在动力学分析中,最让工程师崩溃的是:我想看结构在 0 到 10000 Hz 下的响应,如果每一个频率点都老老实实解一遍几百万自由度的方程,那计算量简直是天文数字。
这时候,SteadyStateSubspace 就像《三体》里的"二向箔"一样出现了。它不直接在庞大的全物理空间里硬刚,而是把问题投射到一个由特征模态构成的"小房间"(子空间)里去算。计算量瞬间从"大海捞针"变成了"盆里摸鱼"。
为什么需要子空间方法?
在结构动力学分析中,频响分析是评估结构动态特性的重要手段。然而,传统的直接积分法或完全模态法面临严峻挑战:
1. 计算规模问题:
现代有限元模型通常有数百万自由度
高频分析需要数千个频率点
直接求解的计算量:DOF³ × 频率点数
2. 频率分辨率 dilemma:
频率点太少:遗漏关键共振峰
频率点太多:计算时间不可接受
共振峰附近需要极高分辨率
3. 阻尼建模复杂性:
结构阻尼、材料阻尼、边界阻尼
频率相关的阻尼特性
复数运算带来的计算开销
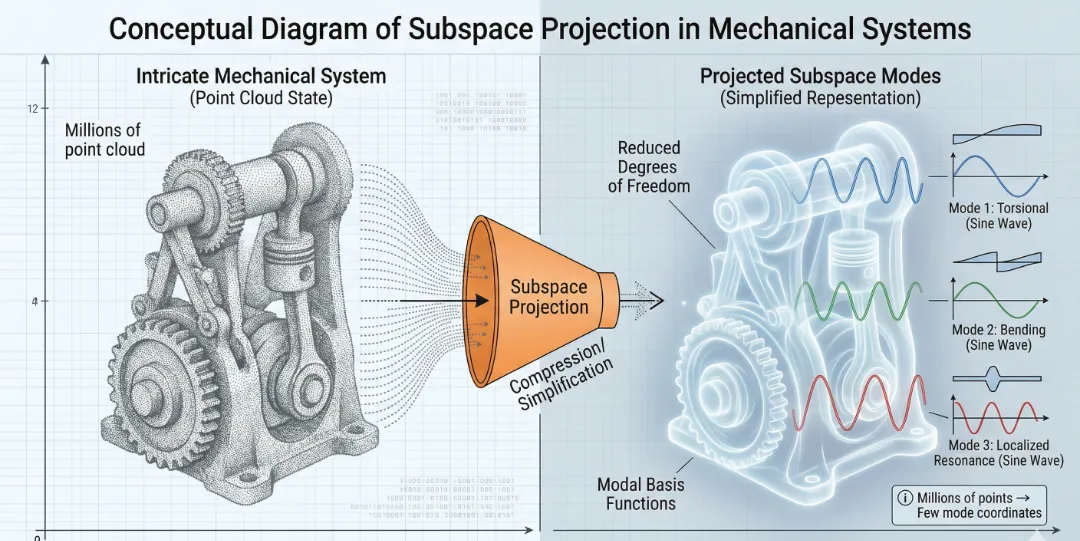
子空间方法的核心思想是:结构的动态响应主要由其低阶模态主导,因此可以用模态坐标来近似物理坐标,从而大幅降低问题维度。
根据官方脚本指南,SteadyStateSubspaceStep 派生自 AnalysisStep。要玩转它,你需要掌握以下三个核心 API 逻辑。
1. 核心入场券:frequencyRange 对象创建此分析步时,`frequencyRange` 是必选参数。它要求传入一个 SteadyStateSubspaceFrequencyArray 对象。
这就像是给歌手定调子。你不能只说"唱个歌",你得告诉 API:从哪个频率开始唱,到哪个频率结束,中间分多少个台阶。脚本允许你精确定义每个频段的采样点数和偏置因子。
频率范围参数详解:
SteadyStateSubspaceFrequencyArray( data=((f_start, f_end, n_points, bias), ))
参数说明:
`f_start`:起始频率 (Hz)
`f_end`:结束频率 (Hz)
`n_points`:该频段内的采样点数
`bias`:频率偏置因子(控制采样密度分布)
偏置因子的作用:
偏置因子控制频率点的分布密度:
`bias = 1.0`:均匀分布
`bias > 1.0`:低频密集,高频稀疏
`bias < 1.0`:低频稀疏,高频密集
对于共振分析,通常希望 `bias > 1.0`,因为低频区域通常有更多模态密集区。
多频段设置:
可以定义多个频段,每个频段有不同的采样策略:
# 定义多频段扫频freqArray = mdb.models['Model-1'].SteadyStateSubspaceFrequencyArray( data=( (10.0, 100.0, 50, 2.0), # 低频段:密集采样 (100.0, 1000.0, 100, 1.0), # 中频段:均匀采样 (1000.0, 5000.0, 50, 0.5), # 高频段:稀疏采样 ))
2. 算力杠杆:factorization(因子化策略)参数 `factorization` 可选 REAL_ONLY 或 COMPLEX。
REAL_ONLY 忽略阻尼带来的复数项,只解实数矩阵;COMPLEX 则要直面惨淡的人生,考虑所有复杂的阻尼和摩擦。
因子化策略的数学原理:
在频域分析中,运动方程变为:
其中:
ω = 角频率
[M] = 质量矩阵
[C] = 阻尼矩阵
[K] = 刚度矩阵
{U(ω)} = 频响位移
{F(ω)} = 频域载荷
REAL_ONLY 策略:
假设阻尼为零或可以忽略:
特点:
矩阵为实对称矩阵
计算速度快(约 2-3 倍)
无法捕捉相位信息
共振峰幅度可能不准确
COMPLEX 策略:
完整考虑阻尼效应:
特点:
矩阵为复数矩阵
计算成本较高
完整捕捉幅值和相位
共振峰有正确的衰减
`scale` 可选 LOGARITHMIC(对数)或 LINEAR(线性)。
共振点的能量可能比平时高出几千倍。如果用"线性"比例看,你会发现除了那几个刺破天的峰值,其他地方全是平的。而 LOGARITHMIC(对数比例)就像是给眼睛装了"动态补偿",让你既能看到惊天动地的共振峰,也能看清谷底的微弱颤动。
缩放比例的数学原理:
LINEAR(线性比例):
特点:
直接反映物理量大小
动态范围受限(通常 1-2 个数量级)
小响应被大响应淹没
LOGARITHMIC(对数比例):
特点:
动态范围极大(可达 6-8 个数量级)
共振峰和弱响应都清晰可见
符合人耳/人眼的感知特性
便于识别共振峰宽度(半功率带宽)
在 Python 中定义一个高阶稳态动力学分析步,你的代码需要分两步走:
from abaqus import *from abaqusConstants import *# 1. 先定义"乐谱":扫频范围# 参数:(起始频率,结束频率,采样点数,偏置因子)freqArray = mdb.models['Model-1'].SteadyStateSubspaceFrequencyArray( data=((10.0, 5000.0, 100, 1.0), ))# 2. 开启"降维打击"分析步# factorization=COMPLEX 保证考虑阻尼效应mdb.models['Model-1'].SteadyStateSubspaceStep( name='DynamicDance', previous='Initial', frequencyRange=freqArray, factorization=COMPLEX, scale=LOGARITHMIC, description='Frequency response using subspace projection')
在使用这一招之前,你必须先跑一个 FrequencyStep(频率分析步)来提取模态! 没有模态,子空间就是无源之水。
完整的频响分析流程:
def setup_complete_frequency_response(model_name): """ 设置完整的频响分析流程 包含:模态分析 + 子空间频响分析 """ from abaqus import mdb from abaqusConstants import * model = mdb.models[model_name] # 步骤 1:模态分析(必须!) model.FrequencyStep( name='Modal-Analysis', previous='Initial', numEigen=50, # 提取前 50 阶模态 eigensolver=LANCZOS, # 使用 Lanczos 求解器 minEigen=0.0, # 最小频率 maxEigen=10000.0 # 最大频率(覆盖感兴趣的频段) ) print(" 步骤 1:模态分析已创建") print(" 提取模态数:50") print(" 频率范围:0-10000 Hz") # 步骤 2:定义频响载荷(可选,根据分析类型) # 这里可以添加集中力、压力等频响载荷 # 步骤 3:子空间频响分析 freqArray = model.SteadyStateSubspaceFrequencyArray( data=( (10.0, 1000.0, 150, 1.5), # 低频段:密集采样 (1000.0, 5000.0, 100, 1.0), # 中高频段:均匀采样 ) ) model.SteadyStateSubspaceStep( name='Frequency-Response', previous='Modal-Analysis', frequencyRange=freqArray, factorization=COMPLEX, scale=LOGARITHMIC, description='Steady state dynamic response', # 高级参数 maxDampingChange=None, maxStiffnessChange=None, matrixStorage=UNSYMMETRIC, maintainLinearSolverSettings=False ) print(" 步骤 2:子空间频响分析已创建") print(" 频率范围:10-5000 Hz") print(" 总采样点数:250") print(" 因子化:COMPLEX") print(" 缩放:LOGARITHMIC") return model.steps['Frequency-Response']# 使用示例setup_complete_frequency_response('Dynamic-Structure')
在 Abaqus 脚本建模中,SteadyStateSubspace 是效率与精度的终极平衡点。
有时候,为了看清全局,我们不需要纠结于每一个原子的运动,只需要抓住系统最核心的"韵律"(模态)。这种从高维物理空间向低维数学子空间的纵身一跃,正是计算力学的优雅所在。
最佳实践建议:
👉互动话题:你见过最夸张的共振事故是什么?是洗衣服把阳台震塌了,还是共振导致了结构断裂?评论区聊聊你对"频率"的敬畏心!




 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
