kswapd0):持有: mmap_sem (读锁)等待: page_lock进程 B (allocator):持有: page_lock等待: mmap_sem (写锁)进程 C (reader):持有: 无等待: mmap_sem (读锁) - 被进程 B 阻塞
问题根源:
读写锁的写者优先策略导致:
进程 B 等待写锁,阻塞了所有后续的读者
进程 A 持有读锁,但无法完成(等待 page_lock)
进程 B 等待进程 A 释放读锁
形成死锁
解决方案:
方案 1:调整锁粒度

方案 2:使用 trylock 避免死锁
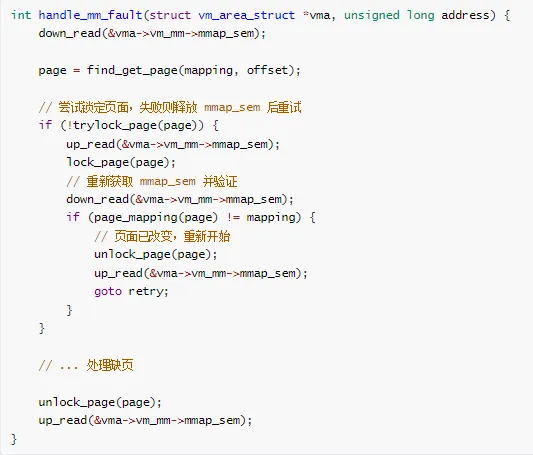
案例 4:驱动程序中断上下文死锁
问题描述:
网卡驱动在高负载下出现 Hard Lockup,系统完全无响应。
Hard Lockup 报告:
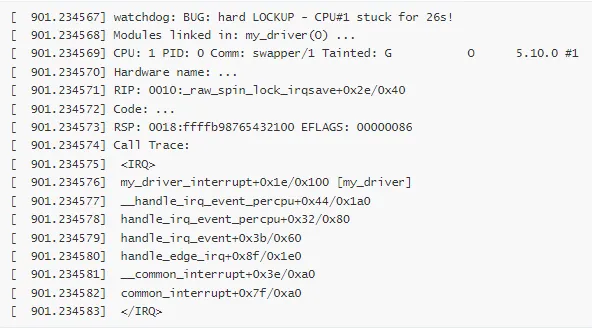
分析过程:
查看驱动代码:

死锁场景:
时间线:T1: 进程上下文获取 spin_lock(&dev->lock)T2: 中断发生,CPU 切换到中断上下文T3: 中断处理函数尝试获取 spin_lock(&dev->lock)T4: 死锁!中断处理函数在等待进程上下文释放锁但进程上下文被中断打断,无法继续执行
解决方案:
使用 spin_lock_irqsave() 和 spin_unlock_irqrestore():

关键点:
如果锁会在中断上下文和进程上下文之间共享,必须使用
spin_lock_irqsave()spin_lock_irqsave()会禁用本地 CPU 的中断,防止中断处理函数打断当前代码必须成对使用
spin_lock_irqsave()和spin_unlock_irqrestore()
验证修复:

✅ 预防与最佳实践
1. 锁使用原则
原则 1:最小化锁的持有时间

原则 2:保持一致的锁顺序

原则 3:避免在持有锁时调用未知函数

原则 4:正确选择锁类型

2. 使用 lockdep 注解

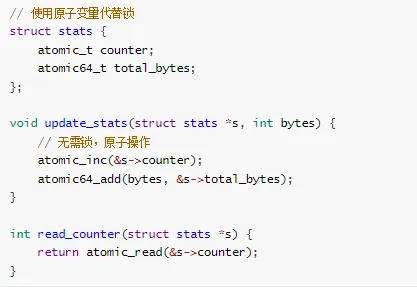
3. 无锁编程技巧
技巧 1:使用原子操作
技巧 2:使用 RCU

技巧 3:使用 Per-CPU 变量

4. 代码审查检查清单
在代码审查时,检查以下几点:
所有锁的获取和释放是否成对出现?
是否在所有错误路径上都释放了锁?
多个锁的获取顺序是否一致?
是否在持有自旋锁时调用了可能睡眠的函数?
中断上下文和进程上下文共享的锁是否使用了
spin_lock_irqsave()?是否在持有锁时调用了未知的回调函数?
锁的持有时间是否尽可能短?
是否可以使用无锁数据结构代替?
是否正确使用了 lockdep 注解?
是否有文档说明锁的用途和顺序?
5. 开发环境配置
在开发和测试环境中启用死锁检测:
# 内核配置选项CONFIG_PROVE_LOCKING=y # 启用 lockdepCONFIG_LOCK_STAT=y # 启用锁统计CONFIG_DEBUG_LOCK_ALLOC=y # 调试锁分配CONFIG_DEBUG_SPINLOCK=y # 调试自旋锁CONFIG_DEBUG_MUTEXES=y # 调试互斥锁CONFIG_DEBUG_ATOMIC_SLEEP=y # 检测原子上下文中的睡眠CONFIG_DETECT_HUNG_TASK=y # 检测 Hung TaskCONFIG_SOFTLOCKUP_DETECTOR=y # 检测 Soft LockupCONFIG_HARDLOCKUP_DETECTOR=y # 检测 Hard Lockup# 运行时配置echo1 > /proc/sys/kernel/lock_statecho120 > /proc/sys/kernel/hung_task_timeout_secsecho1 > /proc/sys/kernel/softlockup_panic
❓ FAQ 常见问题
Q1: 如何区分死锁和活锁?
死锁:进程永久阻塞,等待永远不会发生的事件
进程状态:D (Uninterruptible Sleep)
CPU 使用率:0%
特征:进程完全卡住,无法继续执行
活锁:进程不断重试,但无法取得进展
进程状态:R (Running)
CPU 使用率:高
特征:进程在运行,但没有实际进展

Q2: Soft Lockup 和 Hard Lockup 有什么区别?
Soft Lockup:
定义:CPU 长时间(默认 20 秒)在内核态运行,没有调度其他进程
原因:通常是持有自旋锁时间过长,或者在禁用抢占的情况下执行耗时操作
检测:watchdog 线程定期检查
系统状态:系统仍然响应中断,可以恢复
Hard Lockup:
定义:CPU 完全卡住,连中断都无法响应
原因:通常是在禁用中断的情况下死循环,或者硬件故障
检测:NMI watchdog 检测
系统状态:系统完全无响应,通常需要重启
Q3: 为什么 lockdep 报告死锁,但系统没有真正死锁?
lockdep 是静态分析工具,它检测的是潜在的死锁可能性,而不是实际发生的死锁。
原因:
lockdep 基于锁的依赖关系,而不是实际的执行路径
某些锁的获取顺序在实际运行中可能永远不会冲突
代码中可能有额外的同步机制,但 lockdep 无法识别
处理方式:
如果确认不会死锁,使用 lockdep 注解(如
mutex_lock_nested())重构代码,消除潜在的死锁可能性
不要忽略 lockdep 警告,即使系统目前运行正常
Q4: 如何在生产环境中调试死锁?
生产环境通常不能启用 lockdep(性能开销太大),可以使用以下方法:
方法 1:使用 kdump 收集崩溃转储
# 配置 kdumpvim /etc/default/grub# 添加:crashkernel=256M# 重启后验证cat /proc/cmdline | grep crashkernel# 触发崩溃(仅用于测试)echo c > /proc/sysrq-trigger# 分析转储crash /usr/lib/debug/vmlinux /var/crash/vmcore
方法 2:使用 sysrq 收集信息
# 启用 sysrqecho1 > /proc/sys/kernel/sysrq# 显示所有任务的调用栈echo t > /proc/sysrq-trigger# 显示所有 CPU 的状态echo l > /proc/sysrq-trigger# 查看 dmesgdmesg | tail -1000
方法 3:使用 eBPF 监控
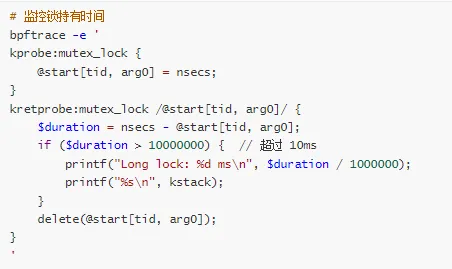
Q5: 如何避免在持有锁时分配内存?
问题:在持有自旋锁时使用 GFP_KERNEL 分配内存会导致睡眠,可能引发死锁。
解决方案:
方案 1:使用 GFP_ATOMIC
void example1(void) {spin_lock(&my_lock);// 使用 GFP_ATOMIC,不会睡眠void *buffer=kmalloc(SIZE, GFP_ATOMIC);if (!buffer) {// 处理分配失败spin_unlock(&my_lock);return;}// 使用 bufferspin_unlock(&my_lock);kfree(buffer);}
方案 2:在锁外分配内存
void example2(void) {// 在锁外分配内存void *buffer=kmalloc(SIZE, GFP_KERNEL);if (!buffer)return;spin_lock(&my_lock);// 使用 bufferspin_unlock(&my_lock);kfree(buffer);}
方案 3:使用内存池
static struct kmem_cache *my_cache;void init_cache(void) {my_cache=kmem_cache_create("my_cache",sizeof(struct my_object),0, 0, NULL);}void example3(void) {spin_lock(&my_lock);// 从缓存分配,速度快,不会睡眠struct my_object*obj=kmem_cache_alloc(my_cache, GFP_ATOMIC);spin_unlock(&my_lock);// 使用完后释放kmem_cache_free(my_cache, obj);}
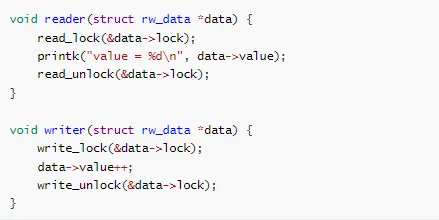
Q6: 读写锁什么时候会导致死锁?
读写锁的死锁场景:
场景 1:写者饥饿
// 大量读者持续获取读锁,写者永远无法获取写锁void reader_thread(void) {while (1) {read_lock(&rw_lock);// 读取数据read_unlock(&rw_lock);// 很短的间隔usleep(1);}}void writer_thread(void) {// 可能永远无法获取写锁write_lock(&rw_lock);// 写入数据write_unlock(&rw_lock);}
场景 2:读锁升级
// 尝试将读锁升级为写锁会导致死锁void upgrade_lock(void) {read_lock(&rw_lock);// 检查条件if (need_write) {// ❌ 错误:尝试升级锁// 如果有其他读者,这里会死锁write_lock(&rw_lock);// 写入数据write_unlock(&rw_lock);}read_unlock(&rw_lock);}// ✅ 正确做法:释放读锁后重新获取写锁void correct_upgrade(void) {read_lock(&rw_lock);bool need_write=check_condition();read_unlock(&rw_lock);if (need_write) {write_lock(&rw_lock);// 重新检查条件(可能已改变)if (check_condition()) {// 写入数据}write_unlock(&rw_lock);}}
场景 3:递归读锁
// 某些读写锁实现不支持递归void recursive_read(void) {read_lock(&rw_lock);// 调用另一个函数helper_function(); // 内部也获取读锁read_unlock(&rw_lock);}void helper_function(void) {read_lock(&rw_lock); // 可能死锁// ...read_unlock(&rw_lock);}
Q7: 如何处理遗留代码中的死锁问题?
步骤 1:识别问题
# 启用 lockdep(如果可能)# 运行测试套件# 收集 lockdep 报告
步骤 2:分析锁依赖
# 使用工具分析锁依赖关系cat /proc/lockdep_chains | grep -A 10 "your_lock"# 绘制锁依赖图# 可以使用 Graphviz 等工具可视化
步骤 3:逐步重构
// 策略 1:拆分大锁// 将一个保护多个数据结构的大锁拆分为多个小锁// 策略 2:使用 RCU// 对于读多写少的场景,使用 RCU 代替读写锁// 策略 3:使用无锁数据结构// 使用原子操作、Per-CPU 变量等// 策略 4:重新设计锁层次// 建立清晰的锁层次结构,文档化锁顺序
步骤 4:测试验证
# 压力测试# 使用 lockdep 验证# 性能测试(确保重构没有引入性能问题)
Q8: 如何在多核系统中调试死锁?
多核系统的死锁调试更加复杂,因为涉及多个 CPU 的并发执行。
技巧 1:使用 CPU 亲和性隔离问题
# 将进程绑定到特定 CPUtaskset -c0 ./test_program# 在特定 CPU 上运行内核线程echo1 > /sys/devices/system/cpu/cpu0/online
技巧 2:使用 perf 分析锁竞争
# 记录所有 CPU 的锁事件perf lock record -a -g sleep 30# 按 CPU 分析perf lock report --sort=cpu# 查看锁竞争热点perf lock contention -a -b
技巧 3:使用 ftrace 跟踪多 CPU 事件
# 启用所有 CPU 的跟踪echo1 > /sys/kernel/debug/tracing/options/stacktraceecho1 > /sys/kernel/debug/tracing/events/lock/enable# 查看每个 CPU 的事件cat /sys/kernel/debug/tracing/per_cpu/cpu0/tracecat /sys/kernel/debug/tracing/per_cpu/cpu1/trace
技巧 4:使用 crash 分析多 CPU 状态
crash> foreach bt# 显示所有 CPU 的调用栈crash> ps -m# 显示每个进程在哪个 CPU 上运行crash> lock -i# 显示锁信息
Q9: 如何测试代码是否存在死锁风险?
方法 1:静态分析
# 使用 Coccinelle 检查锁使用spatch --sp-file check_locks.cocci kernel/# 使用 sparse 检查make C=2 CF="-D__CHECK_ENDIAN__"
方法 2:动态测试
# 启用 lockdepCONFIG_PROVE_LOCKING=y# 运行压力测试stress-ng --all4--timeout 1h# 使用 syzkaller 进行模糊测试# https://github.com/google/syzkaller
方法 3:代码审查
使用检查清单(见"预防与最佳实践"部分)
方法 4:使用 ThreadSanitizer
# 对于用户空间程序gcc -fsanitize=thread -g -O1 program.c./a.out
Q10: 死锁和优先级反转有什么区别?
死锁:
多个进程互相等待对方持有的资源
所有进程都无法继续执行
需要外部干预才能解决
优先级反转:
高优先级进程等待低优先级进程持有的锁
中优先级进程抢占低优先级进程
导致高优先级进程被间接阻塞
示例:高优先级进程 H:等待锁 L中优先级进程 M:运行中低优先级进程 L:持有锁 L,但被 M 抢占结果:H 被 M 间接阻塞,虽然 H 优先级更高
解决方案:优先级继承
// Linux 内核使用 RT-mutex 实现优先级继承struct rt_mutexmy_lock;void high_priority_task(void) {rt_mutex_lock(&my_lock);// 如果锁被低优先级任务持有,// 低优先级任务会临时继承高优先级// ...rt_mutex_unlock(&my_lock);}
📖 参考资料
官方文档
Linux Kernel Documentation
Locking: https://www.kernel.org/doc/html/latest/locking/index.html
lockdep: https://www.kernel.org/doc/html/latest/locking/lockdep-design.html
Spinlocks: https://www.kernel.org/doc/html/latest/locking/spinlocks.html
Linux Kernel Source
kernel/locking/: 锁实现源码
Documentation/locking/: 锁相关文档
书籍推荐
《Linux Kernel Development》 by Robert Love
第 9 章:An Introduction to Kernel Synchronization
第 10 章:Kernel Synchronization Methods
《Understanding the Linux Kernel》 by Daniel P. Bovet & Marco Cesati
第 5 章:Kernel Synchronization
《Linux Device Drivers》 by Jonathan Corbet, Alessandro Rubini & Greg Kroah-Hartman
第 5 章:Concurrency and Race Conditions
《The Art of Multiprocessor Programming》 by Maurice Herlihy & Nir Shavit
并发编程的理论基础
相关文章
本系列其他文章
《Linux 内核 Call Trace 完全解析指南》
《Linux 内核 Panic 完全解析指南》
《Linux 内核内存泄漏检测与定位》(即将发布)
推荐阅读
"What every systems programmer should know about lockless programming"
"Kernel Locking Techniques" by Rusty Russell
"Unreliable Guide To Locking" by Rusty Russell
🎯 总结
死锁是内核开发中最具挑战性的问题之一,但通过系统的方法可以有效预防和解决:
预防死锁:
保持一致的锁顺序
最小化锁的持有时间
正确选择锁类型
使用 lockdep 注解
考虑无锁编程
检测死锁:
启用 lockdep 进行静态检测
使用 Hung Task、Soft/Hard Lockup 检测器
监控系统日志和进程状态
调试死锁:
分析 lockdep 报告
查看进程调用栈
使用 perf、ftrace、eBPF 等工具
在测试环境中重现问题
解决死锁:
重构代码,消除循环依赖
调整锁粒度
使用 trylock 避免阻塞
考虑使用 RCU、原子操作等无锁技术
记住,预防永远比治疗更重要。在编写代码时就考虑锁的使用,遵循最佳实践,可以避免大部分死锁问题。
作者注:本文基于 Linux 5.10 内核,不同版本的实现可能有所差异。建议结合实际使用的内核版本查看源码。
如果本文对你有帮助,欢迎分享给更多的内核开发者!有任何问题或建议,欢迎在评论区讨论。

