Linux内核链表:设计、实现
Linux内核中的链表实现堪称艺术:它通过嵌入和宏抽象,打造了一套类型无关、高效优雅的通用链表API。理解它,是读懂内核源代码的第一步,也是领略C语言宏编程之美的绝佳窗口。
1. 数据结构与核心原理
1.1 双向循环链表
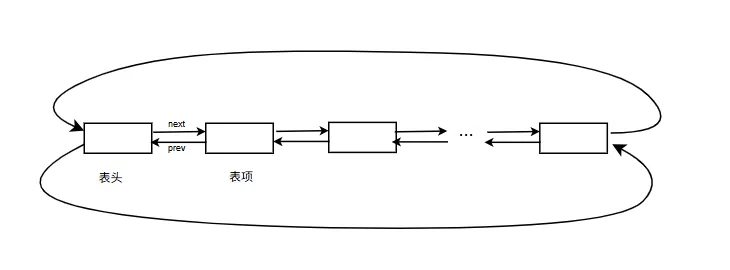
Linux下链表是个双向循环链表。
双向指每个表项包含两个指针:一个指向前一个表项(前向指针 prev),一个指向后一个表项(后向指针 next),支持双向遍历。
循环是指表头的前向指针指向表尾,表尾的后向指针指向表头。这样形成一个循环。
链表的数据结构如下:
struct list_head { struct list_head *prev, *next;};
链表由表头和表项构成,二者均使用 struct list_head 结构体。每个表项(或表头)里都有前向指针,后向指针,方便遍历。示意图如下:
术语统一:本文中“表项”指 struct list_head 结构体,“节点”指被嵌入的父结构体(如 struct person)。prev 称前向指针,next 称后向指针。
1.2 数据存储方式:嵌入而非指向
表项仅有 prev 和 next 两个指针,那么它如何存储实际数据呢?如果是我的话,可能就设计成这样:
struct list_head { struct list_head *next; struct list_head *prev; void *data;};
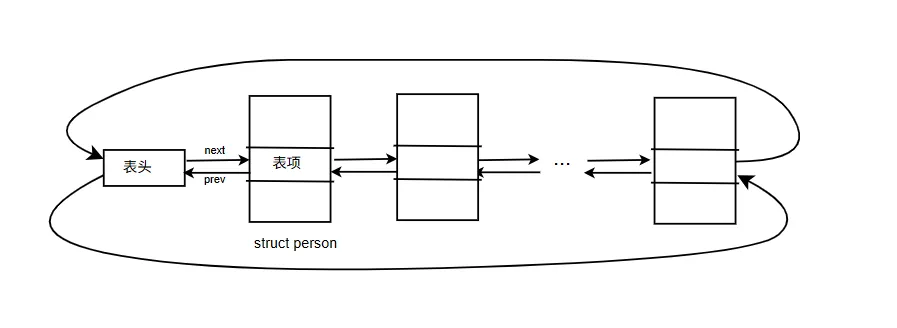
添加一个void *data 指针,指向数据。不过Linux下设计更巧妙。把表项嵌入到存储数据的数据结构里。假设有个person的结构体,里面有一些描述信息,然后所有的person都用链表链起来,如下:
struct person { char name[64]; struct list_head list; int id;};
这里将 struct list_head 嵌入到 struct person 中。下文将 struct list_head 称为表项,将其所在的父结构体 struct person 称为节点(或表节点)。
形成的列表就如下:
这种“嵌入”方式避免了 void *data 带来的额外内存开销和类型不安全性,但代价是:当我们通过链表遍历拿到 struct list_head * 时,如何找回它所在的 struct person?这就引出了Linux内核中最重要的宏之一——container_of。
1.3 从表项到节点:container_of 原理
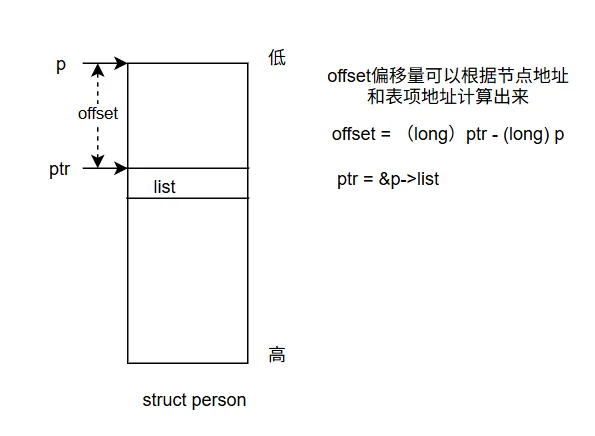
链表操作基于 struct list_head * 指针(即表项地址)。但实际业务操作的是 struct person 节点,因此需要一种方法从表项指针反推出所在节点的指针。 下面介绍container_of实现原理。
上图中表项的地址是ptr,节点的地址是p,这两个地址之间差一个offset。如果节点的地址是p,则表项的地址就为&p->list。则offset可以通过下面代码来计算。
struct person tmp;struct person *p = &tmp;offset = (long)&p->list - (long)p;
Linux 使用了一个小技巧:当 p 为空指针时,上面的计算就变为:
offset = (long)&((struct person*)NULL)->list - (long)NULL;//简化后offset = (long)&((struct person*)NULL)->list//知道了offset值,表项的地址减去offset就是节点的地址p = (long)ptr - (long)&((struct person*)NULL)->list
由此可见,offset 就是当结构体指针为 NULL 时,其成员变量的地址偏移量。有了offset,就可以根据表项地址(ptr)计算节点(p)的地址了。
Linux提供了offsetof宏来计算offset。提供了container_of宏从表项获取节点的地址。代码如下:
#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER)/** * container_of - cast a member of a structure out to the containing structure * @ptr: the pointer to the member. * @type: the type of the container struct this is embedded in. * @member: the name of the member within the struct. * */#define container_of(ptr, type, member) ({ \ consttypeof( ((type *)0)->member ) *__mptr = (ptr); \ // ^^^^^^ 这一行的作用:声明一个与 member 同类型的临时指针 // 为什么要这样做?—— 做类型安全检查,防止传错 ptr 类型 (type *)( (char *)__mptr - offsetof(type,member) );})
因为获取节点的地址是个常用的操作,所以重新定义了一个宏list_entry宏。
/** * list_entry - get the struct for this entry * @ptr: the &struct list_head pointer. * @type: the type of the struct this is embedded in. * @member: the name of the list_head within the struct. */#define list_entry(ptr, type, member) \ container_of(ptr, type, member)
【原理释疑】
为什么 ((TYPE *)0)->MEMBER 不会崩溃? 因为这里并没有真正解引用空指针。& 运算符只是计算成员相对于结构体起始地址的偏移量,编译器在编译期就能算出这个值,不会生成实际的内存访问指令。这是C语言标准允许的合法行为。
为什么需要强制类型转换 (TYPE *)0? 为了让编译器知道 MEMBER 是哪个结构体的成员,从而能正确计算其偏移地址。
2. 链表操作
在程序设计中,数据结构往往决定了算法。对于内核链表,一旦结构体确定,其核心操作逻辑也就随之清晰。
struct list_head { struct list_head *next; struct list_head *prev;};
知道了链表的结构体,就知道链表的操作怎么实现了。
2.1 表头定义以及初始化
Linux提供了LIST_HEAD这个宏来静态定义一个表头。
#define LIST_HEAD_INIT(name) {&name, &name}#define LIST_HEAD(name) \ struct list_head list = LIST_HEAD_INIT(name)
链表头初始化函数INIT_LIST_HEAD,初始化后的链表头prev、next都指向表头自己。
void INIT_LIST_HEAD(struct list_head *list) { list->prev = list; list->next = list;}
2.2 判断链表是否为空
list_empty 函数判断链表是否为空
从INIT_LIST_HEAD函数可以知道。链表头的next、prev指针都指向自己,当next指针指向自己,则就表明链表为空。
staticinlineintlist_empty(conststruct list_head *head){ return READ_ONCE(head->next) == head;}
2.3 获取表节点地址
前面介绍了list_entry从表项指针获取节点指针。Linux还提供另外两个宏,用来获取链表第一个节点的地址和下一个节点的地址。
list_first_entry 返回链表第一个节点的地址,其中ptr指向表头。
#define list_first_entry(ptr, type, member) \ list_entry((ptr)->next, type, member)
list_next_entry 返回当前节点的下一个节点的地址
/** * list_next_entry - get the next element in list * @pos: the type * to cursor * @member: the name of the list_head within the struct. */#define list_next_entry(pos, member) \ list_entry((pos)->member.next, typeof(*(pos)), member)
2.4 链表操作
list_add、list_add_tail 添加一个表项到表头和表尾
staticinlinevoidlist_add(struct list_head *new, struct list_head *head){ __list_add(new, head, head->next);}staticinlinevoidlist_add_tail(struct list_head *_new, struct list_head *head){ __list_add(_new, head->prev, head);}
这两个函数通过__list_add来实现。先找到prev 和 next节点。然后再进去插入。
static inline void __list_add(struct list_head *new, struct list_head *prev, struct list_head *next){ if (!__list_add_valid(new, prev, next)) return; next->prev = new; new->next = next; new->prev = prev; WRITE_ONCE(prev->next, new);}
list_del 删除节点时,先获取待删除节点的 prev 和 next,然后让 prev->next 指向 next,next->prev 指向 prev,从而将目标节点从链表中摘除。
static inline void __list_del(struct list_head *prev, struct list_head *next){ next->prev = prev; prev->next = next;}staticinlinevoidlist_del(struct list_head *entry){ __list_del(entry->prev, entry->next); entry->next = (struct list_head*)LIST_POISON1; entry->prev = (struct list_head*)LIST_POISON2;}
删除后,内核还会对这两个指针“下毒”(poison):将 next 设为 LIST_POISON1(通常为 0x100),prev 设为 LIST_POISON2(通常为 0x200)。
代码来自 include/linux/poison.h
/********** include/linux/list.h **********//* * Architectures might want to move the poison pointer offset * into some well-recognized area such as 0xdead000000000000, * that is also not mappable by user-space exploits: */#ifdef CONFIG_ILLEGAL_POINTER_VALUE# define POISON_POINTER_DELTA _AC(CONFIG_ILLEGAL_POINTER_VALUE, UL)#else# define POISON_POINTER_DELTA 0#endif/* * These are non-NULL pointers that will result in page faults * under normal circumstances, used to verify that nobody uses * non-initialized list entries. */#define LIST_POISON1 ((void *) 0x100 + POISON_POINTER_DELTA)#define LIST_POISON2 ((void *) 0x200 + POISON_POINTER_DELTA)
毒药指针的效果:
// 错误用法:删除后继续访问list_for_each_entry(pos, head, list) { // 如果 pos 是已删除的节点,访问 pos->list.next 会触发 page fault}
内核将 0x100 和 0x200 映射到不可访问的保护区,一旦访问立即崩溃,帮助开发者快速定位 use-after-free 问题。 如果设置为 NULL,可能被误判为“空链表”而继续执行,掩盖 bug。
2.5 链表遍历
可以使用宏list_for_each来遍历链表。该宏跟着next指针就可以遍历所有表项。当next指向表头时,循环就结束。
#define list_for_each(pos, head) \ for (pos = (head)->next; pos != (head); pos = pos->next)
当在遍历中需要删除某个表项,需要用到safe版本的宏。 从前面的list_del函数可以看出,pos节点被删除,pos节点的next指针指向LIST_POISON1。所以宏list_for_each_safe使用了个n来保存下一个需要访问的节点。
#define list_for_each_safe(pos, n, head) \ for (pos = (head)->next, n = pos->next; pos != (head); \ pos = n, n = pos->next)
list_for_each遍历过程中,只是获取表项的地址,还需要调用list_entry获取节点的地址。所以提供了遍历节点的版本list_for_each_entry。
/** * list_for_each_entry - iterate over list of given type * @pos: the type * to use as a loop cursor. * @head: the head for your list. * @member: the name of the list_head within the struct. */#define list_for_each_entry(pos, head, member) \ for (pos = list_first_entry(head, typeof(*pos), member); \ &pos->member != (head); \ pos = list_next_entry(pos, member))
两者的核心区别在于:list_for_each 遍历的是 struct list_head *,需要手动调用 list_entry 转换;而 list_for_each_entry 直接遍历业务节点(如 struct person *),无需额外转换。
list_for_each的版本
list_for_each(pos, head) { struct person *p = list_entry(pos, struct person, list); fn(p);}
list_for_each_entry的版本
struct person *p;list_for_each_entry(p, head, list) { fn(p);}
同样list_for_each_entry_safe是list_for_each_entry的safe版本,在遍历过程中需要删除的场景下使用。
list_for_each_entry_safe代码如下,使用n临时保存下一个要访问的节点:
/** * list_for_each_entry_safe - iterate over list of given type safe against removal of list entry * @pos: the type * to use as a loop cursor. * @n: another type * to use as temporary storage * @head: the head for your list. * @member: the name of the list_head within the struct. */#define list_for_each_entry_safe(pos, n, head, member) \ for (pos = list_first_entry(head, typeof(*pos), member), \ n = list_next_entry(pos, member); \ &pos->member != (head); \ pos = n, n = list_next_entry(n, member))
下面是一个典型的错误用法与正确用法的对比示例:
// ❌ 错误:遍历中删除会导致崩溃list_for_each_entry(p, head, list) { if (p->id == target) { list_del(&p->list); // 删除后,p->list.next 变成毒药指针 free(p); // 循环继续时会访问毒药指针 → 崩溃 }}// ✅ 正确:使用 safe 版本struct person *tmp;list_for_each_entry_safe(p, tmp, head, list) { if (p->id == target) { list_del(&p->list); free(p); // tmp 已保存下一个节点,安全 }}
当然,Linux 还提供了其他遍历方式(如反向遍历、从中间开始遍历等),本文不再展开。
3. 示例:约瑟夫环
理论讲完了,来看一个完整的例子。我们用 Linux 内核链表实现约瑟夫环问题。
约瑟夫环问题:n 个人围成一圈,从第 k 个人开始报数,数到 m 的人出列,下一个人继续从 1 报数,直到全部出列。问出列顺序。
3.1 代码实现
#include<stdio.h>#include<stdlib.h>#include"list.h"// 内核链表头文件struct person { int id; // 编号 1~n struct list_head list; // 链表节点};// 获取下一个有效节点,如果到达哨兵则跳回第一个有效节点static struct person *next_person(struct person *cur, struct list_head *head){ struct list_head *next = cur->list.next; if (next == head) next = head->next; return list_entry(next, struct person, list);}// 初始化 n 个人,编号 1~nstaticvoidinit_people(struct list_head *head, int n){ struct person *p; for (int i = 1; i <= n; i++) { p = malloc(sizeof(*p)); if (!p) { perror("malloc failed"); exit(1); } p->id = i; list_add_tail(&p->list, head); // 尾插,保持编号顺序 }}// 约瑟夫环模拟staticvoidjosephus(struct list_head *head, int k, int m){ struct person *p, *tmp; // 1. 找到第 k 个人作为起点 list_for_each_entry(p, head, list) { if (p->id == k) break; } printf("出列顺序: "); while (!list_empty(head)) { // 2. 报数,移动 m-1 次到达目标 for (int i = 1; i < m; i++) { p = next_person(p, head); } // 3. 输出并删除当前节点 printf("%d ", p->id); tmp = p; p = next_person(p, head); // 保存下一个起点 list_del(&tmp->list); free(tmp); } printf("\n");}intmain(){ struct list_head people; int n = 7, k = 3, m = 2; INIT_LIST_HEAD(&people); init_people(&people, n); printf("约瑟夫环: n=%d, k=%d, m=%d\n", n, k, m); josephus(&people, k, m); return 0;}
4. 为什么要用宏?——从遍历说起
想想如何遍历一个链表?
1.取第一个节点2.判断是否结束:没结束就处理节点,结束了就完成3.取下一个节点,回到第 2 步
这个流程很简单,但用 C 语言直接写,你可能会陷入指针细节:
for (pos = head->next; pos != head; pos = pos->next) { struct person *p = list_entry(pos, struct person, list); fn(p);}
你在思考:next 指针、head 边界、list_entry 转换——这些和“处理每个 person”这个核心意图无关。
在 Python 中,你写 for p in person_list: process(p),语言帮你隐藏了迭代细节。C 语言没有这种语法,但 Linux 内核用宏创造了一个。
Linux 的解法:封装遍历逻辑 有了 list_first_entry 和 list_next_entry,遍历变成了:
对业务来说,遍历链表就变成了
list_for_each_entry(p, &person_list, list) { fn(p); // 只关心处理逻辑}
这带来了什么?
1.改变思维方式:从“怎么做”到“做什么”
不再思考 next 指针、边界判断、类型转换。只需要思考:给我第一个节点,给我下一个节点,直到结束。这是从指令式编程向声明式编程的转变。
2.像函数式编程那样思考
函数式编程(如 Lisp、Haskell 等)有一个核心理念:用高阶函数抽象遍历模式。比如 Lisp 中处理列表:
(mapcar #'fn list) ;; 对每个元素应用 fn
Linux 链表遍历是这样:
list_for_each_entry(p, head, list) { fn(p);}
思想是相通的——遍历逻辑被抽象了,你面对的是“序列”而非“链表”。
Lisp 教会我们:遍历是模式,处理是内容。
3.宏创造新语法
C 语言没有 foreach,但宏可以创造它。list_for_each_entry 就像一个新的语言结构,专门表达“遍历链表”这个意图。
4.代码即注释
看到 list_for_each_entry,你立即知道它在遍历链表。函数名本身就是文档。
通过宏抽象,链表遍历从“操作指针”变成了“处理序列”,这是一种思维层次的提升,也是函数式编程思想在 C 语言中的体现。
5. 总结
Linux 内核链表通过将链表项嵌入数据结构,实现了类型无关的通用链表操作。理解 container_of 和遍历宏是掌握内核链表的关键:
•嵌入而非指向:传统链表用void *data指向数据,而Linux将链表节点嵌入到数据结构中。这样无需额外指针跳转,缓存更友好,且避免了类型转换的麻烦。•宏封装逻辑:list_for_each_entry 等宏将遍历逻辑抽象,让你专注于业务•安全遍历:_safe 版本支持遍历中删除节点
下一步建议:阅读内核源码 include/linux/list.h,尝试自己实现一个 list_for_each_entry_reverse 反向遍历宏。
附录:常用链表接口速查
| | |
| 初始化 | LIST_HEAD(name) | |
| INIT_LIST_HEAD(ptr) | |
| 判断 | list_empty(head) | |
| 添加/删除 | list_add(new, head) | |
| list_add_tail(new, head) | |
| list_del(entry) | |
| 获取地址 | list_entry(ptr, type, member) | |
| list_first_entry(head, type, member) | |
| list_next_entry(pos, member) | |
| 遍历 | list_for_each(pos, head) | |
| list_for_each_entry(pos, head, member) | |
| list_for_each_entry_safe(pos, n, head, member) | |
提示:实际开发中,90% 的场景只用 list_for_each_entry、list_add_tail、list_del 和 list_entry。
说明:Linux 内核链表不记录链表长度,因为这会增加维护成本。如需长度信息,请自行用变量维护。
如果你觉得这篇文章有帮助,欢迎点赞、在看、转发支持~