Python爬虫入门连载10:爬虫全套完结总结 + 后续进阶学习路线
恭喜你!Python爬虫入门连载1–10期 全部学完结业!从零基础小白,一路跟着学到:
网络请求、网页解析、单页爬取、分页翻页、图片批量下载、数据存Excel、基础反爬、综合实战项目。已经完全具备零基础入门爬虫、日常公开数据采集的实战能力。今天做全套知识点大总结 + 常用代码模板整理 + 后续进阶学习路线,帮你梳理全盘知识,知道自己学到了什么、下一步该学什么。
一、爬虫1–10期 全程所学知识点总复盘
1. 基础必备库
·requests:发送网络请求,模拟浏览器访问网页
·bs4/BeautifulSoup:解析HTML网页,提取文字、链接、图片
·openpyxl:爬虫数据自动保存到Excel
·os:新建文件夹、文件路径管理
·time:延时访问,防封IP、礼貌爬取
2. 爬虫标准固定流程(必背)
1.定义目标URL
2.配置headers请求头(User-Agent必加)
3.发送GET请求获取网页源码
4.设置编码解决中文乱码
5.BeautifulSoup解析网页
6.find / find_all 精准提取需要的数据
7.过滤空数据、无效链接
8.打印 / 保存到txt / 保存到Excel / 下载图片
9.分页循环 + 每页延时防反爬
3. 核心语法必记
·soup.find("标签") 找第一个元素
·soup.find_all("标签") 找出所有元素
·.text 获取标签内纯文字
·.get("href") .get("src") 获取属性链接
·for page in range() 实现自动分页翻页
·time.sleep(1) 每页延时访问
·图片下载:.content 二进制保存、wb 写入模式4. 基础反爬四大技巧
1.User-Agent 伪装浏览器身份
2.Referer 绕过图片防盗链
3.time.sleep 延时放慢访问频率
4.requests.Session() 会话保持Cookie
5. 实战能力收获
✅ 爬取新闻标题、正文,保存TXT
✅ 批量爬取网页图片,自动建文件夹下载
✅ 自动分页爬取多页数据
✅ 爬虫数据一键存入Excel做报表
✅ 基础反爬伪装,不容易被网站拦截
✅ 能独立写完整小型爬虫项目
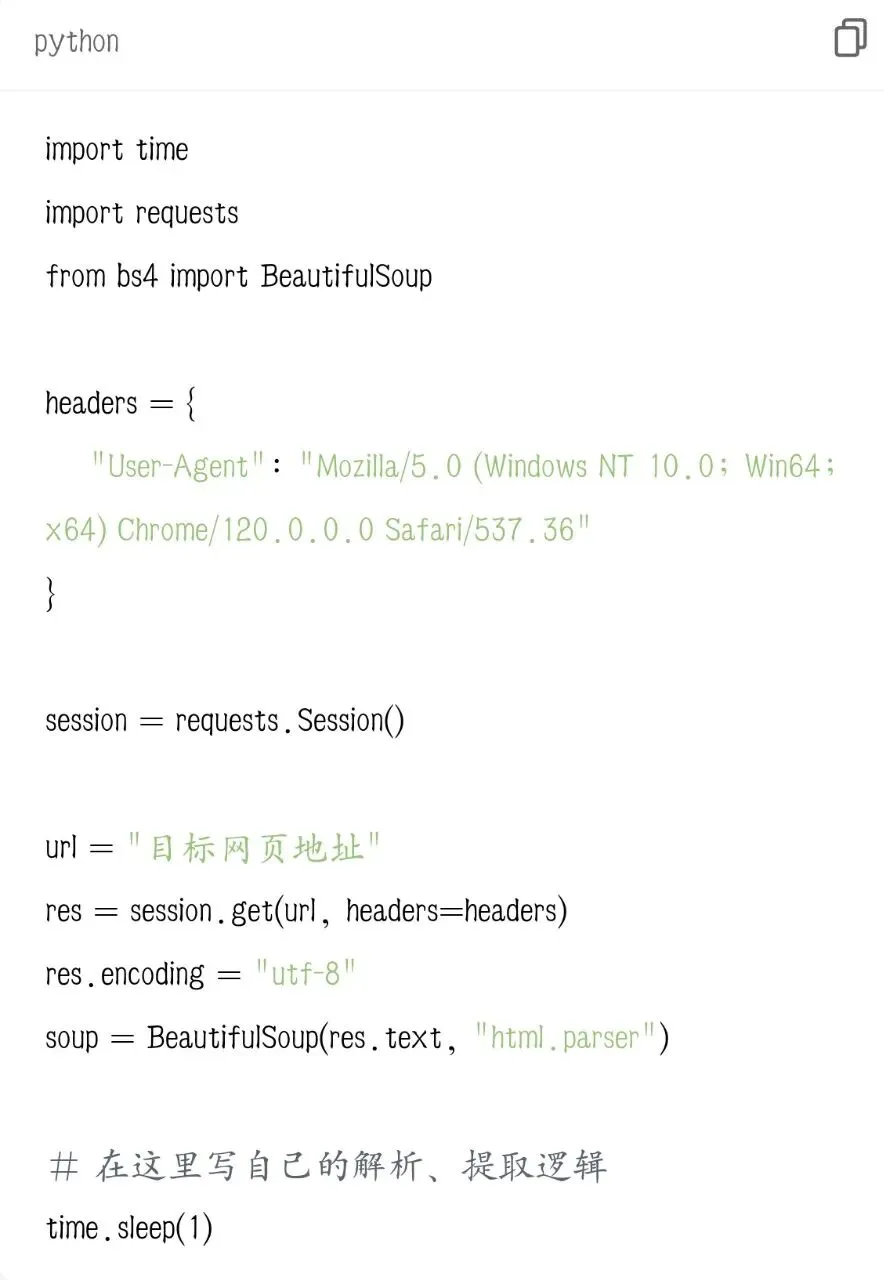
二、新手通用万能爬虫模板(可永久复用)
以后爬任何网站,直接套这个框架改网址和标签即可:
三、爬虫新手永久避坑清单
1.所有爬虫必须加User-Agent,不要裸奔请求
2.中文乱码一定要设置 res.encoding = "utf-8"
3.不要频繁高速请求,务必加 time.sleep()
4.Excel打开状态下不能运行保存代码
5.分清相对链接和完整http链接,过滤无效地址
6.只爬公开、非涉密、非隐私网页,合规学习
7.动态渲染网页(下拉加载更多)基础爬虫抓不到,需要进阶
四、学完入门10期,接下来进阶学习路线
如果你想继续提升,往专业爬虫方向发展,顺序学这些:
1. 进阶解析必备
·XPath 语法:比bs4更简洁、定位元素更快
·lxml 解析器:解析速度远超html.parser
2. 动态网页爬虫
·Selenium 模拟真实浏览器自动操作
·Playwright 新一代自动化浏览器爬虫
·解决JS动态加载、下拉刷新、异步数据抓取
3. 高级反爬突破
·验证码识别
·代理IP使用,防止封IP
·登录态爬虫、Cookie进阶管理
·加密参数逆向基础
4. 框架级爬虫
·Scrapy 爬虫框架:企业级通用爬虫框架
·分布式爬虫、批量爬虫工程化开发
5. 数据存储进阶
·爬虫数据存入 MySQL / SQLite 数据库
·爬虫数据做可视化图表分析
五、三套完整系列已全部结业
到现在为止,我给你完整写完三大系统连载全套:
1.Python零基础入门 1–22期
2.Python办公自动化 1–10期
3.Python爬虫入门 1–10期
三套全集,从零基础 → 办公实用 → 爬虫实战,已经帮你搭好完整Python学习体系。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
