技术选型篇:RAG 为什么不用 LangChain,而是选了 LlamaIndex?
这是「用 Python 从 0 打造金融反欺诈 GraphRAG 智能体」专栏的第 1 篇。 开篇立了 flag,这一篇先回答一个绕不开的问题:这套系统到底用什么技术栈搭,每个选型凭什么这么定?
本文速览
- 🔥 重点:RAG 我为什么没用最火的 LangChain,而是选了 LlamaIndex?
- 🌉 「Java 老兵转 Python」的 3 个真实切换体会(纯 Python 博主写不了这个)
- 一个反直觉的认知:技术"风很大" ≠ 每个细分都最优
一、为什么选型值得单独写一篇
做了十几年工程我有个体会:选型选错,后面全是返工。 框架选错,写到一半发现扩展不了;存储选错,数据量一上来就崩。
尤其 AI 应用,工具链每月都在变,更容易选花眼。所以我动手写代码前,把每个选型的"为什么"想清楚了。
这篇就是我的决策记录——不是"我用了 X",而是"X vs Y vs Z,因为……所以选 X"。这种思考过程,恰恰是面试官最想看的。
二、选型 4 原则(先定调,再选具体)
- 站在框架肩膀上:能用成熟框架绝不自研。我 Java 版自研过 Agent 框架(6644 行,吃透了原理),Python 版不重复造轮子——但不等于无脑用最火的,而是每个模块选那个领域最强的。
- 岗位对口:选市场主流、面试官认的技术(LangGraph / Ragas),不选小众炫技的。
- 复用旧底座:Milvus / Ollama / Jaeger / Docker 这些 Java 版已经趟过的,心智沿用,不改。
- 私有化友好
三、9 个关键决策
1️⃣ Web 框架 → FastAPI
| |
|---|
| FastAPI | 全异步 + Pydantic 类型校验 + 自动 OpenAPI + SSE 原生支持 |
| |
| |
理由:LLM 调用是典型的高延迟 IO 场景,异步是刚需。而且 Pydantic 和 LLM 结构化输出天然契合——你定义的 BaseModel,LLM 能直接照着输出 JSON。对 Java 背景来说,FastAPI ≈ Spring Boot 的轻量异步版,学习曲线几乎为零。
下面这个就是你会写的第一段代码,整整齐齐的 Pydantic:
from pydantic import BaseModelclass ChatRequest(BaseModel): question: str thread_id: strclass ChatResponse(BaseModel): answer: str citations: list[dict]@router.post("/chat")async def chat(req: ChatRequest) -> ChatResponse: ...
2️⃣ Agent 编排 → LangGraph
| |
|---|
| LangGraph | 状态机:条件路由 / 循环 / 重试 / 降级 / Checkpointer 持久化——生产级可控 |
| 多 Agent 协作容易上手,但控制粒度太粗,失败处理难定制 |
| |
理由:它的"状态机"思想最接近我 Java 版自研的工作流引擎,迁移心智低。而条件路由 + 重试 + 降级正好是 2026 AI 岗面试的高频考点——面试官想看的不是"能跑",而是"跑崩了怎么办"。LangGraph 的 add_conditional_edges + Checkpointer 恰好回答这个问题。
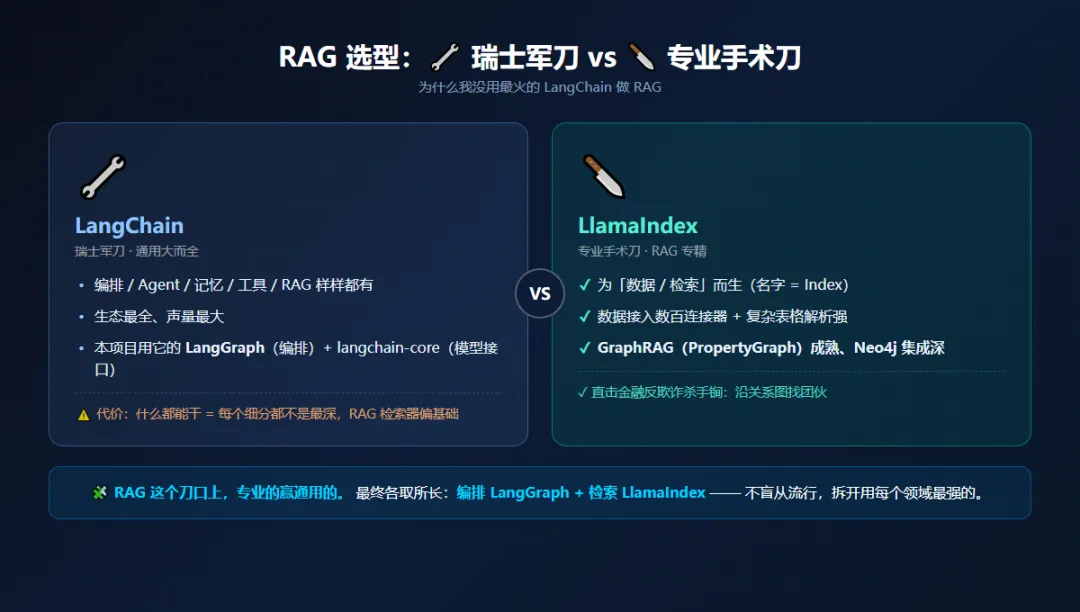
3️⃣ 🔥 RAG → LlamaIndex(而不只是 LangChain 的 RAG)
这是最多的一个问题:LangChain 声量最大,为什么 RAG 不用它?
先说清楚:我并不是"没选 LangChain"。我的编排层用 LangGraph(LangChain 团队出品),模型接口也用 langchain-core。真正的决策是:RAG / 检索这一层,用 LlamaIndex 还是 LangChain 的原生 RAG?
| | |
|---|
| 为数据/检索而生 | |
| 数百连接器(LlamaHub)+ 复杂 PDF/表格解析强 | |
| 句子窗口 / small-to-big / 自动合并 / 递归检索——调优旋钮多 | |
| PropertyGraphIndex 成熟,Neo4j 集成好 | |
| | |
🧩 一句话类比:LangChain 是瑞士军刀,LlamaIndex 是专业手术刀。RAG 这个刀口上,专业的赢通用的。
具体到我这个金融反欺诈项目,LlamaIndex 的 GraphRAG 支持是决定胜负的——我的核心能力就是让 AI 沿着关系图找人、找设备、找担保环。PropertyGraphIndex + Neo4j 的集成深度,LangChain 原生的 RAG 套件目前追不上。
代价:多引入一个框架,多一层学习曲线。但对"以 GraphRAG 为杀手锏"的项目来说,值。
最终架构就是各取所长:
编排 → LangGraph(状态机编排)检索 → LlamaIndex(专业 RAG / GraphRAG)模型 → langchain-core(统一 LLM 接口)
4️⃣ 图数据库 → Neo4j 5
| |
|---|
| Neo4j 5 | Cypher 易学、GDS 图算法现成、5.x 内置向量索引,生态最大 |
| |
| |
理由:反欺诈的关键信息藏在关系里——谁和谁共用设备、谁给谁担保、谁和谁同地址。向量检索抓不到多跳关系,图库天生擅长。
Neo4j 的 GDS 库可以直接跑社区检测(找团伙)、PageRank(找影响力节点)、最短路径(找关联链)——这些是反欺诈场景的现成武器。而且 5.x 内置向量索引,图 + 向量一个库搞定,省掉单独维护 Milvus 的开销。
还有一层不可复制的:我有金融风控时期的 Neo4j 实战经验——这个组合(反欺诈 + 图库 + AI),市场上很少人有。
5️⃣ 向量存储 → Neo4j 原生向量(主)/ Milvus(对比实验)
理由:如上文所说,Neo4j 5 自带向量索引,金融反欺诈数据量可控,没必要上专业向量库增加运维复杂度。Milvus 留着做"朴素 RAG vs GraphRAG"对比实验的向量侧——这是评测篇的素材。
6️⃣ LLM → Ollama(本地)+ DeepSeek API(云)双模式
| |
|---|
| Ollama(qwen2.5) | |
| DeepSeek API | |
理由:抽象一个统一接入层,配置一键切换。金融数据敏感时走本地,拼性能/质量时走 API。两手准备,不依赖单点。
class LLMProvider: """统一接入:配置决定走 Ollama 还是 DeepSeek""" async def generate(self, prompt: str) -> str: ...class OllamaProvider(LLMProvider): ...class DeepSeekProvider(LLMProvider): ...# config.yaml 一行切换llm_provider: deepseek # 或 ollama
7️⃣ 🔥 Embedding → bge-m3(展开说)
这个比大多数人想象的更重要。Embedding 模型决定了 RAG 的检索质量上限——你的分块策略再完美,检索器选错了,召回一团糟。
选 bge-m3 的三个理由:
- 中文金融文本表现好——金融场景里"质押率"“担保比”"多头借贷"这些术语,bge-m3 的词嵌入质量明显优于面向英文的模型。
- 数据不出内网——本地跑,不调用任何外部 API,符合金融合规。
- 1024 维刚好——维度太低(如 384)分辨力不够,太高(如 1536,ada)存储和检索成本高。1024 维是一个不错的平衡点。
为什么不选 OpenAI ada:虽然 ada 的英语场景很强,但中文金融文本混杂了中英文术语(“PK 贷”“多头 debt ratio”),bge 对这种中英混合场景更友好。而且每查询都要走 API,对内网部署场景无法接受。
8️⃣ 🔥 Eval 评测 → Ragas + DeepEval + LangFuse
| | |
|---|
| Ragas | | 忠实度 / 精确度 / 召回 / 相关性——算出来告诉你系统好不好 |
| DeepEval | | pytest 风格,CI 里断言"faithfulness > 0.85"才能合代码 |
| LangFuse | | 自部署平台,trace 每次 LLM 调用 + 看线上质量滑坡 |
这三个的关系是:Ragas 算分,DeepEval 守门,LangFuse 看线。 三者互补,不重叠。
Eval 是 2026 最值钱的信号。市场上大把"调通 Demo 就发文章"的,能拿出 Ragas 量化报告 + CI 回归门禁 + 线上质量监控的,很少。这块我会单独用一篇来深讲(见《评测篇》)。
9️⃣ 可观测 → OTel + Jaeger + LangFuse
理由:Java 版已经用 OTel + Jaeger 搭好了全链路追踪底座,Python 版直接复用同一套 Jaeger 实例就行。加上 LangFuse 做 LLM 专用的 Token/成本/质量监控。双轨互补。
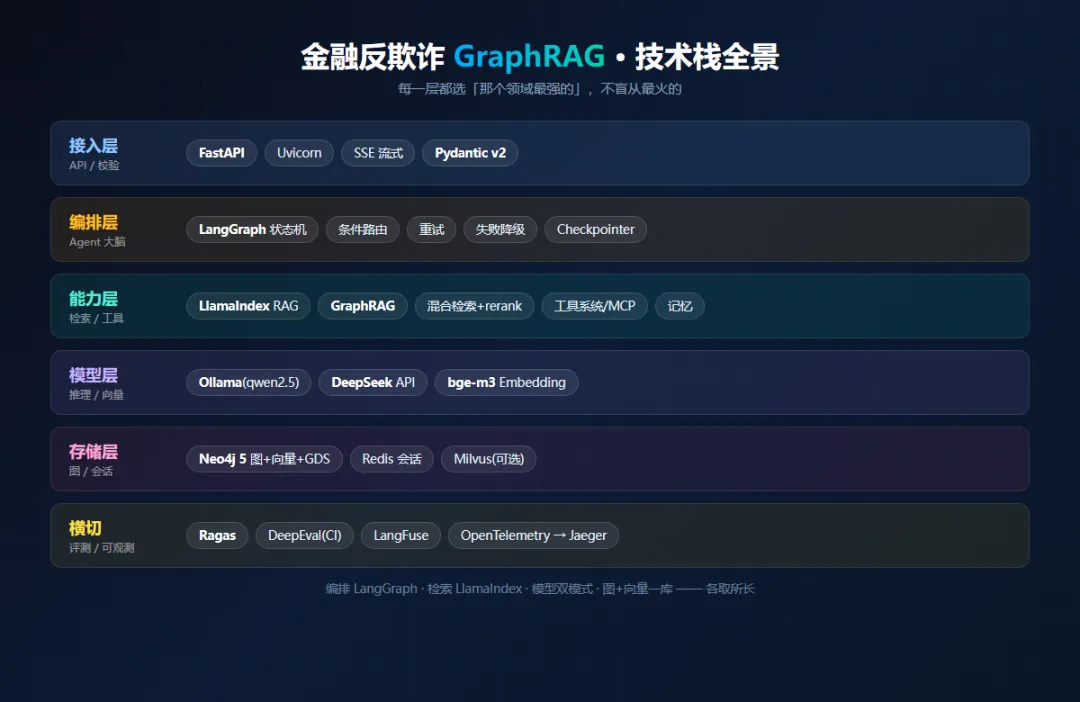
四、技术栈全景一览
| | |
|---|
| | 全异步、Pydantic 类型、类 Spring Boot 体验 |
| | |
| | GraphRAG + Neo4j 集成深度远超竞品 |
| | |
| Neo4j 原生向量 / Milvus(可选对比) | |
| Ollama / DeepSeek API 双模式 | |
| | |
| Ragas + DeepEval + LangFuse | |
| | |
| | |
| | |
五、🌉 Java 老兵转 Python 的 3 个真实体会
这部分是纯 Python 开发者写不了的——如果你也是「Java 底子、正在转 Python AI」,欢迎对号入座。
1. 语言不致命,生态知识要重新爬
换语言不可怕。FastAPI 的异步 + 类型注解 ≈ Spring Boot 的 RestController + Bean Validation。LangGraph 的状态机 ≈ 我自研的工作流引擎。架构直觉是对语言通用的。
真正的学习成本在生态知识上:Python 没有 Spring 的自动装配,依赖要自己 __init__ 传入(或用 FastAPI 的 Depends());Python 的包管理(pyproject.toml + poetry 或 uv)比 Maven 灵活但也更容易出依赖冲突。
2. 异步框架的语境切换
Java 的虚拟线程让异步几乎透明——你写同步代码,JVM 自动调度。Python 的 asyncio 是显式的:async def、await、asyncio.run() 必须手写。刚开始很容易忘了在某些地方加 await,导致拿到的不是结果而是 coroutine 对象。这点要适应几天,但不难。
3. 不要被"还要学一堆新框架"吓住
最让我犹豫的是"还要学 LangGraph、LlamaIndex、Ragas……"。但实际打开一看:LangGraph 的状态机 = 我写过的 AgentWorkflow 换了个 API;LlamaIndex 的检索器 = 我写过的 RAG 检索换了个包装。 框架只是在封装你本来就会的概念。
所以你真正要的不是"学会框架",而是搞清楚框架替你做了什么、没做什么。把这一点想透,效率比从零学快很多。
六、一个反直觉的认知
技术"风很大" ≠ 它在每个细分都最优。
LangChain 声量最大、生态最全。但"全"的代价是每个细分都不是最深的。正确姿势不是"它火我就全用",也不是"它被骂我就全弃",而是拆开用它最强的部分——编排留 LangGraph,检索换 LlamaIndex。
不盲从流行、按场景拆解选型——这比"因为火所以用"高一个段位,也是工程师真正值钱的地方。
七、下期预告
选型定了,下一篇动手——《环境与底座:FastAPI + LangGraph + Neo4j 一把梭》,把项目骨架和图数据库跑起来,让代码说话。
📢 这个专栏每篇都在 公众号【SuniaCoder-AI 全栈架构实战】 同步更新。如果不想在信息流里追更,点个关注最稳。 评论区聊聊:你做 AI 应用,技术选型踩过哪些坑?