Linux 如何用一棵树管住百万页缓存:内核的 Page Cache 面纱
1. 从一个数字说起
一台 8GB 内存的 Linux 机器,通常有 3~5GB 被 Page Cache 占据——换算成 4KB 页面就是 75万~130万页。内核必须随时回答一个问题:“文件 X 的第 N 页在不在内存里?” 回答这个问题的速度直接决定了一次 read() 是 100 纳秒还是 100 微秒——差 1000 倍。
答案藏在一棵树里。
2. 全局视角:三个核心数据结构
先看从文件到缓存页的完整链路:
c
struct inode { // 代表磁盘上的一个文件
struct address_space *i_mapping; // 指向该文件的缓存管理器
...
};
struct address_space { // 文件的"缓存管家"
struct inode *host; // 反指所属文件
struct xarray i_pages; // 核心!页面索引树
unsigned long nrpages; // 当前缓存页总数
const struct address_space_operations *a_ops; // 文件系统回调
};
struct folio { // 一个物理 4KB 页的描述符
struct address_space *mapping; // 我属于哪个文件
pgoff_t index; // 我是文件的第几页
unsigned long flags; // 状态标志 (dirty/uptodate等)
};
关系一句话概括:inode → address_space → XArray(树)→ folio。多个进程打开同一文件,共享同一个 address_space 和同一份缓存——这就是"第二次打开秒开"的原因。
3. XArray 基数树:一棵什么样的树
address_space.i_pages 是一个 XArray——一棵分层的基数树。每个内部节点(xa_node)有 64 个 slot(由 XA_CHUNK_SHIFT=6 决定),每层消耗 key 的 6 个 bit。
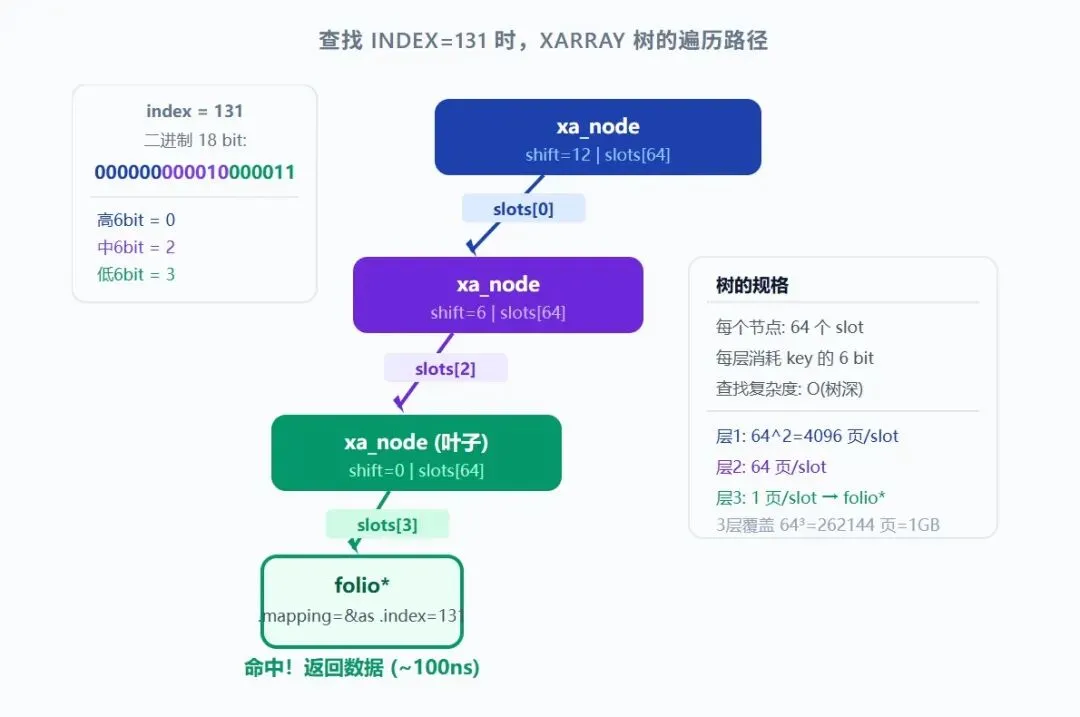 XArray 树查找路径示意图
XArray 树查找路径示意图
图示说明:查找 index=131 时,将 131 拆为 64 进制 [0][2][3],逐层走 slots[0] → slots[2] → slots[3],直达 folio。3 次数组取值,零比较零遍历。
3.1 为什么可以分层查找?
核心就一行代码(lib/xarray.c):
c
offset = (index >> node->shift) & 63; // 取 index 某 6 bit 作为数组下标
entry = node->slots[offset]; // 直接跳到子节点
原理:每个节点 64 = 2^6 个 slot,每层恰好"消耗" index 的 6 个 bit。等价于把 index 看作 64 进制数,每一位就是一层的 slot 下标:
bash
131 (十进制) = 0×64² + 2×64¹ + 3×64⁰
64 进制: [0] [2] [3]
↓ ↓ ↓
层1 层2 层3 的 slot 下标
和十进制查表完全类似——如果你有一个 1000 格的柜子,找第 457 格,你可以拆成"第 4 排、第 5 列、第 7 格"逐层定位,而不需要从第 1 格数到第 457 格。XArray 就是把这个思路换成了 64 进制。
对比红黑树/哈希表:红黑树每层要比大小决定走左/走右;哈希表要处理冲突链。XArray 用位运算直接算出路径——3 次右移 + 3 次取数组元素,CPU 几乎不用"思考"。
3.2 树的容量
key(pgoff_t)是 unsigned long,64-bit 系统为 64 位。每层消耗 6 bit,最大深度 = ⌈64 / 6⌉ = 11 层。
| 文件大小 |
最大 index |
树深度 |
说明 |
| 256 KB |
63 |
1 层 |
单个 xa_node 即可 |
| 16 MB |
4,095 |
2 层 |
大部分配置文件 |
| 1 GB |
262,143 |
3 层 |
常见日志/数据文件 |
| 1 TB |
~2.7亿 |
5 层 |
大型数据库 |
| 理论极限 |
2^64-1 |
11 层 |
永远够用 |
树按需生长——空 slot 不分配 xa_node,稀疏文件几乎零开销。
4. 如何判断一个页是否已缓存
就看 xas_load() 的返回值:非 NULL = 已缓存,NULL = 未缓存。
c
// mm/filemap.c
void *filemap_get_entry(struct address_space *mapping, pgoff_t index)
{
XA_STATE(xas, &mapping->i_pages, index);
struct folio *folio;
rcu_read_lock(); // RCU 读锁:零竞争
folio = xas_load(&xas); // 沿树逐层走到叶子
if (folio && !xa_is_value(folio))
folio_try_get(folio); // 防止并发回收
rcu_read_unlock();
return folio; // NULL = 未缓存,非 NULL = 已缓存
}
没有标志位、没有布尔变量——树的 slot 里有 folio 指针就是缓存了,是 NULL 就是没缓存。整个判断只需沿树走 2~3 层,不遍历任何链表,不比较任何 key。
性能数字:Page Cache 命中约 100 纳秒,SSD 随机读需 50,000~100,000 纳秒——命中与未命中差 500~1000 倍。
5. 插入:缓存一个新页
当 read() 未命中时,内核从磁盘读取数据后把新 folio 挂进树里:
c
// mm/filemap.c
int __filemap_add_folio(struct address_space *mapping,
struct folio *folio, pgoff_t index, ...)
{
XA_STATE(xas, &mapping->i_pages, index);
folio->mapping = mapping; // 反向指针:folio 属于哪个文件
folio->index = index; // 反向记录:folio 是第几页
xas_lock_irq(&xas); // 写操作需要加锁
xas_store(&xas, folio); // 沿路径插入(必要时分配新 xa_node)
mapping->nrpages++;
xas_unlock_irq(&xas);
}
如果路径上缺少中间 xa_node,xas_store 会自动分配——树的"按需生长"就发生在这里。
6. 双向映射:正查 + 反查
c
struct folio {
struct address_space *mapping; // → 所属文件的 address_space
pgoff_t index; // → 文件中第几页
};
-
- 正向:read() 时用——
mapping->i_pages[index] → folio* - 反向:回收时用——
folio->mapping → 哪个文件;folio->index → 哪个位置
每个缓存页只多花 16 字节(一个指针 + 一个 ulong)就实现了双向寻址。
7. 标记系统:一棵树如何追踪脏页
xa_node 内置 tag 位图:
c
struct xa_node {
void __rcu *slots[64]; // 64 个子指针
unsigned long tags[3][1]; // 3 组 tag,每组 64 bit 位图
};
| Tag |
含义 |
使用场景 |
| PAGECACHE_TAG_DIRTY |
页已修改 |
writeback 线程找脏页 |
| PAGECACHE_TAG_WRITEBACK |
正在写回 |
防止重复写回 |
| PAGECACHE_TAG_TOWRITE |
待写入 |
批量写回调度 |
标记为 DIRTY 时,从叶子到根的每一层都设置对应 bit——遍历脏页时可以跳过所有没有脏子节点的子树。百万页中找 100 个脏页不需要遍历百万次。
8. 实战:一次 read() 的完整路径
bash
read(fd, buf, 4096) // 读文件偏移 8192 处的 4KB
│
├─ index = 8192 / 4096 = 2
│
├─ filemap_get_read_batch(mapping, index=2)
│ └─ xas_load() 在 XArray 中查 slot → folio*
│
├─ 命中 (folio != NULL && uptodate)
│ └─ copy_to_user(buf, page_address(folio), 4096)
│ └─ return 4096 ← ~100ns 完成
│
└─ 未命中 (folio == NULL)
├─ page_cache_sync_ra() ← 触发预读(多读几十页)
│ ├─ alloc_pages() ← 分配物理页
│ ├─ __filemap_add_folio() ← 插入 XArray
│ └─ a_ops->readahead() ← 文件系统从磁盘读取
├─ 等待 IO 完成 → set_folio_uptodate()
└─ copy_to_user() → return 4096 ← ~50-100μs(含磁盘)
9. 内存回收:树不会无限膨胀
bash
首次访问 folio
→ 放入 inactive list(观察区)
→ 再次被访问 → 晋升 active list(保护区)
→ 长期不访问 → 留在 inactive 尾部
→ 内存紧张时从尾部开始回收:
clean page → 直接丢弃(磁盘有原始数据)
dirty page → 先 writeback,再丢弃
回收 folio 时,xas_store(&xas, NULL) 把树的对应 slot 置空——之后查找该 index 就回到"未命中"路径。
10. 指针低位复用
folio 的 mapping 字段除了指向 address_space,还要标记页面类型。利用地址对齐:
c
struct address_space { ... } __attribute__((aligned(8)));
// 8 字节对齐 → 地址低 3 bit 永远是 000
#define PAGE_MAPPING_ANON 0x1 // bit0=1 → 匿名页(堆/栈)
if (folio->mapping & 0x1) → 匿名页
else → 文件页(Page Cache)
address_space *as = (void *)(folio->mapping & ~0x3); // 还原指针
百万个 folio,每个省 8 字节 = 省 8MB 内存。
11. 文件系统在哪里?
整棵 XArray 树、LRU 回收、脏页追踪——全部是通用层(mm/filemap.c)做的。文件系统只需实现一组回调:
c
struct address_space_operations {
int (*read_folio)(struct file *, struct folio *);
void (*readahead)(struct readahead_control *);
int (*writepages)(struct address_space *, ...);
int (*write_begin)(struct file *, ...);
int (*write_end)(struct file *, ...);
};
换文件系统不影响缓存性能——无论 ext4 还是 f2fs,Page Cache 的树查找速度完全一致。
12. 一图总结
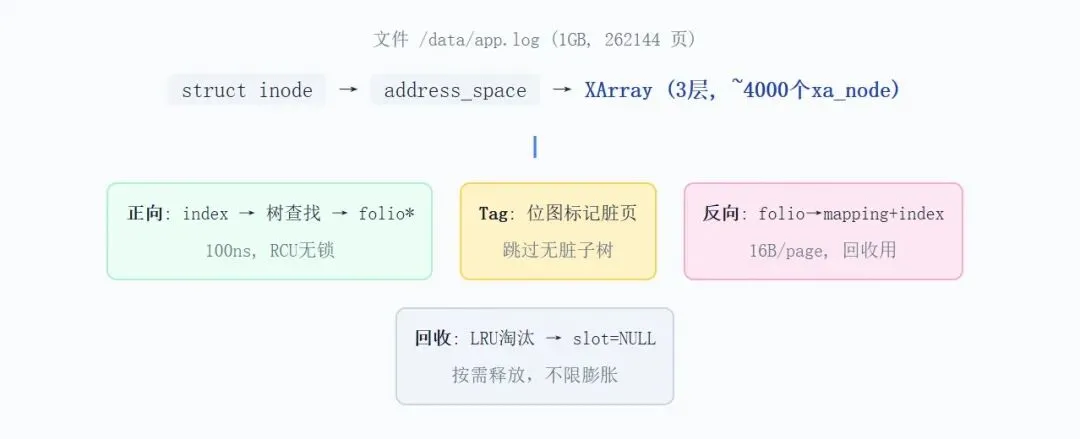 Page Cache 总结图
Page Cache 总结图
图示说明:一个 1GB 文件的完整缓存架构。struct inode → address_space → XArray(3层,~4000个xa_node)。四大能力:正向查找(100ns,RCU无锁)、Tag位图标记脏页(跳过无脏子树)、反向查找(folio→mapping+index,16B/page)、LRU回收(slot=NULL,按需释放)。
Linux 用一棵按需生长、逐层 64 分叉的基数树,在百万页面中实现了纳秒级定位、零遍历的脏页追踪、以及优雅的按需回收。这就是文件第二次读取比第一次快 1000 倍的根本原因——数据已经在树里了,不再需要访问磁盘。

