Python-17-树模型
- 2026-07-02 16:48:15
Python-17-树模型线性模型 是认为个特征是可累加的,通常可以将特征组合成一个线性方程,模型认为每个特征对结果的的贡献是独立的,可以简单相加。例如Y=A+2B+3C+4D,如果特征A值增加1,那么Y的值会相应增加1。如果D的值增加0.1,Y的值才会增加0.4。线性模型的计算是基于特征的数值进行加权计算的,对数值大小本身敏感,所以在使用前需要进行数据预处理,消除量纲。
树模型, 是根据特征数,将所有可能性分成以一个个俄罗斯方块。将对结果影响大的特征放在最前面做根节点,按特征里的内容进行分类。例如A的结果=特征1的条件符合a+特征2的条件符合b+特征3的条件符合c。是一连串的条件的组合,只要数值还符合条件里,结果是不变的。它对特征间数值的量级没有要求,所以在使用时不需要对数据预处理。 树模型内容: 包括的有“决策树、随机森林、AdaBoosting、梯度提升决策树GBDT、极端梯度提升XGBoost”,都可以处理分类问题和预测数值的问题。 决策树理解: 是把一大块的数据集按特征1切成几份,在对切出来的每一份用特征2继续切分。最终形成从上至下的像公司里的组织层级图一样,像一棵自下而上生长的树。 决策树评价: 是用特征进行训练的模型,根据所用特征数的多少,分为浅决策树,和深决策树。而一棵越深的决策树,说明这个模型越复杂,它预测的结果和实际的结果越近,偏差越小。这也有一个弊处,换一批新的数据输入训练好的模型,它的预测结果波动很大,方差大。浅决策树:偏差大,方差小;深决策树:偏差小,方差大。 决策树提升思路:既然一棵树不太好平衡偏差和方差的缺陷,我们使用更多的树来进行组合,组合方式有两种,串行和并行。这样的学习是集成学习(ensemble)
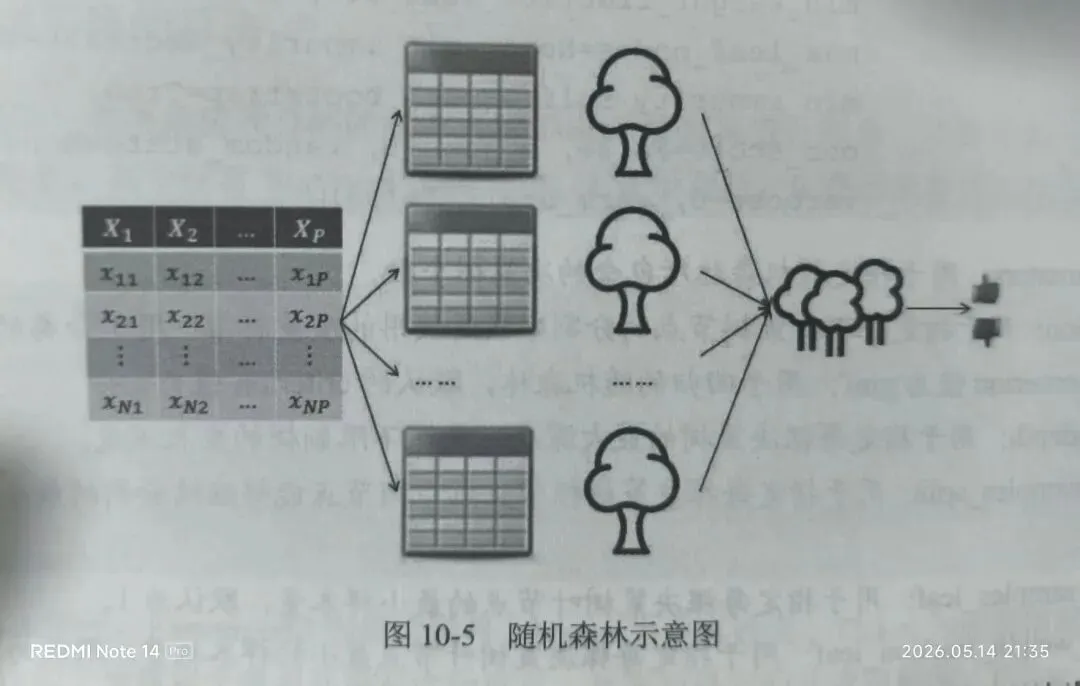
多棵决策树并行工作 随机森林:森林是由多棵树组成的字面意思,随机是表示构成多棵决策树的数据是随机生成的。它的核心思想是采用多棵决策树的投票机制,对于分类问题,将多棵树的判断结果用来投票,投票数多的即为最终的结果;对于预测性问题,取多棵决策树的回归结果的平均值为最终样本的预测值。
多科决策树串行工作 AdaBoost:把多棵树串行起来工作。从第二树起,对前一棵树预测的结果中错误的数据赋予更高的权重。在当次运行时,告诉机器,这几个样本数据很重要,不能再犯错了。相当于错题集,机器为了让总错误最小,会额外关注这几个犯错的数据,可能会牺牲掉一些权重低的数据的正确性。这个模型对异常值很敏感。 GDBT:把多棵树串行起来工作,关注点是是(真实值-预测值)差值的部分。如果差值为正,说明预测低,需要在预测的结果上再加一个值。这个值的内容为(差值*学习率比如0.1),防止步子太大。这样不断计算差值,用新的树拟合残差,最终差值会越来越小,总预测值会越来越近真实值。这里会涉及到一个数学知识(一阶导数):一个函数在某点的梯度(斜率)就是它对自变量求导。通过对平方损失的构造并进行求导会得到负梯度=残差。GDBT是梯度提升的缩写。 XGBoost:相比喻GBDT只有一阶求导的负梯度,XGBoos定义了一完整的目标函数=损失函数+正则化项。差值的一阶倒数确定了方向,XGBoost还使用了二阶导数,可以看出损失函数的曲率。具体讲起来有点多了。
总结: 1.树模型相当于对一组数据进行多条件的筛选,类似Excel里(ifs)。 2.决策树是树模型的基础单元,其它的算法核心都是怎么实现预测值更加接近真实值的处理,引入多棵树解决单棵树的局限性。
~~~梳理了自己的思绪,是开心的。
Day 17--“小满” #Python,#决策树,#数据挖掘 “皎洁终无倦,煎熬亦自求。”-李商隐《灯》
from sklearn.tree import DecisionTreeRegressorfrom sklearn.tree import DecisionTreeClassifier
 |
from sklearn.ensemble import RandomForestClassifierfrom sklearn.ensemble import RandomForestRegressor
#AdaBoost(分类 + 回归)from sklearn.ensemble import AdaBoostClassifierfrom sklearn.ensemble import AdaBoostRegressor
#GBDT 梯度提升树(分类 + 回归)from sklearn.ensemble import GradientBoostingClassifierfrom sklearn.ensemble import GradientBoostingRegressor
from xgboost import XGBClassifierfrom xgboost import XGBRegressor
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。

