Python 凭借强大的数据处理、文本分析与自动化能力,已成为现代审计的核心技术工具,可大幅提升审计效率、覆盖度与精准度,尤其适合处理海量、异构、非结构化数据。以下从核心应用场景、技术方法、实战案例、代码示例四方面系统说明。
一、Python 在审计中的核心应用场景
1. 财务数据审计(最常用)
海量凭证 / 明细账分析:自动读取、清洗、关联财务数据,筛查异常分录、重复支付、大额现金、跨期入账等。
往来款 / 银行流水分析:自动对账、识别未达账项、追踪资金流向、发现挪用 / 侵占线索。
报表勾稽与趋势分析:自动计算财务比率、识别异常波动、验证报表逻辑一致性广西柳州市审计局。
2. 大数据与合规审计
医保 / 社保 / 补贴资金审计:筛查虚假报销、串换项目、冒领、异常消费等。
政府投资 / 工程审计:招投标串标、清单比对、发票追溯、分包合规性核查。
消费券 / 惠民资金审计:定位虚假核销、异地套取、商家合谋等。
3. 文本与非结构化数据审计
招投标文件 / 合同文本分析:关键词提取、相似度比对、识别串标 / 围标线索菏泽市审计局。
会议纪要 / 制度文件审计:TF-IDF、词云、主题模型,快速锁定重点与风险点金华市审计局。
日志 / 交易记录文本挖掘:识别异常行为模式、违规操作痕迹。
4. 自动化与流程优化
数据采集与清洗自动化:批量读取 Excel/CSV/ 数据库、去重、补全、格式统一。
审计程序自动化:自动生成函证、抽样、测试脚本、异常标记与报告。
可视化与预警:用 Matplotlib/Seaborn/Plotly 生成趋势图、异常点、热力图,直观定位风险。
5. 信息系统与安全审计
代码安全审计:检测硬编码密码、API 密钥泄露、SQL 注入、命令注入等。
配置合规检查:自动扫描系统配置、权限设置、日志完整性。
日志分析:海量日志解析、异常行为识别、入侵痕迹追踪。
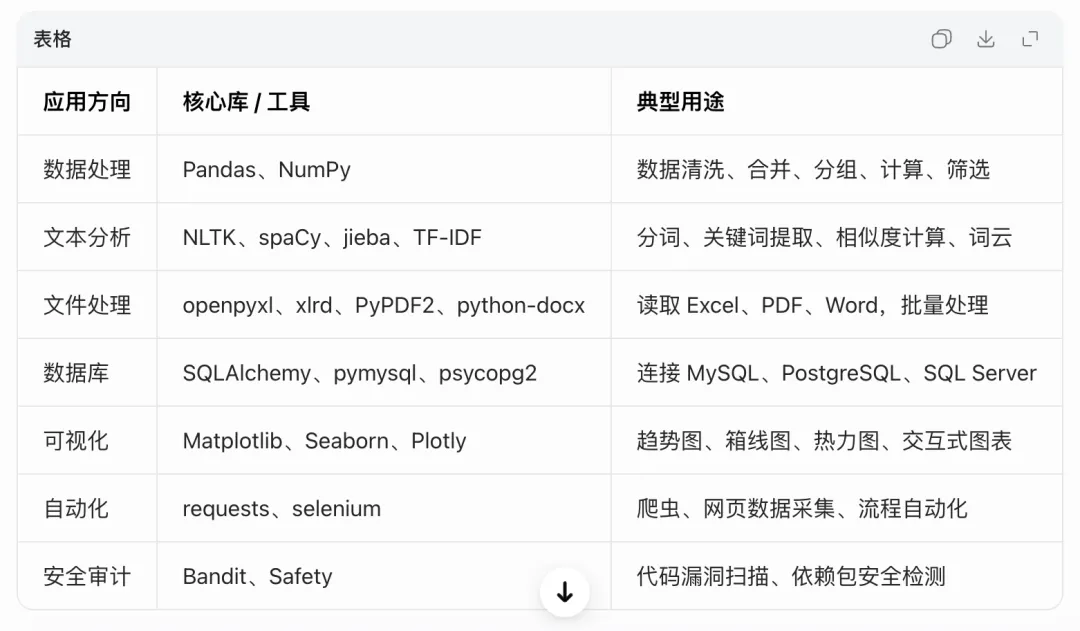
二、Python 审计常用技术与库
三、实战案例(含思路与方法)
案例 1:医保基金审计 —— 查处药店 “以药易药、以药易物” 骗保
背景:定点药店将大米、食用油、保健品等串换为医保药品结算,虚构交易套取基金,传统人工核查效率极低。
Python+SQL 协同方案:
数据层(SQL):提取医保结算数据、药品目录、药店信息,标准化入库。
关联层(SQL):按结算单号、药品编码、药店 ID 关联,聚合金额、频次。
算法层(Python):
用字符串相似度算法(如 Levenshtein 距离、余弦相似度)比对结算药品名与目录名,识别串换。
筛选高频、大额、非医保目录内的结算记录。
分析同一医保卡短时间内多店消费、异常金额等模式。
输出层:生成疑点清单,人工核查。
成效:查处 21 家药店串换非医保物品、8 家串换药品、1 家空刷,违规金额 60.7 万元,推动整改与处罚。
案例 2:政府投资审计 —— 招投标串标筛查
背景:电子标书海量、非结构化,人工无法全面比对,串标隐蔽。
Python 方案:
文件提取:用 PyPDF2、python-docx 批量读取 PDF/Word 标书,提取报价、单位、联系人、工期等关键字段。
数据清洗:Pandas 统一格式、去重、补全缺失值。
异常检测:
计算不同投标单位报价的相似度 / 标准差,识别高度一致报价。
筛查同一 IP、同一联系人、同一邮箱、同一地址的多单位投标。
分析报价规律(如等差、等比),识别围标特征。
结果输出:标记 59 个问题项目,11 个疑似串标,48 个程序违规。
案例 3:消费券审计 —— 追查虚假核销
背景:商家与个人合谋,用虚拟定位异地套取消费券。
Python 方案:
数据准备:获取消费券核销数据(手机号、身份证、商家、金额、时间)。
归属地分析:
用 Python 提取身份证前 6 位,匹配行政区划代码,判断用户户籍地。
调用接口解析手机号归属地,识别异地高频核销。
异常筛选:
同一手机号 / 身份证在多商家高频、大额、集中核销。
核销时间异常(如凌晨、非营业时间)、金额为固定值。
定位疑点:锁定异地套取、虚假交易线索。
案例 4:工程审计 —— 清单比对与发票追溯
背景:招标清单与投标清单雷同、违法分包,人工比对数万条数据效率极低。
Python 方案:
清单比对:自动读取 Excel 清单,按子目编码、名称、工程量、单价比对,高亮一致项,计算相似度。
发票追溯:从数万条发票数据中,按 “总包→分包→再分包” 多层级追溯,自动生成分包关系链与金额汇总。
问题锁定:发现 334 项子目完全一致(一致性 93.56%),揭示违法分包、违规带主材。
案例 5:财务审计 —— 往来款自动对账(某集团内审)
背景:集团往来款对账量大、易出错,每月需 5 天人工。
Python 方案:
数据读取:自动从财务系统导出往来明细账,Pandas 合并。
匹配算法:按 “单位 + 金额 + 日期 + 摘要” 模糊匹配,识别差异。
差异标记:自动标记未达账项、单边账、金额不符。
报告生成:输出对账差异表、调节表。
成效:对账时间从 5 天缩至 4 小时,准确率 100%。
四、Python 审计代码示例(极简可运行)
示例 1:财务凭证异常筛查(Pandas)
python
运行
import pandas as pd
# 1. 读取凭证数据
df = pd.read_excel("凭证数据.xlsx")
# 2. 数据清洗
df = df.dropna(subset=["金额", "凭证日期", "科目编码"])
df["金额"] = df["金额"].astype(float)
# 3. 筛查异常
# 大额现金支出
large_cash = df[(df["科目编码"].str.startswith("1001")) & (df["金额"] > 100000)]
# 跨期入账(如12月31日后入账)
cross_period = df[(df["凭证日期"].dt.month == 1) & (df["摘要"].str.contains("12月"))]
# 重复支付
duplicate = df[df.duplicated(subset=["对方单位", "金额", "凭证日期"], keep=False)]
# 4. 输出结果
with pd.ExcelWriter("审计疑点.xlsx") as writer:
large_cash.to_excel(writer, sheet_name="大额现金", index=False)
cross_period.to_excel(writer, sheet_name="跨期入账", index=False)
duplicate.to_excel(writer, sheet_name="重复支付", index=False)
print("异常筛查完成,结果已保存至 审计疑点.xlsx")
示例 2:药品名称相似度比对(医保审计)
python
运行
import pandas as pd
from fuzzywuzzy import fuzz
# 读取医保目录与结算数据
drug_catalog = pd.read_excel("医保药品目录.xlsx")
settlement = pd.read_excel("医保结算数据.xlsx")
# 定义相似度函数
def find_similar_drug(settle_name, catalog_df, threshold=80):
max_score = 0
similar_name = ""
for _, row in catalog_df.iterrows():
score = fuzz.ratio(settle_name, row["药品名称"])
if score > max_score:
max_score = score
similar_name = row["药品名称"]
return similar_name, max_score
# 批量比对
settlement[["匹配药品名", "相似度"]] = settlement["结算药品名"].apply(
lambda x: pd.Series(find_similar_drug(x, drug_catalog))
)
# 筛选低相似度(疑似串换)
suspicious = settlement[settlement["相似度"] < 80]
suspicious.to_excel("疑似串换药品.xlsx", index=False)
示例 3:代码安全审计(Bandit)
bash
运行
# 安装
pip install bandit
# 扫描项目目录
bandit -r ./审计系统代码/
# 输出示例:
# >> Issue: [B105:hardcoded_password_string] Possible hardcoded password: 'Admin123'
# >> Severity: High Confidence: Medium
# >> Location: ./审计系统代码/db.py:15
# 15 password = "Admin123"
五、Python 审计实施要点
数据合规:严格遵守数据安全与隐私法规,脱敏处理敏感信息(身份证、手机号等)。
流程融合:Python 不是替代审计,而是赋能,需与审计准则、程序深度结合。
人机协同:代码负责批量处理、筛查疑点,人工负责核实、定性、取证。
持续迭代:根据审计发现优化规则、算法,提升精准度,减少误报。
能力建设:审计人员需掌握基础 Python、Pandas、数据可视化,无需成为专业程序员。
六、总结
Python 已从 “可选工具” 变为审计的标配能力,尤其在大数据、非结构化数据、高频重复场景中优势显著。通过数据处理自动化、异常筛查智能化、疑点定位精准化,可将审计人员从繁重手工劳动中解放,聚焦高风险领域,提升审计质量与覆盖度。(以上文章来源于网络,内容仅供读者学习、交流之目的。如有信息有误、涉及侵权,请及时联系我删除)