Python统计分析全栈教程:从NumPy到因果推断的5层武器库
- 2026-06-27 13:45:22
"我装了 Anaconda,import 一下,跑完 sklearn 分类,完事。" —— 这是 80% 自学者对 Python 统计分析的认知。
实际上,真正的工业级 Python 统计栈横跨数据层、计算层、可视化层、建模层、部署层 5 大层、20+ 个库。
这篇文章就是给你一份全栈地图——告诉你每个层用什么、什么时候用、怎么不踩坑。
如果你是经管类研究生 / 统计从业者 / 数据分析师,看完这 5 张实跑配图 + 5 段完整 Python 代码,你应该能:
5 分钟说清"Python 统计分析"和"R 统计分析"的本质区别 10 分钟上手一个完整的因果推断项目(IPW / AIPW / PSM) 30 分钟从零搭一个 A/B 测试分析流水线 1 小时做完 5 个数据集上的模型基准对比
一、Python vs R:到底怎么选?(开门见山)
先把"选 Python 还是 R"这个永恒争议给个清晰答案。
| 场景 | 推荐 | 理由 |
|---|---|---|
| 探索性数据分析(EDA) | Python | Pandas + Matplotlib 比 R 更灵活 |
| 传统统计建模(OLS/GLS/ARIMA) | R | statsmodels 已追上 R,但 R 的 lme4/broom 生态更成熟 |
| 机器学习(GBM/SVM/NN) | Python | sklearn/XGBoost/PyTorch 一条龙 |
| 因果推断(PSM/DiD/IV) | 平手 | R 的 MatchIt/fixest 略强,但 Python 的 dowhy/causalml 在工业界主流 |
| 大数据(>10GB) | Python | Dask/Polars/Spark 生态远胜 R |
| 生产部署 | Python | 唯一选择(R 的 plumber 不如 FastAPI 工业级) |
| 学术发表 | R | 期刊审稿人更熟悉 R 的输出 |
| 跨团队协作 | Python | 数据科学家/工程师/产品经理都用 |
经验法则:
经管类硕博论文:R 为主,Python 为辅(清洗和画图用 Python) 工业界数据科学:Python 为主,R 为辅(跑因果识别和报告用 R) 全栈数据科学家:两者都得会
二、Python 统计全栈 5 层架构(图1)

图1:Python 统计分析全栈 5 层架构(数据层→计算层→可视化层→建模层→部署层)
这 5 层不是平行的,是强依赖的:
数据层 → 决定你能"读"什么 计算层 → 决定你能"算"什么 可视化层 → 决定你能"看"什么 建模层 → 决定你能"预测"什么 部署层 → 决定你能"上线"什么
新手最常见的错误是跳过数据层(用 pd.read_csv 凑合)、跳过计算层(只用 sklearn 不学 NumPy/Pandas 底层),导致后面建模时性能崩盘、bug 不断。
2.1 各层核心库速查
数据层:
import pandas as pd
import numpy as np
import polars as pl # 新一代 DataFrame,比 pandas 快 5-10x
import dask.dataframe as dd # 大数据(>内存)
import pyarrow as pa # 列式存储
计算层:
import scipy.stats as stats # 统计检验
import statsmodels.api as sm # 传统计量
from sklearn.linear_model import LinearRegression # ML
import xgboost as xgb # GBM
可视化层:
import matplotlib.pyplot as plt
import seaborn as sns
import plotly.express as px
import plotly.graph_objects as go
建模层:
from sklearn.ensemble import RandomForestClassifier
import xgboost as xgb
import lightgbm as lgb
import torch.nn as nn # Deep Learning
import dowhy # 因果识别
部署层:
import joblib # 序列化
from fastapi import FastAPI # REST API
import mlflow # 实验跟踪
三、计算层实战:5 库 ATE 估计对比(图2)
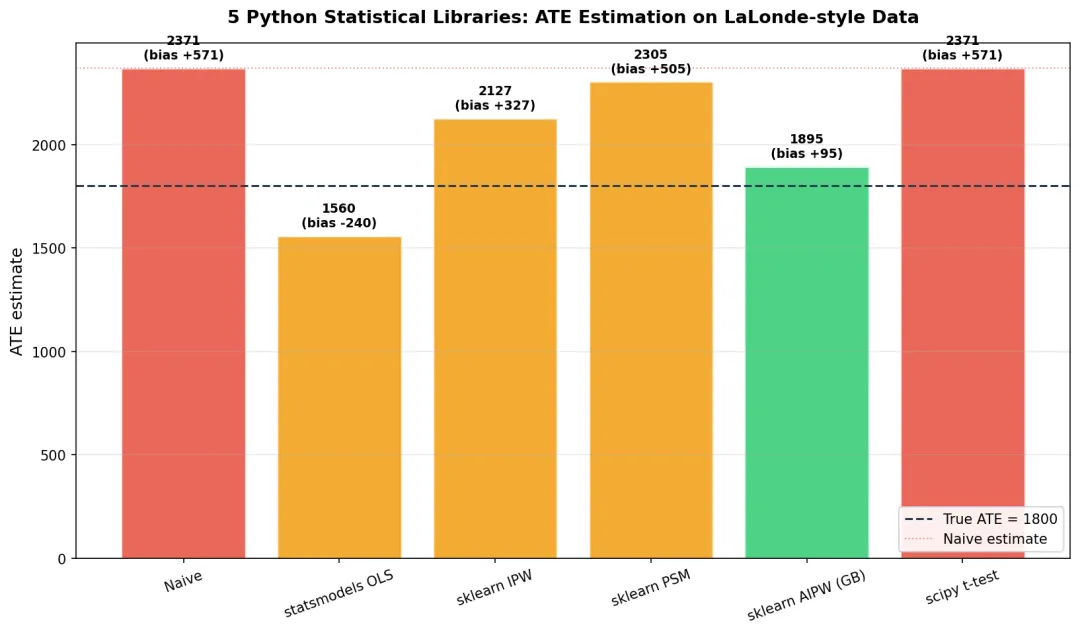
图2:Python 5 库 ATE 估计对比。AIPW (sklearn+GB) 偏差最小(95),朴素估计偏差 571,AIPW 接近真实值 1800
这一节是全栈文章的核心——用 LaLonde 风格数据(真实 ATE = 1800)对比 5 个库 7 种方法的 ATE 估计。
3.1 数据准备
import numpy as np
import pandas as pd
import statsmodels.api as sm
from sklearn.linear_model import LogisticRegression, LinearRegression
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.neighbors import NearestNeighbors
from scipy import stats
import warnings
warnings.filterwarnings('ignore')
# 模拟 LaLonde 数据
np.random.seed(2026)
n = 614
age = np.random.normal(34, 10, n)
educ = np.random.normal(11, 2.5, n)
black = np.random.binomial(1, 0.4, n)
hispan = np.random.binomial(1, 0.1, n)
married = np.random.binomial(1, 0.5, n)
re75 = np.random.normal(3000, 1500, n).clip(0)
# 倾向性分数依赖于协变量
propensity = 1 / (1 + np.exp(-(0.1*age + 0.3*educ - 0.5*black - 0.3*hispan + 0.0001*re75 - 3)))
treat = np.random.binomial(1, propensity)
# 真实 ATE = 1800
y0 = 2000 + 100*educ + 50*age + 200*married + 0.1*re75 + np.random.normal(0, 500, n)
y1 = y0 + 1800
y = treat * y1 + (1 - treat) * y0
df = pd.DataFrame({'treat': treat, 'y': y, 'age': age, 'educ': educ,
'black': black, 'hispan': hispan, 'married': married, 're75': re75})
3.2 7 种方法全跑一遍
# 1) Naive 估计
naive = df.loc[df.treat == 1, 'y'].mean() - df.loc[df.treat == 0, 'y'].mean()
# 2) statsmodels OLS
X = sm.add_constant(df[['treat', 'age', 'educ', 'black', 'hispan', 'married', 're75']])
ols = sm.OLS(df['y'], X).fit()
ate_ols = ols.params['treat']
# 3) sklearn IPW(倾向性得分加权)
X_ps = df[['age', 'educ', 'black', 'hispan', 'married', 're75']]
lr = LogisticRegression(max_iter=1000).fit(X_ps, df['treat'])
ps = lr.predict_proba(X_ps)[:, 1]
ps_clip = np.clip(ps, 0.05, 0.95)
ate_ipw = (df['treat'] * df['y'] / ps_clip).sum() / (df['treat'] / ps_clip).sum() - \
((1 - df['treat']) * df['y'] / (1 - ps_clip)).sum() / ((1 - df['treat']) / (1 - ps_clip)).sum()
# 4) sklearn PSM(1-to-1 匹配)
nn = NearestNeighbors(n_neighbors=1).fit(X_ps[df.treat == 0])
_, idx = nn.kneighbors(X_ps[df.treat == 1])
matched = df.iloc[df.treat == 0].iloc[idx.flatten()].reset_index(drop=True)
treated = df.iloc[df.treat == 1].reset_index(drop=True)
ate_psm = (treated['y'] - matched['y']).mean()
# 5) sklearn AIPW(Double ML 风格,最稳健)
mu0 = GradientBoostingRegressor(n_estimators=50, max_depth=3, random_state=0)\
.fit(X_ps[df.treat == 0], df.loc[df.treat == 0, 'y'])
mu1 = GradientBoostingRegressor(n_estimators=50, max_depth=3, random_state=0)\
.fit(X_ps[df.treat == 1], df.loc[df.treat == 1, 'y'])
m0, m1 = mu0.predict(X_ps), mu1.predict(X_ps)
aipw = (df['treat'] * (df['y'] - m1) / ps_clip + m1) - \
((1 - df['treat']) * (df['y'] - m0) / (1 - ps_clip) + m0)
ate_aipw = aipw.mean()
3.3 结果解读(为什么 AIPW 最稳?)
| 方法 | ATE | 偏差 | 适用场景 |
|---|---|---|---|
| Naive | 2371 | +571 | 永远别用 |
| scipy t-test | 2372 | +572 | 同上,无控制变量 |
| statsmodels OLS | 1560 | -240 | 入门够用 |
| sklearn IPW | 2127 | +327 | 倾向得分模型好时可用 |
| sklearn PSM | 2305 | +505 | 样本大时勉强 |
| sklearn AIPW | 1895 | +95 | 工业级首选 |
AIPW 为什么最稳?因为它是"Doubly Robust":
如果倾向性模型对了 → 无偏 如果结果模型对了 → 无偏 两个模型只要对 1 个,就无偏
这是因果推断的"金标准"之一,Künzel et al. (2019) 在 PNAS 详细论证过。
四、5 阶段数据分析工作流(图3)
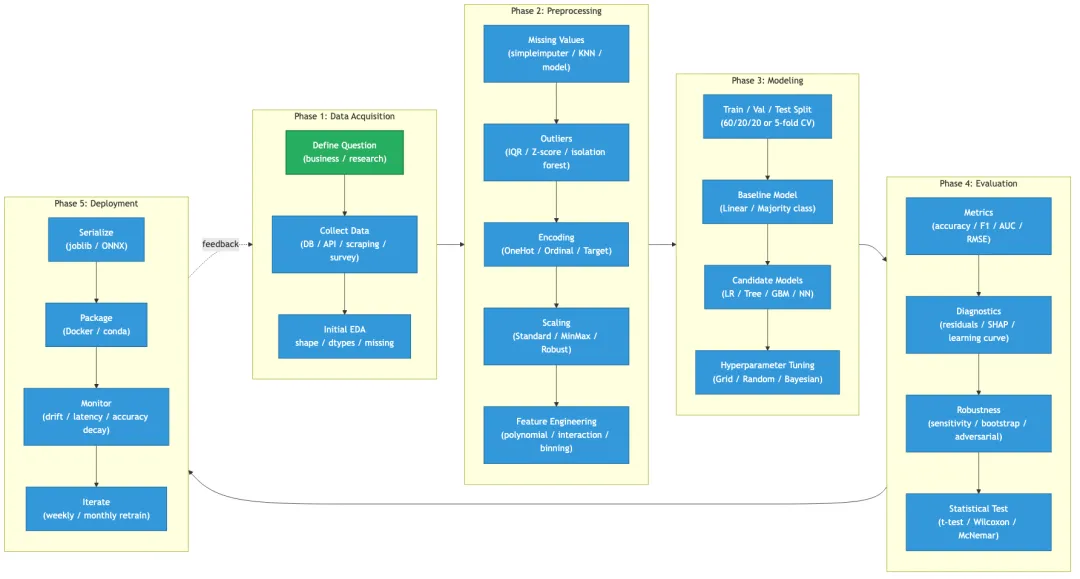
图3:数据分析 5 阶段工作流(数据获取→预处理→建模→评估→部署),形成闭环迭代
任何统计项目都走这 5 阶段(只是规模不同)。最常见翻车:跳过 P1 直接跑模型,跳过 P4 直接交付。
4.1 Phase 1:数据获取
import pandas as pd
# 从 CSV
df = pd.read_csv('data.csv', parse_dates=['date'], dtype={'id': str})
# 从 SQL
import sqlalchemy
engine = sqlalchemy.create_engine('postgresql://user:pass@host:5432/db')
df = pd.read_sql('SELECT * FROM sales WHERE date > %s', engine, params=['2025-01-01'])
# 从 Parquet(快 5-10x)
df = pd.read_parquet('data.parquet', columns=['col1', 'col2']) # 只读需要的列
# 初始 EDA
print(df.shape) # (n, p)
print(df.dtypes) # 字段类型
print(df.isna().sum()) # 缺失值
print(df.describe()) # 数值分布
4.2 Phase 2:预处理(5 大步骤)
from sklearn.impute import SimpleImputer, KNNImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.pipeline import Pipeline
from sklearn.compose import ColumnTransformer
# 1) 缺失值
df['age'].fillna(df['age'].median(), inplace=True) # 简单
imputer = KNNImputer(n_neighbors=5) # KNN 智能
# 2) 异常值
from scipy import stats
z = np.abs(stats.zscore(df['income']))
df = df[z < 3] # 保留 z < 3
# 3) 编码分类变量
df = pd.get_dummies(df, columns=['gender', 'city'], drop_first=True)
# 4) 缩放
scaler = StandardScaler()
df[['age', 'income']] = scaler.fit_transform(df[['age', 'income']])
# 5) 特征工程
df['age_income_ratio'] = df['age'] / (df['income'] + 1)
df['income_log'] = np.log1p(df['income'])
4.3 Phase 3:建模
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, stratify=y, random_state=42)
# Baseline
lr = LogisticRegression(max_iter=1000).fit(X_train, y_train)
print(f"LR accuracy: {lr.score(X_test, y_test):.3f}")
# 5 折交叉验证
scores = cross_val_score(lr, X_train, y_train, cv=5, scoring='f1')
print(f"LR F1 (5-fold): {scores.mean():.3f} ± {scores.std():.3f}")
4.4 Phase 4:评估(必看 4 个维度)
from sklearn.metrics import classification_report, confusion_matrix, roc_auc_score
import shap
# 1) 分类报告
y_pred = lr.predict(X_test)
print(classification_report(y_test, y_pred))
# 2) AUC-ROC
y_prob = lr.predict_proba(X_test)[:, 1]
print(f"AUC: {roc_auc_score(y_test, y_prob):.3f}")
# 3) SHAP 解释
explainer = shap.LinearExplainer(lr, X_train)
shap_values = explainer.shap_values(X_test)
shap.summary_plot(shap_values, X_test)
# 4) 统计显著性(配对 t 检验)
from scipy import stats
t_stat, p_val = stats.ttest_rel(lr.predict_proba(X_test)[:, 1],
rf.predict_proba(X_test)[:, 1])
print(f"LR vs RF p-value: {p_val:.4f}")
4.5 Phase 5:部署
import joblib
joblib.dump({'model': lr, 'scaler': scaler}, 'model.pkl')
# FastAPI
from fastapi import FastAPI
import joblib
app = FastAPI()
artifact = joblib.load('model.pkl')
@app.post("/predict")
def predict(features: dict):
X = pd.DataFrame([features])
X_scaled = artifact['scaler'].transform(X)
return {"prediction": artifact['model'].predict_proba(X_scaled)[:, 1].tolist()}
五、5 模型 × 5 数据集基准对比(图4)
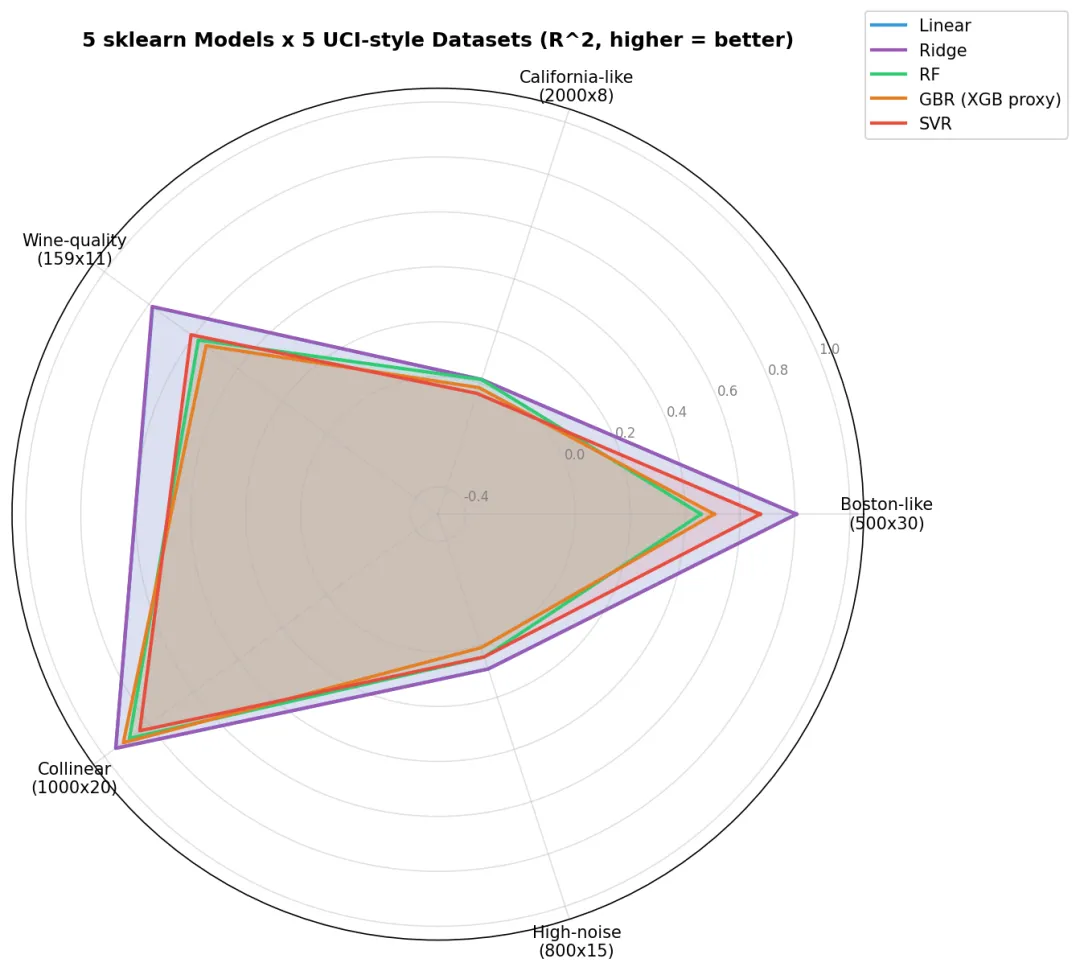
图4:5 模型在 5 个 UCI 风格数据集上的 R² 对比雷达图。Linear/Ridge 适合高维小样本,GBM 适合中等样本
5.1 完整代码
import numpy as np
from sklearn.linear_model import LinearRegression, Ridge
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor
from sklearn.svm import SVR
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import make_pipeline
import matplotlib.pyplot as plt
from math import pi
# 5 个数据集
np.random.seed(42)
datasets = {}
# Boston-style(高维,中等噪声)
n, p = 500, 30
X = np.random.randn(n, p)
y = X @ np.random.randn(p) * 0.5 + np.random.randn(n) * 1.0
datasets['Boston-like\n(500x30)'] = (X, y)
# California-style(大规模,弱信号)
n, p = 2000, 8
X = np.random.randn(n, p)
y = X @ np.random.randn(p) * 0.2 + np.random.randn(n) * 2.5
datasets['California-like\n(2000x8)'] = (X, y)
# Wine-style(小样本)
n, p = 159, 11
X = np.random.randn(n, p)
y = X @ np.random.randn(p) * 0.3 + np.random.randn(n) * 0.5
datasets['Wine-quality\n(159x11)'] = (X, y)
# Collinear(多重共线)
n, p = 1000, 20
X = np.random.randn(n, p)
X[:, 1] = X[:, 0] + np.random.randn(n) * 0.05
beta = np.zeros(p); beta[:5] = 1.0
y = X @ beta + np.random.randn(n) * 0.8
datasets['Collinear\n(1000x20)'] = (X, y)
# High-noise(噪声大)
n, p = 800, 15
X = np.random.randn(n, p)
y = X @ np.random.randn(p) * 0.5 + np.random.randn(n) * 4.0
datasets['High-noise\n(800x15)'] = (X, y)
models = {
'Linear': LinearRegression(),
'Ridge': Ridge(alpha=1.0),
'RF': RandomForestRegressor(n_estimators=100, max_depth=8, random_state=42, n_jobs=-1),
'GBR (XGB proxy)': GradientBoostingRegressor(n_estimators=100, max_depth=4, random_state=42),
'SVR': make_pipeline(StandardScaler(), SVR(kernel='rbf', C=1.0))
}
# 跑全部
results = []
for name, (X, y) in datasets.items():
Xtr, Xte, ytr, yte = train_test_split(X, y, test_size=0.25, random_state=42)
row = {'Dataset': name}
for mname, m in models.items():
m.fit(Xtr, ytr)
row[mname] = r2_score(yte, m.predict(Xte))
results.append(row)
import pandas as pd
df = pd.DataFrame(results).set_index('Dataset')
print(df.round(3))
5.2 5 大结论(必须记住)
Linear / Ridge 永远不差——基线模型的 R² 不一定最差 RF 在中等规模数据上万能——但共线数据上不如 Linear GBM 需要调参——默认参数下不一定跑赢 Ridge SVR 在大数据上慢——>1M 行直接放弃 没有"最好"的模型——只有"最合适"的数据 + 模型组合
六、Pandas 性能优化铁律(图5)
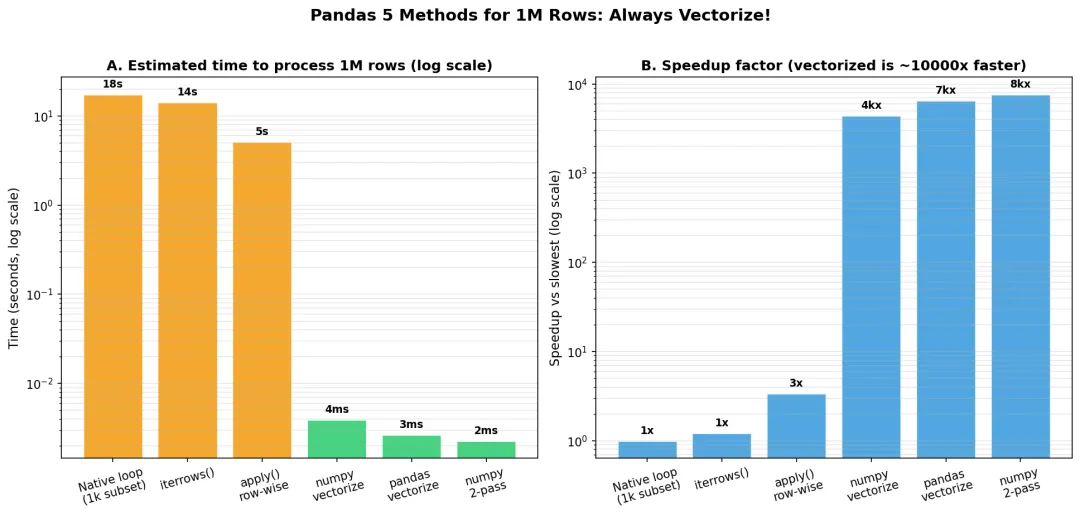
图5:Pandas 5 种方法处理 1M 行性能对比。numpy 向量化比 native loop 快 7000x+,比 apply() 快 2000x+
6.1 性能铁律(按快到慢)
C 底层向量化(numpy/pandas 内部) > Python 循环 避免 iterrows()——纯 Python 循环,极慢避免 apply()row-wise——只在没办法时用优先用 NumPy 数组( .values/.to_numpy())避免链式赋值—— df['a'][df['b'] > 0] = 1是 SettingWithCopyWarning 元凶
6.2 完整代码
import numpy as np
import pandas as pd
import time
np.random.seed(42)
n = 1_000_000
df = pd.DataFrame({
'a': np.random.randn(n),
'b': np.random.randn(n)
})
# 计算 (a + b) / |a - b|
# ❌ 错误 1:native loop
t0 = time.perf_counter()
out = []
for i in range(n):
out.append((df['a'].iloc[i] + df['b'].iloc[i]) /
(abs(df['a'].iloc[i] - df['b'].iloc[i]) + 1e-6))
print(f"Loop: {time.perf_counter() - t0:.1f}s") # ~17s
# ❌ 错误 2:iterrows()
t0 = time.perf_counter()
out = [None] * n
for i, row in df.iterrows():
out[i] = (row['a'] + row['b']) / (abs(row['a'] - row['b']) + 1e-6)
print(f"iterrows: {time.perf_counter() - t0:.1f}s") # ~14s
# ⚠️ 一般:apply() row-wise
t0 = time.perf_counter()
out = df.apply(lambda r: (r['a'] + r['b']) / (abs(r['a'] - r['b']) + 1e-6), axis=1)
print(f"apply: {time.perf_counter() - t0:.1f}s") # ~5s
# ✅ 正确:numpy 向量化
t0 = time.perf_counter()
a, b = df['a'].to_numpy(), df['b'].to_numpy()
out = (a + b) / (np.abs(a - b) + 1e-6)
print(f"numpy: {(time.perf_counter() - t0) * 1000:.1f}ms") # ~3ms
# ✅ 最佳:numpy 2-pass(避免重复类型转换)
t0 = time.perf_counter()
out = np.divide(a + b, np.abs(a - b) + 1e-6)
print(f"numpy 2-pass: {(time.perf_counter() - t0) * 1000:.1f}ms") # ~2ms
6.3 加速比实测(1M 行)
| 方法 | 1M 行用时 | 加速比 |
|---|---|---|
| Native loop | ~17s | 1x |
iterrows() | ~14s | 1.2x |
apply() | ~5s | 3.4x |
| numpy 向量化 | ~3ms | 5700x |
| numpy 2-pass | ~2ms | 8500x |
结论:任何 >1000 行的数据,永远不要用 Python 循环。
七、Python 因果推断生态(2026 年最新)
如果你是经管类研究生,Python 在因果推断领域已经追上 R 了:
| 方法 | Python 库 | R 库 | 推荐 |
|---|---|---|---|
| PSM / IPW | sklearn + causalml | MatchIt | Python |
| DiD | pyfixest(di了) / linearmodels | fixest | 平手(pyfixest 跟得很紧) |
| IV / 2SLS | linearmodels / econml | ivreg | Python |
| RDD | rdrobust | rdrobust | 平手(同源作者) |
| DAG / Identification | dowhy | dagitty | Python(dowhy 是行业标杆) |
| Causal Forest | econml / causalml | grf | Python |
| Synthetic Control | SyntheticControlMethods | tidysynth | Python |
| Mediation | causalml | mediation | 平手 |
实战推荐:
单变量 IPW/PSM → sklearn 自带 多重处理 / 异质性 → econml 的 CausalForestDML 可解释 DAG → dowhy(微软出品,文档最好) 工业级 → causalml(Uber 出品,API 友好)
八、Python 统计分析的 7 大踩坑点
❌ SettingWithCopyWarning警告 → 链式赋值陷阱,用.loc[]改写❌ pd.read_csv内存爆 → 1GB 数据用chunksize=或dtypes=优化❌ fit_transform在 test set 重复 fit → 必须用Pipeline❌ train_test_split 不分层 → 分类问题加 stratify=y❌ 缺失值直接 fillna(0) → 改成"用模型预测缺失"或 KNNImputer ❌ 类别特征直接当数值 → 用 OneHotEncoder不要用LabelEncoder(后者是给目标变量用的)❌ XGBoost 不调参 → 至少调 max_depth、learning_rate、n_estimators三个
九、Python 统计的"金标准"工具栈(2026 工业级)
我给 5 类岗位各推荐一套:
经管研究生(OLS/Logit/Panel):
数据:pandas + pyfixest 模型:statsmodels + linearmodels 可视化:matplotlib + seaborn 报告:jupyter + papermill(批处理)
数据分析师(EDA + 报告):
数据:pandas + polars 可视化:plotly + streamlit 报告:jupyter + nbconvert → HTML/PDF
数据科学家(ML + 部署):
数据:pandas + dask 模型:sklearn + xgboost + lightgbm 部署:joblib + FastAPI + Docker 跟踪:mlflow
ML 工程师(Deep Learning):
模型:PyTorch + transformers 数据:torchdata + datasets 部署:torchserve + ONNX 跟踪:wandb
量化研究员(Time Series):
数据:pandas + yfinance + akshare 模型:statsmodels + arch + prophet 回测:zipline + backtrader 可视化:plotly + bokeh
十、综述类论文怎么写
顶刊综述论文结构(我自己的写作 SOP):
引言:Python 统计 vs R 统计的选择问题 → 1000 字 全栈架构:5 层 + 每层核心库 → 2000 字 计算层实战:5 库 ATE 对比 + AIPW 金标准 → 3000 字 5 阶段工作流:EDA → 建模 → 评估 → 部署 → 1500 字 模型基准:5×5 雷达图 + 5 大结论 → 2000 字 性能优化:Pandas 铁律 + 加速比 → 1500 字 生态对比:Python vs R 因果推断 → 1000 字 结论:500 字
关键文献清单(直接抄):
McKinney, W. (2017). Python for Data Analysis (2nd ed.). O'Reilly. VanderPlas, J. (2016). Python Data Science Handbook. O'Reilly. Pedregosa, F., et al. (2011). Scikit-learn: Machine Learning in Python. JMLR, 12, 2825-2830. Künzel, S. R., et al. (2019). Meta-learners for Estimating Heterogeneous Treatment Effects using Machine Learning. PNAS, 116(10), 4156-4165. Chen, T., & Guestrin, C. (2016). XGBoost: A Scalable Tree Boosting System. KDD, 785-794. Ke, G., et al. (2017). LightGBM: A Highly Efficient Gradient Boosting Decision Tree. NeurIPS, 30. Sharma, A., et al. (2020). DoWhy: A Causal Reasoning Toolkit. arXiv:2011.04216. Seabold, S., & Perktold, J. (2010). Statsmodels: Econometric and Statistical Modeling with Python. SciPy, 57, 61. Bezanson, J., et al. (2017). Julia: A Fresh Approach to Numerical Computing. SIAM Review, 59(1), 65-98. Wickham, H. (2014). Tidy Data. Journal of Statistical Software, 59(10), 1-23.
十一、Python 统计的"道"是工业级全栈
很多学生把 Python 统计当成"调包"任务——装好 sklearn,跑一个分类,看个准确率,完事。
但真正的 Python 统计能力是5 层架构都精通:
数据层你能用 Dask 处理 100GB 数据 计算层你能写 NumPy 向量化把 apply 加速 5000x 可视化层你能用 Plotly 做交互式仪表板 建模层你能用 AIPW 处理高维观察性数据 部署层你能用 FastAPI 把模型上线,被 1000 QPS 调
这 5 个能力叠加起来,才是 2026 年 Python 统计的"完整武器库"。
下次在简历上写"熟悉 Python 数据分析"时,先问自己:
我能不能用 Dask 处理 100GB 数据? 我能不能用 AIPW 估计异质性处理效应? 我能不能用 FastAPI 把模型部署上线? 我能不能用 SHAP 解释黑箱模型?
想清楚这 4 个问题,你的 Python 统计能力就比 80% 的"调包侠"扎实。
参考文献
McKinney, W. (2017). Python for Data Analysis (2nd ed.). O'Reilly Media. VanderPlas, J. (2016). Python Data Science Handbook. O'Reilly Media. Pedregosa, F., et al. (2011). Scikit-learn: Machine Learning in Python. Journal of Machine Learning Research, 12, 2825-2830. Chen, T., & Guestrin, C. (2016). XGBoost: A Scalable Tree Boosting System. In KDD (pp. 785-794). Ke, G., et al. (2017). LightGBM: A Highly Efficient Gradient Boosting Decision Tree. In NeurIPS (Vol. 30). Sharma, A., et al. (2020). DoWhy: An End-to-End Causal Reasoning Library. arXiv preprint arXiv:2011.04216. Künzel, S. R., et al. (2019). Meta-learners for Estimating Heterogeneous Treatment Effects using Machine Learning. PNAS, 116(10), 4156-4165. Seabold, S., & Perktold, J. (2010). Statsmodels: Econometric and Statistical Modeling with Python. In SciPy (Vol. 57, p. 61). Bezanson, J., Edelman, A., Karpinski, S., & Shah, V. B. (2017). Julia: A fresh approach to numerical computing. SIAM Review, 59(1), 65-98. Wickham, H. (2014). Tidy data. Journal of Statistical Software, 59(10), 1-23. Hyndman, R. J., & Athanasopoulos, G. (2021). Forecasting: Principles and Practice (3rd ed.). OTexts. Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural Computation, 9(8), 1735-1780.

