一、单选题(每题2分,共30分)
题号 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
答案 | B | C | B | C | A | D | A | B | A | C | B | D | B | D | B |
1、通讯卫星在通信⽹络系统中主要起到()
的作⽤ 。
A.信息过滤
B.信号中继
C.避免攻击
D.数据加密
【答案】B
【解析】卫星通信的主要目的是通过卫星发射的信号和地面接收的信号实现用户间的通信,属于中转信号功能,过滤、攻击和加密不是卫星的主要功能,故选B。
2、⼩杨想编写⼀个判断任意输⼊的整数N是否为素数的程序
,下⾯哪个⽅法不合适? (
)
A. 埃⽒筛法
B. 线性筛法
C. ⼆分答案
D. 枚举法
【答案】C
【解析】二分答案算法的核心思路是对需要求的答案进行二分,每次将答案范围减半直到找到目标答案为止;在求素数问题上,不存在二分的明显规律,因此使用二分法判断是否是素数不是一种合适的算法,本题选C。
3、内排序有不同的类别
,下⾯哪种排序算法和冒泡排序是同⼀类? (
)
A. 希尔排序
B. 快速排序
C. 堆排序
D. 插⼊排序
【答案】B
【解析】本题主要考查几种排序算法。冒泡排序和快速排序都是内排序中比较排序类算法,并且属于交换排序的类型。A选项希尔排序和D选项插入排序是属于比较排序类算法中的插入排序类型。而C选项堆排序是属于比较排序类算法中的选择排序类型。故本题选择B选项。
4、下⾯Python代码⽤于求斐波那契数列
,该数列第1 、2项为1,
以后各项均是前两项之和 。下⾯有关说法错误的是(
)。

A. fiboA( ) ⽤递归⽅式,fiboB() 循环⽅式
B. fiboA( ) 更加符合斐波那契数列的数学定义
,直观易于理解 ,⽽ fiboB()需要将数学定义转换为计算机程
序实现
C. fiboA( ) 不仅仅更加符合数学定义
,直观易于理解 ,且因代码量较少执⾏效率更⾼
D. fiboB( ) 虽然代码量有所增加
,但其执⾏效率更⾼
【答案】C
【解析】fiboA()借助函数自我调用求解数列,fiboB()借助简单循环方式求解数列,选项A正确;fiboA()直观体现了斐波那契数列中元素间的关系,选项B正确;递归算法代码执行效率与递归范围关系更密切,与代码量关系不大,选项C错误;fiboA()中的递归算法通常来说执行效率偏低,fiboB()只需要执行一层循环,效率更高,选项D正确;故此题选C。
5、下⾯Python代码以递归⽅式实现合并排序
,并假设 merge(left,right)函数能对有序(同样排序规则)的left 和right 排序
。横线处应填上代码是(
)。

A. mergeSort(listData[:Middle]),
mergeSort(listData[Middle:])
B. mergeSort(listData[:Middle-1]),
mergeSort(listData[Middle+1:])
C. mergeSort(listData[:Middle]),
mergeSort(listData[Middle+1:])
D. mergeSort(listData[:Middle-1]),
mergeSort(listData[Middle:])
【答案】A
【解析】使用递归方式实现合并排序时,整体思路为对数列进行左右两半的分段,再分别对左右两段进行合并排序;题目中Middle作为原列表元素位置的中点,在进行列表切片时,需要根据切片规则注意Middle处的值是否丢失或重复;B选项丢失了Middle-1及Middle,C选项丢失了Middle,D选项丢失了Middle-1,故此题选A。
6、阅读下⾯的Python代码
,执⾏后其输出是( )。

A. 1->120<===>2->120
B. 1->120<===>1->120
C. 1->120<===>1->2->3->4->5->120
D. 1->120<===>2->3->4->5->6->120
【答案】A
【解析】代码中fracA()和fracB()两个函数,均是求解N的阶乘的函数,并把N的阶乘作为返回值返回给函数;不同的是fracA()使用递推进行求解,fracB()使用递归求解;通过装饰器对两个函数功能的链接,第一个print输出的先是stepCount的值+5的阶乘的返回值;第二个print输出了中转符号;而第三个print输出由递归求解的5的阶乘值时,由于函数内部自我逐层调用与逐层返回,在装饰器捆绑的countIt()函数功能下,接连返回了每次递归的次数,最终输出阶乘结果120;由于使用global关键字生命stepCount为全局变量,所以第三个print输出过程中,该值从2开始一直到6。本题正确答案为D。
7、下⾯的Python⽤于对lstA排序,使得偶数在前奇数在后,横线处不应填⼊(
)。

A. key = not isEven
B. key = lambda x: isEven(x), reverse = True
C. key = isEven, reverse = True
D. key = lambda x: not isEven(x)
【答案】A
【解析】sort()方法中的key参数,可以接收自定义的函数名作为其参数值,也可以接收获取到的某个值来作为排序的依据。isEven()会将获得到的参数奇数返回0,偶数返回1;结合lambda函数,以此函数返回的0或1作为排序依据,那么lambda
x: is Even(x)会使奇数排列在偶数前(0<1);故选项B、C中设置的reverse翻转顺序,可以将偶数排列到奇数前,以此实现题目要求;选项D中对函数返回值类型做not否定,也能够是排序依据发生颠倒,所以D选项写法也能够实现效果;但A选项写法中,对函数名直接进行not否定,由于函数名作为key的参数是并非bool类型,会引起程序报错,所以本道题目选择A。
8、下⾯的Python代码⽤于排序sA 字符串中每个字符出现的次数(字频),
sA 字符串可能很长
,此处仅为⽰ 例 。排序要求是按字频降序
,如果字频相同则按字符的ASCII升序
,横线处应填⼊代码是( )。

A.
charCount, key = lambda x:(-x[1],x[0])
B.
charCount.items(), key = lambda x:(-x[1],ord(x[0]))
C.
charCount.items(), key = lambda x:(x[1],-ord(x[0]))
D. 触发异常
,不能对字典进⾏排序。
【答案】B
【解析】本道题通过字典存储信息,字典中元素的键表示字符,值表示该字符出现次数;通过遍历字符串,将每个获取到的字符作为键存入或访问,如果get()的返回值非None则把该值增加1,实现了计数的效果;排序依据需要借助字典中键和值设置条件,通过获取items(),获取到的第0项为字符,第1项为数值,所以-x[1]为大数的相反数,排列靠前实现按字频降序;ord(x[0])为字符则设置为第二排序依据,实现字符ASCII升序,故本题选B。
9、有关下⾯Python代码正确的是(
)。

A.
True True False
B.
False True False
C.
False False True
D. 触发异常
【答案】A
【解析】isEven和isOdd()两个函数,经运算后得到的均为布尔值,故type(isEven)和type(isOdd)类型相同,第一个输出结果为True;
isEven(10)当传入参数为10时,10%2==0条件成立,故返回True值给函数,第二个输出结果为True;isOdd(10)给出10作为参数时,10%2==1条件不成立,返回False给函数,第三个输出结果为False,故此题选择A选项。
10、下⾯的Python代码实现对list 的快速排序
,有关说法 ,错误的是( )。

A.
qSort(less) + qSort(greater) + [pivot]
B.
[pivot] + qSort(less) + qSort(greater)
C.
qSort(less) + [pivot] + qSort(greater)
D.
qSort(less) + pivot + qSort(greater)
【答案】C
【解析】快速排序的思路为,借助分治算法思想,将待排序列表分成三部分:参照值、比参照值小的、比参照值大的;代码中pivot选取列表第0项为参照值,然后遍历列表将小于等于参照值的数加入less列表,大于参照值的数加入greater列表;此时排序未完成,需要对less列表、greater列表再次调用qSort()函数排序,并将结果作为三部分列表返回给函数,顺序应为“小”+“参照”+“大”,故此题选C。
11、下⾯Python代码中的isPrimeA() 和isPrimeB() 都⽤于判断参数N是否素数
,有关其时间复杂度的正确说 法是( )。

A. isPrimeA( )的最坏时间复杂度是O(N/2),isPrimeB(
) 的最坏时间复杂度是O(logN),isPrimeA()优于isPrimeB()
B.
isPrimeA() 的最坏时间复杂度是O(N/2),isPrimeB(
) 的最坏时间复杂度是O(N½),isPrimeB()绝⼤多数情况下优于isPrimeA()
C. isPrimeA() 的最坏时间复杂度是O(N½),isPrimeB( ) 的最坏时间复杂度是O(N),isPrimeA( ) 优于isPrimeB(
)
D. isPrimeA() 的最坏时间复杂度是O(logN),isPrimeB( ) 的最坏时间复杂度是O(N),isPrimeA(
) 优于isPrimeB(
)
【答案】B
【解析】isPrimeA()函数中,for循环范围为从2到N//2+1,运行次数最大为N//2,时间复杂度为O(N/2);isPrimeB()函数中,for循环范围为从2到N的0.5次方+1,运行次数最大为N½,时间复杂度为O(N½);通常情况下,N½值要小于N/2值,所以isPrimeB()运行效率通常更高;故此题选B。
12、下⾯Python代码⽤于有序list 的二分查找,有关说法错误的是( )。

A. 代码采⽤⼆分法实现有序list的查找
B.代码采⽤分治算法实现有序list的查找
C. 代码采⽤递归⽅式实现有序list的查找
D.代码采⽤动态规划算法实现有序list的查找
【答案】D
【解析】二分查找算法借助于二分法思想,将查找范围不断二分减半,是一种快速的查找算法;在本题中给出的写法中,通过先将列表分为左、中、右三部分并依次查找,再将结果整合到一块返回,体现了分治算法中先分、再治、最后合的特点;而程序定义函数和函数自我调用,体现了递归算法的实现方式,故此题A、B、C选项皆正确;而D选项动态规划算法,更重要的是体现整体过程中每个步骤需要根据条件选取的决策,跟本题代码关联不大,故选择D。
13、在上题的算法中,其时间复杂度是(
)。
A.
O(N)
B.
O(logN)
C.
O(NlogN)
D.
O(N2)
【答案】B
【解析】二分查找算法每次会将查找范围缩小一半,假设有n个元素,查找进行了k次,查找到最后一个元素时找到目标,则有等式n/2^k=1,即2^k=n,k=log2N,所以时间复杂度为O(logN)。
14、下⾯的Python代码⽤于实现每个字符后紧跟随字符及其出现次数
,并对紧跟随字符排序,即出现次数最多排在前,形如:{ '中': [( '文', 1), ( '国', 2), ( '华', 2)]},此处S 仅是部分字符,可能很多,横线处应填⼊代码是( )。

A.
x[0]:x[1].items().sort(key = lambda x:x[1], reverse = True)
B.
x[0]:x[1].items().sort(key = lambda x:x[0], reverse = True)
C.
x[0]:sorted(x[1].items(), key = lambda x:-x[0])
D.
x[0]:sorted(x[1].items(), key = lambda x:-x[1])
【答案】B
【解析】本题思路及方法类似于选择题第8题,将字符及字符出现次数作为键值对存入字典后,再使用items()方法并结合字典推导式获取字典中的键与值,以-x[1]作为排序依据实现根据字频降序排列,再将x[0]的字符与排序后的元素值组合加入dictAfter字典,实现题目效果,此题选D。
15、有关下⾯Python代码的说法正确的是(
)。

A. 上述代码构成单向链表
B. 上述代码构成双向链表
C. 上述代码构成循环链表
D. 上述代码构成指针链表
【答案】B
【解析】根据代码显示,前置节点通过Next属性指向后置节点,后置节点又通过Prv属性指回前置节点,并且代码中三个节点并未构成循环,从概念上属于双向链表,正确答案为B。
二、判断题(每题2分,共20分)
题号 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
答案 | √ | √ | √ | × | × | √ | √ | √ | × | √ |
1、⼩杨想写⼀个程序来算出正整数N有多少个因数
,经过思考他写出了⼀个重复没有超过N/2次的循环就能够算出来了。 ( )
【答案】正确
【解析】在枚举过程中,如果找到某个数字x是N的因数,那么N/x即为N的另一个因数,所以重复次数可以不超过N/2。
2、同样的整数序列分别保存在单链表和双向链中
,这两种链表上的简单冒泡排序的复杂度相同。 (
)
【答案】正确
【解析】冒泡排序的特点为遍历待排序数列,依次进行数据间的两两比较,比较的方向是从前向后的,方向上都是单向比较,在两种链表结构种并没有效率差距,所以本题正确。
3、归并排序的时间复杂度是
。( )
【答案】正确
【解析】归并排序每次将序列拆分成等长的两部分,然后对这两部分进行排序,最后再将这两部分合并成一个有序序列。每次将序列拆分成两部分的时间复杂度为O(n/2),对两部分进行排序的时间复杂度为O(nlog(n)),因此总的时间复杂度为O(n) * O(nlog(n)) =
O(n*log(n))。
4、在Python中
,当对 list 类型进⾏in 运算查找元素是否存在时
,其查找通常采⽤⼆分法。 (
)
【答案】错误
【解析】python中使用关键字in判断列表内是否包含某元素时,大多数情况使用的是列表类型的index()方法对其中元素进行依次比对,并不是使用快速查找的二分法。
以下Python代码能以递归⽅式实现斐波那契数列
,该数列第1 、2项为1,
以后各项均是前两项之和 。(
)

【答案】错误
【解析】代码中fiboA()和fiboB()两个函数并没有定义,不是在Fibo()中调用函数本身,无法通过递归的方式求解N的前两项的值,故此题错误。
6、贪⼼算法可以达到局部最优
,但可能不是全局最优解 。(
)
【答案】正确
【解析】贪心算法的核心是,从局部最优上优先考虑,做出当前选择的最优解;算法关键在于贪心策略的选择,某个状态的选择不会影响以后的状态,贪心算法并不能保证对全局所有问题都得到最优解,本题描述正确。
7、如果⾃定已class已经定义了__lt__() 魔术⽅法
,则⾃动⽀持内置函数 sorted()。( )
【答案】正确
【解析】__lt__() 方法是一个比较方法,用于比较两个对象的大小。当使用 sorted() 函数对包含这个类的对象列表进行排序时,会根据 __lt__() 方法的结果进行排序。
8、插⼊排序有时⽐快速排序时间复杂度更低
。 ( )
【答案】正确
【解析】当待排序数列接近有序时,插入排序进行的操作更少,时间复杂度可能略低于快速排序。
9、下⾯的Python代码能实现⼗进制正整数N转换为⼋进制并输出。( )

【答案】错误
【解析】通过对8取余后的余数,应该是倒序排列后才是转换成的八进制数,题目中代码应改为输出rst[::-1]后才是正确的转换结果。
10、Python代码print(sorted(list(range(10)),
key = lambda x:x % 5)) 执⾏后将输出[0, 5, 1, 6, 2, 7, 3, 8, 4,
9] 。( )
【答案】正确
【解析】list(range(10))的结果是[0,1,2,3,4,5,6,7,8,9],相当于使用sorted()函数对该列表进行排序;lambda
x:
x%5作用为依次从列表中取出元素x,并以x%5作为依据进行排序;故0,1,2,3,4对5取余变,5,6,7,8,9对五取余分别为0,1,2,3,4,所以分别排在了原列表0,1,2,3,4后面,最终列表中元素排列顺序为[0,5,1,6,2,7,3,8,4,9],此题正确。
三、编程题(每题25分,共50分)
1、小杨的幸运数
问题描述
⼩杨认为,所有⼤于等于a的完全平⽅数都是他的超级幸运数。
⼩杨还认为,所有超级幸运数的倍数都是他的幸运数。⾃然地,⼩杨的所有超级幸运数也都是幸运数。
对于⼀个⾮幸运数,⼩杨规定,可以将它⼀直+1,直到它变成⼀个幸运数。我们把这个过程叫做幸运化。例如,如果a=4,那么4是最⼩的幸运数,⽽1不是,但我们可以连续对1做3次+1操作,使其变为4,所以我们可以说, 幸运化后的结果是 4。
幸运化后的结果是 4。
现在,⼩样给出N个数,请你⾸先判断它们是不是幸运数;接着,对于⾮幸运数,请你将它们幸运化。
输入描述
第⼀⾏2个正整数a,N。
接下来N⾏
,每⾏⼀个正整数x,表⽰需要判断(幸运化)
的数。
输出描述
输出N⾏,对于每个给定的x,如果它是幸运数,请输出lucky,否则请输出将其幸运化后的结果。
特别提醒
在常规程序中,输⼊
、输出时提供提⽰是好习惯。但在本场考试中,
由于系统限定,请不要在输⼊、输出中附带任何提⽰信息。
样例输入1

样例输出1

样例解释1
1虽然是完全平⽅数,但它⼩于a,
因此它并不是超级幸运数,也不是幸运数。将其进⾏3次+1操作后,最终得到幸运数4。
4是幸运数,因此直接输lucky。
5不是幸运数,将其进⾏3次+1操作后,最终得到幸运数8。
9是幸运数,因此直接输出lucky。
样例输入2
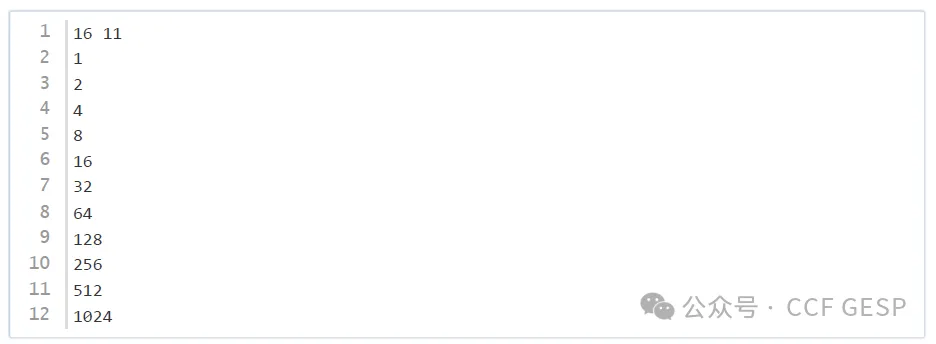
样例输出2
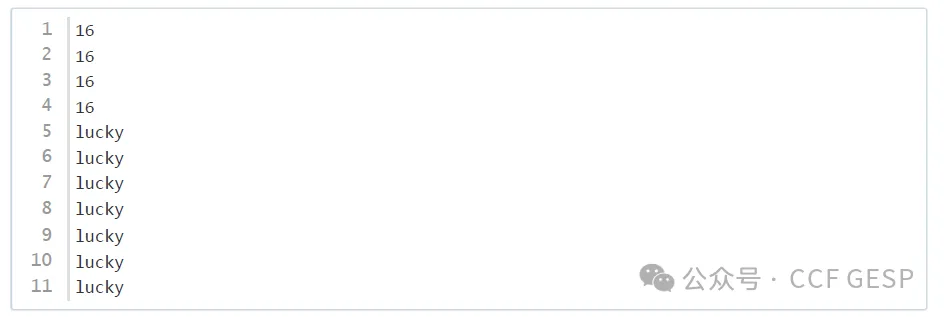
数据规模
对于30%的测试点,保证a,x≤100,N≤100。
对于60%的测试点,保证a,
x≤106。
对于所有测试点,保证a≤1,000,001;保证N≤2x
105,保证1≤x≤1,000,001。
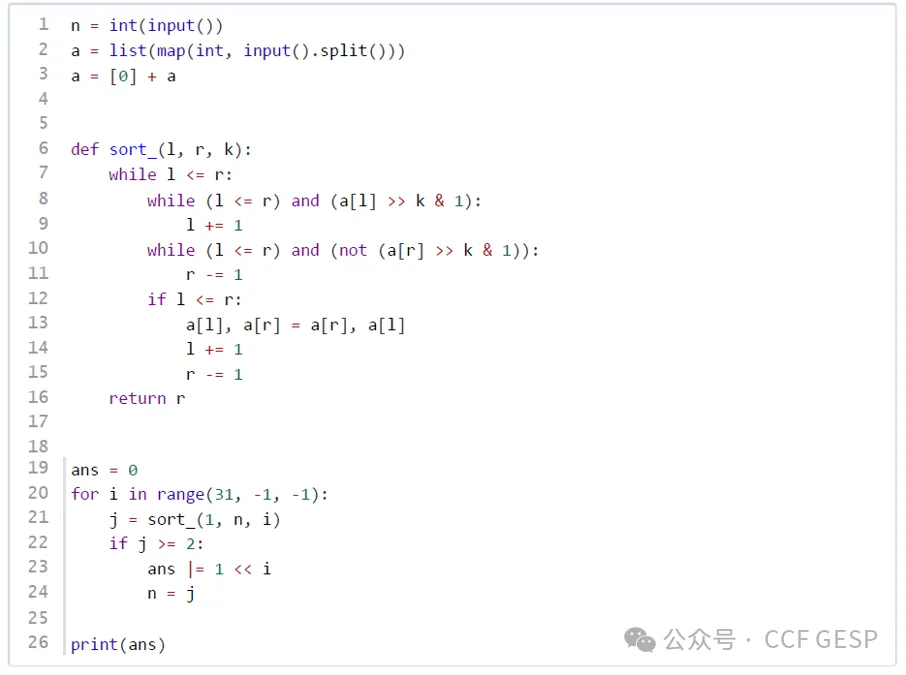
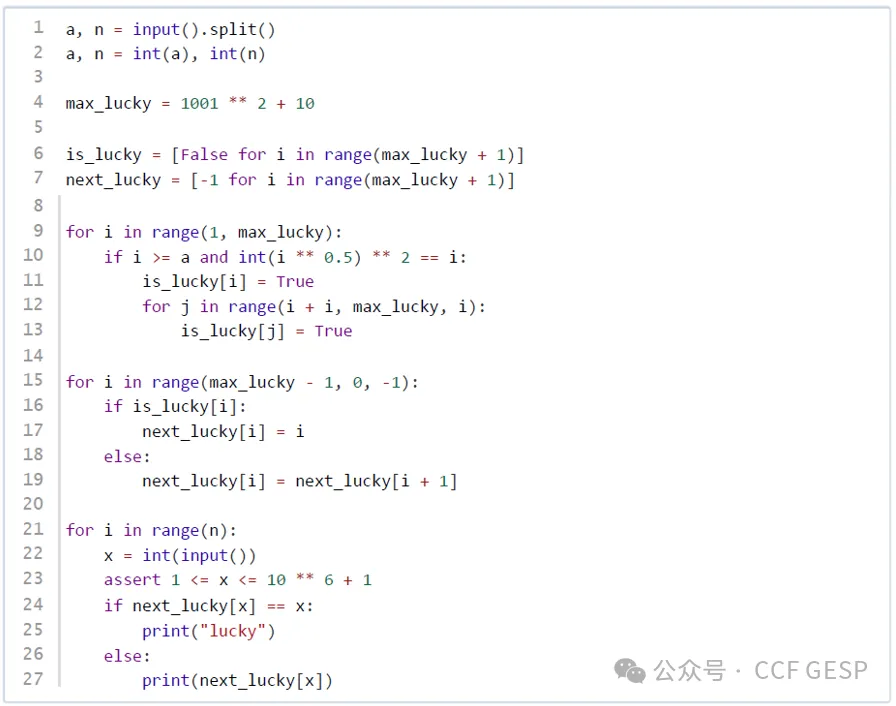
【题目大意】本题围绕“完全平方数”这一概念,求出大于要求数字的所有全部完全平方数作为超级幸运数字,并且根据这些完全平方数,求出范围内所有完全平方数的倍数;再将不属于完全平方数的数字进行自增操作,直到变为最近的超级幸运数为止。
【解题思路】
1.按要求输入数据并设定最大范围;
2.从a到最大数范围内进行遍历,将每个完全平方数记录到幸运数列表中;同时当获得完全平方数后,将该数字的所有倍数记录到幸运数列表中;
3.从大到小遍历“下一个幸运数”列表,将每个非幸运数的下一个幸运数设置为其后面的第一个幸运数;
4.最后,根据输入的整数 x,如果 x 是幸运数,则输出"lucky",否则输出其下一个非幸运数。
【参考程序】
2、烹饪问题
问题描述
有N种⾷材,编号从0⾄N
- 1,其中第i种⾷材的美味度为ai。
不同⾷材之间的组合可能产⽣奇妙的化学反应。具体来说,如果两种⾷材的美味度分别为x和y,那么它们的契合度为x
and y。
其中,and运算为按位与运算
,需要先将两个运算数转换为⼆进制,然后在⾼位补⾜0,再逐位进⾏与运算。例如,12与6的⼆进制表⽰分别为1100和0110,将它们逐位进⾏与运算,得到0100,转换为⼗进制得到4,因此12
and 6 = 4。在C++或Python中,可以直接使⽤&运算符表⽰与运算。
现在,请你找到契合度最⾼的两种⾷材,并输出它们的契合度。
输入描述
第⼀⾏⼀个整数N,表⽰⾷材的种数。
接下来⼀⾏N个⽤空格隔开的整数,依次为a0,…
,aN-1,表⽰各种⾷材的美味度。
输出描述
输出一行一个整数,表示最高的契合度。
特别提醒
在常规程序中,输入、输出时提供提示是好习惯。但在本场考试中,由于系统限定,请不要在输入、输出中附带任何提示信息。
样例输入1

样例输出1

样例解释1
可以编号为1 , 2 的⾷材之间的契合度为2 and 3 =2 ,是所有⾷材两两之间最⾼的契合度。
样例输入2

样例输出2

样例解释1
可以编号为3
 4 的⾷材之间的契合度为10 and 13 = 8,是所有⾷材两两之间最⾼的契合度。
4 的⾷材之间的契合度为10 and 13 = 8,是所有⾷材两两之间最⾼的契合度。
数据规模
对于40%的测试点
,保证N ≤ 1 , 000;
对于所有测试点
,保证 N ≤ 106,0
≤ ai≤ 2,147,483,647。。
【题目大意】本题围绕数字间的位运算操作,根据给出的数据,求出N个数之中,两个数字间按位与的最大值。
【解题思路】
1.双层循环嵌套可以列举所有数字搭配,并进行位运算后记录最大值;但当数据量超大时,会导致程序超时,需要进行优化;
2.根据ai≤2,147,483,647(2³¹-1),最多31位二进制,从最高位开始枚举,时间复杂度O(31N),可以解决所有数据且不超时;
3.记录每位下的最大值作为答案,并枚举进行位运算后,找到当前位数下满足条件的数值个数;个数小于2时,答案变量清零并进行下一次枚举。
【参考程序】