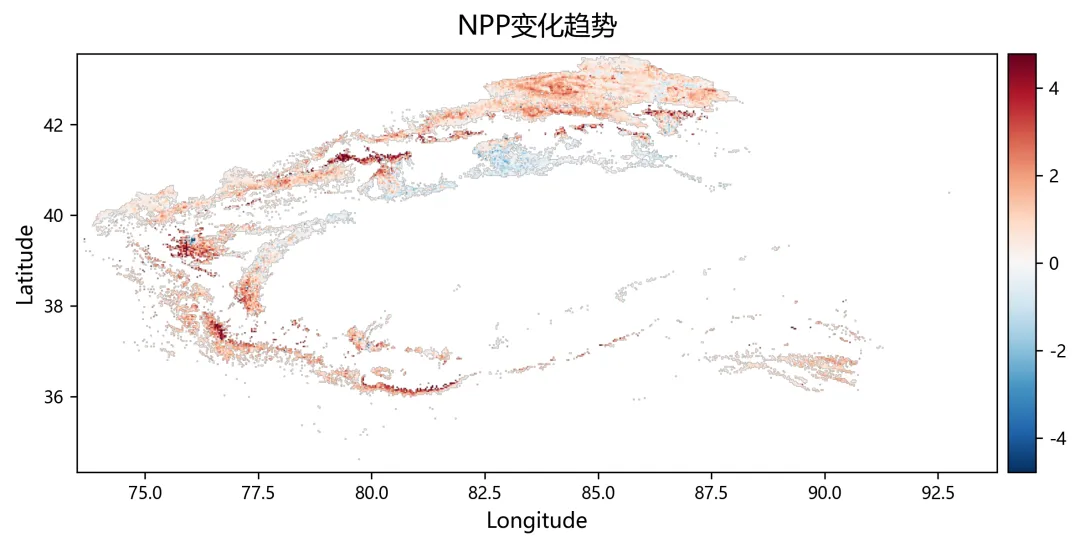
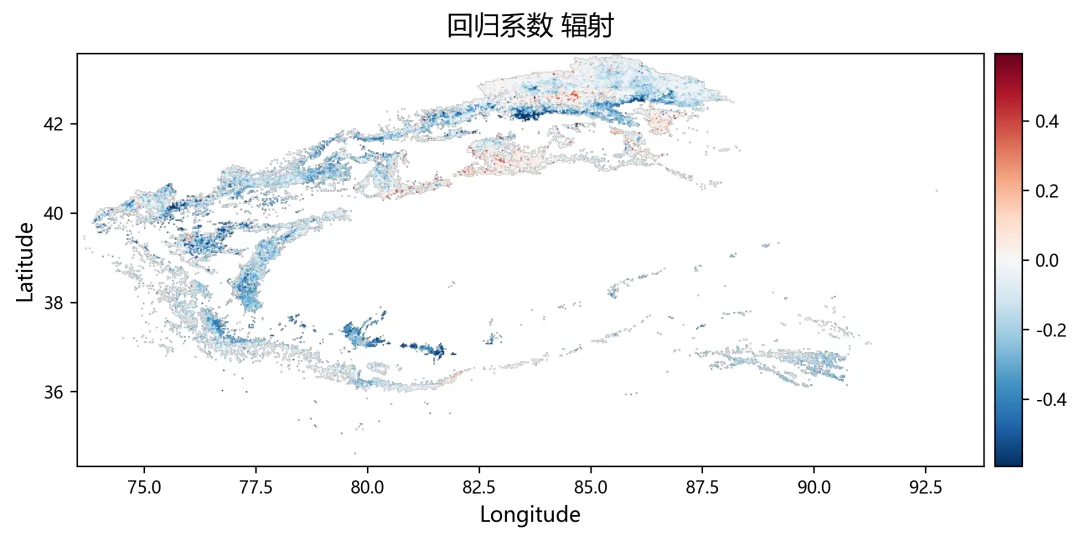
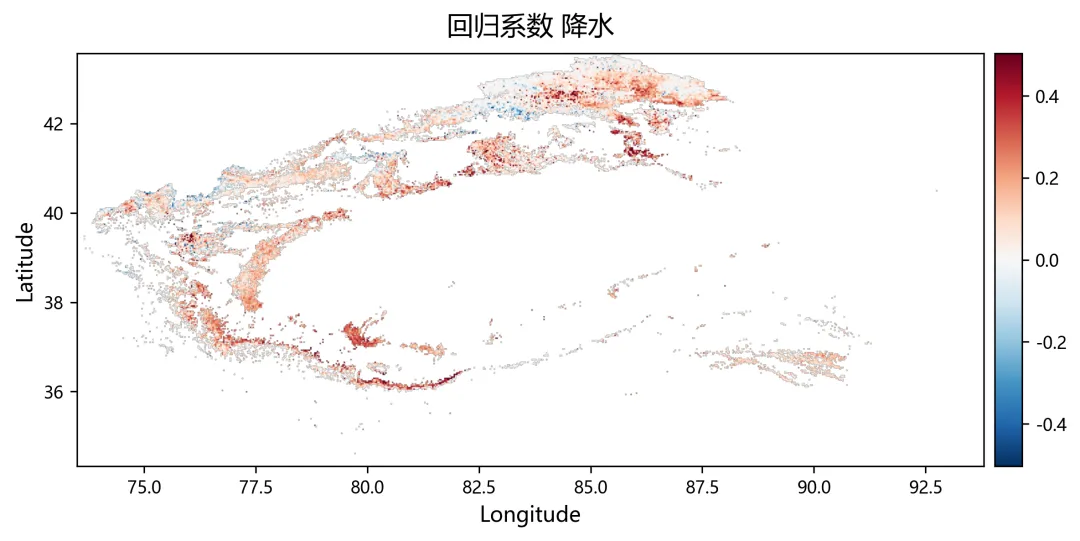
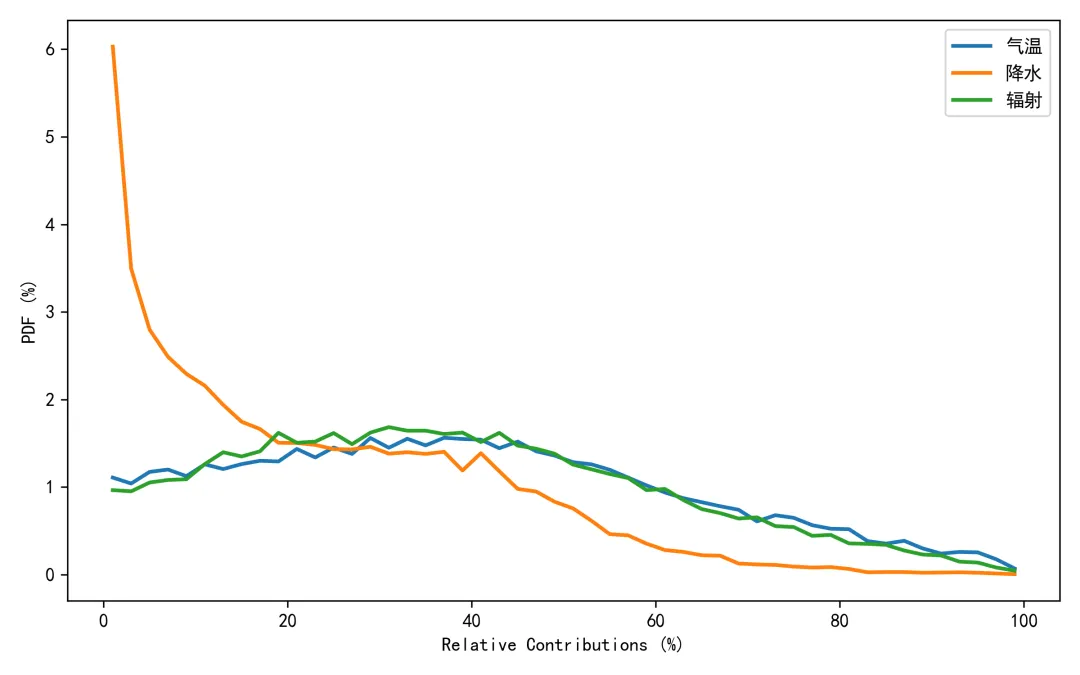
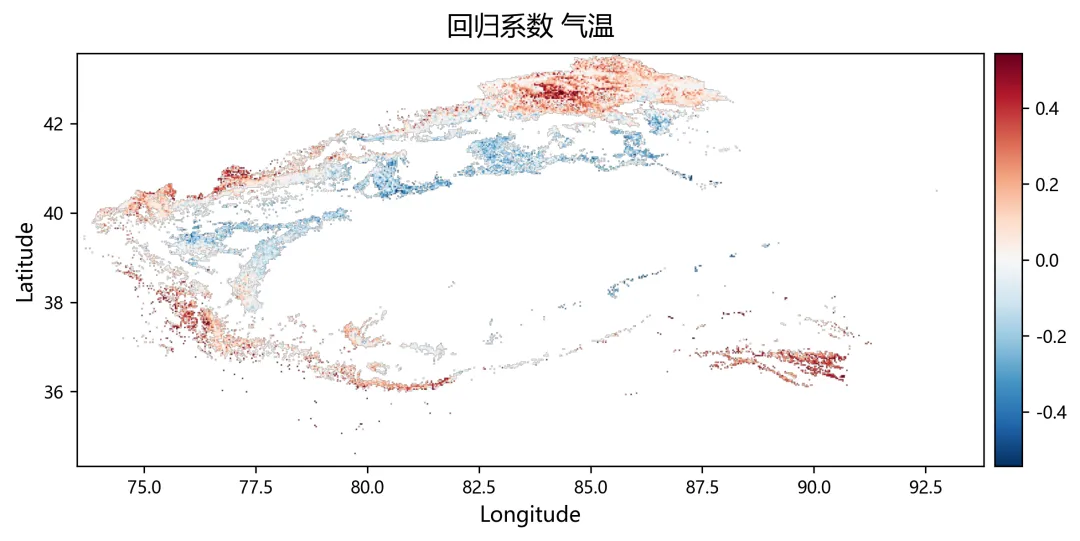
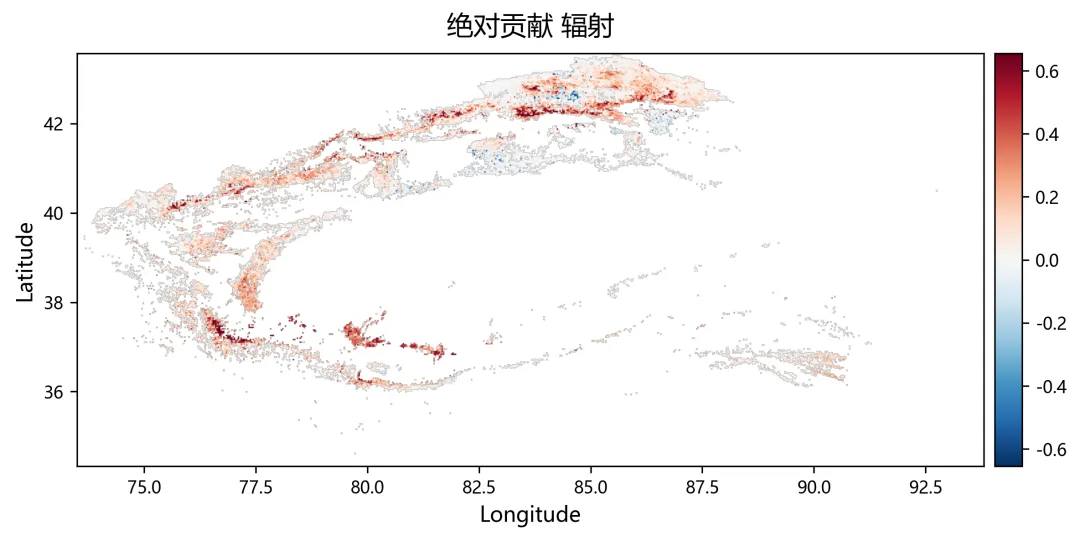
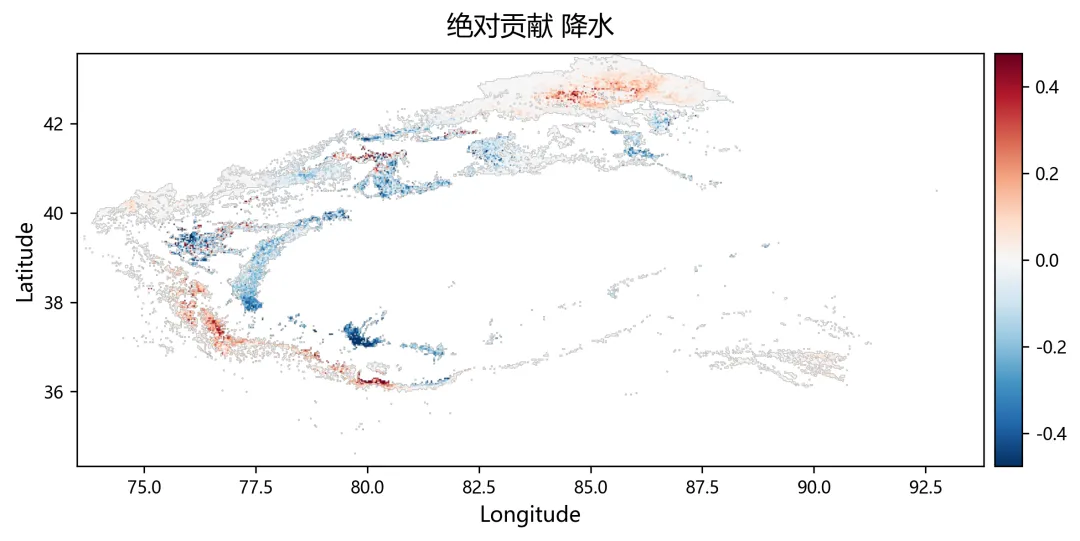
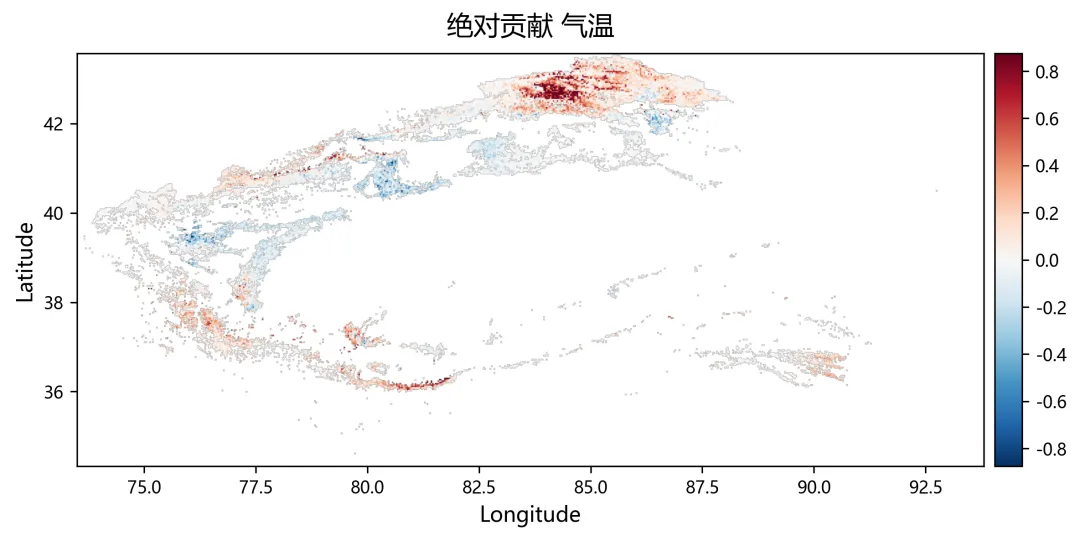
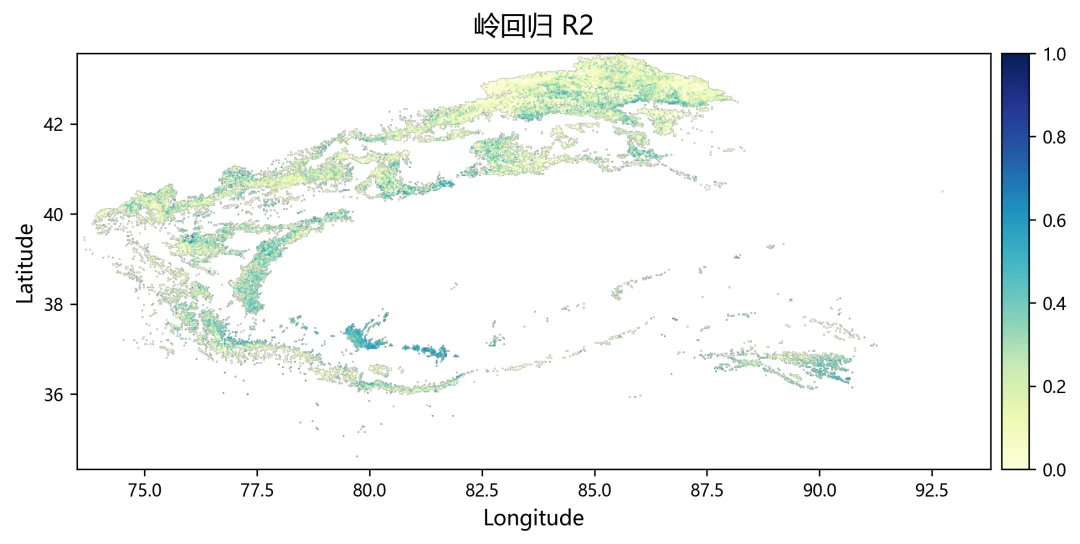
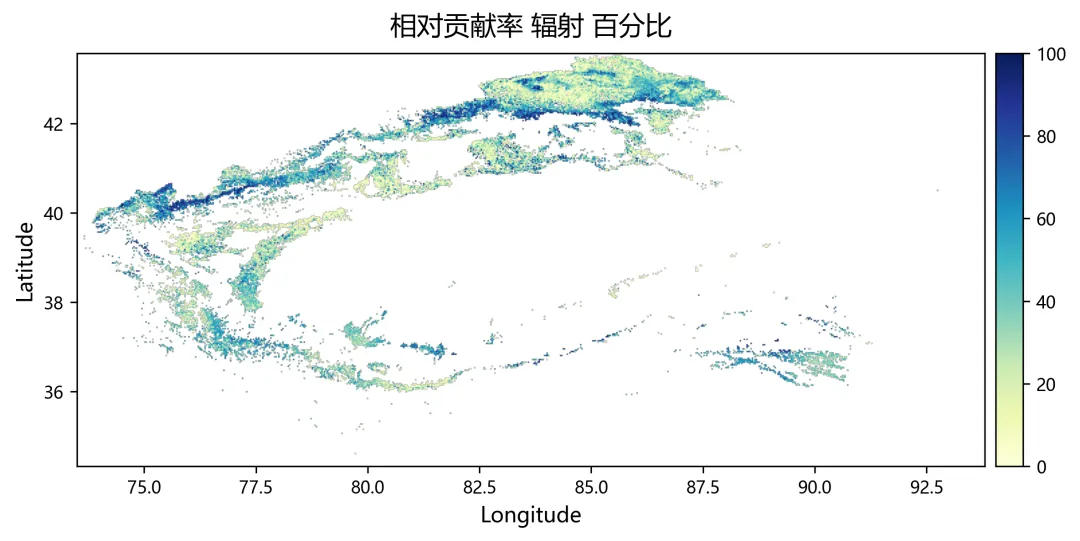
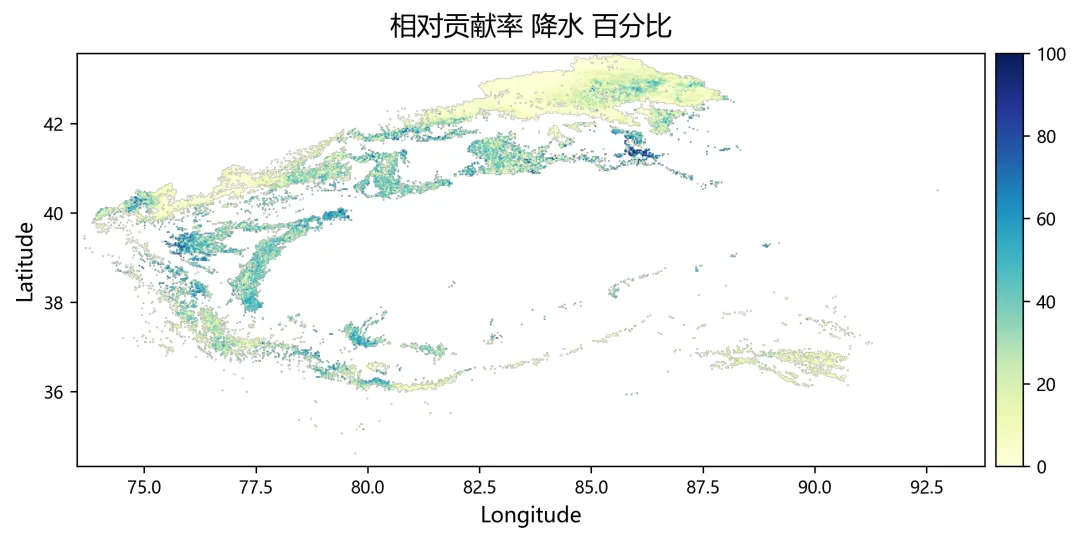
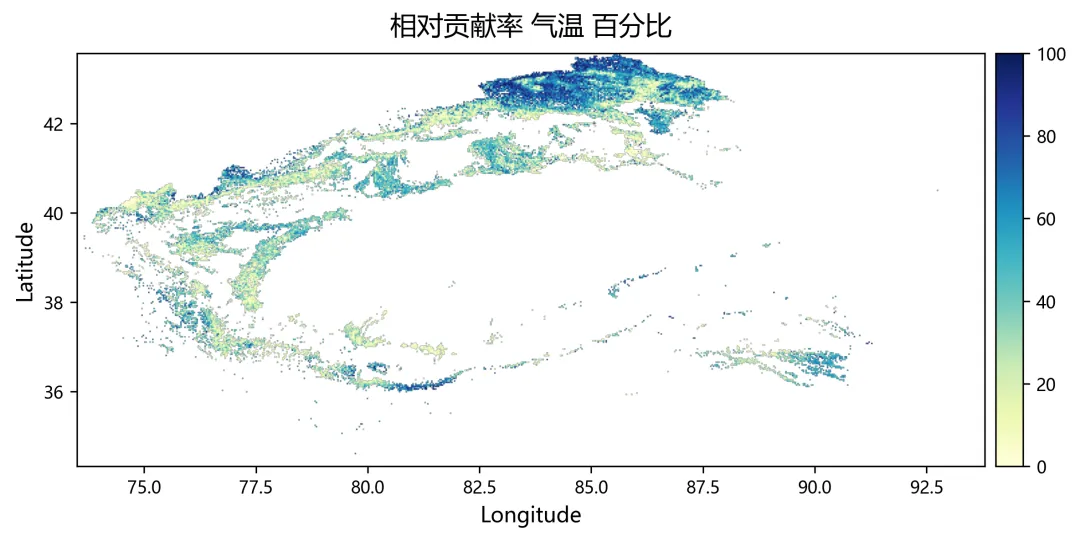
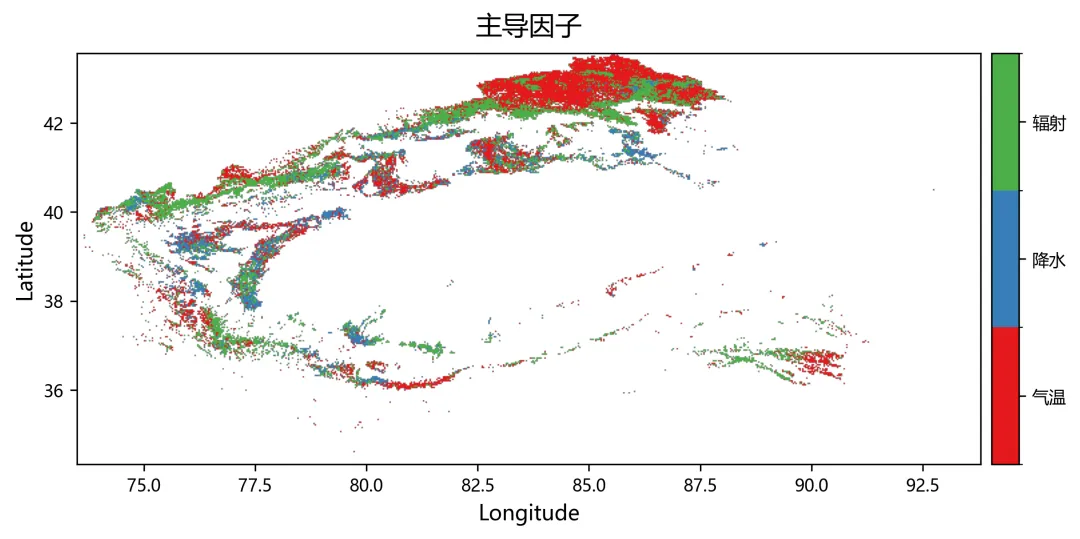
import osimport numpy as npimport rasterioimport matplotlib.pyplot as pltplt.rcParams["font.sans-serif"] = ["SimHei"]plt.rcParams["axes.unicode_minus"] = Falsefrom sklearn.linear_model import Ridge, RidgeCVfrom sklearn.metrics import r2_scorefrom tqdm import tqdmnpp_dir = r"D:\python代码\岭回归\净初级生产力NPP"climate_dir = r"D:\python代码\岭回归\气温tmean降水pr辐射srad"out_dir = r"D:\python代码\岭回归\输出结果"os.makedirs(out_dir, exist_ok=True)years = list(range(2001, 2025))variables = ["tmean", "pr", "srad"]variable_names = ["气温", "降水", "辐射"]min_years = 10alphas = np.logspace(-3, 3, 60)out_nodata = -9999.0def find_tif(folder, keyword, year): files = os.listdir(folder) for file in files: name = file.lower() if name.endswith((".tif", ".tiff")): if keyword.lower() in name and str(year) in name: return os.path.join(folder, file) return Nonedef read_tif(path): with rasterio.open(path) as src: arr = src.read(1).astype(np.float32) nodata = src.nodata profile = src.profile.copy() if nodata is not None: arr[arr == nodata] = np.nan arr[np.isinf(arr)] = np.nan return arr, profiledef read_stack(folder, keyword): stack = [] profile = None for year in years: path = find_tif(folder, keyword, year) if path is None: raise FileNotFoundError(f"没有找到 {keyword}{year} 年数据") arr, p = read_tif(path) if profile is None: profile = p h, w = arr.shape else: if arr.shape != (h, w): raise ValueError(f"{path} 的行列号和其他数据不一致") stack.append(arr) return np.stack(stack, axis=0), profiledef normalize(x): xmin = np.nanmin(x) xmax = np.nanmax(x) if not np.isfinite(xmin) or not np.isfinite(xmax): return None if np.isclose(xmax - xmin, 0): return None return (x - xmin) / (xmax - xmin)def trend(x, t): ok = np.isfinite(x) & np.isfinite(t) if ok.sum() < min_years: return np.nan if np.isclose(np.nanmax(x[ok]) - np.nanmin(x[ok]), 0): return 0.0 return np.polyfit(t[ok], x[ok], 1)[0]def save_tif(arr, profile, filename): path = os.path.join(out_dir, filename) profile = profile.copy() profile.update(dtype=rasterio.float32, count=1, nodata=out_nodata, compress="lzw") data = arr.astype(np.float32) data[~np.isfinite(data)] = out_nodata with rasterio.open(path, "w", **profile) as dst: dst.write(data, 1) print(f"已输出:{path}")print("读取NPP数据")npp, profile = read_stack(npp_dir, "NPP")print("读取气候数据")climate = {}for var in variables: climate[var], _ = read_stack(climate_dir, var)rows, cols = npp.shape[1], npp.shape[2]year_arr = np.array(years, dtype=np.float32)coef = np.full((3, rows, cols), np.nan, dtype=np.float32)relative = np.full((3, rows, cols), np.nan, dtype=np.float32)absolute = np.full((3, rows, cols), np.nan, dtype=np.float32)dominant = np.full((rows, cols), np.nan, dtype=np.float32)r2_map = np.full((rows, cols), np.nan, dtype=np.float32)npp_trend = np.full((rows, cols), np.nan, dtype=np.float32)print("开始岭回归")for r in tqdm(range(rows)): for c in range(cols): y0 = npp[:, r, c] if np.all(~np.isfinite(y0)): continue x0 = np.column_stack([ climate["tmean"][:, r, c], climate["pr"][:, r, c], climate["srad"][:, r, c] ]) ok = ( np.isfinite(y0) & np.isfinite(x0[:, 0]) & np.isfinite(x0[:, 1]) & np.isfinite(x0[:, 2]) ) if ok.sum() < min_years: continue y = y0[ok] x = x0[ok, :] t = year_arr[ok] if np.isclose(np.nanmax(y) - np.nanmin(y), 0): continue yn = normalize(y) if yn is None: continue xn = np.zeros_like(x, dtype=np.float32) good = True for k in range(3): temp = normalize(x[:, k]) if temp is None: good = False break xn[:, k] = temp if not good: continue try: model_cv = RidgeCV(alphas=alphas) model_cv.fit(xn, yn) model = Ridge(alpha=model_cv.alpha_) model.fit(xn, yn) pred = model.predict(xn) co = model.coef_ coef[:, r, c] = co r2_map[r, c] = r2_score(yn, pred) npp_trend[r, c] = trend(y, t) x_trend = np.array([ trend(xn[:, 0], t), trend(xn[:, 1], t), trend(xn[:, 2], t) ], dtype=np.float32) y_range = np.nanmax(y) - np.nanmin(y) abs_value = co * x_trend * y_range absolute[:, r, c] = abs_value total = np.nansum(np.abs(abs_value)) if total > 0: rel_value = np.abs(abs_value) / total * 100 relative[:, r, c] = rel_value dominant[r, c] = np.nanargmax(rel_value) + 1 except: continuefor k, name in enumerate(variable_names): save_tif(coef[k], profile, f"回归系数_{name}.tif") save_tif(relative[k], profile, f"相对贡献率_{name}_百分比.tif") save_tif(absolute[k], profile, f"绝对贡献_{name}.tif")save_tif(dominant, profile, "主导因子.tif")save_tif(r2_map, profile, "岭回归_R2.tif")save_tif(npp_trend, profile, "NPP变化趋势.tif")valid_relative = []labels = []for k, name in enumerate(variable_names): data = relative[k] data = data[np.isfinite(data)] data = data[(data >= 0) & (data <= 100)] valid_relative.append(data) labels.append(name)plt.figure(figsize=(8, 5))bins = np.linspace(0, 100, 51)for data, label in zip(valid_relative, labels): if len(data) > 0: density, edges = np.histogram(data, bins=bins, density=True) x = (edges[:-1] + edges[1:]) / 2 y = density * 100 plt.plot(x, y, linewidth=2, label=label)plt.xlabel("Relative Contributions (%)")plt.ylabel("PDF (%)")plt.legend()plt.tight_layout()fig_path = os.path.join(out_dir, "相对贡献率_PDF图.png")plt.savefig(fig_path, dpi=300)plt.close()print(f"已输出:{fig_path}")print("全部完成")print("主导因子编码:1=气温,2=降水,3=辐射")
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
