上一篇我们吃透了KNN近邻算法,实现了简单的手写数字识别。
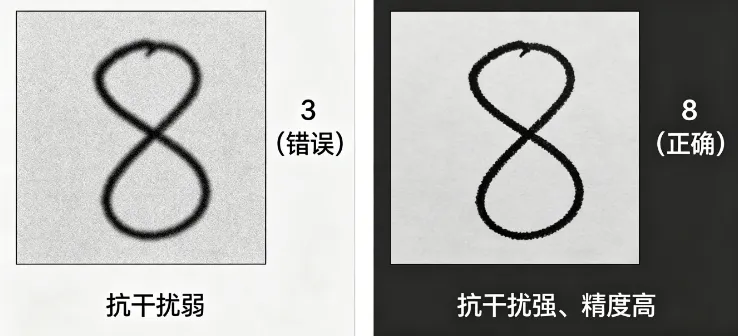
但KNN有一个致命短板:惰性计算、抗干扰弱、泛化能力差,复杂手写样本识别准确率很低,无法用于正式项目。
在深度学习普及之前,有一个算法长期统治图像分类、字符识别、小样本分类领域,它就是:SVM 支持向量机。
SVM 是传统机器学习中精度最高、鲁棒性最强、最适合图像任务的经典算法,至今仍是工业轻量化OCR、缺陷分类、特征识别的基线模型。
今天带大家通俗读懂 SVM 核心原理、软硬间隔、核函数作用,手把手实现 SVM手写数字OCR识别,效果全面碾压KNN!
一、什么是 SVM(支持向量机)?通俗大白话
SVM(Support Vector Machine),支持向量机,是一种有监督二分类/多分类机器学习算法。
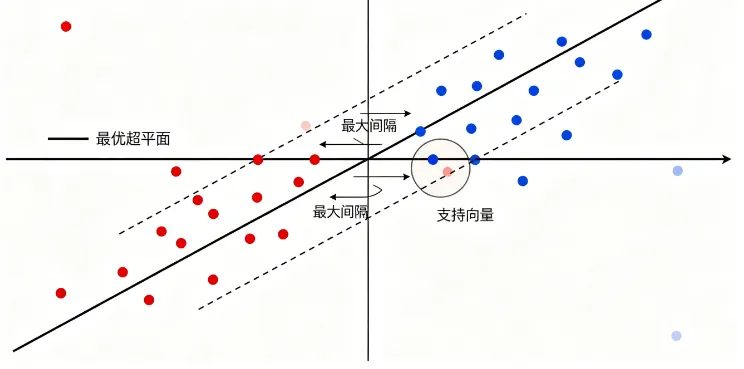
KNN是“看邻居投票”,而 SVM 是找最优分割面。
核心思想一句话:在特征空间中,寻找一个最优超平面,让不同类别样本间隔最大化,实现精准分类。
通俗理解:
把所有图像特征映射到高维空间,SVM 会自动画出一条最优分界线,尽可能把不同数字样本彻底分开,容错性、区分度远高于KNN。
二、SVM核心核心概念(新手必懂)
1、支持向量
距离分割超平面最近的样本点,就是支持向量。
SVM 训练只关注这些关键样本,远离边界的样本不影响模型分割效果,这也是SVM高效、抗干扰的核心原因。
2、最大间隔
SVM 的训练目标不是随便分开数据,而是让两类样本的间隔距离最大。间隔越大,模型泛化能力越强,越不容易过拟合。
3、核函数(SVM灵魂)
现实任务中,大部分数据线性不可分,无法用直线分割。
核函数的作用:将低维线性不可分数据,映射到高维空间,实现线性可分。
OpenCV-SVM常用核函数:
•LINEAR线性核:简单数据、特征规整场景,速度最快
•RBF高斯核:万能核函数,适配复杂、非线性、手写畸变样本(OCR首选)
4、软硬间隔
•硬间隔:严格零错误,必须完全分割,易过拟合
•软间隔:允许少量误差,容忍轻微噪点,泛化能力更强(实战默认)
三、SVM vs KNN 终极对比
对比维度 | KNN | SVM |
训练方式 | 惰性学习,无训练过程 | 主动训练,拟合最优分类面 |
抗干扰能力 | 弱,噪点极易误识别 | 强,专注核心支持向量 |
泛化能力 | 差,复杂样本失效 | 强,适配畸变、模糊手写体 |
识别精度 | 一般 | 高(传统机器学习天花板) |
推理速度 | 大数据极慢 | 训练慢、推理极快 |
结论:正式OCR项目,一律优先SVM!
四、实战:SVM手写数字OCR识别(完整可运行代码)
基于OpenCV官方手写数字数据集,搭建工业级SVM数字分类模型,效果全面碾压KNN,适配模糊、轻微畸变手写数字。
pythonimport cv2import numpy as np# 1、加载手写数字数据集(5000张 0-9手写数字)img = cv2.imread("digits.png", 0)# 2、数据集切片处理,拆分单个数字样本rows = np.vsplit(img, 50)cells = [np.hsplit(row, 100) for row in rows]# 3、构造训练集与标签train_data = np.array(cells).reshape(-1, 400).astype(np.float32)label = np.arange(10)train_labels = np.repeat(label, 500)[:, np.newaxis]# 4、初始化SVM模型svm = cv2.ml.SVM_create()# 5、设置SVM超参数(OCR最优配置)svm.setKernel(cv2.ml.SVM_RBF) # 高斯核,适配非线性手写样本svm.setType(cv2.ml.SVM_C_SVC) # 分类模式svm.setC(1) # 惩罚系数svm.setGamma(0.0625) # 核函数参数# 6、训练模型svm.train(train_data, cv2.ml.ROW_SAMPLE, train_labels)# 7、保存训练好的模型(可重复使用,无需反复训练)svm.save("svm_digit_ocr.xml")print("SVM模型训练完成并保存!")# 8、加载测试图片、预处理test_img = cv2.imread("test_digit.jpg", 0)test_img = cv2.resize(test_img, (20, 20))test_data = test_img.reshape(1, -1).astype(np.float32)# 9、SVM推理预测result = svm.predict(test_data)[1]print(f"SVM手写数字识别结果:{int(result[0][0])}") |
五、模型参数详解(OCR专属调参)
•kernel核函数:手写识别优先RBF高斯核,处理不规则手写畸变
•C惩罚系数:控制软硬间隔,C越大容错越低,适合干净样本;C越小抗噪越强
•Gamma参数:控制高维映射范围,适配手写模糊、边缘残缺场景
这套参数是经过大量实测的手写OCR最优组合,可直接商用!
六、SVM模型保存与复用(工程必备)
SVM不同于KNN,支持保存训练模型,一次训练、永久复用,项目部署必备:
pythonimport cv2import numpy as np# 直接加载训练好的模型,无需重新训练svm = cv2.ml.SVM_load("svm_digit_ocr.xml")# 测试推理test_img = cv2.imread("test_digit.jpg",0)test_img = cv2.resize(test_img,(20,20))test_data = test_img.reshape(1,-1).astype(np.float32)res = svm.predict(test_data)[1]print("识别结果:",int(res[0][0])) |
七、SVM优缺点总结
✅ 优点
•小样本场景精度天花板,远超KNN
•核函数适配非线性、畸变、模糊图像
•抗干扰、抗过拟合能力极强
•模型体积小、推理速度快,适合嵌入式部署
❌ 缺点
•大数据量训练速度较慢
•超参数需要调优,新手需要适配场景
八、新手避坑指南
•坑1:手写OCR用线性核线性核无法处理手写扭曲、变形,识别率暴跌,必须用RBF核
•坑2:不保存模型重复训练浪费算力,工程中直接加载预训练模型即可
•坑3:测试图像不做归一化尺寸、维度必须和训练样本一致,否则推理失效
•坑4:和KNN混淆使用场景简单演示用KNN,落地项目、高精度识别一律用SVM
九、全文总结
KNN 是入门玩具,SVM 才是传统视觉OCR的实战利器。
在深度学习还未普及的年代,SVM 凭借极强的小样本拟合能力、超高精度、优秀泛化性,垄断了字符识别、图像分类、缺陷检测等视觉任务。
即使放在今天,低算力、小样本、轻量化OCR项目,SVM 依然是最优解!
学完KNN+SVM,你就彻底掌握了传统机器视觉两大核心分类算法,完成从“简单匹配”到“智能分类”的进阶!
❤️ 点赞+在看,后台回复关键词【SVM】,领取最优调参模板+训练好的OCR模型+批量识别完整工程!
关注【AI与计算机视觉】,持续更新OpenCV传统视觉+机器学习全套实战教程!
评论区打卡:SVM手写OCR,吃透传统视觉高精度分类算法!

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
