嵌入式Linux内存深度剖析与优化实战:从原理到落地
在嵌入式Linux开发中,内存优化往往是一个被低估却又至关重要的环节。与服务器或桌面环境动辄数十GB的内存配置不同,嵌入式设备通常受限于成本与功耗,物理内存资源捉襟见肘。此前Bootlin分享了一场关于Linux内存检视与优化的深度演讲,展示了如何系统地理解Linux内存管理机制,并利用现有工具链进行精准的优化。本文将基于该演讲的核心内容,结合内核源码与工程实践,深入拆解嵌入式Linux内存优化的方法论。一、 内存管理的基石:虚拟内存与物理架构
要优化内存,首先必须理解Linux是如何抽象和管理硬件资源的。1.1 虚拟内存的核心机制
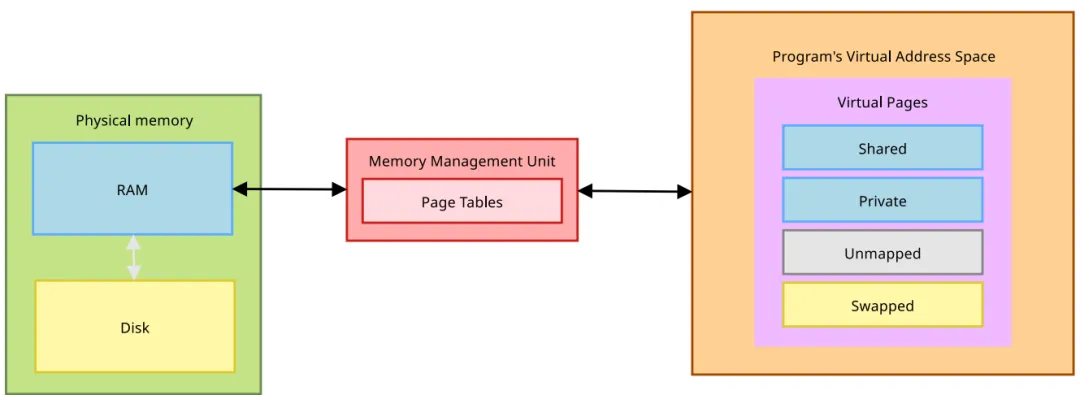
Linux采用虚拟内存管理,应用程序并不直接操作物理地址,而是通过MMU(内存管理单元)映射到物理内存。这种机制带来了三个核心优势:简化编程模型:为每个进程提供统一且连续的地址空间。进程隔离:防止用户态程序越界访问内核或其他进程的内存。抽象扩展:将主存与交换分区(Swap)抽象为统一的资源池。在内核中,物理内存被切分为固定大小的页(Page)。在绝大多数ARM64架构的嵌入式系统中,页大小为4KiB。为了管理这些物理页,内核定义了 struct page 结构体(include/linux/mm_types.h)。工程启示:这是一个容易被忽视的内存开销点。假设系统有2GiB内存,每页4KiB,则共有约52万个物理页。每个 struct page 约占64字节,这意味着仅用于描述物理内存的数据结构就消耗了约32MiB的内存。在设计大内存嵌入式系统时,这部分“元数据税”必须计入预算。1.2 虚拟内存区域(VMA)
虽然物理内存以页为单位,但虚拟内存的管理粒度更粗一些——以VMA(Virtual Memory Area)为单位。通过 struct vm_area_struct,内核管理一段连续的虚拟地址空间。无论是代码段(.text)、数据段(.data)还是堆(heap)、栈(stack),在内核看来都是一个个VMA。通过查看 /proc//maps,我们可以清晰地看到进程的各个VMA分布。1.3 物理内存的分区(Zones)与节点(Nodes)
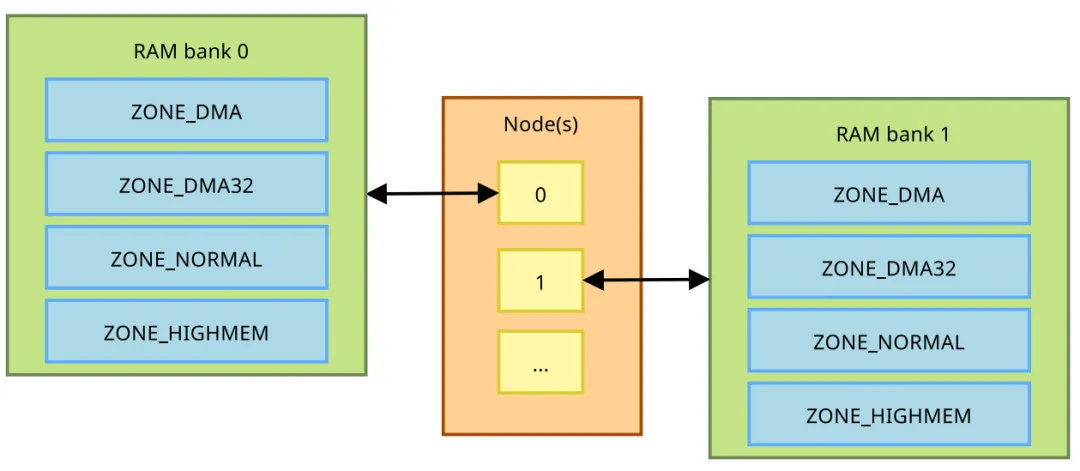
物理内存并非均质的,Linux将其划分为不同的Zone:ZONE_DMA/ZONE_DMA32:用于兼容旧式DMA设备或32位寻址限制的设备。ZONE_NORMAL:内核直接映射的普通内存。在64位系统中,这通常是主要的可用内存区。ZONE_HIGHMEM:仅在32位系统中存在,用于映射高于896MiB的物理内存。在NUMA(非一致内存访问)架构或多核ARM平台上,内存还关联到具体的Node。我们可以通过 /proc/buddyinfo 查看伙伴系统(Buddy System)的状态。这个文件展示了不同Zone中不同阶数(Order)的连续内存块数量。例如,cat /proc/buddyinfo 输出的第一列代表0阶(2^0个页,即4KiB)的空闲块数量。如果高阶内存块极少,说明系统存在严重的内存碎片化问题,可能导致大块连续内存分配失败(即使总空闲内存充足)。二、 内核空间:透视内核的内存足迹
内核自身也是内存消耗的大户。优化的第一步是量化内核到底用了多少内存,以及用在了哪里。2.1 解读启动日志(Dmesg)
系统启动时,内核会打印内存布局信息,这是分析的起点:Memory: 2012000K/2064384K available (7936K kernel code, 572K rwdata, 1708K rodata, 1280K init, 328K bss, 52384K reserved)Total (2064384K): 物理内存总量(扣除OPTEE等安全固件占用的部分)。Kernel Code (7936K): 内核二进制镜像的 .text 段,即指令代码。Rwdata (572K): 已初始化的可写全局变量和静态变量。Rodata (1708K): 只读数据,如常量字符串、常量数组。Init (1280K): 初始化函数和数据。这部分内存在内核启动完成后会被释放,因此我们看到后续的 MemTotal 比这里的 available 略大。BSS (328K): 未初始化的静态变量(默认清零)。Reserved (52384K): 预留内存,包括上述内核代码数据、页表、以及CMA(连续内存分配器)等。实战技巧:对比 MemTotal 和物理内存总量的差值。如果差值巨大,检查是否配置了过大的CMA区域(cma-reserved)或者内核日志缓冲区(log_buf_len)。2.2 运行时监控:/proc/meminfo
进入系统后,/proc/meminfo 是我们观察内存动态的窗口。除了常见的 MemTotal 和 MemFree,以下指标对嵌入式优化尤为关键:Slab: 内核对象缓存(如inode、dentry、TCP连接控制块等)。Slab占用过高通常意味着驱动或内核子系统创建了大量对象。可以通过 slabtop 命令查看具体是哪些对象占用了内存。KernelStack: 每个内核线程或用户线程的内核栈都会占用此处内存。如果系统创建了上千个线程,这里会是一笔巨大的开销。PageTables: 页表占用的内存。随着进程地址空间增大(例如进程加载了大库),此项会增加。VmallocUsed: vmalloc 区域的使用量。驱动程序中常使用 vmalloc 申请非连续的大块虚拟内存。三、 用户空间:谁在吞噬你的内存?
用户空间的分析重点在于区分“独占”与“共享”,以及识别内存泄漏。3.1 传统工具:ps 与 top
ps aux 或 top 命令输出的 VSZ(虚拟内存大小)和 RSS(常驻内存集)是最常用的指标。VSZ:包含了进程地址空间的所有映射,包括尚未加载到物理内存的部分,以及共享库的映射。因此它通常远大于实际消耗。陷阱:RSS会将共享库按全量计算在每个进程中。如果一个10MB的libc被10个进程使用,ps 会显示这10个进程各占了10MB,导致统计虚高。这在嵌入式系统中极具误导性。3.2 进阶工具:smem
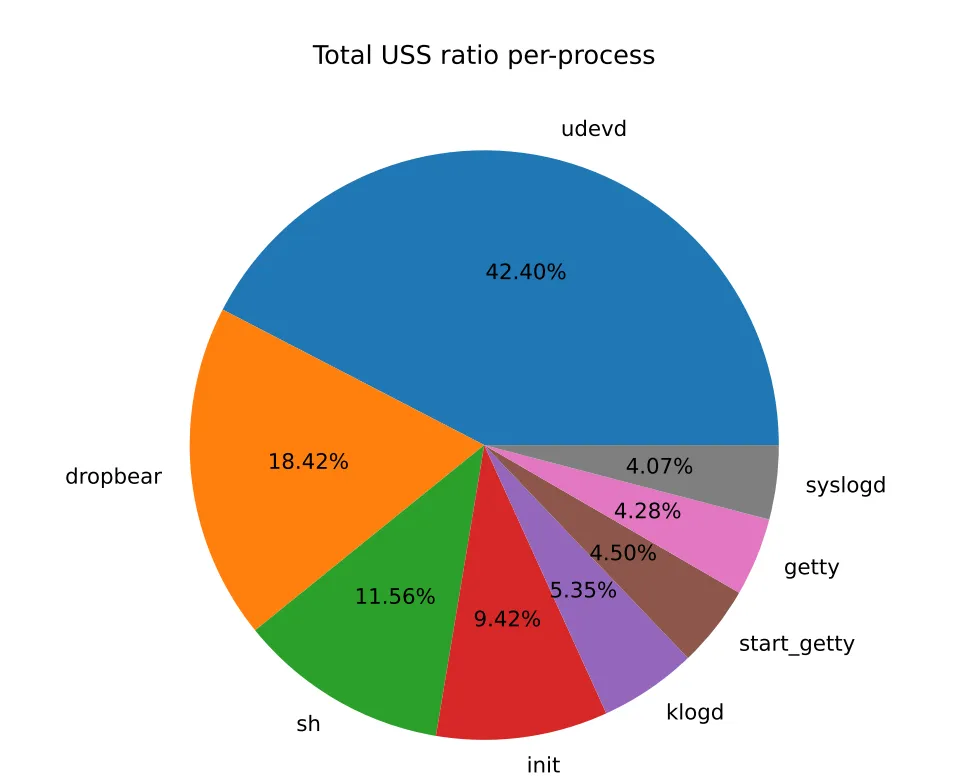
为了解决RSS的统计偏差,smem 工具引入了两个关键指标:USS (Unique Set Size):进程独占的物理内存。这是判断进程真实内存消耗的最准确指标。PSS (Proportional Set Size):按比例计算的共享内存。如果10MB的共享库被10个进程共享,每个进程的PSS只增加1MB。实战案例:使用 smem -t -P 可以快速定位特定进程的内存占比。结合 smem --pie=name -s pss,可以生成直观的内存分布饼图,帮助我们发现系统中最耗内存的“元凶”。3.3 深入分析:/proc//smaps
smem 的数据源正是 /proc//smaps。这个文件详细列出了该进程每一个VMA的映射情况,包括Rss、Pss、Private_Dirty、Private_Clean等。Private_Dirty:通常是堆(Heap)和栈(Stack)中已被修改的部分,这部分无法被交换出去,是内存压力的敏感指标。Anonymous: 匿名内存,通常指通过 malloc 分配的内存。四、 优化实战:从几十MB到几MB的艺术
4.1 内核裁剪:瘦身为先
功能裁剪:这是最有效的手段。审视内核配置,关闭不需要的功能。例如,如果不使用图形界面,关闭DRM、GPU驱动;如果不使用蓝牙,关闭BT协议栈;如果不需要热插拔,甚至可以考虑关闭UEFI/ACPI支持。编译器优化:调整 CONFIG_CC_OPTIMIZE_FOR_SIZE(使用 -Os 编译),牺牲部分性能换取更小的二进制体积。禁用调试选项:CONFIG_DEBUG_KERNEL、CONFIG_KALLSYMS(符号表)、CONFIG_DEBUG_INFO 在开发阶段有用,但在生产环境中会显著增加内存占用和存储占用。模块替代内置:尽量使用 =m(模块)而非 =y(内置)。模块在加载时才占用内存,卸载后即可释放,增加了灵活性。4.2 捕捉内存泄漏
动态追踪:使用 free -h 观察 available 内存是否随时间持续下降。如果是,说明存在泄漏。定位进程:使用 smem 监控各进程的USS/PSS变化,找到泄漏源。精确定位:使用Valgrind。虽然Valgrind会带来巨大的性能损耗(通常不适用于在线生产环境,更适合实验室测试),但它能精准定位泄漏点和非法内存访问。 valgrind --leak-check=full --show-leak-kinds=all ./your_program它会明确指出哪一行代码分配了未释放的内存,以及是否存在非法读写。4.3 应对内存压力:Swap与ZRAM
嵌入式系统通常没有Swap分区,但这并不意味着不能利用Swap机制。Swappiness:通过 /proc/sys/vm/swappiness 调整内核换出倾向。设置为0在大多数情况下并不禁用Swap,而是极度倾向于不换出。在cgroup v1中,设置 memory.swappiness=0 才能真正禁止该组的Swap。ZRAM:这是嵌入式领域的“神器”。它在RAM中划分一块区域,将数据压缩后再存储。4.4 最后的防线:OOM Killer调优
当内存耗尽时,内核会触发OOM Killer(Out-Of-Memory Killer)杀掉进程以回收内存。评分机制:内核通过计算 oom_badness 来决定杀谁。得分高的通常是占用内存多、运行时间短、nice值低的进程。保护关键进程:如果你有必须保活的关键服务(如看门狗、通信守护进程),可以通过调整 /proc//oom_score_adj 来保护它。将进程优先级设为最低(最不容易被杀) echo -1000 > /proc/$(pgrep critical_service)/oom_score_adj
注意:OOM_SCORE_ADJ_MIN (-1000) 意味着完全免疫OOM Killer。请谨慎使用,滥用可能导致系统因无法回收内存而彻底卡死(Kernel Panic)。