与Python的相爱相杀
- 2026-07-02 03:56:57
与Python的相爱相杀梳理代码的时候,摘出来几个通用的小逻辑,如果全都放在一起介绍会比较混乱,而且内容太多就看疲惫了。本次的餐前小点心包括:判断二月份的天数、表格与数据的对应关系、获取包含姓名的数据(加函数、列表等)。 一、判断二月份的天数 判断二月份的天数是28天还是29天(闰年为29天):可以使用Python的calendar模块提供的isleap()方法来判断年份是否为闰年;也可以直接通过计算判断是否为闰年(能被4整除但不能被100整除,或者能被400整除的为闰年)。 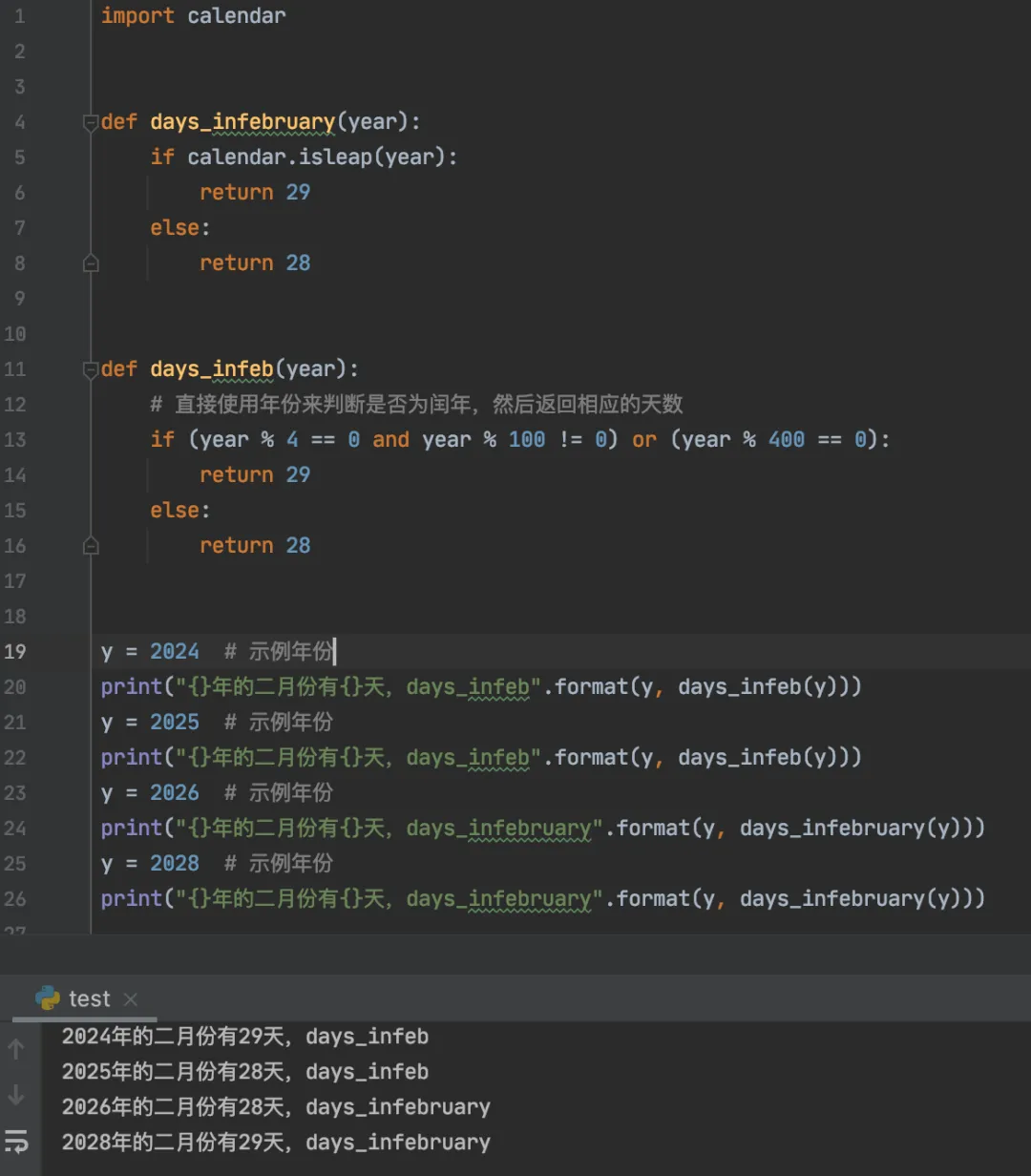
二、表格与数据的对应关系 处理表格前,需要先找好表格与数据的对应关系: 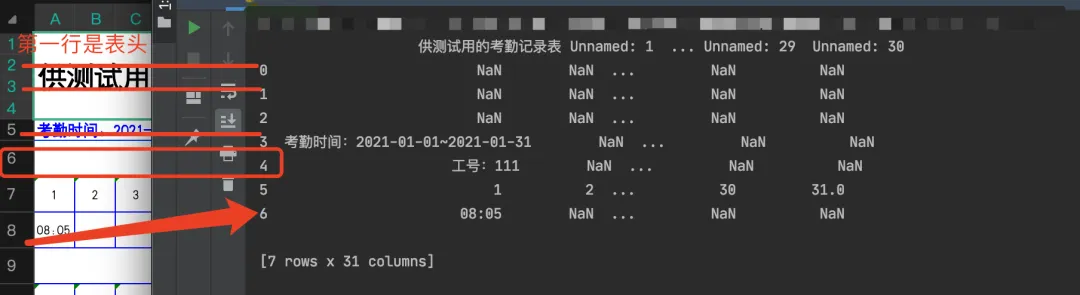
如图,Excel表格的第6行对应代码所读取的数据框架中索引为4的数据(以处理的文件或运行结果为准,每个原始文件的数据位置可能不同哦),里面有我们需要的工号、姓名和部门的信息;表格第7行是当前月份的日期:一月份(1-31),六月份(1-30);表格第8行(索引6)是当前人员的具体考勤时间点,与日期相对应(比如赵一在2021年1月1日08:05有记录)。统计每个人的考勤时间就需要重复获取每个人每个月在哪天有打卡的时间,再根据这些时间的间隔是否满足规则记为有效或无效,最后再统计出来每个月的有效考勤次数以及全年的有效考勤次数。 代码: 三、获取包含姓名的数据 原始文件是按照月份记录的所有人员的打卡时间,所以处理文件的时候需要根据人名创建对应的sheet表单,表单中记录这个人12个月每一天的打卡时间点。假设原始文件如图所示: 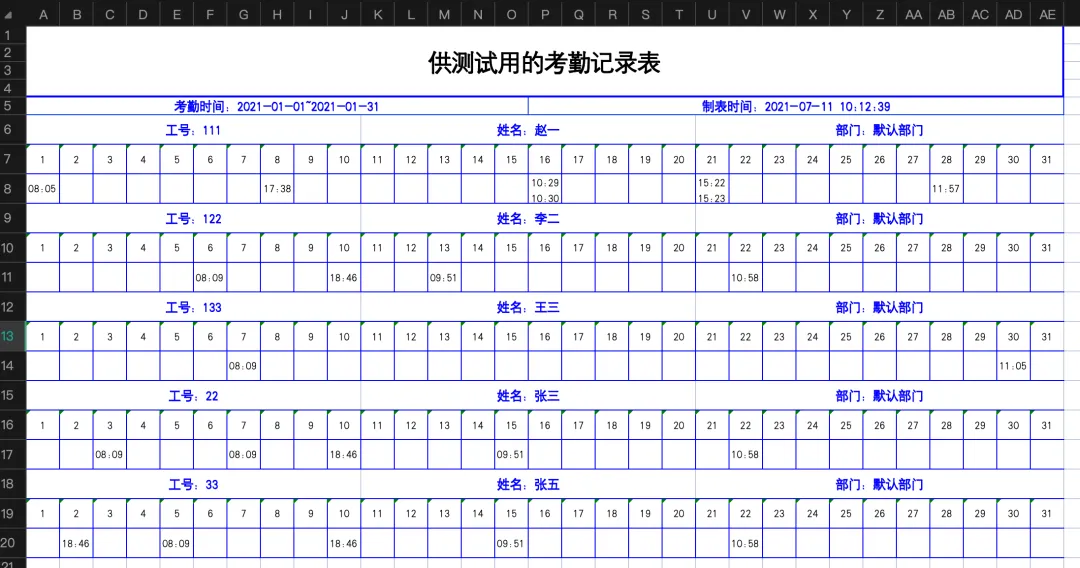
获取当前月份(示例中是一月份)指定列(K列,也就是第11列)中全部的姓名数据,这样就可以根据姓名列表创建sheet表单。方法如下:检查某一列中的每个值是否包含指定字符串(参数na=False可以过滤掉单元格为NaN的数据,只保留符合条件的数据)。 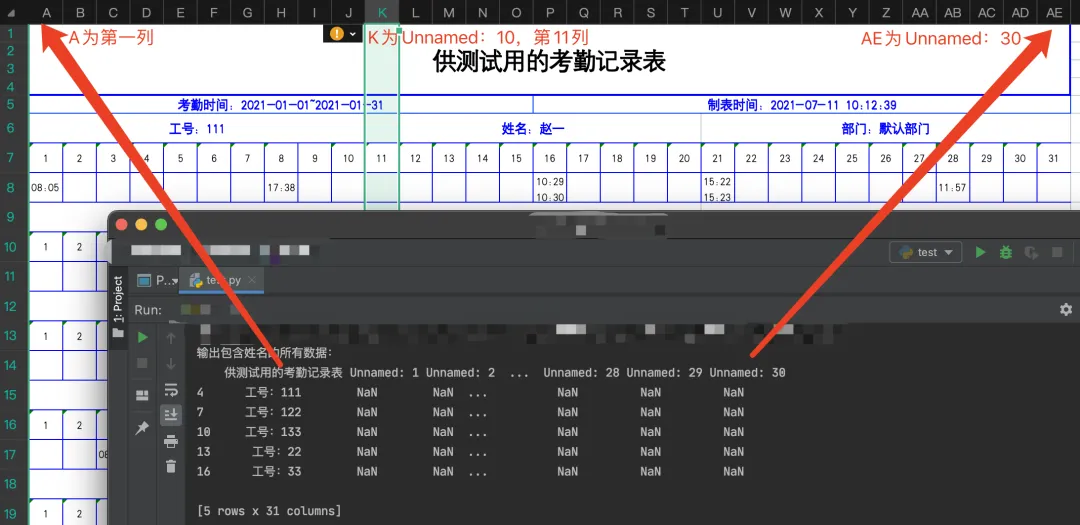
表格相关内容(戳一下带颜色的时光机可直达哦): 简单读写 数据处理 表格处理大全 现在来看,代码中要干的事情就有点多了,可以优化到函数里,简化一下主代码逻辑: 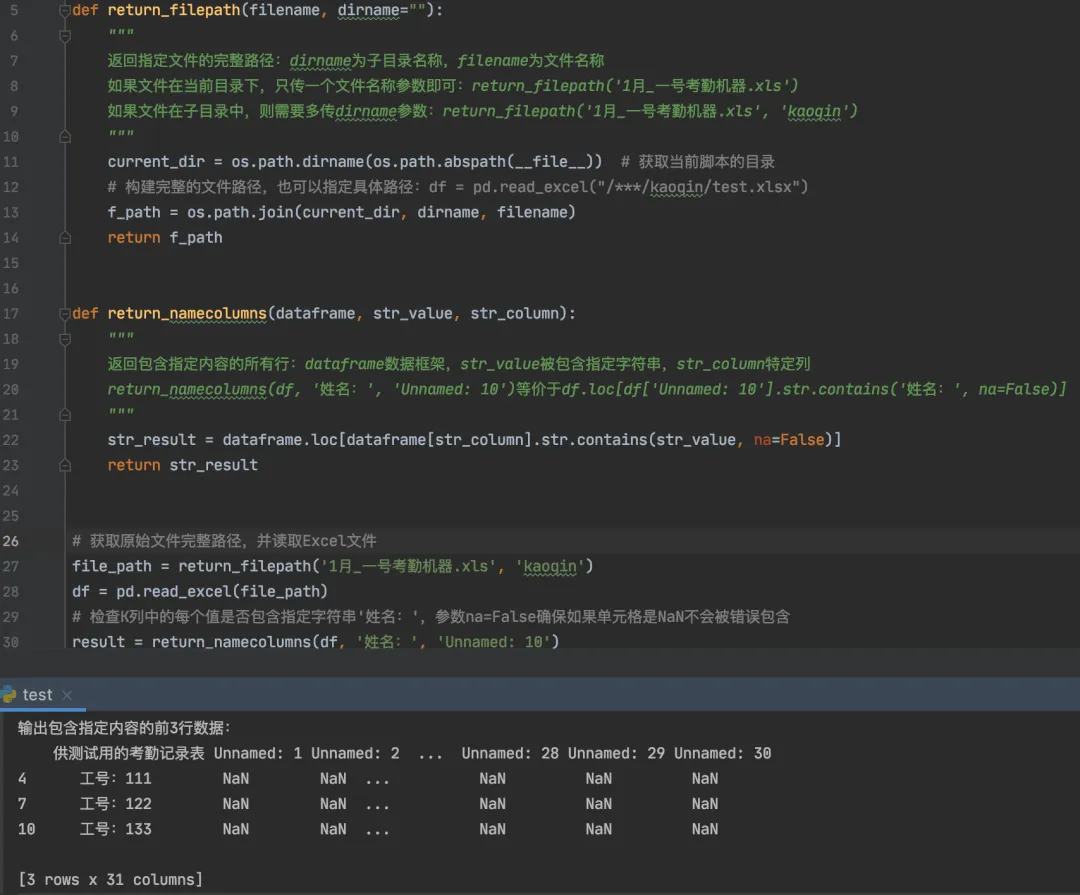
函数相关内容 戳 —> 函数 ,需要注意调用时的参数顺序。 上面说了我们要姓名列表, 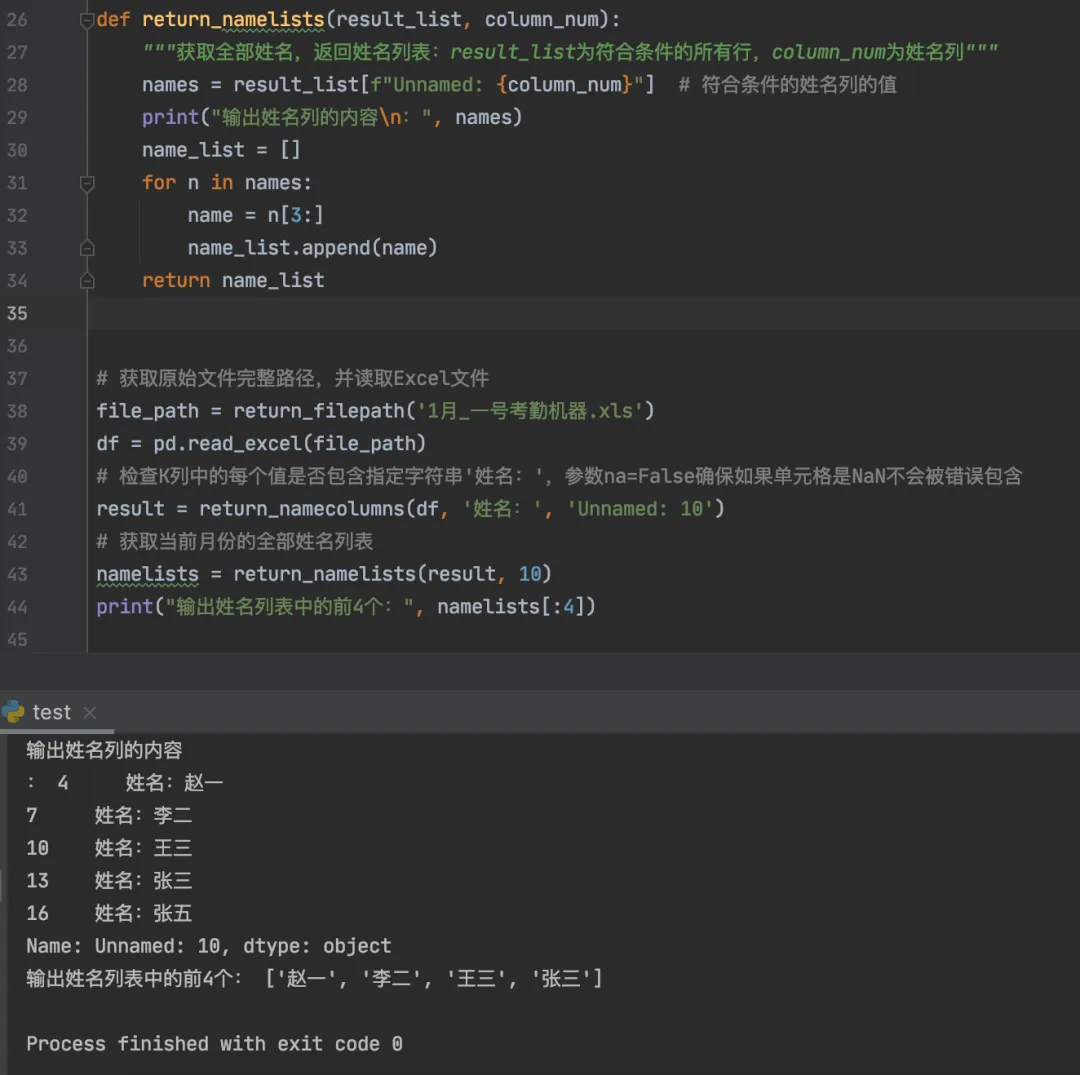
列表相关内容: 列表简介 操作列表,温故知新~ 
补完这三个逻辑,再加上之前介绍过的Python与Excel的相爱相杀,基本上就可以按照需求实现自己想做的东西啦,要不照着测试成品试试看吧~ 
写在前面:直说能消除大部分误会,长嘴的感情才能长久。
import calendardef days_infebruary(year):if calendar.isleap(year):return 29else:return 28def days_infeb(year):# 直接使用年份来判断是否为闰年,然后返回相应的天数if (year % 4 == 0 and year % 100 != 0) or (year % 400 == 0):return 29else:return 28y = 2024 # 示例年份print("{}年的二月份有{}天,days_infeb".format(y, days_infeb(y)))y = 2025 # 示例年份print("{}年的二月份有{}天,days_infeb".format(y, days_infeb(y)))y = 2026 # 示例年份print("{}年的二月份有{}天,days_infebruary".format(y, days_infebruary(y)))y = 2028 # 示例年份print("{}年的二月份有{}天,days_infebruary".format(y, days_infebruary(y)))
import osimport pandas as pd# 获取当前脚本的目录current_dir = os.path.dirname(os.path.abspath(__file__))# 构建完整的文件路径,如果有子目录:os.path.join(current_dir, 'kaoqin', '1月_一号考勤机器.xls')file_path = os.path.join(current_dir, '1月_一号考勤机器.xls')# 读取Excel文件df = pd.read_excel(file_path)# 输出Excel表格中的前8行数据,表头不计数print(df.head(7))
import osimport pandas as pd# 获取当前脚本的目录current_dir = os.path.dirname(os.path.abspath(__file__))# 构建完整的文件路径,如果有子目录:os.path.join(current_dir, 'kaoqin', '1月_一号考勤机器.xls')file_path = os.path.join(current_dir, '1月_一号考勤机器.xls')# 读取Excel文件df = pd.read_excel(file_path)# 检查K列中的每个值是否包含指定字符串'姓名:',参数na=False确保如果单元格是NaN不会被错误包含result = df.loc[df['Unnamed: 10'].str.contains('姓名:', na=False)]# 输出包含指定内容的所有数据print("输出包含姓名的所有数据:\n", result)
import osimport pandas as pddef return_filepath(filename, dirname=""):"""返回指定文件的完整路径:dirname为子目录名称,filename为文件名称如果文件在当前目录下,只传一个文件名称参数即可:return_filepath('1月_一号考勤机器.xls')如果文件在子目录中,则需要多传dirname参数,注意参数顺序!!return_filepath('1月_一号考勤机器.xls', 'kaoqin')"""current_dir = os.path.dirname(os.path.abspath(__file__)) # 获取当前脚本的目录# 构建完整的文件路径,也可以指定具体路径:df = pd.read_excel("/***/kaoqin/test.xlsx")f_path = os.path.join(current_dir, dirname, filename)return f_pathdef return_namecolumns(dataframe, str_value, str_column):"""返回包含指定内容的所有行:dataframe数据框架,str_value被包含指定字符串,str_column特定列return_namecolumns(df, '姓名:', 'Unnamed: 10')等价于df.loc[df['Unnamed: 10'].str.contains('姓名:', na=False)]"""# 参数na=False确保如果单元格是NaN不会被错误包含str_result = dataframe.loc[dataframe[str_column].str.contains(str_value, na=False)]return str_result# 获取原始文件完整路径,并读取Excel文件file_path = return_filepath('1月_一号考勤机器.xls', "kaoqin")df = pd.read_excel(file_path)# 检查K列中的每个值是否包含指定字符串'姓名:'result = return_namecolumns(df, '姓名:', 'Unnamed: 10')print("输出包含指定内容的前3行数据:\n", result.head(3))
import osimport pandas as pddef return_filepath(filename, dirname=""):"""返回指定文件的完整路径:dirname为子目录名称,filename为文件名称如果文件在当前目录下,只传一个文件名称参数即可:return_filepath('1月_一号考勤机器.xls')如果文件在子目录中,则需要多传dirname参数,注意参数顺序!!return_filepath('1月_一号考勤机器.xls', 'kaoqin')"""current_dir = os.path.dirname(os.path.abspath(__file__)) # 获取当前脚本的目录# 构建完整的文件路径,也可以指定具体路径:df = pd.read_excel("/***/kaoqin/test.xlsx")f_path = os.path.join(current_dir, dirname, filename)return f_pathdef return_namecolumns(dataframe, str_value, str_column):"""返回包含指定内容的所有行:dataframe数据框架,str_value被包含指定字符串,str_column特定列return_namecolumns(df, '姓名:', 'Unnamed: 10')等价于df.loc[df['Unnamed: 10'].str.contains('姓名:', na=False)]"""str_result = dataframe.loc[dataframe[str_column].str.contains(str_value, na=False)]return str_resultdef return_namelists(result_list, column_num):"""获取全部姓名,返回姓名列表:result_list为符合条件的所有行,column_num为姓名列"""names = result_list[f"Unnamed: {column_num}"] # 符合条件的姓名列的值print("输出姓名列的内容\n:", names)name_list = []for n in names:name = n[3:]name_list.append(name)return name_list# 获取原始文件完整路径,并读取Excel文件file_path = return_filepath('1月_一号考勤机器.xls')df = pd.read_excel(file_path)# 检查K列中的每个值是否包含指定字符串'姓名:',参数na=False确保如果单元格是NaN不会被错误包含result = return_namecolumns(df, '姓名:', 'Unnamed: 10')# 获取当前月份的全部姓名列表namelists = return_namelists(result, 10)print("输出姓名列表中的前4个:", namelists[:4])
无聊中..
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- Python爬虫教程35:常见的反爬与应对示例
- 用Python做石头剪刀布小游戏(附完整代码)
- 用Python做词语接龙小游戏(附完整代码)
- 用Python做一个升级版数字小游戏(附完整代码)
- 用 Python 搜索巨潮资讯公告:新手也能看懂的关键词公告抓取教程
- 一文搞懂 Linux 文件权限:chmod、chown 到底怎么用
- Linux GDB高级调试:GDB调试子进程与多进程同时调试
- Linux 磁盘分区与挂载实操,从此不再迷糊
- Impactor:Linux 用户终于不用借 Mac 给 iPhone 装 ipa 了
- 北科大的大佬终于把Python做成了漫画电子书
