写在前面的话
既要又要。最近,看一个视频博主很火,他是博士肄业,有很高的学历。他现在做打假赛道,高学历死磕高学历。他打假的对象是各个985院校各学院院长,对他们进行期刊文章打假。他虽然不是各个学科都懂,但他就看院长们在超牛国外期刊上发的文章,他会看这些文章的数据,有没有明显是造的,比如:末位都是5,数据都是间隔3,因为文章一旦发表,就不让改了,可能之前没人关注过这事,现在麻烦来了。有的导致院长停职,他说:作为院长不能既要又要,文章出问题了,说是自己没参与,下面学生写的,自己只是挂名。文章没出事,拿着这些知名文章去申请国家基金,去演讲出书获利。这位博主靠这个火了,还挺意外,流量来了,不愁吃喝,不过,死磕名校院长这事,估计让他在学术圈是混不下去了,话又说回来,估计人家也不打算进那个圈子啦。
[228+100]-------->底部有张生活照 (头条号运营:大家想全托管上号的联系我哦,每天让你得个早餐钱,wx: qhz198607)
(头条号运营:大家想全托管上号的联系我哦,每天让你得个早餐钱,wx: qhz198607)
【关键词】:python、ragflow、专家诊断、并发执行
一、专家诊断(三级)
描述:现在专家诊断过程中,用到了es搜索,并且用到了多次es搜索,有的搜索很慢,排查一下原因。
开工:
第一步:慢查询(四级)
20250409周三时间段:18:45-19:00
慢query如下:
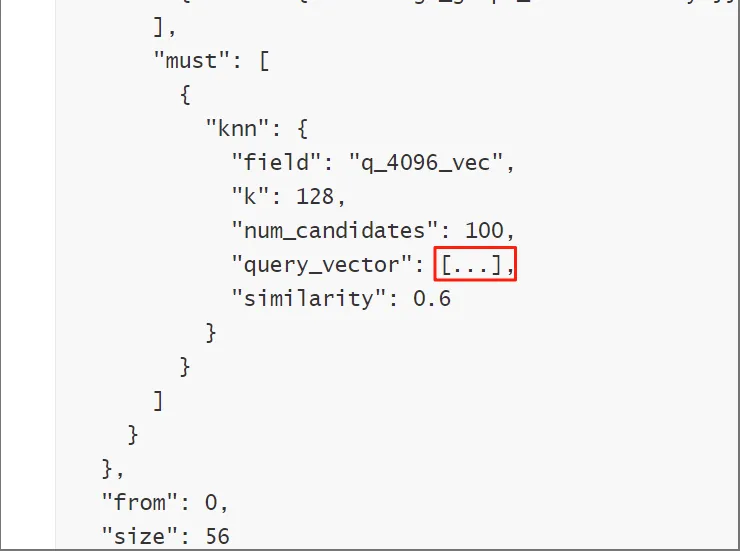
query:{"knn": {"field": "q_4096_vec", "k": 128, "num_candidates": 256, "query_vector": [6.1073222160339355, -1.404711365699768, 1.6913169622421265, 1.3805965185165405, -2.808076858520508, -4.008290767669678, -3.010448932647705, -9.411792755126953, 4.551467418670654, 1.8493108749389648, "..."], "filter": {"bool": {"filter": [{"terms": {"kb_id": ["bf5b0a6eff1211ef94e1acde48001122"]}}, {"term": {"knowledge_graph_kwd": "entity"}}]}}, "similarity": 0.6}, "from": 0, "size": 56} 注:查下原因。
第二步:es超时(四级)
20250409周三时间段:18:56-19:00
原因及方案如下:
ES KNN 搜索性能分析
这个 Elasticsearch KNN (k-Nearest Neighbors) 搜索查询存在几个可能导致性能问题的因素:
主要性能瓶颈
高维向量搜索:
大量候选检查:
过滤条件影响:
结果数量:
优化建议
降低候选数量:
json
"num_candidates": 100 // 尝试减少到50-100范围
优化过滤策略:
向量维度优化:
硬件优化:
确保节点有足够内存处理高维向量
考虑使用专门优化的向量搜索库如 FAISS
查询结构调整:
{
"query": {
"bool": {
"filter": [
{"terms": {"kb_id": ["bf5b0a6eff1211ef94e1acde48001122"]}},
{"term": {"knowledge_graph_kwd": "entity"}}
],
"must": [
{
"knn": {
"field": "q_4096_vec",
"k": 128,
"num_candidates": 100,
"query_vector": [...],
"similarity": 0.6
}
}
]
}
},
"from": 0,
"size": 56
}监控与测试:
使用 Profile API 分析查询各阶段耗时
对不同参数组合进行基准测试
如果这些优化仍不足,可能需要考虑专门的向量数据库解决方案。
注:先看下这个query中的省略号是真的还是输出时做了优化。截图如下:
图7a-1
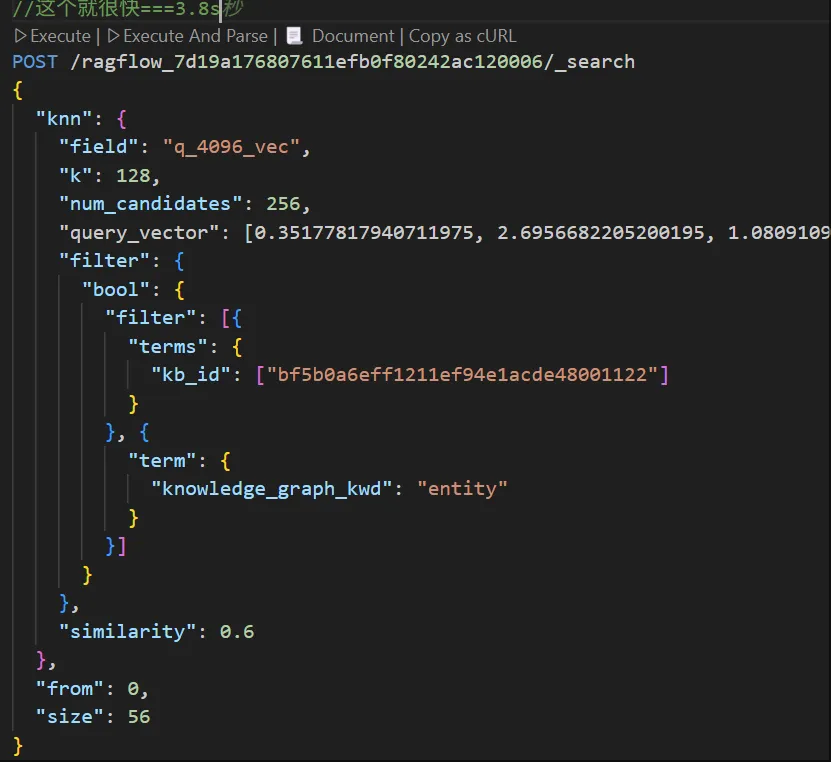
注:经查是输出做了优化,断点截图如下:
图7a-2
注:上面这个就很快3.8s就出结果了,同样的下面这个就很慢,如下:
ESConnection.search ['ragflow_7d19a176807611efb0f80242ac120006'] query:{"knn": {"field": "q_4096_vec", "k": 128, "num_candidates": 256, "query_vector": [0.35177817940711975, 2.6956682205200195, 1.0809109210968018, -2.875462293624878, 4.698151588439941, 1.482258677482605, -3.3839235305786133, -4.588975429534912, 6.330898761749268, -0.15971216559410095, "..."], "filter": {"bool": {"filter": [{"terms": {"kb_id": ["bf5b0a6eff1211ef94e1acde48001122"]}}, {"term": {"knowledge_graph_kwd": "relation"}}]}}, "similarity": 0.6}, "from": 0, "size": 56} 注:与上面的区别是一个是
"knowledge_graph_kwd": "entity"}
一个是:
"knowledge_graph_kwd": "relation"}
注:一个实体,一个关系,就是说查实体时不慢,查关系时慢。
那接下来看下有多少实体,多少关系。
第三步:实体及关系数量(四级)
20250409周三时间段:20:30-21:00
是不是说实体量少,关系量大,导致查询关系超时了。
从截图来看,确实查关系超时了,截图发吓:
图7a-3
注:接下来,查下实体数量及关系数量。
二、并发执行(三级)
描述:现在执行es同步索引数据到新索引,请求一个接口,速度很慢,想法提高一下。
开工:
第一步:思路(四级)
20250410周四时间段:11:31-12:00
想着传个参数过去,比如100万条数据,同时调10次接口,
第一个接口传0,从0开始
第二个接口传10万,从10万开始,
。。。。
所以接下来,要修改下接口,传参数。
第二步:修改接口(四级)
20250410周四时间段:14:53-15:00
修改程序如下:
图7b-1
注:接下来,运行看看效果,发现不支持from,因为下面有scroll,问下deepseek.
第三步:问deepseek(四级)
20250410周四时间段:15:54-16:00
20250410周四时间段:16:08-17:00
解决方法如下:
主要问题及优化建议
避免使用 from 参数结合 Scroll API:
低效的打标操作:
错误处理与恢复机制:
性能调优:
优化说明如下:
优化说明
建议根据实际Elasticsearch集群性能调整 batch_size 和 request_timeout 参数,并在生产环境进行充分测试。
添加重试机制和更完善的错误处理。
明确的进度日志,便于监控迁移状态。
增大请求超时时间至120秒。
调整批量大小至5000(根据实际集群性能调整)。
高效分页:
批量打标优化:
错误恢复:
性能调优:
代码健壮性:
注:运行报错了,截图如下:
图7b-2
注:不支持这个参数search_after,查下怎么改进,另外,还要查下,es的性能,以决定起几个并发合适。
三、头条号战果汇报
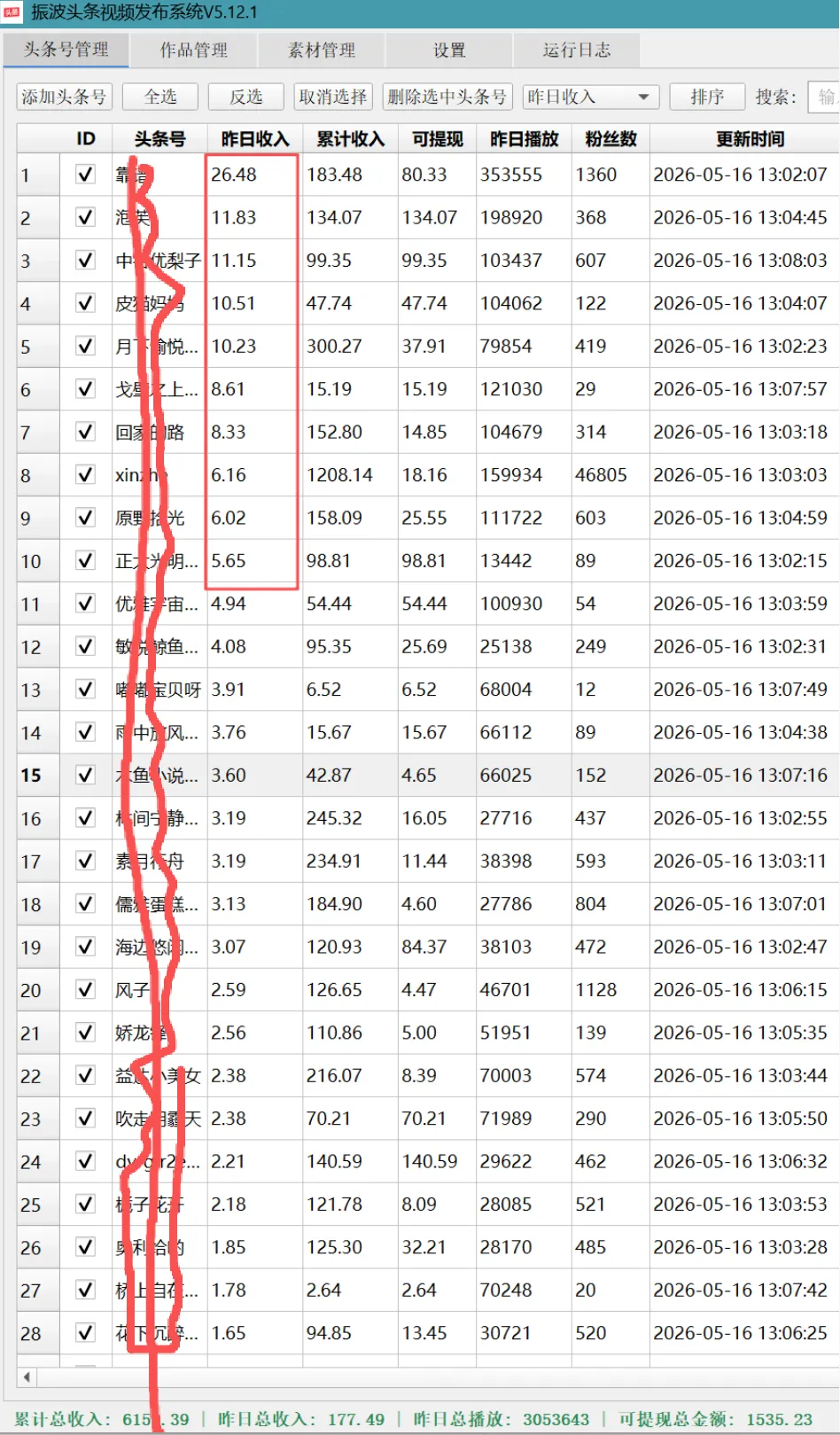
昨日数据来啦,累计总收入:6151.52,昨日总收入:177.49 昨日总播放:305.1万,可提现总金额:2199.57,软件截图如下:
图7c-1
注:想要全脱管运营头条号的联系我,你出账号,我来运营,收益四六分成(你六我四),你当甩手掌柜,每天都能得几块零花钱,财富wx: 17701328814,也可以加群先了解一下。
图7c-2
四、生活照片
拍摄于2026年2月8日,19:52:14,带两个孩子去看花灯,还挺可爱。人要学会知足常乐,或者说当拿到自己不该拿到的,出了问题,要认。就像之前翟姓演员,演戏,上春晚,忙的不亦乐乎,也是顶流了,就好好演戏呗,偏要去考什么博士学位,考就偷摸考呗,还大肆晒毕业照,结果人家一扒,论文数据全是假的,重复率很高,结果被除名,也被封杀,何必呢。
图7d-1
《本文完》