TL;DR —— 本文从招聘数据、技术栈演进和一线从业者状态出发,梳理了 Linux 运维岗位在 2026 年的真实处境。 不贩卖焦虑,不给模糊的"趋势预测",而是给出三个有据可查的技术方向和一个可执行的半年学习路线。 如果你正在这个行业里,或者打算进来,希望这篇文章能帮你把路看清楚一点。
一、一个运维老兵的问题
上个月跟一位做了快十年运维的朋友吃饭,他翻着招聘 App,突然问了一句:
"现在搜 Linux 运维,出来的 JD 有一半我看不太懂。"
他管过三千多台物理机,写过几百个自动化脚本,生产环境半夜崩了他看一眼日志大概就知道往哪查。但 JD 里写的那些——eBPF、Platform Engineering、FinOps、AI for Ops——他在过去两年几乎没碰过。
他的焦虑不是没来由的。招聘市场传递的信号比他预想的更直接。
这篇文章就是写给他的,也是写给所有在这个行业里、正在想"下一步怎么走"的人的。
二、先看几组实在的数据
招聘侧
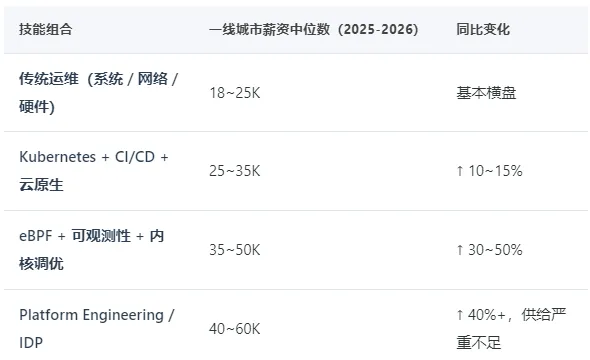
综合主流招聘平台和行业报告(LindedIn CN、Boss 直聘、猎聘 2025-2026 数据),标题带"运维"的岗位总量相比 2023 年下降约 15%。但标题带 SRE、Platform Engineering、可观测性工程师 的岗位,同期增长接近 3 倍。
岗位没有消失。它只是不再叫那个名字了。
薪资侧
溢价最猛的不是"更难的",而是"更稀缺的"。尤其是 Platform Engineering —— 市场上同时懂运维底层、又能用产品思维搭平台的人,一只手数得过来。
技术栈侧
CNCF 2026 年最新报告显示:
- eBPF 过去 18 个月采用率增长 200%,从"前沿探索"进入"生产标配"
- OpenTelemetry 成为可观测性事实标准,三大云厂商均已原生支持
- Platform Engineering 已落地:超过 60% 的中大型企业正在搭建或在用内部开发者平台(IDP)
三组数据放到一起,结论其实很明确:市场在用脚投票,告诉你要往哪个方向走。
三、不是运维不重要了,是"手工运维"不重要了
回顾过去十年运维的演进,可以看到一条非常清晰的线索:
核心规律只有一个:
运维的价值链在向上移动。"保证机器活着" → "保证服务可靠" → "保证交付效率" → "保证成本可控"。
每往上一层,需要的技能就多一个维度。停留在第一层的人,不是不努力,而是整个行业的自动化已经把那一层吃掉了。
十年前你的价值是"让服务器别宕机"。
五年前你的价值是"让业务别因为基础设施问题挂掉"。
现在你的价值是"让开发团队能自己搞定基础设施,而你负责设计那个'能让他们自己搞定'的平台"。
四、三个值得认真押注的方向
以下不是泛泛的趋势罗列。每个方向都附了具体的技术栈、切入点和一个可执行的路线。不需要全选——选一个你最感兴趣的,先扎进去半年。
方向一:eBPF + 可观测性 —— 从"装监控"到"写探针"
可观测性这件事,在 2026 年已经跟五年前完全不同了。装一套 Prometheus + Grafana 配几张 Dashboard 就能交差的日子过去了。
eBPF 为什么重要? 它让你在不改应用代码、不重启服务的前提下,观测内核层面的每一次系统调用、每一次网络包收发、每一次文件访问。这意味着排障从"猜"变成"看"。
举个例子:
# 以前排查偶发延迟尖刺: sar -u 1 10 # CPU 看起来还好 iostat -x 1 10 # IO 也没有异常 ss -s # 网络连接数正常 # ……全是间接指标,最后大概率不知道为什么# 现在用 bpftrace,一行脚本直接定位: bpftrace -e 'kprobe:vfs_read /pid == $TARGET_PID/ { @start[tid] = nsecs; } kretprobe:vfs_read /@start[tid]/ { @lat_us = hist((nsecs - @start[tid]) / 1000); delete(@start[tid]); }'# 延迟分布直方图直接拍脸上,哪个调用耗时多少一目了然。
具体切入点:
- 学会用
bpftrace 写一行脚本,解决一个当前环境里的真实问题——这比你读十篇文章都有用 - 深入了解 Cilium(网络)、Pixie(应用层)、Falco(安全),选一个跟你的场景最相关的
- Brendan Gregg 的博客和他 2025 年更新的 eBPF 资料,仍然是最好的入门材料→ brendangregg.com/ebpf.html
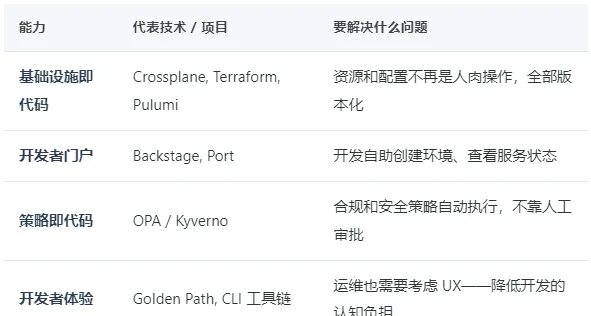
方向二:Platform Engineering —— 从"接需求"到"建平台"
如果你现在的日常是:
开发提工单 → 你手动建资源 → 开发问"好了吗" → 你说"再等一下" → 开发心想"为什么不能自助"
那你需要理解 Platform Engineering。
核心思路不复杂:你不再帮开发做运维,而是给开发做一个"他们自己点按钮就能搞定"的内部平台。 这需要几个关键能力:
这个方向最大的红利:现在市场上同时懂"运维底层"又懂"平台产品思维"的人非常少。不需要你是顶级程序员,只需要你愿意从"接需求"切换到"做产品"的思维模式。你先占位,就稀缺。
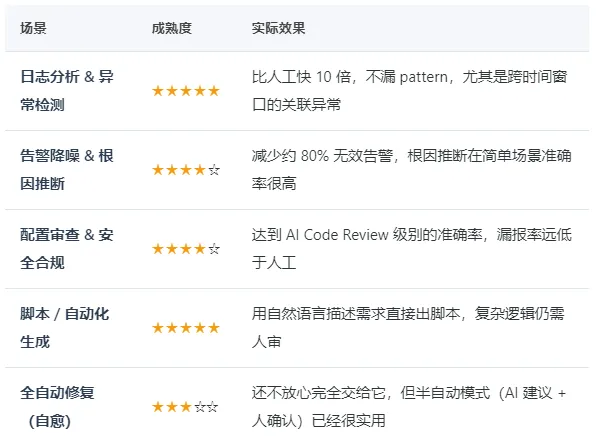
方向三:AI for Ops —— 从"被替代焦虑"到"让 AI 给你打工"
2026 年了还在问"AI 会不会取代运维"的人,大概率没真正把 AI 用到日常工作中。真正用过的人都在想:"怎么让 AI 干更多?"
以下是一张当前 AI 在运维中的真实可用性评估,既不过度吹捧,也不保守低估:
个人建议:不要把 AI 当成"竞争对手"来焦虑。当成杠杆。一个熟练使用 AI 辅助排障的运维,效率可以轻松顶 3 个不会用的。未来三年的职场护城河不是"我比 AI 强",而是——
五、一个不浮夸的半年学习路线
不需要三个方向全选。贪多是最大的敌人。选一个,半年时间只扎这一件事,足够把护城河挖出来。
一个提醒:不要同时追三个方向,那等于一个都没追。选一个你当前工作中最能直接用上的,先用真实场景把技能"焊"在身上,再考虑横向扩展。
六、说点实在的
Linux 运维这个岗位不会消失。
服务器还在,内核还在,系统调用还在,故障还会在周六凌晨三点发生。这些东西不会因为 AI 出现了就自动修好,也不会因为 Kubernetes 普及了就不再需要懂底层的人。
但 "只需要懂底层"的日子结束了。
从前,会装系统、调内核参数、写 shell 脚本差不多能吃大半辈子。现在除了这些,你还得至少会其中一样:
- 用代码思维解决运维问题——不是"写脚本",是"做系统"
- 用平台思维放大自己的价值——不是"服务开发",是"赋能开发"
- 用 AI 工具成倍提高自己的产出——不是"被替代",是"被武装"
运维的终点从来不是"机器正常",而是"业务成功"。
你离业务越近,不可替代性就越强。这个规律十年没变过,以后也不会变。
作者一个在 Linux 服务器旁边坐了多年的运维老兵。写过代码,搞过架构,排过凌晨三点的生产故障。现在主要研究怎么让运维这件事——不只是更自动化,而是更聪明。
如有不同意见,欢迎讨论。


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
