目录:
1、() 分组与优先提取
(1)案例1
(2)案例2
2、| 或
(1)案例1
(2)案例2
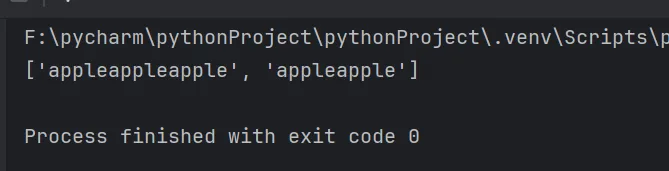
import res = "apple banana peach orange aaa appleappleapple appleapple"# ()分组ret = re.findall("(?:apple){2,3}", s)print(ret)
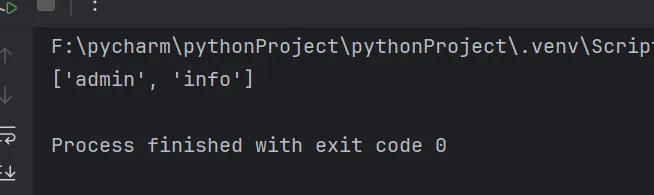
import retext = """Visit us at user@qq.com for more info.Contact support at support@qq.com.Also, check out admin@my163.com and info@163.com"""# ()内容优先提取ret = re.findall(r"\b([\w.-]+)@\w*163\.com\b", text)print(ret)
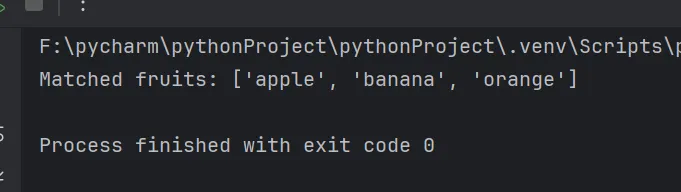
import retext = "I like apple, banana, and orange. I also enjoy grapes."# 正则表达式匹配 "apple"、"banana" 或 "orange"pattern = r"apple|banana|orange"# 查找所有匹配项matches = re.findall(pattern, text)# 输出结果print("Matched fruits:", matches)
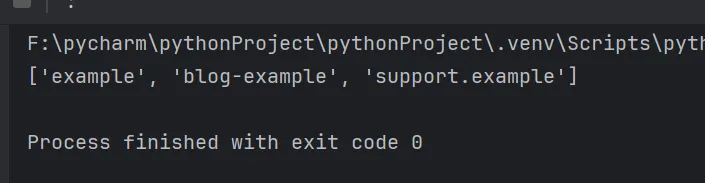
import retext = """Visit us at example.com for more information.You can also cheak out our partner site: partner-site.orgDon't forget about our blog at blog-example.com!For support, visit support.example.cn"""# 提取.com\.cn前的域名ret = re.findall(r"\b([\w.-]+)\.(?:com|cn)\b", text)print(ret)
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
