还在手动比对各家物流报价?写个Python脚本,让电脑帮你做选择题!
在电商、外贸、跨境业务中,物流成本往往是不可忽视的一环。不同渠道、不同重量区间,价格千差万别。面对动辄几十行的报价表,人工比对不仅费时,还容易出错。今天,我们就用Python写一个物流报价优化器,只需输入重量,就能自动匹配所有报价,并选出价格最低的渠道。
痛点场景
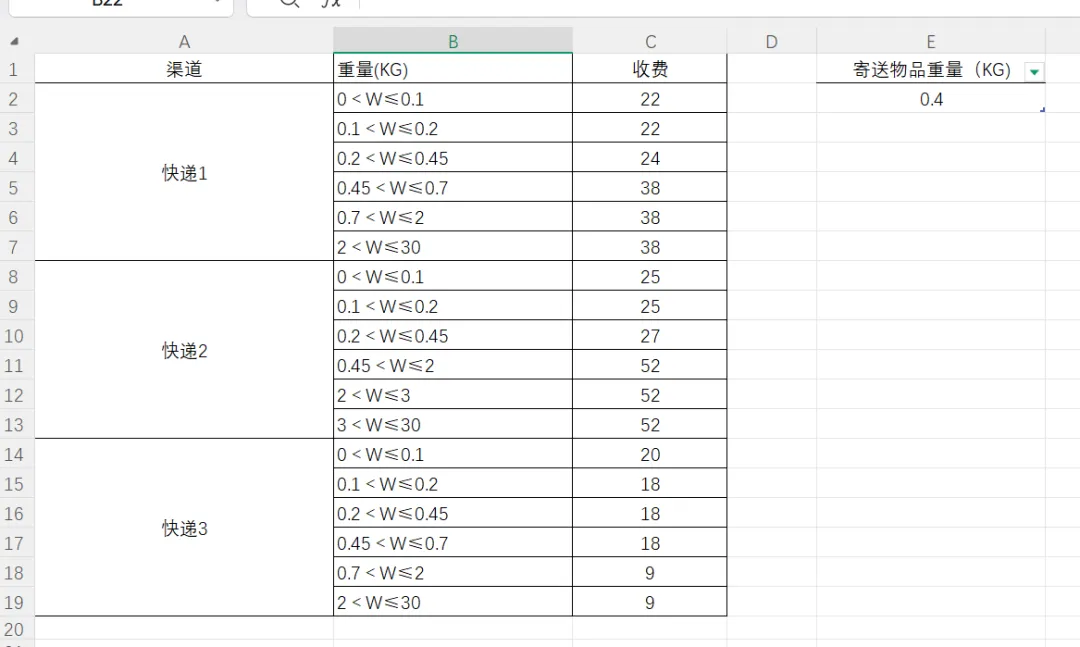
有一份Excel报价表,包含三列:
- 渠道:物流商名称(如“快递2”“快递1”“快递3”),这是快递公司。
- 重量表达式:重量区间,如
0<W≤0.5、0.5<W≤1、W>10
我们想要:
人工做这件事,需要逐个判断重量落在哪个区间,再比较价格。如果报价规则复杂(比如区间重叠、表达式多种多样),手动处理简直是灾难。
下面我们就用Python来彻底解决这个问题。
核心思路
整个优化器的核心逻辑分为三步:
- 解析重量表达式:将类似
0<W≤0.5的文本转换成Python能计算的表达式(例如0 < weight <= 0.5)。 - 评估匹配:对每个报价,把重量代入表达式,判断是否为真。
为了便于复用,我们把所有功能封装成一个类LogisticsPriceOptimizer,并提供简单的接口。
代码实现
代码包含以下几个主要部分:
1. 初始化与数据加载
classLogisticsPriceOptimizer:def__init__(self, data_file="物流报价数据.xlsx"): self.price_table = None self.actual_weight = None self.data_file = data_filedefload_price_data(self):# 读取Excel,检查必要列 self.price_table = pd.read_excel(self.data_file)# ... 数据验证和预览
使用pandas读取Excel,并验证是否包含“渠道”“重量表达式”“收费”三列。
2. 预处理表达式
defpreprocess_expressions(self, weight):deftransform_expression(expr):# 替换中文符号 expr = expr.replace("<", "<").replace("≤", "<=")# 将W替换为实际重量 expr = expr.replace("W", str(weight))return expr df['python_expression'] = df['重量表达式'].apply(transform_expression)
这一步把文本表达式变成可执行的Python表达式,如0<W≤0.5 → 0 < 0.4 <= 0.5。
3. 评估表达式
defevaluate_expressions(self, df):defsafe_eval(expr):try:return eval(expr)except:returnFalse df['matches'] = df['python_expression'].apply(safe_eval) matched = df[df['matches'] == True]return matched
用eval计算每个表达式的真假,筛选出匹配的行。
4. 找出最优方案
deffind_optimal_plan(self, matched_df): matched_df = matched_df.sort_values('收费', ascending=True) min_price = matched_df['收费'].min() optimal = matched_df[matched_df['收费'] == min_price]return optimal
按价格排序,取最低价对应的所有渠道(可能有多个价格相同)。
5. 整合流程
defcalculate_for_weight(self, weight): self.load_price_data() # 加载数据 processed = self.preprocess_expressions(weight) # 预处理 matched = self.evaluate_expressions(processed) # 匹配 optimal = self.find_optimal_plan(matched) # 最优return optimal
6. 批量计算
defbatch_calculate(self, weights, save_results=True): results = []for weight in weights:# ... 计算每个重量,收集结果 results_df = pd.DataFrame(results)if save_results: results_df.to_csv("批量计算结果.csv", encoding='utf-8-sig')return results_df
支持批量计算并自动保存为CSV文件。
实际演示
假设我们有一份Excel数据:
运行代码,输入重量0.4KG:
开始计算物流最优方案 (重量=0.4KG)============================================================正在评估 5 个表达式...匹配表达式数: 3匹配的表达式详情: 渠道 重量表达式 python_expression 收费 快递1 0<W≤0.5 0 < 0.4 <= 0.5 5.0 快递2 0.3<W≤0.8 0.3 < 0.4 <= 0.8 9.0 快递4 W≤1 0.4 <= 1 6.0最优物流方案 (重量=0.4KG):==========================================================最低价格: ¥5.0匹配渠道总数: 3最优渠道数量: 1最优渠道详情: • 快递1 重量区间: 0<W≤0.5 价格: ¥5.0
程序自动帮我们找到了最便宜的快递1,价格5元。
批量计算也毫无压力:
optimizer.batch_calculate([0.2, 0.6, 1.2])
输出汇总表格并保存为CSV。
附录:完整代码
import pandas as pdimport osclassLogisticsPriceOptimizer:""" 物流报价优化器类 用于根据重量和物流报价数据,计算最优的物流渠道方案 """def__init__(self, data_file="物流报价数据.xlsx"):""" 初始化物流报价优化器 Parameters: ----------- data_file : str, optional 物流报价数据文件路径,默认读取"物流报价数据.xlsx" """ self.price_table = None# 存储原始报价数据 self.actual_weight = None# 当前正在计算的重量 self.data_file = data_file # 数据文件路径defload_price_data(self):""" 直接从指定的Excel文件加载物流报价数据 Returns: -------- pandas.DataFrame: 加载的数据,如果失败则返回None """ file_path = self.data_fileifnot os.path.exists(file_path): print(f"错误:未找到文件 '{file_path}'") print("请确保 '物流报价数据.xlsx' 文件在当前目录中")returnNonetry:# 读取Excel文件 self.price_table = pd.read_excel(file_path) print(f"成功从Excel文件加载数据: {file_path}")# 检查必需的列是否存在 required_columns = ['渠道', '重量表达式', '收费'] missing_columns = [col for col in required_columns if col notin self.price_table.columns]if missing_columns: print(f"数据缺少必需的列: {missing_columns}") print(f"当前数据列: {list(self.price_table.columns)}") print("请确保Excel文件包含以下列:") print("1. '渠道' - 物流渠道名称") print("2. '重量表达式' - 重量区间表达式,如 '0<W≤0.1'") print("3. '收费' - 价格")returnNone print(f"\n数据加载成功:") print(f"文件: {file_path}") print(f"数据形状: {self.price_table.shape} (行数: {len(self.price_table)}, 列数: {len(self.price_table.columns)})") print(f"数据列: {list(self.price_table.columns)}")# 显示数据预览 print(f"\n数据预览 (前5行):") print(self.price_table.head().to_string(index=False))# 显示渠道信息 print(f"\n物流渠道汇总:") channels = self.price_table['渠道'].unique()for i, channel in enumerate(channels, 1): count = len(self.price_table[self.price_table['渠道'] == channel]) print(f" {i}. {channel} ({count}个报价)")return self.price_tableexcept Exception as e: print(f"加载文件时发生错误: {str(e)}")returnNonedefpreprocess_expressions(self, weight):""" 预处理重量表达式 将文本表达式转换为Python可执行的表达式 Parameters: ----------- weight : float 物品实际重量 Returns: -------- pandas.DataFrame: 处理后的数据,包含新列'python_expression' """if self.price_table isNone: print("请先加载数据!")returnNone self.actual_weight = weight# 复制数据,避免修改原始数据 df = self.price_table.copy()deftransform_expression(expr):"""转换单个表达式:替换符号,并将W替换为实际重量"""ifnot isinstance(expr, str): expr = str(expr)# 替换中文符号为Python符号 expr = expr.replace("<", "<").replace("≤", "<=")# 将表达式中的W替换为实际重量 expr = expr.replace("W", str(weight))return expr# 应用转换函数到每一行 df['python_expression'] = df['重量表达式'].apply(transform_expression) print(f"\n表达式预处理完成 (重量={weight}KG):") print(f"已处理 {len(df)} 个重量表达式")return dfdefevaluate_expressions(self, df):""" 评估表达式,返回匹配的行 Parameters: ----------- df : pandas.DataFrame 包含预处理表达式的数据 Returns: -------- pandas.DataFrame: 匹配的数据行 """if df isNoneor len(df) == 0: print("没有可评估的数据")returnNonedefsafe_eval(expr):"""安全地评估表达式"""try:# 使用eval计算表达式return eval(expr)except Exception as e: print(f"表达式评估错误: {expr} -> {str(e)}")returnFalse# 评估所有表达式 print(f"\n正在评估 {len(df)} 个表达式...") df['matches'] = df['python_expression'].apply(safe_eval)# 筛选出匹配的行 matched = df[df['matches'] == True].copy() print(f"\n表达式评估结果:") print(f"总表达式数: {len(df)}") print(f"匹配表达式数: {len(matched)}") print(f"匹配率: {len(matched)/len(df)*100:.1f}%")if len(matched) > 0: print(f"\n匹配的表达式详情:") display_df = matched[['渠道', '重量表达式', 'python_expression', '收费']] print(display_df.to_string(index=False))else: print(f"\n没有匹配的表达式")return matcheddeffind_optimal_plan(self, matched_df):""" 从匹配的行中找到最优方案(价格最低) Parameters: ----------- matched_df : pandas.DataFrame 匹配的数据行 Returns: -------- pandas.DataFrame: 最优方案数据(可能多个渠道价格相同) """if matched_df isNoneor len(matched_df) == 0: print(f"\n没有找到匹配重量 {self.actual_weight}KG 的物流渠道!")returnNone# 按价格升序排序 matched_df = matched_df.sort_values('收费', ascending=True)# 获取最优方案(最低价格) min_price = matched_df['收费'].min() all_optimal = matched_df[matched_df['收费'] == min_price] print(f"\n最优物流方案 (重量={self.actual_weight}KG):") print("="*50) print(f"最低价格: ¥{min_price}") print(f"匹配渠道总数: {len(matched_df)}") print(f"最优渠道数量: {len(all_optimal)}") print(f"\n最优渠道详情:")for idx, row in all_optimal.iterrows(): print(f" • {row['渠道']}") print(f" 重量区间: {row['重量表达式']}") print(f" 价格: ¥{row['收费']}") print()if len(all_optimal) < len(matched_df): print(f"\n其他匹配渠道 (价格较高):") other_channels = matched_df[matched_df['收费'] > min_price]for idx, row in other_channels.iterrows(): print(f" • {row['渠道']} - ¥{row['收费']} ({row['重量表达式']})")return all_optimaldefcalculate_for_weight(self, weight):""" 完整计算流程:加载数据 -> 计算指定重量的最优方案 Parameters: ----------- weight : float 物品实际重量 Returns: -------- tuple: (最优方案数据框, 处理后的完整数据框) """ print("="*60) print(f"开始计算物流最优方案 (重量={weight}KG)") print("="*60)# 1. 加载数据(如果尚未加载)if self.price_table isNone: self.load_price_data()if self.price_table isNone:returnNone, None# 2. 预处理表达式 processed_df = self.preprocess_expressions(weight)if processed_df isNone:returnNone, None# 3. 评估表达式,得到匹配的行 matched_df = self.evaluate_expressions(processed_df)# 4. 找到最优方案 optimal_plan = self.find_optimal_plan(matched_df)return optimal_plan, processed_dfdefbatch_calculate(self, weights, save_results=True, output_file="批量计算结果.csv"):""" 批量计算多个重量的最优方案 Parameters: ----------- weights : list 重量列表 save_results : bool 是否保存结果到文件 output_file : str 结果保存文件名 Returns: -------- pandas.DataFrame: 批量计算结果 """ print("="*60) print(f"批量计算物流最优方案 ({len(weights)} 个重量)") print("="*60)# 1. 加载数据(如果尚未加载)if self.price_table isNone: self.load_price_data()if self.price_table isNone:returnNone results = []for i, weight in enumerate(weights, 1): print(f"\n[{i}/{len(weights)}] >>> 计算重量: {weight}KG <<<")# 预处理表达式 processed_df = self.preprocess_expressions(weight)if processed_df isNone:continue# 评估表达式 matched_df = self.evaluate_expressions(processed_df)if matched_df isnotNoneand len(matched_df) > 0: matched_df = matched_df.sort_values('收费', ascending=True) best_channel = matched_df.iloc[0]['渠道'] best_price = matched_df.iloc[0]['收费'] matched_count = len(matched_df) expression = matched_df.iloc[0]['重量表达式']else: best_channel = "无匹配" best_price = None matched_count = 0 expression = "无" results.append({'重量(KG)': weight,'最优渠道': best_channel,'价格(元)': best_price,'匹配渠道数': matched_count,'重量表达式': expression })# 创建结果数据框 results_df = pd.DataFrame(results) print("\n" + "="*60) print("批量计算结果汇总") print("="*60) print(results_df.to_string(index=False))# 保存结果if save_results and len(results_df) > 0:if output_file.endswith('.csv'): results_df.to_csv(output_file, index=False, encoding='utf-8-sig') print(f"\n结果已保存为CSV文件: {output_file}")elif output_file.endswith('.xlsx'): results_df.to_excel(output_file, index=False) print(f"\n结果已保存为Excel文件: {output_file}")else: output_file = f"{output_file}.csv" results_df.to_csv(output_file, index=False, encoding='utf-8-sig') print(f"\n结果已保存为CSV文件: {output_file}")return results_df# 主程序示例defmain():"""主程序:直接读取物流报价数据.xlsx""" print("物流报价最优方案计算器 - 直接读取Excel版") print("="*60)# 1. 创建优化器实例,默认读取"物流报价数据.xlsx" optimizer = LogisticsPriceOptimizer("物流报价数据.xlsx")# 2. 从文件加载数据 print(f"\n正在加载文件: 物流报价数据.xlsx") optimizer.load_price_data()if optimizer.price_table isNone: print("\n无法加载数据,程序退出")return print("\n" + "="*60) print("开始计算最优物流方案") print("="*60)# 3. 示例1:计算单个重量 print("\n示例1: 计算单个重量 (0.4KG)") example_weight = 0.4 optimal_plan, processed_df = optimizer.calculate_for_weight(example_weight)# 4. 示例2:批量计算 print("\n" + "="*60) print("示例2: 批量计算多个重量") test_weights = [0.05, 0.15, 0.3, 0.4, 0.5, 1.0, 2.5, 5.0, 10.0] batch_results = optimizer.batch_calculate( test_weights, save_results=True, output_file="物流报价批量计算结果.csv" )# 5. 用户交互示例 print("\n" + "="*60) print("示例3: 自定义重量计算") print("="*60)# 让用户输入重量whileTrue:try: user_input = input("\n请输入物品重量(KG) (输入'q'退出, 输入'p'打印数据): ").strip()if user_input.lower() == 'q': print("感谢使用,再见!")breakelif user_input.lower() == 'p': print("\n当前数据预览:") print(optimizer.price_table.to_string(index=False))continue weight = float(user_input)if weight < 0: print("重量不能为负数!")continue# 计算 optimal_plan, _ = optimizer.calculate_for_weight(weight)if optimal_plan isnotNoneand len(optimal_plan) > 0: print(f"\n计算完成!重量 {weight}KG 的最优方案:")for idx, row in optimal_plan.iterrows(): print(f" • {row['渠道']} - ¥{row['收费']} ({row['重量表达式']})")else: print(f"未找到重量 {weight}KG 的物流方案")except ValueError: print("请输入有效的数字!")except Exception as e: print(f"计算错误: {str(e)}") print("\n" + "="*60) print("生成的文件:") print("="*60)if os.path.exists("物流报价批量计算结果.csv"): size_kb = os.path.getsize("物流报价批量计算结果.csv") / 1024 print(f" • 物流报价批量计算结果.csv ({size_kb:.1f} KB)") print("\n使用说明:") print("1. 确保 '物流报价数据.xlsx' 文件在当前目录") print("2. 文件需要包含三列: '渠道', '重量表达式', '收费'") print("3. 运行程序会自动加载并计算") print("4. 可以自定义输入重量进行计算") print("5. 批量计算的结果保存在 '物流报价批量计算结果.csv'") print("="*60)# 快速使用函数defquick_calculate(weight):""" 快速计算函数 Parameters: ----------- weight : float 物品重量 Returns: -------- pandas.DataFrame: 最优方案 """ optimizer = LogisticsPriceOptimizer("物流报价数据.xlsx") optimal_plan, _ = optimizer.calculate_for_weight(weight)return optimal_plandefbatch_calculate_weights(weights_list):""" 批量计算函数 Parameters: ----------- weights_list : list 重量列表 Returns: -------- pandas.DataFrame: 批量计算结果 """ optimizer = LogisticsPriceOptimizer("物流报价数据.xlsx") results = optimizer.batch_calculate(weights_list, save_results=True)return results# 简单测试函数deftest_simple():"""最简单的测试函数""" print("简单测试 - 读取物流报价数据.xlsx") print("="*40)# 创建优化器 optimizer = LogisticsPriceOptimizer("物流报价数据.xlsx")# 加载数据if optimizer.load_price_data() isNone:return# 计算几个示例重量 test_weights = [0.2, 0.4, 1.5]for weight in test_weights: print(f"\n计算重量: {weight}KG") optimal, _ = optimizer.calculate_for_weight(weight)if optimal isnotNone: best = optimal.iloc[0] print(f" 最优: {best['渠道']} - ¥{best['收费']}")if __name__ == "__main__":# 运行主程序 main()# 或者运行简单测试# test_simple()# 或者使用快速函数# 示例: 计算单个重量# optimal = quick_calculate(0.4)# 示例: 批量计算# weights = [0.1, 0.5, 1.0, 2.0]# results = batch_calculate_weights(weights)
获取和交流
需要本章或其他文章的源码和数据的同学,关注+三连,在对应文章下评论“6666“,加下面微信,发你!也可以拉你进群交流学习,加群备注:IT小本本学习
为了能随时获取最新动态,大家可以动动小手将公众号添加到“星标⭐”哦,点赞 + 关注,用时不迷路!!!!
关注公众号:IT小本本 👇