AI 小说/文章生成系统设计文档
项目概述
基于 Flask + 阿里百炼(通义千问 API)实现的结构化 AI 小说/文章生成系统。
核心流程:大纲生成 → 人物卡片 → 章节内容生成(分段) → 一致性校验
关键约束:故事情节一致性、人物设定一致性、前后文逻辑连贯、支持续写。
功能需求
基础功能
多选配置
| |
|---|
| 玄幻、言情、悬疑、科幻、现实主义、历史、武侠、都市、奇幻、恐怖 |
| 严肃文学、网络文学、短篇小说、散文体、意识流、幽默讽刺、诗意抒情 |
| qwen-turbo / qwen-plus / qwen-max / qwen-long(可配置temperature) |
| Markdown(.md) / 纯文本(.txt) |
前端要求
提示词设计
1. 大纲生成提示词
你是一位专业的小说策划编辑。请根据用户提供的题材、风格、字数要求,生成一份结构化的小说大纲。
要求:
- 输出JSON格式
- 包含:书名、类型、主题、世界观设定、核心冲突、故事线(起承转合)
- 每个章节需包含:章节号、标题、核心事件、涉及人物、情绪基调
- 章节之间必须有因果逻辑链条,前一章的结果是后一章的起因
- 标注每章的伏笔埋设和回收点
用户输入:
- 题材:{genre}(可多选组合,如"悬疑+科幻")
- 风格:{style}(可多选组合,如"严肃文学+意识流")
- 目标字数:{word_count}
- 核心设定:{core_setting}
- 附加要求:{extra_requirements}
输出JSON结构示例:
{
"title": "书名",
"genres": ["类型1", "类型2"],
"styles": ["风格1", "风格2"],
"theme": "主题",
"world_setting": "世界观设定描述",
"core_conflict": "核心冲突",
"characters_overview": ["角色1", "角色2"],
"chapters": [
{
"chapter_num": 1,
"title": "章节标题",
"core_event": "核心事件",
"characters_involved": ["角色1"],
"tone": "情绪基调",
"foreshadowing_plant": ["伏笔1"],
"foreshadowing_resolve": [],
"cause_from_previous": null,
"effect_to_next": "本章结果导致..."
}
]
}
2. 人物卡片生成提示词
你是一位专业的角色设计师。请根据小说大纲,为每个主要角色生成详细的人物卡片。
要求:
- 输出JSON格式
- 每个角色包含:
- 姓名、年龄、性别
- 外貌特征(具体到发色/瞳色/身高/体型/标志性特征)
- 性格(用MBTI + 3个关键词描述)
- 背景故事(200字以内)
- 核心动机
- 口头禅(1-3句)
- 说话风格(用词偏好、语气特点)
- 技能/能力
- 弱点/缺陷
- 与其他角色的关系图谱
- 成长弧线:开始状态 → 转折事件 → 最终状态
- 角色之间必须有明确的关系定义(盟友/对手/恋人/师徒/亲属等)
- 角色设定不能与大纲中的世界观矛盾
参考大纲:
{outline_json}
输出JSON结构示例:
{
"characters": [
{
"name": "角色名",
"age": 25,
"gender": "男",
"appearance": {
"hair": "黑色短发",
"eyes": "深棕色",
"height": "178cm",
"build": "偏瘦",
"distinctive_features": ["左眉有疤", "常戴银色耳环"]
},
"personality": {
"mbti": "INTJ",
"keywords": ["冷静", "执着", "孤僻"]
},
"background": "背景故事...",
"motivation": "核心动机...",
"catchphrases": ["口头禅1"],
"speech_style": "简短有力,少用形容词,偶尔冷幽默",
"abilities": ["能力1"],
"weaknesses": ["弱点1"],
"relationships": [
{"target": "角色B", "type": "对手", "description": "描述"}
],
"arc": {
"start": "开始状态",
"turning_point": "转折事件",
"end": "最终状态"
}
}
]
}
3. 章节内容生成提示词(核心 - 保证一致性)
你是一位专业的小说作家。请严格按照以下约束生成第{chapter_num}章的内容。
【强制约束 - 违反任何一条即为失败】
1. 人物描写必须与人物卡片完全一致,不得出现卡片中未定义的外貌/性格特征
2. 情节必须严格遵循大纲中本章的核心事件,不得偏离
3. 必须承接上一章的结尾场景,开头需自然衔接
4. 本章中埋设的伏笔必须在大纲标注的章节中回收
5. 角色说话风格必须与人物卡片中定义的一致
6. 不得引入大纲中未规划的新角色或新设定
7. 写作风格必须符合用户选择的风格组合:{styles}
【本章信息】
- 章节大纲:{chapter_outline}
- 涉及角色:{characters_involved}
- 情绪基调:{tone}
- 上一章结尾摘要:{previous_summary}
- 需要埋设的伏笔:{foreshadowing_plant}
- 需要回收的伏笔:{foreshadowing_resolve}
【人物卡片】
{character_cards}
【全局设定】
{world_setting}
【输出要求】
- 字数:{target_words}字左右
- 在末尾用 --- 分隔,附加本章摘要(200字以内,用于传递给下一章)
- 标注本章新增的伏笔和回收的伏笔
4. 分段生成提示词(长章节拆分)
你是一位专业的小说作家。现在需要生成第{chapter_num}章的第{segment_num}/{total_segments}段。
【分段上下文】
- 本章总体规划:{chapter_outline}
- 本段需要覆盖的内容:{segment_plan}
- 前一段结尾内容:{previous_segment_ending}
- 本段目标字数:{segment_words}字
【强制约束】(同章节生成约束)
{constraints}
【人物卡片】
{character_cards}
【输出要求】
- 开头必须自然衔接前一段结尾
- 结尾需为下一段留出衔接点
- 如果是最后一段,需要为下一章留出悬念或过渡
5. 一致性校验提示词
你是一位严格的小说审校编辑。请检查以下章节内容是否存在一致性问题。
检查项:
1. 人物外貌描写是否与卡片一致(逐条对照)
2. 人物性格表现是否与设定一致(言行举止是否符合MBTI和关键词)
3. 人物说话风格是否与卡片定义一致
4. 情节是否偏离大纲的核心事件
5. 是否与前文存在矛盾(时间线/地点/已发生事件)
6. 新出现的设定是否在世界观范围内
7. 伏笔埋设和回收是否按计划执行
8. 写作风格是否符合用户选择的风格
【待检查内容】
{chapter_content}
【参照信息】
- 大纲:{outline}
- 人物卡片:{character_cards}
- 前文摘要:{previous_summaries}
- 本章计划伏笔:{planned_foreshadowing}
输出JSON格式:
{
"passed": true/false,
"score": 85,
"issues": [
{
"type": "人物外貌矛盾/性格偏离/情节偏离/时间线错误/设定冲突/风格不一致",
"severity": "严重/一般/轻微",
"description": "具体问题描述",
"location": "第X段/第X句",
"original_setting": "原始设定内容",
"suggestion": "修改建议"
}
]
}
6. 续写提示词(大纲修改后重新生成)
你是一位专业的小说策划编辑。用户修改了第{modified_chapter}章及之后的大纲,请重新规划后续章节。
【约束】
1. 已生成的前{last_generated}章内容不可修改,视为既定事实
2. 新的后续章节必须与已有内容逻辑一致
3. 已埋设但未回收的伏笔必须在新规划中安排回收
4. 人物的成长弧线需要重新适配
【已有内容摘要】
{existing_summaries}
【未回收的伏笔】
{unresolved_foreshadowing}
【用户修改后的大纲】
{modified_outline}
请输出修订后的完整后续章节大纲(JSON格式,结构同原大纲)。
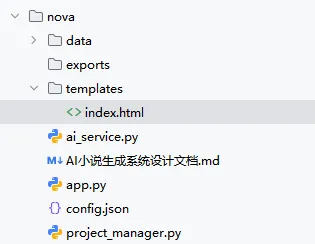
系统架构
后端 API(Flask)
Flask后端:
├── /api/project/create - 创建新项目
├── /api/project/save - 保存项目状态
├── /api/project/load - 加载项目
├── /api/project/list - 项目列表
│
├── /api/outline/generate - 生成大纲
├── /api/outline/update - 手动修改大纲
│
├── /api/characters/generate - 生成人物卡片
├── /api/characters/update - 手动修改人物卡片
│
├── /api/chapter/generate - 生成章节(支持分段)
├── /api/chapter/regenerate - 重新生成指定章节
├── /api/chapter/validate - 一致性校验
│
├── /api/continue/replan - 续写:重新规划后续大纲
├── /api/continue/generate - 续写:生成后续章节
│
├── /api/model/list - 可用模型列表
├── /api/model/switch - 切换模型
│
├── /api/export/markdown - 导出为Markdown
└── /api/export/txt - 导出为纯文本
前端页面结构
前端(可视化编辑器):
├── 首页/项目管理
│ ├── 新建项目向导
│ └── 已有项目列表
│
├── 项目工作台
│ ├── 左侧:章节导航树
│ ├── 中间:编辑/预览区
│ │ ├── 大纲编辑器(拖拽排序)
│ │ ├── 人物卡片编辑器(关系图谱可视化)
│ │ ├── 章节内容编辑器(富文本)
│ │ └── 全文预览
│ └── 右侧:配置面板
│ ├── 模型选择(下拉切换)
│ ├── 类型/风格多选
│ ├── 生成参数(temperature/字数)
│ └── 一致性检查结果
│
├── 续写面板
│ ├── 修改大纲入口
│ ├── 影响范围预览
│ └── 一键重新生成
│
└── 导出面板
├── 格式选择(md/txt)
├── 导出范围(全部/指定章节)
└── 下载
数据模型
Project(项目)
├── id, name, created_at, updated_at
├── genres[] - 类型多选
├── styles[] - 风格多选
├── model_config - 模型配置
├── word_count_target - 目标字数
│
├── Outline(大纲)
│ ├── title, theme, world_setting, core_conflict
│ └── chapters[]
│ ├── chapter_num, title, core_event
│ ├── characters_involved[], tone
│ ├── foreshadowing_plant[], foreshadowing_resolve[]
│ └── cause_from_previous, effect_to_next
│
├── Characters(人物卡片)[]
│ ├── name, age, gender, appearance{}
│ ├── personality{}, background, motivation
│ ├── catchphrases[], speech_style
│ ├── abilities[], weaknesses[]
│ ├── relationships[], arc{}
│ └── status (活跃/退场/死亡)
│
├── Chapters(章节内容)[]
│ ├── chapter_num, content, summary
│ ├── segments[] - 分段内容
│ ├── foreshadowing_status{}
│ ├── validation_result{}
│ └── generated_at, model_used
│
└── History(生成历史)[]
├── action, timestamp
├── model_used, parameters
└── input_prompt, output
分段生成策略
当章节目标字数超过模型单次生成上限时,自动分段:
分段规则:
1. 每段目标字数 = min(2000, 模型max_tokens对应字数)
2. 总段数 = ceil(章节目标字数 / 每段目标字数)
3. 根据章节大纲的核心事件,将内容拆分为对应段落计划
4. 每段生成时携带:前段结尾200字 + 本段计划 + 人物卡片 + 全局约束
5. 生成完毕后拼接,再做整体一致性校验
模型配置
支持模型:
├── qwen-turbo - 速度快,适合草稿和迭代
├── qwen-plus - 平衡质量和速度
├── qwen-max - 最高质量,适合最终生成
└── qwen-long - 长上下文,适合长章节
可调参数:
├── temperature - 创造力(0.1保守 ~ 1.0奔放)
├── top_p - 多样性
├── max_tokens - 单次最大输出
└── presence_penalty - 重复惩罚
技术栈
| |
|---|
| |
| |
| |
| HTML + CSS + JavaScript(可视化编辑器) |
| |
| |
| |
下一步
"""AI 小说生成系统 - Flask 主应用基于阿里百炼(DashScope)API"""import osimport jsonimport uuidimport timefrom datetime import datetimefrom flask import Flask, request, jsonify, render_template, send_filefrom flask_cors import CORSapp = Flask(name)CORS(app)配置app.config['DATA_DIR'] = os.path.join(os.path.dirname(file), 'data')app.config['EXPORT_DIR'] = os.path.join(os.path.dirname(file), 'exports')确保目录存在os.makedirs(app.config['DATA_DIR'], exist_ok=True)os.makedirs(app.config['EXPORT_DIR'], exist_ok=True)导入模块from ai_service import AIServicefrom project_manager import ProjectManagerai_service = AIService()project_mgr = ProjectManager(app.config['DATA_DIR'])==================== 页面路由 ====================@app.route('/')def index():return render_template('index.html')==================== 项目管理 API ====================@app.route('/api/project/create', methods=['POST'])def create_project():"""创建新项目"""data = request.jsonproject = project_mgr.create(name=data.get('name', '未命名项目'),genres=data.get('genres', []),styles=data.get('styles', []),word_count_target=data.get('word_count_target', 50000),core_setting=data.get('core_setting', ''),model_config=data.get('model_config', {}))return jsonify({'success': True, 'project': project})@app.route('/api/project/list', methods=['GET'])def list_projects():"""项目列表"""projects = project_mgr.list_all()return jsonify({'success': True, 'projects': projects})@app.route('/api/project/<project_id>', methods=['GET'])def get_project(project_id):"""获取项目详情"""project = project_mgr.load(project_id)if not project:return jsonify({'success': False, 'error': '项目不存在'}), 404return jsonify({'success': True, 'project': project})@app.route('/api/project/<project_id>', methods=['PUT'])def update_project(project_id):"""更新项目"""data = request.jsonproject = project_mgr.update(project_id, data)return jsonify({'success': True, 'project': project})@app.route('/api/project/<project_id>', methods=['DELETE'])def delete_project(project_id):"""删除项目"""project_mgr.delete(project_id)return jsonify({'success': True})==================== 大纲 API ====================@app.route('/api/outline/generate', methods=['POST'])def generate_outline():"""生成大纲"""data = request.jsonproject_id = data['project_id']project = project_mgr.load(project_id)if not project:return jsonify({'success': False, 'error': '项目不存在'}), 404outline = ai_service.generate_outline( genres=project['genres'], styles=project['styles'], word_count=project['word_count_target'], core_setting=project['core_setting'], extra_requirements=data.get('extra_requirements', ''), model_config=project.get('model_config', {}))project['outline'] = outlineproject_mgr.save(project)return jsonify({'success': True, 'outline': outline})@app.route('/api/outline/update', methods=['PUT'])def update_outline():"""手动修改大纲"""data = request.jsonproject_id = data['project_id']project = project_mgr.load(project_id)if not project:return jsonify({'success': False, 'error': '项目不存在'}), 404project['outline'] = data['outline']project_mgr.save(project)return jsonify({'success': True, 'outline': project['outline']})==================== 人物卡片 API ====================@app.route('/api/characters/generate', methods=['POST'])def generate_characters():"""生成人物卡片"""data = request.jsonproject_id = data['project_id']project = project_mgr.load(project_id)if not project:return jsonify({'success': False, 'error': '项目不存在'}), 404if not project.get('outline'): return jsonify({'success': False, 'error': '请先生成大纲'}), 400characters = ai_service.generate_characters( outline=project['outline'], model_config=project.get('model_config', {}))project['characters'] = charactersproject_mgr.save(project)return jsonify({'success': True, 'characters': characters})@app.route('/api/characters/update', methods=['PUT'])def update_characters():"""手动修改人物卡片"""data = request.jsonproject_id = data['project_id']project = project_mgr.load(project_id)if not project:return jsonify({'success': False, 'error': '项目不存在'}), 404project['characters'] = data['characters']project_mgr.save(project)return jsonify({'success': True, 'characters': project['characters']})==================== 章节生成 API ====================@app.route('/api/chapter/generate', methods=['POST'])def generate_chapter():"""生成章节(支持分段)"""data = request.jsonproject_id = data['project_id']chapter_num = data['chapter_num']project = project_mgr.load(project_id)if not project:return jsonify({'success': False, 'error': '项目不存在'}), 404outline = project.get('outline', {})characters = project.get('characters', [])chapters = project.get('chapters', [])# 获取本章大纲chapter_outline = Nonefor ch in outline.get('chapters', []): if ch['chapter_num'] == chapter_num: chapter_outline = ch breakif not chapter_outline: return jsonify({'success': False, 'error': f'大纲中未找到第{chapter_num}章'}), 400# 获取上一章摘要previous_summary = ''for ch in chapters: if ch['chapter_num'] == chapter_num - 1: previous_summary = ch.get('summary', '') break# 计算是否需要分段chapter_word_target = project['word_count_target'] // len(outline.get('chapters', [1]))max_per_segment = 2000model_config = project.get('model_config', {})result = ai_service.generate_chapter( chapter_num=chapter_num, chapter_outline=chapter_outline, characters=characters, world_setting=outline.get('world_setting', ''), styles=project['styles'], previous_summary=previous_summary, target_words=chapter_word_target, max_per_segment=max_per_segment, model_config=model_config)# 保存章节chapter_data = { 'chapter_num': chapter_num, 'content': result['content'], 'summary': result['summary'], 'segments': result.get('segments', []), 'foreshadowing_status': result.get('foreshadowing_status', {}), 'generated_at': datetime.now().isoformat(), 'model_used': model_config.get('model', 'qwen-plus')}# 更新或插入章节if 'chapters' not in project: project['chapters'] = []existing = Falsefor i, ch in enumerate(project['chapters']): if ch['chapter_num'] == chapter_num: project['chapters'][i] = chapter_data existing = True breakif not existing: project['chapters'].append(chapter_data) project['chapters'].sort(key=lambda x: x['chapter_num'])project_mgr.save(project)return jsonify({'success': True, 'chapter': chapter_data})@app.route('/api/chapter/regenerate', methods=['POST'])def regenerate_chapter():"""重新生成指定章节"""return generate_chapter()@app.route('/api/chapter/validate', methods=['POST'])def validate_chapter():"""一致性校验"""data = request.jsonproject_id = data['project_id']chapter_num = data['chapter_num']project = project_mgr.load(project_id)if not project:return jsonify({'success': False, 'error': '项目不存在'}), 404# 获取章节内容chapter_content = ''for ch in project.get('chapters', []): if ch['chapter_num'] == chapter_num: chapter_content = ch['content'] breakif not chapter_content: return jsonify({'success': False, 'error': '章节内容为空'}), 400# 获取前文摘要previous_summaries = []for ch in project.get('chapters', []): if ch['chapter_num'] < chapter_num: previous_summaries.append(ch.get('summary', ''))result = ai_service.validate_chapter( chapter_content=chapter_content, outline=project.get('outline', {}), characters=project.get('characters', []), previous_summaries=previous_summaries, model_config=project.get('model_config', {}))return jsonify({'success': True, 'validation': result})==================== 续写 API ====================@app.route('/api/continue/replan', methods=['POST'])def replan_outline():"""续写:重新规划后续大纲"""data = request.jsonproject_id = data['project_id']modified_from_chapter = data['modified_from_chapter']modified_outline = data['modified_outline']project = project_mgr.load(project_id)if not project:return jsonify({'success': False, 'error': '项目不存在'}), 404# 收集已有章节摘要existing_summaries = []for ch in project.get('chapters', []): if ch['chapter_num'] < modified_from_chapter: existing_summaries.append({ 'chapter_num': ch['chapter_num'], 'summary': ch.get('summary', '') })# 收集未回收的伏笔unresolved = ai_service.get_unresolved_foreshadowing(project, modified_from_chapter)new_outline = ai_service.replan_outline( existing_summaries=existing_summaries, unresolved_foreshadowing=unresolved, modified_outline=modified_outline, modified_from_chapter=modified_from_chapter, model_config=project.get('model_config', {}))# 更新大纲(保留前面章节,替换后面章节)old_chapters = [ch for ch in project['outline'].get('chapters', []) if ch['chapter_num'] < modified_from_chapter]project['outline']['chapters'] = old_chapters + new_outline.get('chapters', [])# 删除被修改的章节内容project['chapters'] = [ch for ch in project.get('chapters', []) if ch['chapter_num'] < modified_from_chapter]project_mgr.save(project)return jsonify({'success': True, 'outline': project['outline']})==================== 模型管理 API ====================@app.route('/api/model/list', methods=['GET'])def list_models():"""可用模型列表(从config.json读取)"""import json as _jsonconfig_path = os.path.join(os.path.dirname(file), 'config.json')with open(config_path, 'r', encoding='utf-8') as f:config = _json.load(f)return jsonify({'success': True, 'models': config.get('available_models', [])})@app.route('/api/model/switch', methods=['POST'])def switch_model():"""切换模型"""data = request.jsonproject_id = data['project_id']model_config = data['model_config']project = project_mgr.load(project_id)if not project:return jsonify({'success': False, 'error': '项目不存在'}), 404project['model_config'] = model_configproject_mgr.save(project)return jsonify({'success': True, 'model_config': model_config})==================== 导出 API ====================@app.route('/api/export/markdown', methods=['POST'])def export_markdown():"""导出为Markdown"""data = request.jsonproject_id = data['project_id']chapter_range = data.get('chapter_range', None) # None表示全部project = project_mgr.load(project_id)if not project:return jsonify({'success': False, 'error': '项目不存在'}), 404content = _build_export_content(project, chapter_range, fmt='markdown')filename = f"{project['name']}.md"filepath = os.path.join(app.config['EXPORT_DIR'], filename)with open(filepath, 'w', encoding='utf-8') as f: f.write(content)return send_file(filepath, as_attachment=True, download_name=filename)@app.route('/api/export/txt', methods=['POST'])def export_txt():"""导出为纯文本"""data = request.jsonproject_id = data['project_id']chapter_range = data.get('chapter_range', None)project = project_mgr.load(project_id)if not project:return jsonify({'success': False, 'error': '项目不存在'}), 404content = _build_export_content(project, chapter_range, fmt='txt')filename = f"{project['name']}.txt"filepath = os.path.join(app.config['EXPORT_DIR'], filename)with open(filepath, 'w', encoding='utf-8') as f: f.write(content)return send_file(filepath, as_attachment=True, download_name=filename)def _build_export_content(project, chapter_range, fmt='markdown'):"""构建导出内容"""outline = project.get('outline', {})chapters = project.get('chapters', [])if chapter_range: chapters = [ch for ch in chapters if chapter_range[0] <= ch['chapter_num'] <= chapter_range[1]]if fmt == 'markdown': lines = [f"# {outline.get('title', project['name'])}\n\n"] for ch in sorted(chapters, key=lambda x: x['chapter_num']): # 从大纲获取章节标题 ch_title = f"第{ch['chapter_num']}章" for outline_ch in outline.get('chapters', []): if outline_ch['chapter_num'] == ch['chapter_num']: ch_title = f"第{ch['chapter_num']}章 {outline_ch.get('title', '')}" break lines.append(f"## {ch_title}\n\n") lines.append(f"{ch['content']}\n\n") return ''.join(lines)else: lines = [f"{outline.get('title', project['name'])}\n{'=' * 40}\n\n"] for ch in sorted(chapters, key=lambda x: x['chapter_num']): ch_title = f"第{ch['chapter_num']}章" for outline_ch in outline.get('chapters', []): if outline_ch['chapter_num'] == ch['chapter_num']: ch_title = f"第{ch['chapter_num']}章 {outline_ch.get('title', '')}" break lines.append(f"{ch_title}\n{'-' * 30}\n\n") lines.append(f"{ch['content']}\n\n") return ''.join(lines)if name == 'main':app.run(debug=True, port=5000)
"""AI 服务层 - 对接阿里百炼 DashScope API配置从 config.json 读取"""import osimport jsonimport mathimport requests从 config.json 加载配置_config_path = os.path.join(os.path.dirname(file), 'config.json')with open(_config_path, 'r', encoding='utf-8') as _f:CONFIG = json.load(_f)DASHSCOPE_API_KEY = CONFIG['dashscope_api_key']DASHSCOPE_API_URL = CONFIG['dashscope_api_url']class AIService:"""AI 生成服务"""# 提示词模板OUTLINE_PROMPT = """你是一位专业的小说策划编辑。请根据用户提供的题材、风格、字数要求,生成一份结构化的小说大纲。要求:输出纯JSON格式(不要包含```json标记)包含:title, genres, styles, theme, world_setting, core_conflict, characters_overview, chapters每个章节需包含:chapter_num, title, core_event, characters_involved, tone, foreshadowing_plant, foreshadowing_resolve, cause_from_previous, effect_to_next章节之间必须有因果逻辑链条标注每章的伏笔埋设和回收点用户输入:题材:{genres}风格:{styles}目标字数:{word_count}字核心设定:{core_setting}附加要求:{extra_requirements}"""CHARACTER_PROMPT = """你是一位专业的角色设计师。请根据小说大纲,为每个主要角色生成详细的人物卡片。要求:输出纯JSON格式(不要包含```json标记)输出格式:{{"characters": [...]}}每个角色包含:name, age, gender, appearance(hair/eyes/height/build/distinctive_features), personality(mbti/keywords), background, motivation, catchphrases, speech_style, abilities, weaknesses, relationships, arc(start/turning_point/end)角色之间必须有明确的关系定义角色设定不能与大纲中的世界观矛盾参考大纲:{outline_json}"""CHAPTER_PROMPT = """你是一位专业的小说作家。请严格按照以下约束生成第{chapter_num}章的内容。【强制约束 - 违反任何一条即为失败】人物描写必须与人物卡片完全一致,不得出现卡片中未定义的外貌/性格特征情节必须严格遵循大纲中本章的核心事件,不得偏离必须承接上一章的结尾场景,开头需自然衔接本章中埋设的伏笔必须在大纲标注的章节中回收角色说话风格必须与人物卡片中定义的一致不得引入大纲中未规划的新角色或新设定写作风格必须符合:{styles}【本章信息】章节大纲:{chapter_outline}涉及角色:{characters_involved}情绪基调:{tone}上一章结尾摘要:{previous_summary}需要埋设的伏笔:{foreshadowing_plant}需要回收的伏笔:{foreshadowing_resolve}【人物卡片】{character_cards}【全局设定】{world_setting}【输出要求】字数:{target_words}字左右在末尾用 === 分隔,附加本章摘要(200字以内)只输出小说正文和摘要,不要输出其他内容"""SEGMENT_PROMPT = """你是一位专业的小说作家。现在需要生成第{chapter_num}章的第{segment_num}/{total_segments}段。【分段上下文】本章总体规划:{chapter_outline}本段需要覆盖的内容:{segment_plan}前一段结尾内容:{previous_segment_ending}本段目标字数:{segment_words}字【强制约束】人物描写必须与人物卡片一致情节遵循大纲,不得偏离开头必须自然衔接前一段结尾角色说话风格与人物卡片一致写作风格:{styles}【人物卡片】{character_cards}【全局设定】{world_setting}【输出要求】只输出小说正文结尾需为下一段留出衔接点"""VALIDATE_PROMPT = """你是一位严格的小说审校编辑。请检查以下章节内容是否存在一致性问题。检查项:人物外貌描写是否与卡片一致人物性格表现是否与设定一致人物说话风格是否与卡片定义一致情节是否偏离大纲的核心事件是否与前文存在矛盾新出现的设定是否在世界观范围内伏笔埋设和回收是否按计划执行【待检查内容】{chapter_content}【大纲】{outline}【人物卡片】{character_cards}【前文摘要】{previous_summaries}输出纯JSON格式(不要```json标记):{{"passed": true/false, "score": 0-100, "issues": [{{"type": "类型", "severity": "严重/一般/轻微", "description": "描述", "location": "位置", "suggestion": "建议"}}]}}"""REPLAN_PROMPT = """你是一位专业的小说策划编辑。用户修改了第{modified_from}章及之后的大纲,请重新规划后续章节。【约束】已生成的前{last_generated}章内容不可修改,视为既定事实新的后续章节必须与已有内容逻辑一致已埋设但未回收的伏笔必须在新规划中安排回收人物的成长弧线需要重新适配【已有内容摘要】{existing_summaries}【未回收的伏笔】{unresolved_foreshadowing}【用户修改后的大纲要求】{modified_outline}请输出纯JSON格式的后续章节大纲(不要```json标记):{{"chapters": [...]}}"""def _call_api(self, prompt, model_config=None): """调用阿里百炼API(HTTP方式)""" config = model_config or {} model = config.get('model', CONFIG.get('default_model', 'qwen-plus')) temperature = config.get('temperature', CONFIG.get('default_temperature', 0.7)) top_p = config.get('top_p', CONFIG.get('default_top_p', 0.9)) max_tokens = config.get('max_tokens', CONFIG.get('default_max_tokens', 4000)) headers = { 'Authorization': f'Bearer {DASHSCOPE_API_KEY}', 'Content-Type': 'application/json' } payload = { 'model': model, 'input': { 'messages': [{'role': 'user', 'content': prompt}] }, 'parameters': { 'temperature': temperature, 'top_p': top_p, 'max_tokens': max_tokens, 'result_format': 'message' } } response = requests.post(DASHSCOPE_API_URL, headers=headers, json=payload, timeout=120) result = response.json() if response.status_code == 200 and 'output' in result: return result['output']['choices'][0]['message']['content'] else: error_msg = result.get('message', result.get('code', '未知错误')) raise Exception(f"API调用失败: {error_msg}")def _parse_json(self, text): """解析AI返回的JSON""" # 尝试去除可能的markdown代码块标记 text = text.strip() if text.startswith('```json'): text = text[7:] if text.startswith('```'): text = text[3:] if text.endswith('```'): text = text[:-3] text = text.strip() return json.loads(text)def generate_outline(self, genres, styles, word_count, core_setting, extra_requirements='', model_config=None): """生成大纲""" prompt = self.OUTLINE_PROMPT.format( genres='、'.join(genres), styles='、'.join(styles), word_count=word_count, core_setting=core_setting, extra_requirements=extra_requirements or '无' ) result = self._call_api(prompt, model_config) return self._parse_json(result)def generate_characters(self, outline, model_config=None): """生成人物卡片""" prompt = self.CHARACTER_PROMPT.format( outline_json=json.dumps(outline, ensure_ascii=False, indent=2) ) result = self._call_api(prompt, model_config) data = self._parse_json(result) return data.get('characters', data)def generate_chapter(self, chapter_num, chapter_outline, characters, world_setting, styles, previous_summary, target_words, max_per_segment=2000, model_config=None): """生成章节(自动判断是否分段)""" if target_words <= max_per_segment: # 单段生成 return self._generate_single_chapter( chapter_num, chapter_outline, characters, world_setting, styles, previous_summary, target_words, model_config ) else: # 分段生成 return self._generate_segmented_chapter( chapter_num, chapter_outline, characters, world_setting, styles, previous_summary, target_words, max_per_segment, model_config )def _generate_single_chapter(self, chapter_num, chapter_outline, characters, world_setting, styles, previous_summary, target_words, model_config): """单段生成章节""" # 过滤相关角色 involved = chapter_outline.get('characters_involved', []) related_chars = [c for c in characters if c.get('name') in involved] if not related_chars: related_chars = characters prompt = self.CHAPTER_PROMPT.format( chapter_num=chapter_num, styles='、'.join(styles), chapter_outline=json.dumps(chapter_outline, ensure_ascii=False), characters_involved='、'.join(involved), tone=chapter_outline.get('tone', ''), previous_summary=previous_summary or '(这是第一章)', foreshadowing_plant=json.dumps(chapter_outline.get('foreshadowing_plant', []), ensure_ascii=False), foreshadowing_resolve=json.dumps(chapter_outline.get('foreshadowing_resolve', []), ensure_ascii=False), character_cards=json.dumps(related_chars, ensure_ascii=False, indent=2), world_setting=world_setting, target_words=target_words ) result = self._call_api(prompt, model_config) # 分离正文和摘要 content, summary = self._split_content_summary(result) return { 'content': content, 'summary': summary, 'segments': [content], 'foreshadowing_status': { 'planted': chapter_outline.get('foreshadowing_plant', []), 'resolved': chapter_outline.get('foreshadowing_resolve', []) } }def _generate_segmented_chapter(self, chapter_num, chapter_outline, characters, world_setting, styles, previous_summary, target_words, max_per_segment, model_config): """分段生成章节""" total_segments = math.ceil(target_words / max_per_segment) segment_words = target_words // total_segments # 简单的段落计划分配 core_event = chapter_outline.get('core_event', '') segment_plans = self._create_segment_plans(core_event, total_segments) involved = chapter_outline.get('characters_involved', []) related_chars = [c for c in characters if c.get('name') in involved] if not related_chars: related_chars = characters segments = [] previous_ending = previous_summary or '(这是第一章开头)' for i in range(total_segments): prompt = self.SEGMENT_PROMPT.format( chapter_num=chapter_num, segment_num=i + 1, total_segments=total_segments, chapter_outline=json.dumps(chapter_outline, ensure_ascii=False), segment_plan=segment_plans[i], previous_segment_ending=previous_ending, segment_words=segment_words, styles='、'.join(styles), character_cards=json.dumps(related_chars, ensure_ascii=False, indent=2), world_setting=world_setting ) segment_content = self._call_api(prompt, model_config) segments.append(segment_content.strip()) # 取最后200字作为下一段的衔接 previous_ending = segment_content.strip()[-200:] # 拼接所有段落 full_content = '\n\n'.join(segments) # 生成本章摘要 summary = self._generate_summary(full_content, model_config) return { 'content': full_content, 'summary': summary, 'segments': segments, 'foreshadowing_status': { 'planted': chapter_outline.get('foreshadowing_plant', []), 'resolved': chapter_outline.get('foreshadowing_resolve', []) } }def _create_segment_plans(self, core_event, total_segments): """将核心事件拆分为段落计划""" if total_segments == 1: return [core_event] elif total_segments == 2: return [f"铺垫与展开:{core_event}的前半部分", f"高潮与收束:{core_event}的后半部分"] elif total_segments == 3: return [f"开端铺垫:{core_event}的起因", f"发展高潮:{core_event}的核心冲突", f"结局过渡:{core_event}的结果"] else: plans = [] for i in range(total_segments): progress = f"第{i+1}部分({int((i/total_segments)*100)}%-{int(((i+1)/total_segments)*100)}%)" plans.append(f"{progress}:{core_event}") return plansdef _split_content_summary(self, text): """分离正文和摘要""" if '===' in text: parts = text.split('===', 1) return parts[0].strip(), parts[1].strip() # 尝试其他分隔符 if '---' in text: parts = text.rsplit('---', 1) if len(parts[1].strip()) < 500: # 摘要不应太长 return parts[0].strip(), parts[1].strip() # 无分隔符,取最后200字作摘要 return text.strip(), text.strip()[-200:]def _generate_summary(self, content, model_config): """为内容生成摘要""" prompt = f"请为以下小说章节内容生成一个200字以内的摘要,概括核心情节和人物变化:\n\n{content[:3000]}" return self._call_api(prompt, model_config)def validate_chapter(self, chapter_content, outline, characters, previous_summaries, model_config=None): """一致性校验""" prompt = self.VALIDATE_PROMPT.format( chapter_content=chapter_content[:3000], outline=json.dumps(outline, ensure_ascii=False, indent=2)[:2000], character_cards=json.dumps(characters, ensure_ascii=False, indent=2)[:2000], previous_summaries='\n'.join(previous_summaries[-3:]) # 只取最近3章 ) result = self._call_api(prompt, model_config) return self._parse_json(result)def replan_outline(self, existing_summaries, unresolved_foreshadowing, modified_outline, modified_from_chapter, model_config=None): """续写:重新规划""" prompt = self.REPLAN_PROMPT.format( modified_from=modified_from_chapter, last_generated=modified_from_chapter - 1, existing_summaries=json.dumps(existing_summaries, ensure_ascii=False), unresolved_foreshadowing=json.dumps(unresolved_foreshadowing, ensure_ascii=False), modified_outline=json.dumps(modified_outline, ensure_ascii=False) ) result = self._call_api(prompt, model_config) return self._parse_json(result)def get_unresolved_foreshadowing(self, project, before_chapter): """获取未回收的伏笔""" planted = set() resolved = set() for ch in project.get('chapters', []): if ch['chapter_num'] < before_chapter: status = ch.get('foreshadowing_status', {}) for f in status.get('planted', []): planted.add(f) for f in status.get('resolved', []): resolved.add(f) return list(planted - resolved)