Python机器学习全流程分享:临床数据建模从哪里开始,怎么走到一篇可发表的研究?
- 2026-07-02 16:04:39
零代码数据库自动提取MIMIC数据库自动提取功能EICU数据库自动提取功能NWICU数据库自动提取功能公众号后台回复【666】查看详细功能介绍欢迎加入免费学习交流QQ群【512931102】
背景
很多同学第一次接触临床机器学习时,最容易卡住的地方不是算法。真正麻烦的是:环境装不好,数据库变量不知道怎么提,代码跑通了但图表看不懂,模型结果看着不错却不知道能不能写进论文。本篇文章会带你把一项临床数据机器学习研究的完整流程拆开看一遍:从环境搭建、MIMIC/eICU 数据获取,到特征筛选、模型训练、结果解释和外部验证。如果你正在准备做 ICU、急诊、重症、脑出血、脓毒症、死亡风险预测、并发症预测这类课题,这条流程基本绕不开。

第一步:先把代码环境搭好
临床研究里做机器学习,常见组合通常是 Python + R。
Python 更适合做数据清洗、建模、调参、可解释性分析
R 在统计检验、Lasso、Boruta、部分医学统计图表方面也很常用。
很多高分文章的补充代码里,两种语言会同时出现。但对零基础同学来说,第一关往往就是安装环境。
你需要准备:
Python 和 R 解释器安装配置
代码编辑与运行环境
常用数据分析包安装
现在更推荐用 Positron 这类一体化分析环境。它对 Python 和 R 都比较友好,也适合做临床科研项目管理。配置好以后,一个项目里的数据、代码、结果图、模型文件都可以放在同一套目录下,后期复现会轻松很多。
不要一开始就急着学算法。先保证你能稳定读入数据、运行代码、导出结果。环境不稳,后面每一步都会被打断。
第二步:搞清楚 MIMIC 和 eICU 数据库怎么用
做真实世界临床机器学习,MIMIC 和 eICU 是两个非常常见的公共数据库。MIMIC 数据来自 Beth Israel Deaconess Medical Center 的重症监护场景,eICU 则包含多中心 ICU 数据。它们都适合做死亡风险预测、并发症预测、疾病分型、治疗反应评估等方向。但数据库不是下载下来就能直接建模的,你至少要弄清楚这三件事:
这类数据库目前在机器学习领域发了哪些文章。
哪些选题已经被做得很拥挤,哪些方向还可以切入。
目标变量和特征变量应该从哪些表里提取。
很多同学卡在“变量提取”这一关,同时也是最关键的一步。比如想做脓毒症预测,你不仅要知道患者基本信息在哪张表,还要知道实验室指标、生命体征、用药、诊断、入出量、结局变量分别怎么提。SQL 写错一点,后面的模型都会跟着偏。所以比较稳妥的学习方式,是先拆一篇经典文献:它研究的是什么人群,纳入排除标准是什么,结局怎么定义,变量来自哪里,最后如何复现数据提取。【AI辅助临床数据建模实战:基于MIMIC与eICU的Python机器学习课程】里会把 MIMIC/eICU 经典文章拆解、数据提取复现,以及基于魔方工作台的自动提取功能放在一起讲。目的不是让你背数据库结构,而是让你能真正拿到一份可用于建模的数据表,从而减少大量花在变量提取的时间。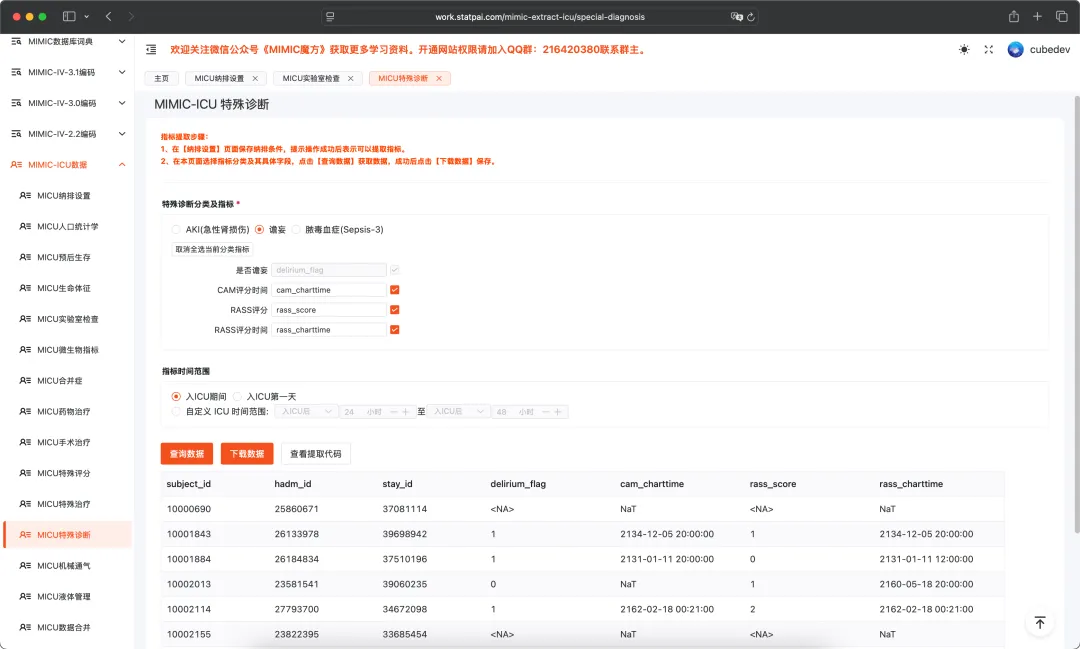
第三步:先看懂文献里的图和指标
很多人跑机器学习,一上来就问“哪个模型最好”,“这么多模型应该用哪个”。这个问题太早了。你得先看懂一篇机器学习文章到底在汇报什么。否则模型跑出来以后,ROC、DCA、校准曲线、SHAP 图摆在面前,也不知道该怎么解释。
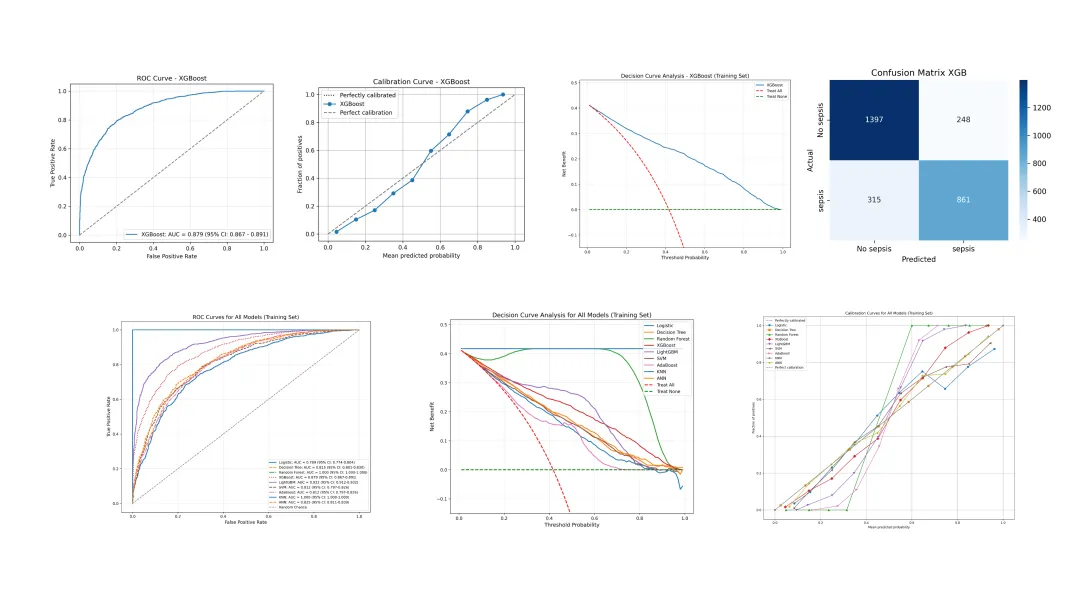
临床机器学习文章里最常见的结果,主要有三类曲线。
ROC 曲线看模型区分能力。AUC 越高,说明模型把阳性和阴性样本区分开的能力越强。
DCA 曲线看临床净获益。它回答的问题不是“模型准不准”,而是在某个阈值范围内,用这个模型辅助决策是否比全部干预或全部不干预更划算。
校准曲线看预测概率和真实发生率是否接近。临床预测模型不能只看 AUC,如果模型总是把 20% 风险预测成 60%,它在实际使用中会带来误导。
除了曲线,还要看性能指标:
准确率
精确率
灵敏度
特异度
F1 分数
Brier 分数
这些指标没有一个能单独代表模型好坏。比如在阳性样本很少的疾病预测里,准确率可能看起来很高,但模型其实没有抓住真正高风险的人。
最关键的是 SHAP,SHAP 图是临床机器学习论文里非常常见的可解释性工具:
条形图看变量整体重要性
蜂群图看变量对模型输出的方向和分布
依赖图看单个变量与风险变化的关系
瀑布图和力图更适合解释单个患者为什么被预测为高风险。
只有看懂这些图,后面写结果和讨论时才不会只剩一句“模型表现良好”。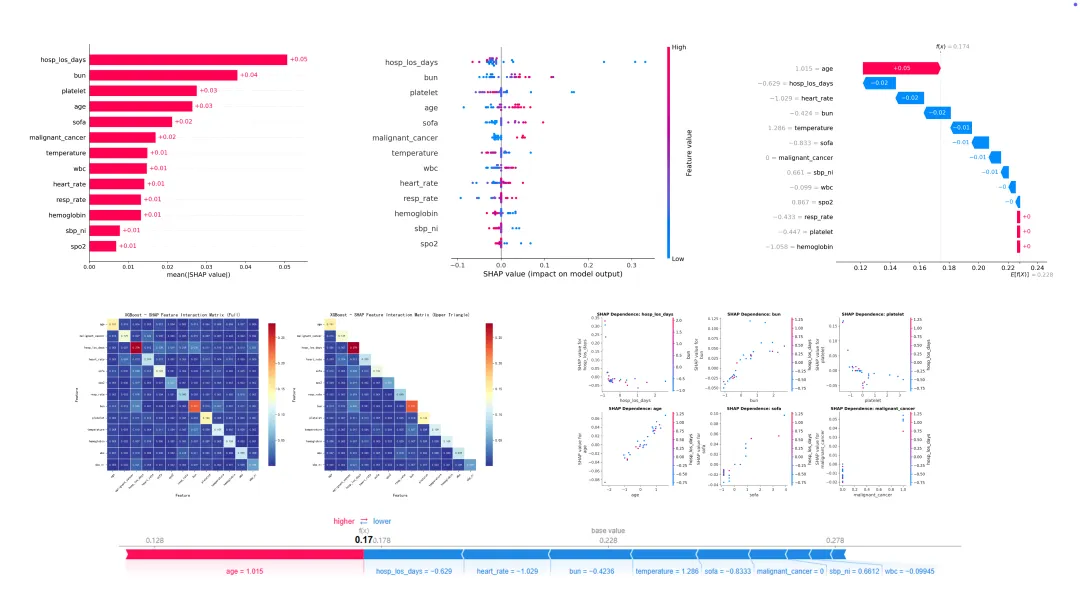
第四步:补齐 Python 和 R 的基础
零基础能不能学临床机器学习?可以,但不能跳过代码基础。你不需要先成为程序员,但至少要看懂这些内容:
变量、列表、字典、数据框
条件判断和循环
函数调用
数据导入和导出
Python 里要熟悉 pandas、numpy、scikit-learn、xgboost、lightgbm、shap 这些常用工具;R 里至少要能看懂基础语法、统计检验、Lasso 回归、Boruta 特征筛选相关代码。现在我们可以让 AI 去帮助我们学习代码:比如让它解释报错、补全代码、改写函数、生成图表代码。
AI 协同编程确实能帮很多忙,但前提是你知道自己要做什么,也能判断它给出的结果是否合理。临床科研里最危险的不是不会写代码,而是代码跑错了自己不知道。
第五步:从原始数据走到一个完整模型
到了建模阶段,流程可以分成五段。
1. 数据预处理
原始临床数据通常很乱。有缺失值,有异常值,有单位不一致,有重复记录,也有明显不符合临床常识的数值。比如某个实验室指标出现极端值,可能是真实危重状态,也可能是录入或提取错误。常见处理包括:
缺失值统计与填补
异常值识别
数据分布检验
组间比较
连续变量标准化
样本不平衡处理
预处理不是机械套模板。比如缺失值比例很高的变量,是否保留要结合临床意义;样本均衡方法也不能随便用,否则可能导致模型在验证集上表现虚高。
2. 特征工程与变量筛选
临床数据的变量很多,但不是越多越好。变量太多会增加过拟合风险,也会让模型解释变得困难。常见做法是先结合临床知识做初筛,再使用统计或机器学习方法进一步筛选。Lasso 回归和 Boruta 是比较常用的工具:
Lasso 可以通过正则化压缩变量系数,筛出与结局相关性更强的一组变量
Boruta 基于随机森林思想,可以帮助判断变量是否真的比随机噪声更有价值。
在实际项目里,我们通常会把 R 代码和 Python 建模结合起来:R 负责部分变量筛选,Python 负责后续模型训练和解释。
3. 构建多个主流模型
临床机器学习论文里,通常不会只做一个模型。常见模型包括:
Logistic 回归
决策树
随机森林
XGBoost
LightGBM
SVM
KNN
AdaBoost
ANN
Logistic 回归可解释性强,是很好的基线模型。随机森林、XGBoost、LightGBM 这类集成模型经常能得到更好的预测表现。SVM、KNN、ANN 也可以作为对比模型。
模型训练时,还要做交叉验证和网格搜索,不能只凭一次随机划分就下结论。参数调优虽然不一定让模型大幅提升,但可以让结果更稳,也更容易写清楚方法学。
4. 模型评估与结果解释
训练完成后,要把每个模型放在同一套指标下比较。一般会同时汇报 ROC、DCA、校准曲线,以及准确率、精确率、灵敏度、特异度、F1 分数、Brier 分数等指标。如果模型表现不错,还要进一步做 SHAP 分析。SHAP 的价值不只是“画得好看”。它能帮助我们回答几个更接近临床的问题:
哪些变量对模型贡献最大?
某个变量升高后,风险是增加还是降低?
模型为什么把某个患者判定为高风险?
这些结果是否符合临床常识?
如果 SHAP 结果和临床认知完全相反,就要回头检查变量定义、数据提取、样本选择和模型训练过程。
5. 外部验证
一篇预测模型文章要更有说服力,外部验证很重要。外部验证可以使用本院自有数据,也可以用 eICU 等独立数据库。它考察的是模型换到另一个数据来源后,表现是否还能保持。这一步难度会明显提高。因为不同数据库的变量名称、检测频率、单位、缺失模式都可能不同。你需要重新制定变量收集策略,把变量定义尽量标准化,再评估模型的泛化能力。
很多模型在训练集里表现很好,一到外部验证就下降明显。这个结果并不一定是坏事,它反而能提醒我们模型是否真的具备临床推广价值。
第六步:把方法用到自己的数据上
公共数据库适合入门和发文训练,但最终很多同学还是想分析自己的临床数据。这时流程还是同一套,只是问题会更具体:
自己的数据能不能支撑这个结局事件?
样本量够不够?
变量缺失是否严重?
纳入排除标准怎么写?
结果能不能和已有文献对话?
【AI辅助临床数据建模实战:基于MIMIC与eICU的Python机器学习课程】里会结合一篇 IF 6 分、Q1 分区的脑出血预测脓毒症机器学习文章,拆解它的研究设计、变量处理、模型结果和论文呈现方式。这样学完公共数据库流程后,可以更自然地迁移到自己的课题。
我们为什么把这门课设计成“全流程”
临床机器学习不是单独学一个 XGBoost,也不是会画 ROC 曲线就够了。真正能落地的流程,至少要打通这几件事:
从环境配置开始,能把 Python 和 R 跑起来。
从 MIMIC/eICU 数据库开始,能申请、理解、提取、复现。
从文献结果开始,能看懂 ROC、DCA、校准曲线、性能指标和 SHAP。
从代码基础开始,能自己改参数、查报错、换变量、复跑模型。
从建模实战开始,能完成预处理、变量筛选、九大模型训练、自动调参、模型评估和解释。
再往前一步,能做外部验证,把方法迁移到本院数据或 eICU 数据。
这也是我们团队推出【AI辅助临床数据建模实战:基于MIMIC与eICU的Python机器学习课程】的设计思路。课程包含环境准备教程、MIMIC/eICU 数据库使用、机器学习文献图表解读、Python 和 R 代码基础、AI 辅助建模实战、私有数据统计分析案例。课程方式为录播+直播:录播适合反复看,直播部分会带着大家把完整流程跑一遍。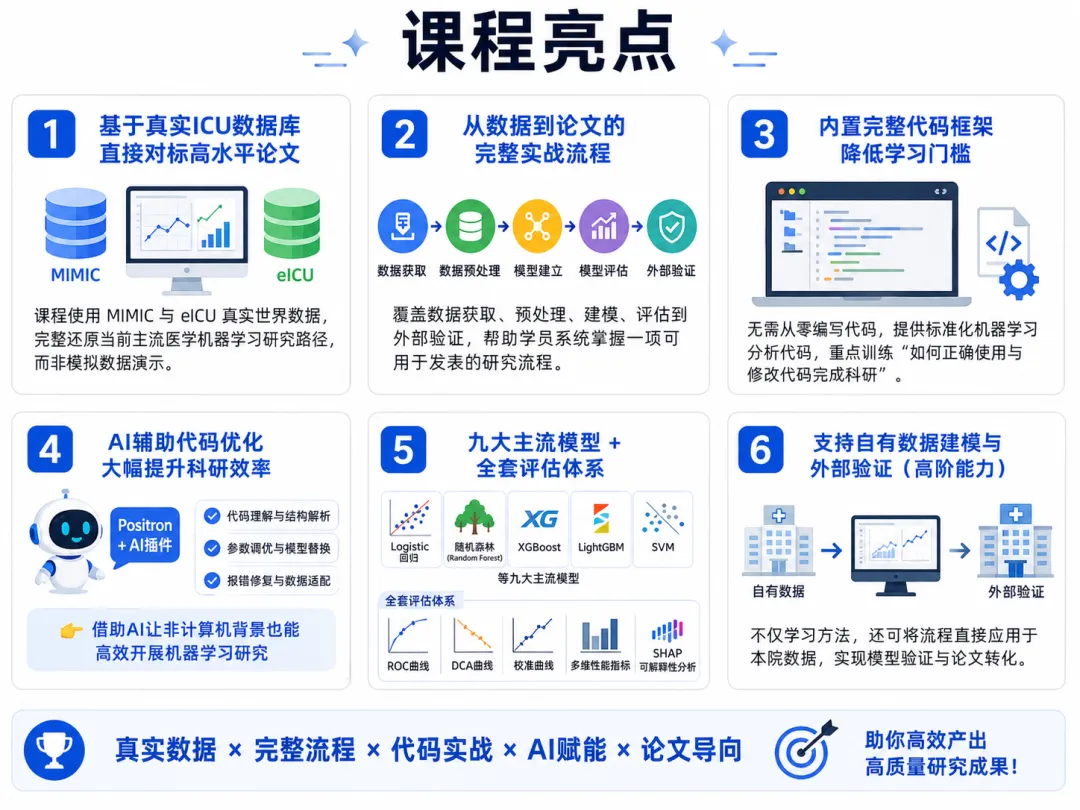
如果你已经有临床选题,但不知道如何提取数据、筛变量、建模型、解释图表,这门课会更适合你。
如果你还没有选题,也可以先从 MIMIC/eICU 的经典文献和发文趋势入手,找到一个更稳的切入点。
临床机器学习最怕只学碎片。今天学一个模型,明天学一张图,最后还是不知道怎么把它们连成一篇文章。我们希望这门课解决的,就是这件事:让你从第一行代码开始,走到一套可以复现、可以解释、可以写进论文的方法流程。
感兴趣的同学可以关注本次【AI辅助临床数据建模实战:基于MIMIC与eICU的Python机器学习课程】,适合临床医生、研究生、科研助理,以及正在准备真实世界数据机器学习论文的团队学习。欢迎添加下面的助教老师微信咨询:

随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- OpenCV-Python中的图像金字塔:高斯金字塔 & 拉普拉斯金字塔
- Linux每日一学|第9天:cat 命令
- 告别 Linux 折腾时代!这款 Fedora 魔改系统,中文适配颜值直接拉满的Evernight Vista OS懒人必备
- 学Python的主要用途你知道了吗?
- 要想Python不挂科,这100题必刷.
- 看漫画也能学Python?小学生都能学会!!
- 花30天速成Python,无痛自律!
- Python-10-特征工程
- 【已复现】Dirty Frag: Linux内核LPE深度解析,poc见V4bel/dirtyfrag
- 85系列菲律宾比索PHP欣赏
