Python学习【196】:大数据时代是怎么来的?本文带你理清IT技术演进史
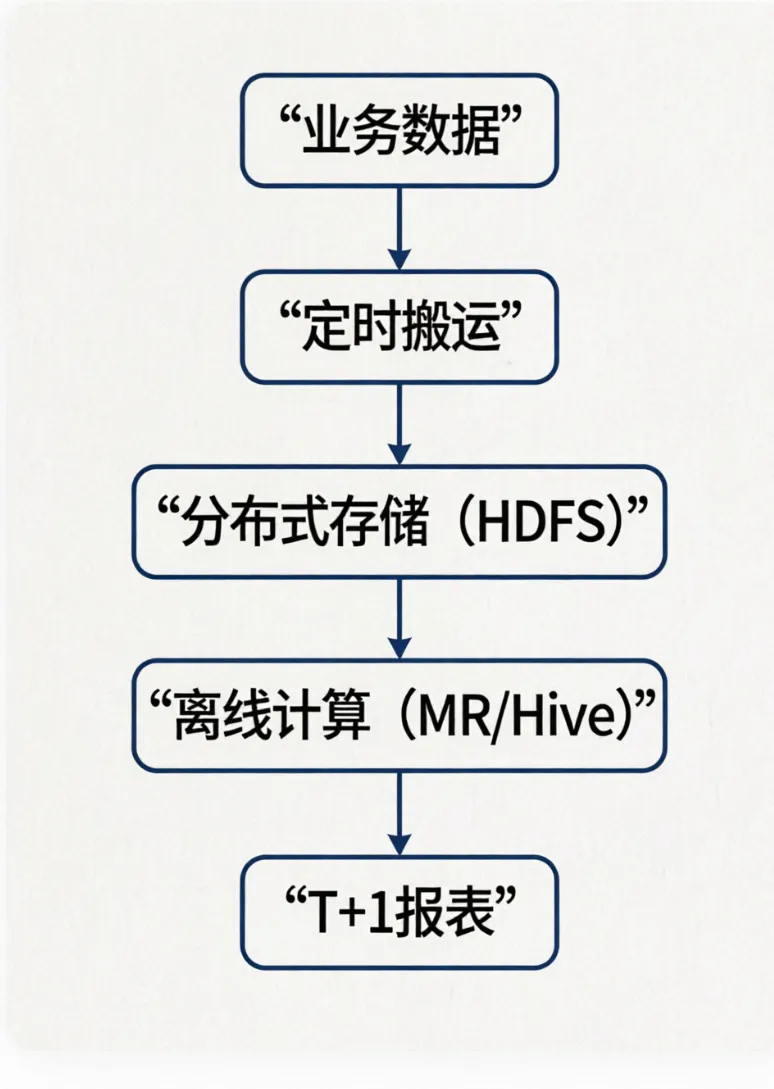
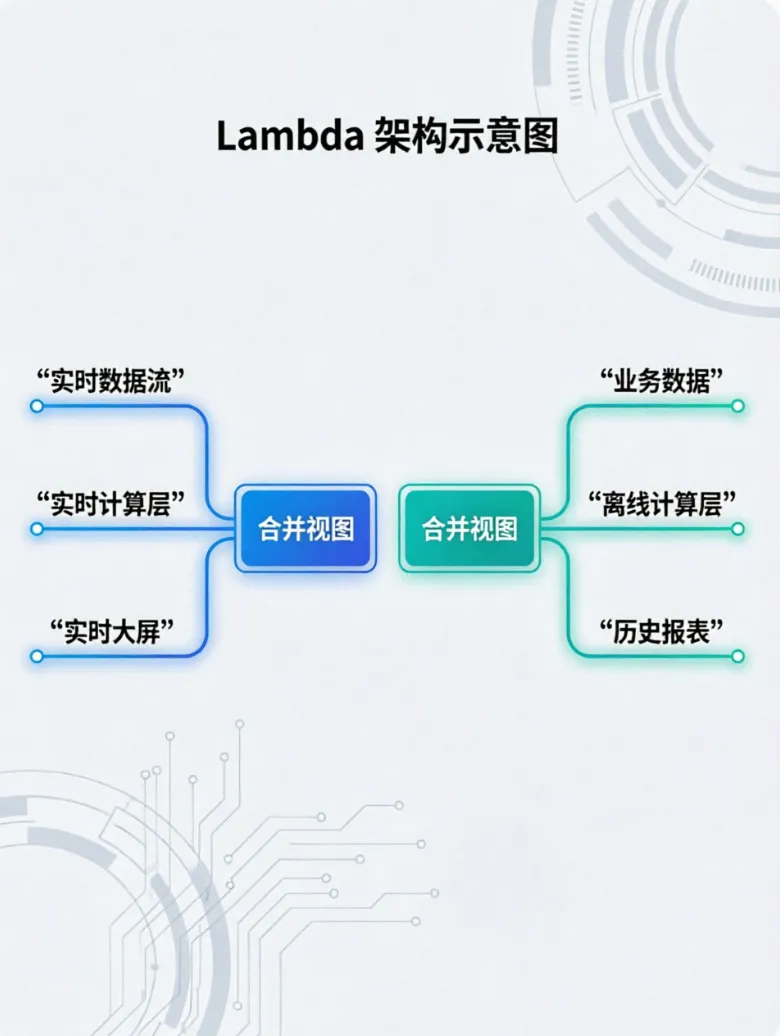
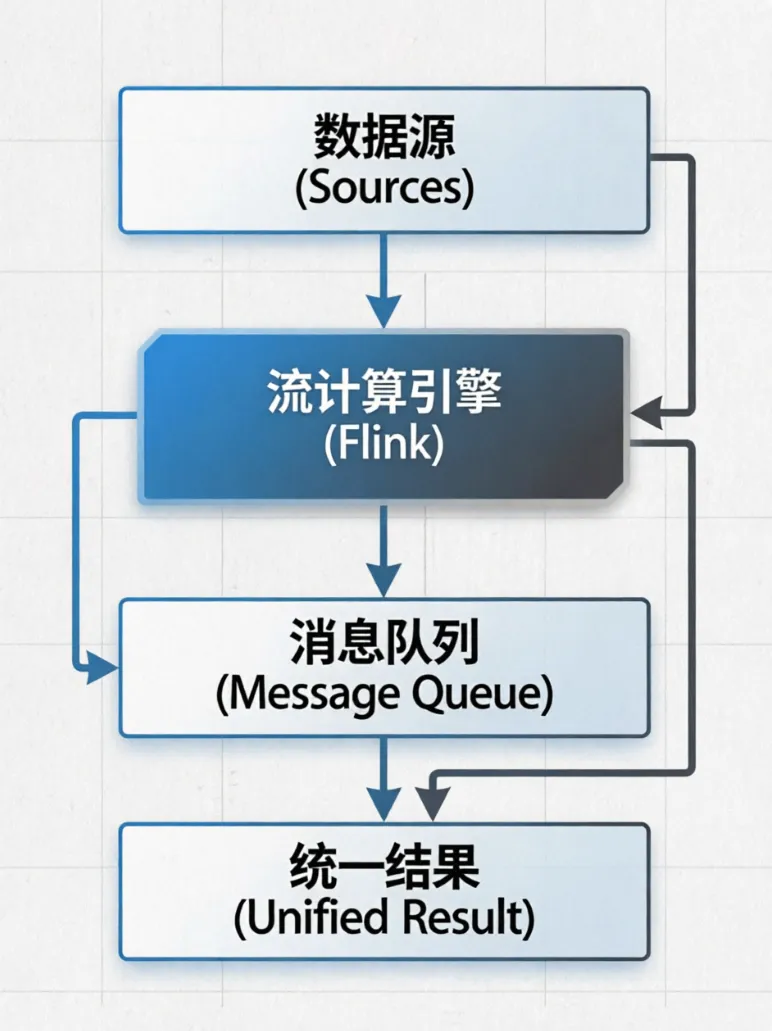
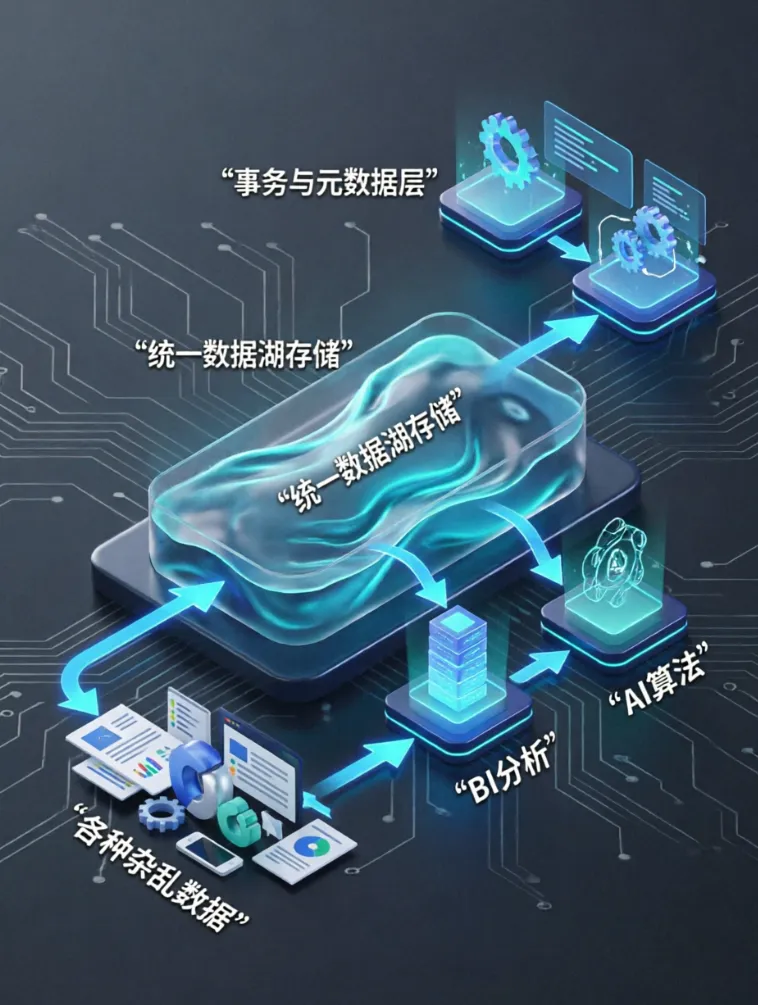
过去,企业处理数据全靠昂贵的小型机,不仅笨重,而且一旦数据量大,系统就卡死。直到2004年前后,谷歌的几篇技术文章横空出世,彻底打破了这种僵局。它们告诉全世界:用一堆便宜的普通电脑连在一起,就能搞定海量数据。这直接开启了今天的大数据时代。第一阶段(2004年-2013年):离线批处理时代以哈杜普(Hadoop)为代表,它把海量数据拆成小块,分给几百台普通电脑同时算。这解决了“存不下、算不动”的问题,但缺点是太慢,一份报告往往要等几个小时甚至第二天才能出来。核心特点:纯批处理,像工厂流水线一样每天定时开工,主打稳定,但毫无实时性可言。第二阶段(2013年-2017年):批流双链路时代随着业务要求变快,大家发现纯离线处理不够用了。于是“拉姆达(Lambda)架构”应运而生。它搞了两套系统:一套用来算历史数据,另一套用来算实时数据。虽然兼顾了实时性,但企业得维护两套代码,既费时又费力,还容易出错。核心特点:为了快,硬生生修了两条路(批处理和流处理),导致代码写两遍,数据容易对不上。第三阶段(2017年-2020年):全流式计算时代为了简化复杂的架构,斯帕克(Spark)和弗林克(Flink)等内存计算引擎登场。它们把数据放在内存里算,速度提升了上百倍。系统不仅能快速出报表,还能做到秒级甚至毫秒级的实时响应,比如双十一的实时交易大屏。核心特点:把一切都当成“水流”。历史数据也可以像水流一样重新回放计算,一套代码走天下,开发效率大幅提升。以前,存原始数据的“数据湖”和存整理后数据的“数据仓库”是分开的,导致数据来回搬运,很容易变成没人管的“数据沼泽”。现在的“湖仓一体”把两者合二为一,既能低成本存下各种乱七八糟的原始数据,又能像查账本一样快速、精准地分析。同时,大数据平台搬到了云端,资源可以像用水用电一样按需弹性伸缩。核心特点:打破了“湖”和“仓”的边界。底层像湖一样便宜且包容万物,上层像仓库一样严谨高效,是目前最主流的终极形态。回顾这段历程,大数据处理的核心其实非常朴素:它就是为了应对海量、复杂的数据需求,用“多节点分布式计算和存储”的优势,彻底替代了过去那种昂贵、笨重的小型机模式。从最初的“把数据算出来”,到后来的“把数据算得快”,再到现在的“让数据自己会思考”,大数据平台的每一次进化,都在让数据变得更有价值。让我们保持学习的热情,2026年一马当先、马到成功!








 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
