2026 年你必须了解的 9 个现代 Python 库
- 2026-07-03 01:19:32
大家好,众所周知,Python 拥有大量出色的库,其中许多确实可以改变游戏规则。
因此,我发现了以下几款现代库,如果你想在 2026 年保持领先,这些库你一定要了解。
1. Polars — 极速 DataFrame 库
Polars 是一个由 Rust 编写的极速 DataFrame 库,用于操作结构化数据。

为什么要使用它:
•性能比 Pandas 快 10 到 100 倍•支持对大型数据集进行惰性求值•原生支持 Apache Arrow
文档:https://docs.pola.rs/
安装方法:
pip install polars示例
下面是一个使用 Polars 创建 DataFrame 的简单示例:
import polars as plimport datetime as dtdf = pl.DataFrame({"name":["Alice Archer","Ben Brown","Chloe Cooper","Daniel Donovan"],"birthdate":[dt.date(1997,1,10),dt.date(1985,2,15),dt.date(1983,3,22),dt.date(1981,4,30),],"weight":[57.9,72.5,53.6,83.1],# 单位:kg"height":[1.56,1.77,1.65,1.75],# 单位:m})print(df)
shape:(4,4)┌────────────────┬────────────┬────────┬────────┐│ name ┆ birthdate ┆ weight ┆ height ││---┆---┆---┆---││ str ┆ date ┆ f64 ┆ f64 │╞════════════════╪════════════╪════════╪════════╡│AliceArcher┆1997-01-10┆57.9┆1.56││BenBrown┆1985-02-15┆72.5┆1.77││ChloeCooper┆1983-03-22┆53.6┆1.65││DanielDonovan┆1981-04-30┆83.1┆1.75│└────────────────┴────────────┴────────┴────────┘
2. Ruff —— 速度最快的 Python 格式化与代码检查工具
Ruff 是一个使用 Rust 编写的超高速代码检查工具(Linter),旨在用一个工具同时替代 Flake8、Black 和 isort。

为什么要使用它?
•比 Flake8 快约 20 倍•支持自动修复(Auto-fix)代码问题•同时具备代码格式化(Formatter)和代码检查(Linter)功能•减少工具链复杂度,提高开发效率•非常适合大型项目和 CI/CD 流程
文档
https://docs.astral.sh/ruff/
安装方法
pip install ruff示例
我们可以使用 uv 来初始化一个项目:
uv init --lib demo该命令会创建如下结构的 Python 项目:
demo├── README.md├── pyproject.toml└── src└── demo├── __init__.py└── py.typed
接着,我们可以将 src/demo/__init__.py 的内容替换为以下代码:
from typing importIterableimport osdef sum_even_numbers(numbers:Iterable[int])->int:"""给定一个整数可迭代对象,返回其中所有偶数的和。"""return sum(num for num in numbersif num %2==0)
接下来,我们将 Ruff 添加到项目中:
uv add --dev ruff然后,可以通过 uv run ruff check 对项目运行 Ruff 代码检查:
$ uv run ruff checksrc/numbers/__init__.py:3:8: F401 [*]`os` imported but unusedFound1 error.[*]1 fixable with the `--fix` option.
在 src/numbers/__init__.py文件的第 3 行第 8 列,导入了 os 模块,但并未使用。
我们可以运行以下命令,让 Ruff 自动修复该问题:
$ uv run ruff check --fixFound1 error (1fixed,0 remaining).
3. PyScript — 在浏览器中运行 Python
PyScript 允许你在浏览器中编写并执行 Python 代码,就像使用 JavaScript 一样。
为什么要使用它?
•可以创建由 Python 驱动的 Web 应用•直接在 HTML 中工作,无需后端支持•对于前端开发者来说,能够用熟悉的 Python 快速构建交互式网页
文档
https://docs.pyscript.net/2025.2.4/
安装方法
PyScript 不需要通过 pip 安装。只需在 HTML 文档的 <head> 中添加 <script> 和 <link> 标签即可,例如:
<head><!-- PyScript 样式表 --><linkrel="stylesheet"href="https://pyscript.net/latest/pyscript.css"/><!-- PyScript 脚本 --><scriptdefersrc="https://pyscript.net/latest/pyscript.js"></script></head>
示例
创建一个简单的 .html 文件,然后使用 <py-script> 标签编写 Python 代码。
<!doctype html><html><head><!-- 推荐的 Meta 标签 --><metacharset="UTF-8"><metaname="viewport"content="width=device-width,initial-scale=1.0"><!-- PyScript CSS --><linkrel="stylesheet"href="https://pyscript.net/releases/2025.2.4/core.css"><!-- 该脚本用于初始化 PyScript --><scripttype="module"src="https://pyscript.net/releases/2025.2.4/core.js"></script></head><body><!-- 现在可以使用 <py-script> 标签编写 Python 代码 --><py-script>import sysfrom pyscript import displaydisplay(sys.version)</py-script></body></html>
4. Pandera — Pandas 数据验证工具
Pandera 使用基于 schema 的验证方法,帮助你对 Pandas 的 DataFrame 和 Series 进行数据校验。

为什么要使用它?
•在数据处理之前捕捉数据错误,避免下游问题•类似 Pydantic,但专门针对 Pandas•支持数据的单元测试(Unit Testing)•提高数据管道和数据分析的可靠性
文档
https://pandera.readthedocs.io/en/stable/
安装方法
pip install pandera示例
下面是一个使用 Pandera 对 Pandas DataFrame 进行验证的示例:
import pandas as pdimport pandera as pa# 待验证的数据df = pd.DataFrame({"column1":[1,4,0,10,9],"column2":[-1.3,-1.4,-2.9,-10.1,-20.4],"column3":["value_1","value_2","value_3","value_2","value_1"],})# 定义验证 schemaschema = pa.DataFrameSchema({"column1": pa.Column(int, checks=pa.Check.le(10)),# 小于等于 10"column2": pa.Column(float, checks=pa.Check.lt(-1.2)),# 小于 -1.2"column3": pa.Column(str, checks=[pa.Check.str_startswith("value_"),# 必须以 'value_' 开头# 自定义检查函数:确保下划线分割后有两部分pa.Check(lambda s: s.str.split("_", expand=True).shape[1]==2)]),})# 验证数据validated_df = schema(df)print(validated_df)
column1 column2 column301-1.3 value_114-1.4 value_220-2.9 value_3310-10.1 value_249-20.4 value_1
5. JAX — Google 出品的高性能深度学习框架
JAX 是一个由 Google 开发的高性能机器学习与数值计算库,专为高效计算而设计。
为什么要使用它?
•相比 NumPy,在 GPU/TPU 上具有更高性能•支持自动微分(Automatic Differentiation)•被广泛用于 Google 的 AI 与科研项目•适用于深度学习与科学计算
文档
https://docs.jax.dev/en/latest/quickstart.html
安装方法
仅 CPU(Linux / macOS / Windows)
pip install -U jaxGPU(NVIDIA,CUDA 12)pip install -U "jax[cuda12]"TPU(GoogleCloud TPU VM)pip install -U "jax[tpu]"
示例
下面是一个类似 NumPy 的简单示例:
import jax.numpy as jnpdef selu(x, alpha=1.67, lmbda=1.05):return lmbda * jnp.where(x >0, x, alpha * jnp.exp(x)- alpha)x = jnp.arange(5.0)print(selu(x))
[0.1.052.13.14999994.2]6. Textual — 用 Python 构建终端用户界面 (TUI) 应用
Textual 允许你在 Python 中使用丰富的组件构建现代终端界面应用程序。
为什么要使用它?
•可以创建美观的终端应用程序•与 Rich 库配合使用,实现丰富的样式和布局•无需前端开发经验即可构建交互式终端界面•适合构建工具类应用、监控面板和 CLI 工具
文档
https://textual.textualize.io/tutorial/
安装方法
pip install textual示例
下面是一个创建简单 TUI 应用的示例:
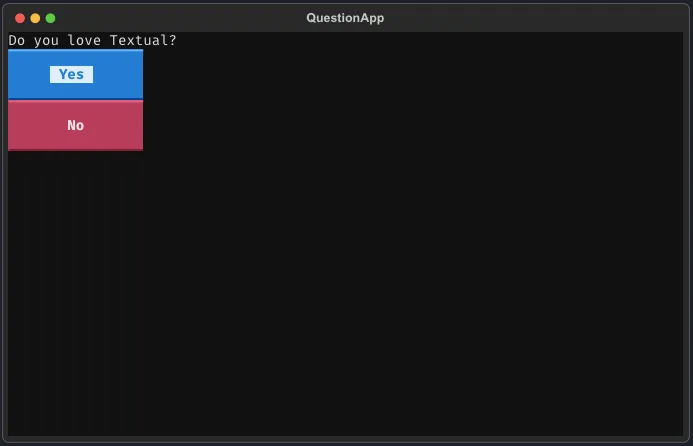
from textual.app importApp,ComposeResultfrom textual.widgets importLabel,ButtonclassQuestionApp(App[str]):def compose(self)->ComposeResult:yieldLabel("Do you love Textual?")yieldButton("Yes", id="yes", variant="primary")yieldButton("No", id="no", variant="error")def on_button_pressed(self,event:Button.Pressed)->None:self.exit(event.button.id)if __name__ =="__main__":app =QuestionApp()reply = app.run()print(reply)
运行上面的 TUI 应用后,你将在终端中看到如下效果:
7. LlamaIndex — 构建自定义 AI 助手
LlamaIndex 简化了大型数据集的索引与查询,非常适合基于大语言模型(LLM)的应用。
为什么要使用它?
•用于 RAG(Retrieval-Augmented Generation,检索增强生成)•支持与 OpenAI GPT 模型集成•可处理结构化和非结构化数据•帮助开发自定义 AI 助手、问答系统和知识检索工具
文档
https://docs.llamaindex.ai/en/stable/#getting-started
安装方法
pip install llama-index示例
下面是一个使用 agent 调用工具执行基本乘法的简单示例。
•创建文件 starter.py 设置环境变量 OPENAI_API_KEY,值为你的 OpenAI API Key[1]
import asynciofrom llama_index.core.agent.workflow importAgentWorkflowfrom llama_index.llms.openai importOpenAI# Define a simple calculator tooldef multiply(a:float, b:float)->float:"""Useful for multiplying two numbers."""return a * b# Create an agent workflow with our calculator toolagent =AgentWorkflow.from_tools_or_functions([multiply],llm=OpenAI(model="gpt-4o-mini"),system_prompt="You are a helpful assistant that can multiply two numbers.",)async def main():# Run the agentresponse = await agent.run("What is 1234 * 4567?")print(str(response))# Run the agentif __name__ =="__main__":asyncio.run(main())
The result of \( 1234 \times 4567 \) is \( 5,678,678 \).8. Robyn — 最快的 Python Web 框架
Robyn 是一个高性能 Python Web 框架,是 Flask 和 FastAPI 的替代方案之一,针对多核处理进行了优化。

为什么要使用它?
•性能约为 FastAPI 的 5 倍•支持异步(async)与多线程•底层使用 Rust 构建,性能极高•适合高并发 Web 服务与 API 开发
文档
https://robyn.tech/documentation/en
安装方法
pip install robyn示例
使用以下命令创建一个简单项目:
$ python -m robyn --create运行后,会生成如下项目结构:
$ python3 -m robyn --create?DirectoryPath:.?NeedDocker?(Y/N) Y?Pleaseselect project type (Mongo/Postgres/Sqlalchemy/Prisma):❯No DBSqlitePostgresMongoDBSqlAlchemyPrisma
运行创建命令后,会生成如下应用结构:
├── src│├── app.py├──Dockerfile
编写应用代码
接下来,你可以在 app.py 中编写如下代码:
from robyn importRequest@app.get("/")async def h(request:Request)-> str:return"Hello, world"
使用以下命令启动 Web 服务:
python -m robyn app.py9. DuckDB — 闪电般快速的内存数据库
DuckDB 是一个面向分析场景的内存型 SQL 数据库,在分析任务中通常比 SQLite 更快。

为什么要使用它?
•在数据分析场景中速度极快•无需单独启动数据库服务(开箱即用)•可与 Pandas、Polars 等工具无缝集成•非常适合本地数据分析、探索性分析(EDA)
文档
https://duckdb.org/docs/stable/clients/python/overview.html
安装方法
pip install duckdb --upgrade示例
下面是一个结合 Pandas DataFrame 使用 DuckDB 的简单示例:
import duckdbimport pandas as pdpandas_df = pd.DataFrame({"a":[42]})duckdb.sql("SELECT * FROM pandas_df")
输出结果
┌───────┐│ a ││ int64 │├───────┤│42│└───────┘
https://medium.com/the-pythonworld/9-modern-python-libraries-you-must-know-in-2026-e8a60611646bReferences
[1] OpenAI API Key: https://platform.openai.com/api-keys
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- Tableau与Python结合,搞定90%数据处理工作
- Python入门教程:类和对象的综合示例用法
- 苏州计算机二级Python培训,难度亲民,零基础友好!附2026年9月考试全攻略
- 不卷补习卷思维 | 少儿Python编程集训班火热招生中....
- 【Linux命令】mv命令:移动或改名
- 限量版,Linux 爱好者们的3份福利免费资料(珍藏)
- Linux 网络命令大全:工程师必备的 24 个实用命令(收藏级)
- Linux内核 CopyFail 高危漏洞复现及修复方案
- 【案例教程】最新AI+Python驱动的高光谱遥感全链路解析与典型案例实践
- 背下来,你就是Python爬虫岗的天花板!
