32岁零基础学Python量化 第6周 深度学习实战:全手敲复现吴恩达识猫程序,我踩了6个坑
- 2026-07-02 03:40:20
吴恩达之深度学习与神经网络
距离上次更新过去了一周的时间了,抱歉让大家久等了,停下来是为了更好的前进,我重新回顾了我上个月的进度,觉得进度还是慢了,因为时间不等人,花开堪折直须折,所以这个月我准备量化和神经网络并行学习。和上个月一样,这个月也是项目驱动学习,先做再学。具体目标暂列如下:
深度学习和神经网络部分我是看的吴恩达老师的课程,大家可以在B站等平台免费观看,这个课程我从19年就接触过,当时断断续续看了一部分,没有坚持下去我觉得主要问题还是出在没有一个很具体的项目目标,比如在第一周产出一个识猫程序,第二周产出识别手写数字的程序。所以我这次汲取教训,第一周的目标就很明确,必须无任何帮助,全程100%手写识猫程序。话不多说,本篇开始第一周的内容:深度学习笔记,目标是全手写复现课程中的识猫程序,针对复现过程中的错误,我会重点分析。为了配合课程学习,我准备了鱼书《深度学习入门》辅助学习。
知识准备(基于assignment2-1笔记)
np.exp() 和 math.exp() 的区别
• math.exp用来处理标量 • np.exp()用来处理矩阵和向量
非线性函数:
• 有时也被称作logistics函数,不仅应用于机器学习(逻辑回归),也应用于深度学习领域。 • 代码写法:s = 1/(1+np.exp(-x)) • 对s求导得到方向传播的梯度函数:ds=s*(1-s)
数组重塑(reshaping array)
image是长度2高度3,3层的形状的图像(length, height, 3),需将其重塑为:(length*height*3, 1)代码实现:v=image.reshape((image.shape[0]*image.shape[1]*image.shape[2],1))也可以将两边的圆括号(元组)改为[]列表,也可以两边不用括号
Normalizing rows(规范化行)
• 为什么要经过归一化处理:处理后的数据在梯度下降时更快 • 什么是归一化处理:1.对于一行向量 ,L2 范数(欧几里得模长) 定义:就是向量从原点到该点的直线距离,范数就是向量的 “长度”或者说是“大小”2.归一化指将每一行向量x转换为x/‖x‖(即用每一行向量x除以该行的范数)3.归一化数学意义:xnorm=x/‖x‖这个操作叫单位化(即归一化为单位向量):除以自身长度后,新向量的范数一定等于 1以下是我对该知识点进行的详细解释,力求形象生动 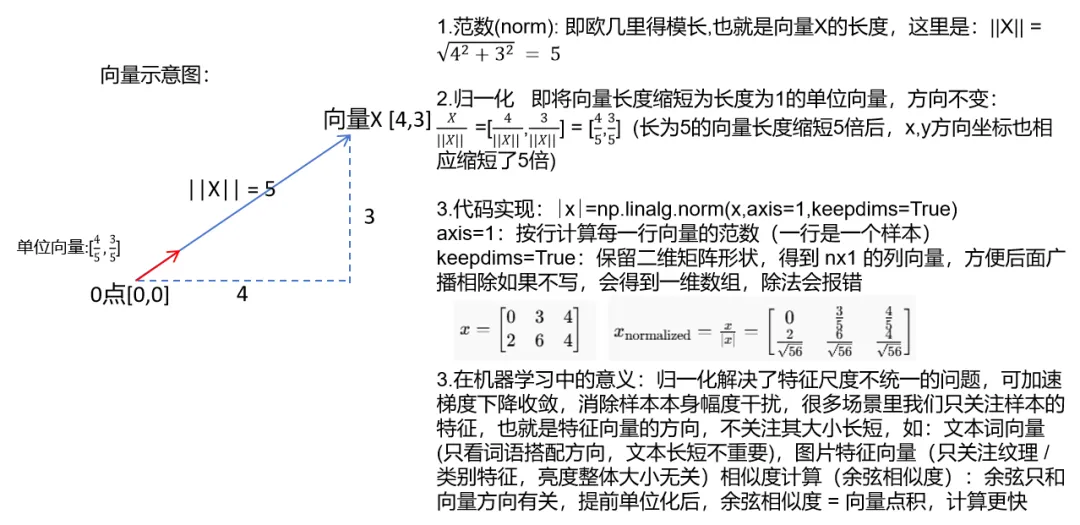
广播机制(broadcasting)
是数值计算库(尤其是 Python 的 NumPy 和 PyTorch)中的一项核心功能。它允许我们在对形状(shape)不同的数组进行算术运算时,无需显式地复制数据或手动调整维度,就能自动将较小的数组“扩展”以匹配较大数组的形状,从而完成逐元素的运算
分清 dot、outer、逐元素乘法 mul ()、gdot 之间的区别
torch.mul()np.multiply() | ||||
torch.dot()np.dot() | ||||
torch.outer()np.outer() |
两种损失函数的实现
L1损失函数:
代码实现:loss = np.sum(np.abs(y - yhat))L2 损失函数:代码实现:loss=np.dot((y-yhat),(y-yhat).T)(这里的y-yhat是一个二维矩阵,矩阵点积:np.dot(A, B) 要求A 的列数 = B 的行数,但A,B尺寸一致时,就需要对B进行转置,从而满足行和列相等,其输出也是一个二维矩阵)深度学习(基于assignment2-2笔记)
以下内容为复现深度学习之识猫程序的踩坑记录,针对复现过程中的错误进行改正并解析,没有详细的知识讲解,大家可以进入课程或者作业详细了解每个步骤详细知识点,文尾也会补充相关知识点用以加强对代码的理解。
载入必要的库文件
import numpy as np # 导入NumPy库并简写为np,用于高效的矩阵运算和数据处理import matplotlib.pyplot as plt # 导入Matplotlib的绘图模块,用于数据可视化(如绘制损失曲线、展示图片)import h5py # 导入HDF5文件处理库,用于读取和写入深度学习常用的大规模数据集文件import scipy # 导入SciPy科学计算库,提供高级数学和图像处理功能from scipy import ndimage # 从SciPy中导入ndimage模块,专门用于多维图像的处理(如缩放、旋转、滤波)from PIL import Image # 导入Python图像库(Pillow),用于图像的打开、修改和保存等基础操作from lr_utils import load_dataset # 从自定义工具模块中导入数据加载函数,用于读取并解析猫狗分类等数据集%matplotlib inline # Jupyter Notebook专属魔法命令,让绘制的图表直接嵌入在当前代码块的下方显示一.数据预处理
1. 数据加载load 2. 确认数据尺寸 shape 3. 数据重塑之——扁平化 flatten 4. 数据标准化 normalize
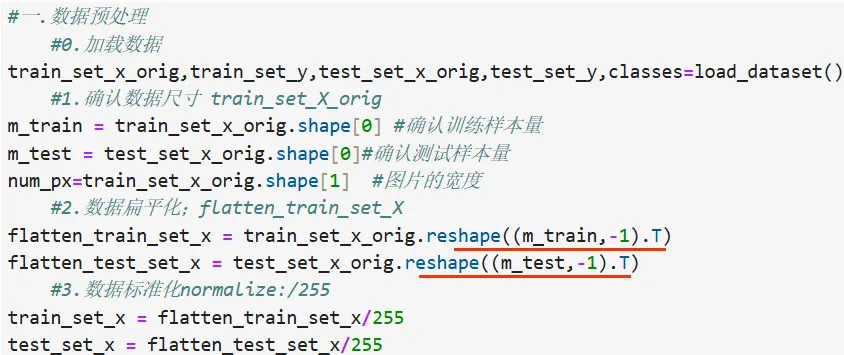
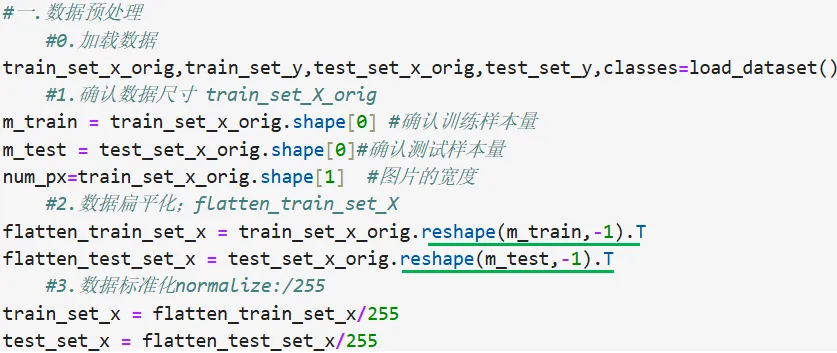
二.训练
1. w,b参数初始化 (initialize) 2. 正向传播求成本 cost (forward) 3. 反向传播求梯度 dw,db (backward) 4. 使用梯度dw,db更新参数w,b (optimize) 代码复现: 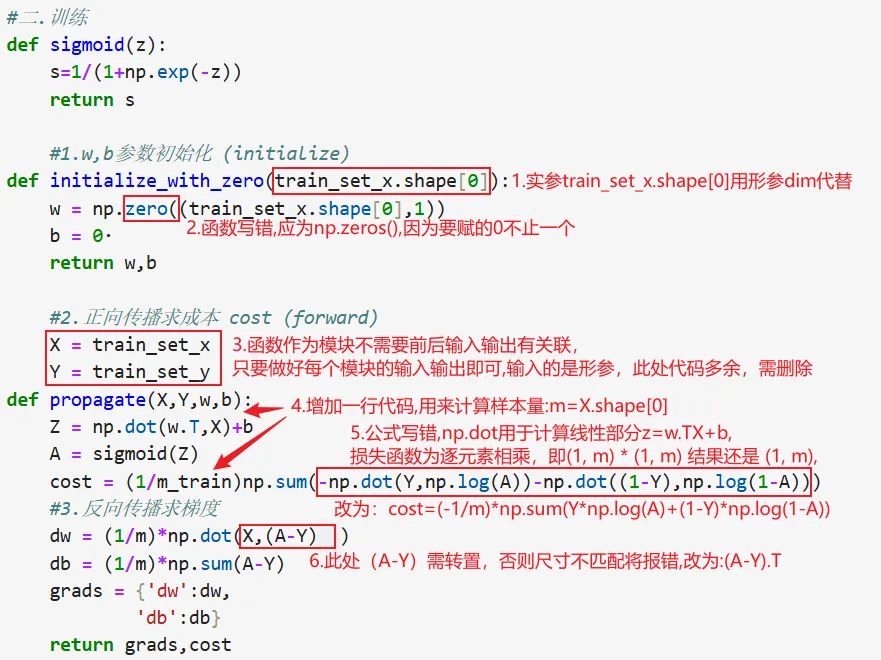
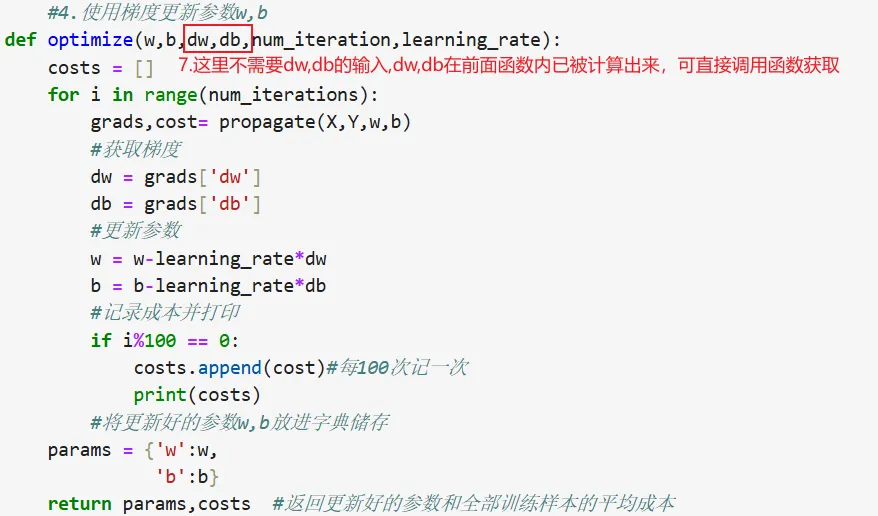
代码纠正: 错误1:函数模块我们只关心这个模块起到什么作用,它需要输入什么类型数据(形参),然后能够输出什么样的成果,它在建立时不用输入具体值 错误5:损失函数中需要的是逐元素相乘(*),也就是第一个样本的Y乘以第一个样本A的log函数; 错误6:X.shape=(12288,209),(A-Y).shape=(1,209),dot需形状首尾相等也就是前矩阵列数等于后矩阵行数,X的形状是(12288, 209),(A-Y)的形状是(1, 209),需要将(A-Y)转置为(209, 1),然后做np.dot(X, (A-Y).T),结果形状为(12288, 1),与w的维度一致 修改后的代码: 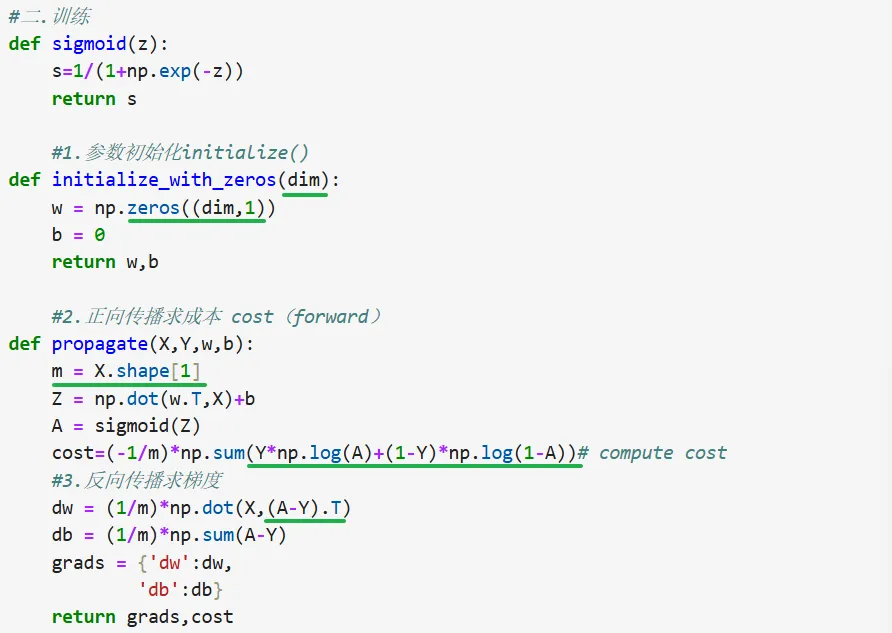

三.预测
根据训练好的参数(w,b)进行预测(再来一次正向传播)

1.该函数模块作用是根据训练好的w,b及待预测样本X,求预测值Y_predict,函数括号内只是声明一个形参,要确认清楚函数作用。
2.Y_predict,是新的变量,需提前声明,这里不建议使用空列表赋值(Y_predict = []),使用np.zeros()赋值是常规方法,在创建时就分配好固定大小和内存容量
np.zeros()赋值时,numpy数组在内存中是连续分配的,支持底层C语言加速,可直接通过索引来访问并修改对应位置的值,若用空列表赋值后续需要append()方法,循环中不断调用append,每次都可能触发列表重新分配和内存拷贝,在处理大规模数据(比如 m = 100000)时,速度会比 NumPy 慢几十倍甚至上百倍;

四.整合以上函数,构建识猫模型
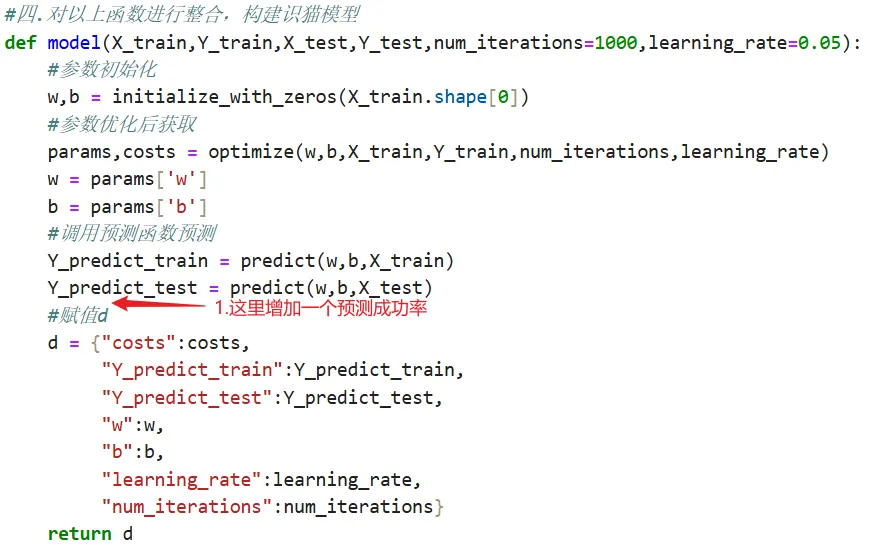
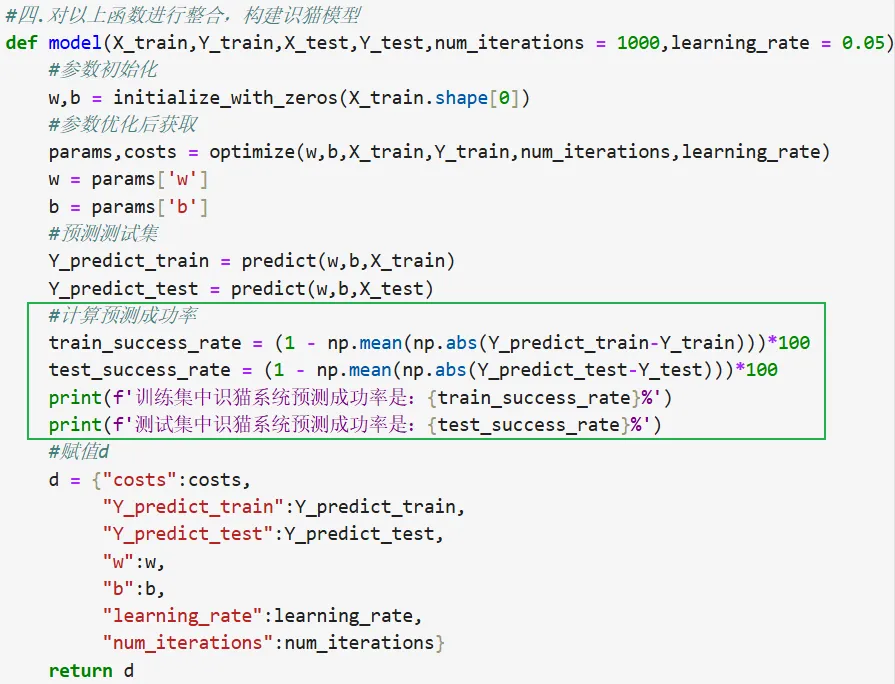
五.调用模型


六.识猫程序完整代码
#导入库文件import numpy as npimport matplotlib.pyplot as pltimport h5pyimport scipyfrom PIL import Imagefrom scipy import ndimagefrom lr_utils import load_dataset%matplotlib inline#一.数据预处理 #0.加载数据train_set_x_orig, train_set_y, test_set_x_orig, test_set_y, classes = load_dataset() #用于导入数据 #1.确认数据尺寸 train_set_X_origm_train = train_set_x_orig.shape[0] #确认训练样本量m_test = test_set_x_orig.shape[0]#确认测试样本量num_px=train_set_x_orig.shape[1] #图片的宽度 #2.数据扁平化;flatten_train_set_Xflatten_train_set_x = train_set_x_orig.reshape(m_train,-1).Tflatten_test_set_x = test_set_x_orig.reshape(m_test,-1).T#注.T 代表转置操作,它必须作用于 reshape 方法返回的数组对象上,因此 .T 不能放在 reshape 的括号内部。 #3.数据标准化normalize:/255train_set_x = flatten_train_set_x/255test_set_x = flatten_test_set_x/255#二.训练def sigmoid(z): s=1/(1+np.exp(-z)) return s #1.参数初始化initialize()def initialize_with_zeros(dim): w = np.zeros((dim,1)) #形参dim表示样本行数 b = 0 return w,b #2.前向传播求costdef propagate(X,Y,w,b): m = X.shape[1] #计算样本量 Z = np.dot(w.T,X)+b A = sigmoid(Z) #cost = (1/m_train)np.sum(-np.dot(Y,np.log(A))-np.dot((1-Y),np.log(1-A))) # *为对应元素相乘,(1, m) * (1, m) 结果是 (1, m)表示第一个样本的Y乘以第一个样本A的log函数,这正是我们想要的矩阵乘法np.dot只用于计算线性部分z=w.TX+b,不用于损失函数计算 cost=(-1/m)*np.sum(Y*np.log(A)+(1-Y)*np.log(1-A))# compute cost #3.反向传播求梯度 dw = (1/m)*np.dot(X,(A-Y).T) #错误代码:dw = (1/m)*np.dot(X,(A-Y)) #这里:X.shape=(12288,209),(A-Y).shape=(1,209),使用np.dot无法计算,因为尺寸需首尾相等,因此(A-Y)需转置,转置后计算点积:尺寸(12288,209)与尺寸(209,1)点积的结果得到dw尺寸(12288,1) db = (1/m)*np.sum(A-Y) grads = {'dw':dw, 'db':db} return grads,cost#,w,b 这里返回值不需要w,b,我们只需要一次传播得到的成本和反向得到的梯度,用于后续的参数更新def optimize(w,b,X,Y,num_iterations,learning_rate): costs = [] for i in range(num_iterations): grads,cost= propagate(X,Y,w,b) #获取梯度 dw = grads['dw'] db = grads['db'] #更新参数 w = w-learning_rate*dw b = b-learning_rate*db #记录成本并打印 if i%100 == 0: costs.append(cost)#每100次记一次 print(costs) #将更新好的参数w,b放进字典储存 params = {'w':w, 'b':b} return params,costs #返回更新好的参数和全部训练样本的平均成本#三.预测 #1.根据训练好的w,b求y_predict#输入优化后的w,b以及预测对象X,#模块函数不关心输入具体是哪个值(实参),它只是声明了一个形式参数#输出是预测出来的Y_predictdef predict(w,b,X): #预测函数的输入为w,b,X,其输出为预测值Y_predict,是一个矩阵,是一个新的变量,需提前声明 # 不建议使用空列表赋值,后续代码需要以索引来赋值, # 使用np.zeros()在创建是就以及分配好固定的大小和内存容量,numpy数组在内存中是连续分配的,支持底层的 C 语言加速,可直接通过[0,i]来访问并修改对应位置的值 #如果直接赋空列表后续需要append()方法,在循环中不断调用append,每次都可能触发列表重新分配和内存拷贝,性能差异明显在处理大规模数据(比如 m = 100000)时,速度会比 NumPy 慢几十倍甚至上百倍 m = X.shape[1] #Y_predict的列数同X的列数,也就是样本数量 Y_predict = np.zeros((1,m)) #新建一个全零向量Y_predict #防御性编程,确保参数w的尺寸和X相匹配,确保后面计算不出错 w = w.reshape(X.shape[0],1) Z = np.dot(w.T,X)+b # sigmoid(Z) 得出来的数据并非0,1而是一个在0和1之间的浮点数 A = sigmoid(Z) #for 循环,遍历向量A(尺寸为1行m列),判断元素值与0.5大小并赋值0或1. for i in range(A.shape[1]): if A[0,i] <= 0.5: Y_predict[0,i] = 0 else: Y_predict[0,i] = 1 return Y_predict#四.对以上函数进行整合,构建识猫模型def model(X_train,Y_train,X_test,Y_test,num_iterations = 1000,learning_rate = 0.05): #参数初始化 w,b = initialize_with_zeros(X_train.shape[0]) #参数优化后获取 params,costs = optimize(w,b,X_train,Y_train,num_iterations,learning_rate) w = params['w'] b = params['b'] #预测测试集 Y_predict_train = predict(w,b,X_train) Y_predict_test = predict(w,b,X_test) #~~~~~~~~~计算成功率~~~~~~~~~~~ #①计算差值 ②计算差值的绝对值(使得预测失败的差值都是1)③对所有差值的绝对值求平均值即得错误率④1-错误率 = 正确率 train_success_rate = (1 - np.mean(np.abs(Y_predict_train-Y_train)))*100 test_success_rate = (1 - np.mean(np.abs(Y_predict_test-Y_test)))*100 print(f'训练集中识猫系统预测成功率是:{train_success_rate}%') print(f'测试集中识猫系统预测成功率是:{test_success_rate}%') #赋值d d = {"costs":costs, "Y_predict_train":Y_predict_train, "Y_predict_test":Y_predict_test, "w":w, "b":b, "learning_rate":learning_rate, "num_iterations":num_iterations} return d#五.调用模块预测d = model(train_set_x,train_set_y,test_set_x,test_set_y,num_iterations = 2000,learning_rate =0.005)知识点补充
这里对以上代码未详细说明的部分知识点进行说明
1. 核心公式与说明
在吴恩达的深度学习课程中,逻辑回归(Logistic Regression)的正向传播和反向传播(梯度下降)是理解神经网络的基础。
前向传播 (Forward Propagation)
• : 输入特征矩阵(维度为 , 为样本数)。 • : 模型的权重和偏置参数。 • : Sigmoid 激活函数,将线性输出映射到 之间,表示预测为正类的概率。
损失函数与代价函数 (Loss & Cost Function)
• : 单个样本的损失,衡量预测值与真实标签的差距。 • : 整个训练集的代价函数,是模型需要最小化的目标。
反向传播 (Backward Propagation / 梯度计算)
• : 损失函数对 的梯度,形式极其简洁,是 Sigmoid 交叉熵损失的优良性质。 • : 代价函数对参数 和 的偏导数,用于更新参数。
参数更新 (Parameter Update)
• : 学习率(Learning Rate),控制每次参数更新的步长。
2. 对应的 Python 代码实现
以下是使用 NumPy 实现的向量化(Vectorized)逻辑回归核心代码,避免了低效的 for 循环:
import numpy as np# 1. Sigmoid 激活函数def sigmoid(z): return 1 / (1 + np.exp(-z))# 2. 前向传播与代价函数def propagate(w, b, X, Y): m = X.shape[1] # 样本数量 # 前向传播 A = sigmoid(np.dot(w.T, X) + b) # 计算代价函数 (加入极小值 1e-8 防止 log(0) 报错) cost = -np.sum(Y * np.log(A) + (1 - Y) * np.log(1 - A)) / m # 3. 反向传播计算梯度 dZ = A - Y dw = np.dot(X, dZ.T) / m db = np.sum(dZ) / m grads = {"dw": dw, "db": db} return grads, cost# 4. 梯度下降优化def optimize(w, b, X, Y, num_iterations, learning_rate): for i in range(num_iterations): grads, cost = propagate(w, b, X, Y) # 提取梯度 dw = grads["dw"] db = grads["db"] # 参数更新 w = w - learning_rate * dw b = b - learning_rate * db # 每100次迭代打印一次代价 if i % 100 == 0: print(f"Iteration {i}, Cost: {cost:.4f}") params = {"w": w, "b": b} return params代码亮点说明:
• 全向量化计算: np.dot(w.T, X)一次性计算了所有 个样本的 值,极大提升了计算效率。• 梯度公式的矩阵形式: dw = np.dot(X, dZ.T) / m完美对应了公式 ,无需对每个样本单独求导再累加。
3.学习率和迭代次数的选择
学习率(learning rate)控制着模型每次更新参数时“走多远”。如果学习率太大,模型可能会在最优解附近震荡甚至发散(Loss 变成 NaN);如果太小,模型收敛极慢,甚至容易陷入局部最优,对于此次代码中使用的这种基础梯度下降算法,常见的初始学习率通常在 0.01到 0.1之间,我们代码中的0.05是个合理的起点
迭代次数(iterations) 决定了模型在训练集上遍历学习的遍数。迭代太少会导 致欠拟合,太多会导致过拟合(在训练集表现好,但在测试集表现差)。 对 于相对简单的监督学习问题(如基础的图像二分类),通常 1000到 5000次 迭代基本可以达到较好的收敛效果。代码中的2000可以作为初步测试的基准。
结语
下一篇将更新神经网络方面内容,对于本篇各位同学和前辈有什么心得或建议欢迎留言一起交流。
谢谢看完,晚安~~
推荐阅读
对于相对简单的监督学习问题(如基础的图像二分类),通常 1000 到 5000 次迭代基本可以达到较好的收敛效果。你代码中的 1000 可以作为初步测试的基准。 、
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- Playwright python --之运行和调试
- Linux Shell 函数库与脚本复用——建立自己的工具箱
- 用AI+Python搭建了一个数据分析智能体,直接解放双手,再也不用熬夜加班了!
- Linux命令大全-pvcreate命令
- 【招聘】python、intramart経験者 日本横浜【赴日驻日IT工作岗位】
- python的入门基础重点:列表
- Java大神整理的面试笔记传疯了,堪称最强!
- Linux 7.2 消灭了一个 C 标准库函数 strncpy——这场迁移照出了 C 语言在系统编程中的结构性安全债
- 小白学编程,10分钟教你看懂90%Python代码
- 假如你从高考后开始学Python,听劝!自学Python前,请收下这张“防迷路地图”!!
