大家好,我是木木。
今天给大家分享一个成熟的 Python 库,langchain。
langchain
做 LLM 应用时,真正麻烦的往往不是“调用一次模型”,而是把 Prompt、模型、工具、解析器、记忆、检索和业务流程串成一条稳定链路。langchain 的定位就是帮你做这件事:把 AI 能力拆成可组合组件,再按流程编排起来。
它现在也在向 Agent 工程平台演进,所以更适合讲“让 AI 调工具、走流程、接业务系统”这类需求。简单问答可以不用它,但只要流程开始变长,它的组合能力就很有价值。
项目地址:https://github.com/langchain-ai/langchain
官方文档:https://docs.langchain.com/
三大特点
组件成熟
Prompt、模型、输出解析、Runnable、工具、检索和 Agent 相关能力都已经形成比较完整的生态。
编排灵活
可以用 | 串联步骤,也可以并行分支、条件路由、批处理和流式输出,适合把复杂 AI 流程拆开维护。
生态丰富
大量模型、向量库、工具和观测系统都有现成集成,做原型和接业务系统都比较省时间。
最佳实践
安装方式:python -m pip install langchain==1.2.17
下面的 Demo 使用 langchain-core 里的 Runnable、Prompt 和 Parser,不调用真实 LLM,所以不会消耗 API 额度。
功能一:把 Prompt 和处理步骤串起来
这段代码解决什么问题:把“生成消息”和“模型/处理函数”拆成两个步骤,再用管道组合。真实项目里,fake_llm 可以换成模型客户端,链路结构不需要大改。
importwarningswarnings.filterwarnings('ignore')fromlangchain_core.promptsimportChatPromptTemplatefromlangchain_core.runnablesimportRunnableLambdaprompt=ChatPromptTemplate.from_messages([('system','你是一个技术选型助手。'),('human','用一句话介绍 {name}')])deffake_llm(value):user_text=value.to_messages()[-1].contentreturnf'收到任务:{user_text} -> 适合编排 AI 流程'chain=prompt|RunnableLambda(fake_llm)result=chain.invoke({'name':'LangChain'})print('result:',result)print('steps:',len(chain.steps))print('first step:',type(chain.steps[0]).__name__)print('second step:',type(chain.steps[1]).__name__)
这个模式的好处是边界清楚。Prompt 改 Prompt,模型改模型,后处理改后处理,不需要把所有逻辑揉成一个大函数。
功能二:并行跑多个分支
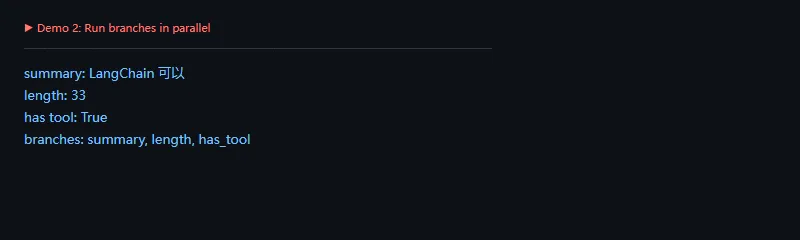
这段代码解决什么问题:同一份输入可以同时进入多个处理分支,比如摘要、打标签、判断是否需要调工具。这样适合做内容审核、路由判断和多指标分析。
importwarningswarnings.filterwarnings('ignore')fromlangchain_core.runnablesimportRunnableLambda,RunnableParalleltext='LangChain 可以把 prompt、模型、工具和解析器串起来'workflow=RunnableParallel(summary=RunnableLambda(lambdax:x['text'][:12]),length=RunnableLambda(lambdax:len(x['text'])),has_tool=RunnableLambda(lambdax:'工具'inx['text']),)result=workflow.invoke({'text':text})print('summary:',result['summary'])print('length:',result['length'])print('has tool:',result['has_tool'])print('branches:',', '.join(workflow.steps__.keys()))
多分支流程要注意成本。真实接模型时,每个分支可能都是一次请求,所以需要缓存、限流和明确的失败兜底。
环境与版本信息
- Demo 环境:Windows 11,Python 3.11
- 本文安装的
langchain 版本:1.2.17 - 当前包要求 Python:
>=3.10,<4.0 - 关键依赖版本:
langchain-core 1.3.3、langgraph 1.1.10 - 官方定位:面向 agents 和 LLM-powered applications 的框架
高级功能
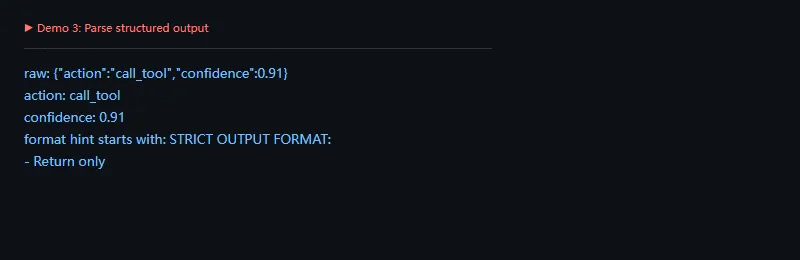
这段代码解决什么问题:LLM 返回的文本如果要进入业务流程,最好先解析成结构化结果。JsonOutputParser 可以给模型格式提示,也可以把 JSON 文本解析成可用对象。
importwarningswarnings.filterwarnings('ignore')frompydanticimportBaseModel,Fieldfromlangchain_core.output_parsersimportJsonOutputParserclassRoute(BaseModel):action:str=Field(description='下一步动作')confidence:float=Field(description='置信度')parser=JsonOutputParser(pydantic_object=Route)raw='{"action":"call_tool","confidence":0.91}'parsed=parser.parse(raw)print('raw:',raw)print('action:',parsed['action'])print('confidence:',parsed['confidence'])print('format hint starts with:',parser.get_format_instructions()[:36])
结构化解析不是银弹,但能减少“模型说得像对的,程序却不知道怎么用”的尴尬。上线时还要给解析失败、字段缺失和低置信度分支留处理逻辑。
适用场景
- 你要把 Prompt、模型、工具和输出解析组成稳定流程
- 你需要并行分支、路由、批处理、流式输出或 Agent 调度
- 你希望快速接入不同模型、向量库、检索组件和观测系统
不适用场景
- 只是一次简单问答或短文本生成,普通模型 SDK 就够了
上线检查
- 每个 Runnable 的输入输出要清楚,避免链路中间靠隐式字段传来传去。
- 模型输出进入业务系统前,必须做结构化解析、校验和日志记录。
总结
langchain 适合把 LLM 应用从“单次调用”推进到“可维护流程”。它的核心价值不是替你写 Prompt,而是把 Prompt、模型、工具、解析器和运行流程变成可组合、可替换的工程结构。