【生信分析】Python-4.序列特征识别:基于隐马尔可夫模型(HMM)的序列特征识别
- 2026-07-02 16:26:18

基于隐马尔可夫模型(Hidden Markov Model, HMM)
的序列特征识别


基于隐马尔可夫模型(Hidden Markov Model, HMM)的序列特征识别,是一种经典的统计模式识别方法。它的核心思想是:认为我们观测到的序列数据(如语音、文本、基因)是由一个我们无法直接看到的“隐藏状态”序列生成的。
🎯 核心概念:双重随机过程
HMM之所以强大,在于它巧妙地构建了一个“双重随机过程”:
1. 隐藏的马尔可夫链:系统内部存在一系列“隐藏状态”(如语音中的音素、基因中的编码区),这些状态之间的转移遵循马尔可夫性质,即下一个状态只依赖于当前状态。这个转移过程是随机的,但我们看不到。
2. 可观测的发射过程:每个隐藏状态会按照一定的概率分布,“发射”或生成一个我们实际能观测到的符号(如声波特征、文本单词、碱基序列)。
简单来说,HMM要解决的问题就是:仅凭我们能看到的“结果”(观测序列),去推断产生这个结果的“原因”(隐藏状态序列)。
🧠 三个核心问题与算法
HMM的应用围绕三个核心问题展开,每个问题都有其经典算法:
评估问题(Evaluation):给定模型参数和一个观测序列,计算这个序列出现的概率。常用于模式识别,例如在语音识别中,为每个词建立一个HMM,然后看哪个模型产生当前语音的概率最大。核心算法是前向-后向算法。
解码问题(Decoding):给定模型参数和观测序列,找出最有可能产生它的那个隐藏状态序列。这是序列标注的核心,如词性标注、基因预测。核心算法是维特比算法(Viterbi Algorithm)。
学习问题(Learning):在只有观测序列的情况下,如何估计模型的参数(状态转移概率、发射概率)。这是一个无监督学习过程。核心算法是鲍姆-韦尔奇算法(Baum-Welch Algorithm)。
🌐 主要应用领域
HMM在需要处理时序或序列数据的领域有广泛应用:
语音识别:作为早期最成功的核心算法之一,将语音信号识别为文字。
生物信息学:识别基因序列中的编码区(外显子)、预测蛋白质家族。
自然语言处理:进行词性标注、命名实体识别等序列标注任务。
行为与动作识别:识别人体行为、手写识别和人脸特征标注。
其他领域:金融市场的状态检测、雷达目标识别等。
✨ HMM的优势与局限
优势
可解释性强:模型参数(转移概率、发射概率)都有明确的概率意义,结果易于理解。
处理变长序列:天然支持不同长度的序列数据。
数据效率高:在小数据集上表现良好,且能自然地处理缺失数据。
局限
马尔可夫假设:假设当前状态只依赖于前一个状态,可能无法捕捉长距离的依赖关系。
需要领域知识:模型设计(如状态数)需要一定的先验知识。
表达能力有限:隐藏状态的表示能力有限,可能不如深度模型。
🛠️ Python工具与资源
`hmmlearn`:专注于HMM的经典库,实现了多种HMM变体。
`Sequentia`:提供了与`scikit-learn`接口兼容的HMM和动态时间规整(DTW)算法。
`pomegranate`:一个更全面的概率模型库,也包含了HMM的实现。
💎 总结
基于隐马尔可夫模型的序列特征识别,其核心在于用可观测的序列去推断背后隐藏的状态序列。通过其配套的三个经典算法,它能优雅地解决模式识别、序列标注等任务。尽管在一些领域面临深度学习的挑战,但其高可解释性和在小型数据集上的高效性,使其在需要透明决策的领域(如生物信息学、金融分析)仍然是重要的工具。
如果你想针对某个具体应用场景(如基因识别、词性标注)深入了解,我可以为你提供更详细的说明。

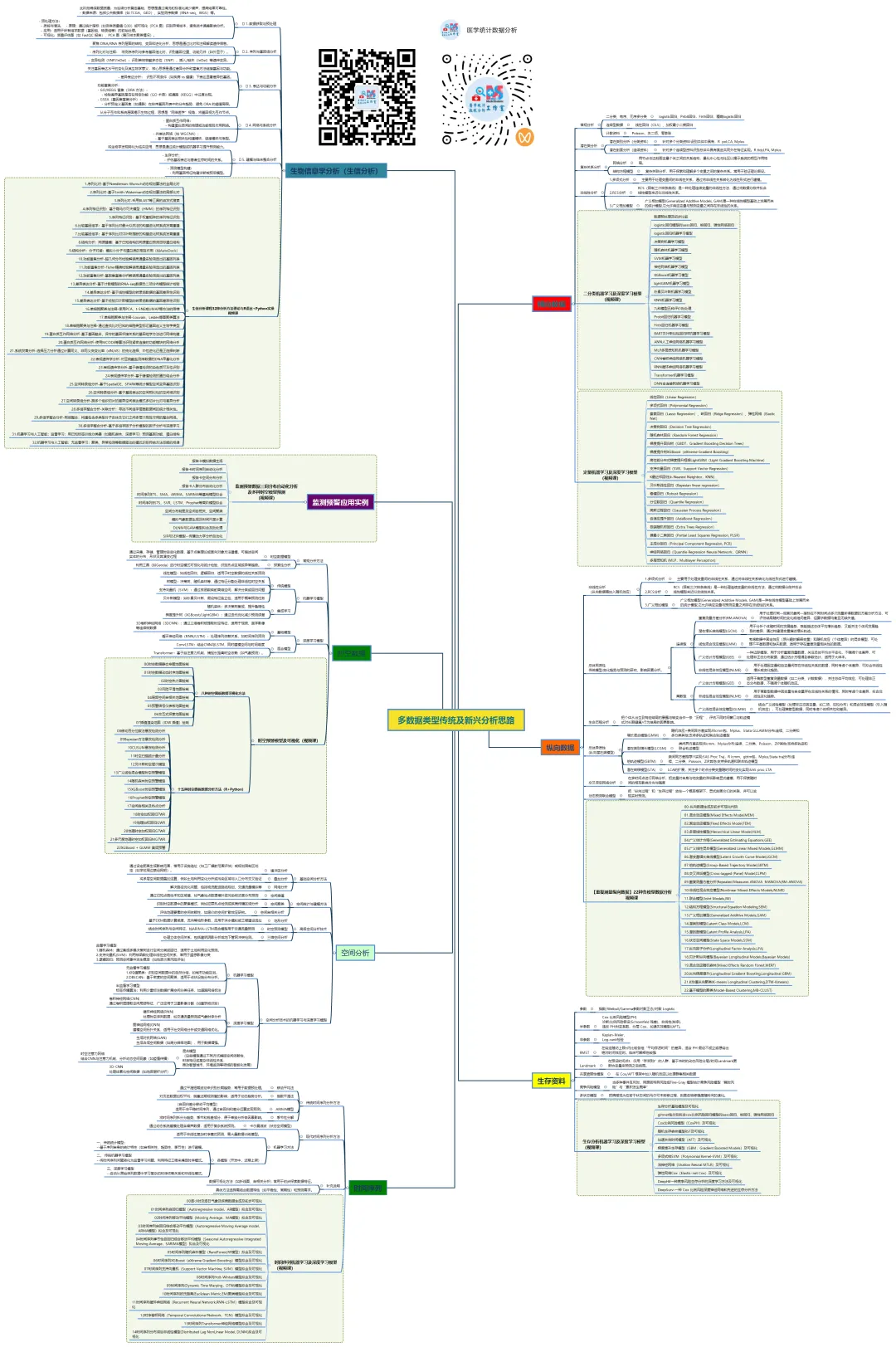
生物信息学分析(生信分析)是结合生物学、计算机科学和统计学,对生物数据进行处理、挖掘和解释的多学科领域。其核心思想是通过计算手段从海量数据(如基因组、转录组、蛋白质组数据)中提取生物学洞见,从而解决疾病机制、基因功能、进化关系等问题。
4. 序列特征识别:基于隐马尔可夫模型(HMM)的序列特征识别
概念:利用HMM这一概率模型来描述具有特定模式的序列家族(如蛋白质结构域家族),并用它来识别新序列中是否包含该特征。
原理:HMM包含一系列“状态”(如匹配、插入、删除),以及状态间转移的概率和每个状态下产生特定氨基酸/碱基的概率。通过训练(如使用多序列比对)得到一个家族的HMM模型后,可通过维特比算法或前向算法计算一条新序列由该模型生成的概率,从而判断其是否属于该家族。
思想:一个序列家族的成员在进化中保持着核心的模式和可变的区域。HMM能优雅地刻画这种保守与变异并存的概率特征,是识别远程同源序列的强大工具。
应用:Pfam、TIGRFAM等蛋白质结构域数据库的构建与搜索;非编码RNA家族识别;基因预测。
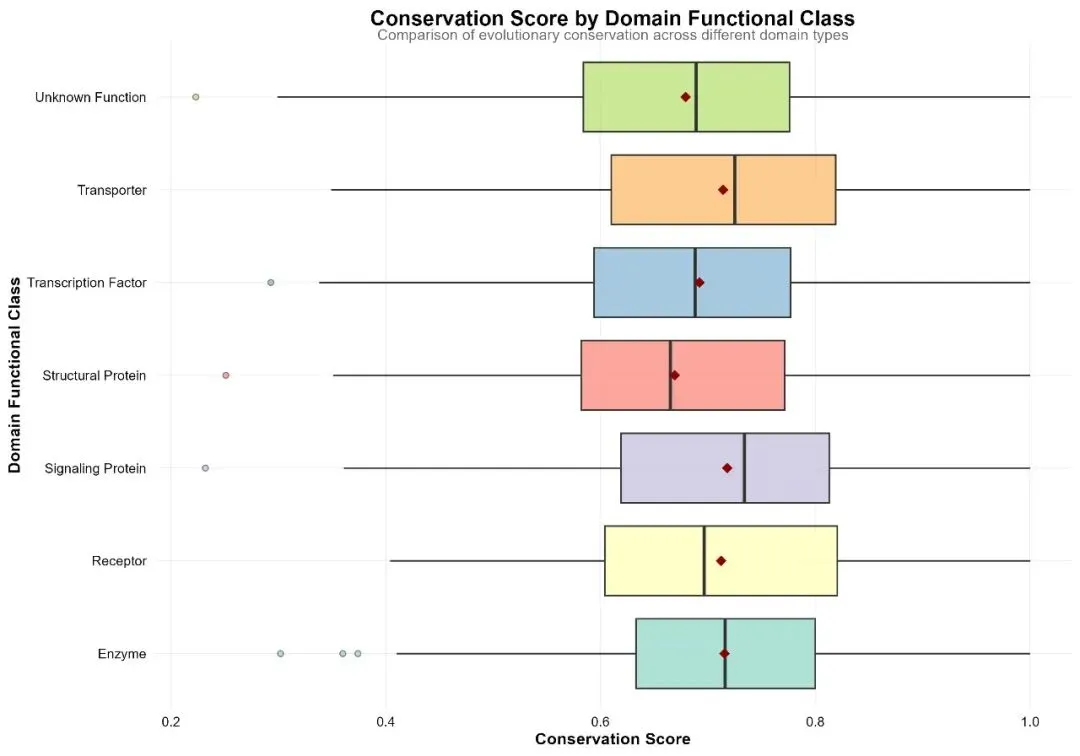
可视化方法:HMMER等工具的输出包含序列与模型匹配的示意图,显示匹配域的位置和置信度(E值)。也可用序列标识图展示HMM模型本身的保守位点。

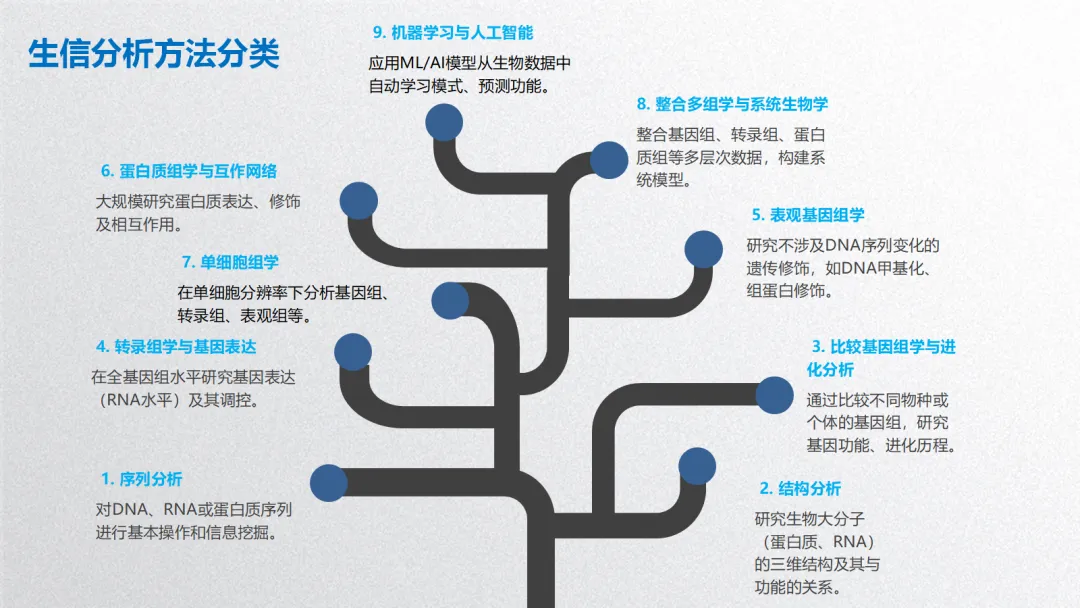
生信分析可按照分析目的和数据层次分为以下几个主要方面:
1. 序列分析
2. 结构分析
3. 比较基因组学与进化分析
4. 转录组学与基因表达分析
5. 表观基因组学
6. 蛋白质组学与互作网络
7. 单细胞组学
8. 整合多组学与系统生物学
9. 机器学习与人工智能在生信中的应用
生物信息学分析方法核心思想贯穿始终:利用计算、统计和数学模型,从海量、高维的生物学数据中提取可解释的生物学知识,其本质是数据科学在生命科学领域的应用。以下基于常见研究流程,将生信分析方法分为 5 个主要方面,并详细介绍各类方法的概念、原理、思想、应用及可视化方式。
# # 安装必要的Python包# pip install numpy pandas scikit-learn matplotlib seaborn openpyxl python-docx joblib plotly scipy statsmodels tqdm pillow# ============================================================================# HMM序列特征识别分析流程:模拟数据、分析建模、可视化与报告生成# Python版本:3.12# 结果保存到:桌面04_HR-Results文件夹# ============================================================================import osimport sysimport numpy as npimport pandas as pdimport warningsimport randomfrom datetime import datetimefrom pathlib import Pathimport jsonfrom typing import Dict, List, Tuple, Optional# 设置随机种子np.random.seed(12345)random.seed(12345)warnings.filterwarnings('ignore')# 1. 初始化设置 ----------------------------------------------------------------print("=" * 70)print("HMM序列特征识别分析流程")print("=" * 70)# 设置工作目录为桌面desktop_path = Path.home() / "Desktop"os.chdir(desktop_path)# 创建结果文件夹结构results_dir = Path("04_HR-Results")sub_dirs = ["data", "tables", "figures", "models", "reports"]for sub_dir in sub_dirs: (results_dir / sub_dir).mkdir(parents=True, exist_ok=True)print(f"✓ 结果文件夹已创建: {results_dir.absolute()}")# 2. 导入必要的包 -------------------------------------------------------------print("\n=== 加载必要的Python包 ===")# 检查并安装缺失的包(注释掉,实际运行时需要确保已安装)required_packages = ["numpy", "pandas", "scipy", "scikit-learn", "statsmodels","matplotlib", "seaborn", "plotly", "openpyxl", "python-docx","joblib", "tqdm", "pillow"]# 这里不自动安装,需要用户自行安装import numpy as npimport pandas as pdfrom scipy import statsimport scipy.stats as scipy_statsfrom sklearn.model_selection import train_test_splitfrom sklearn.linear_model import LinearRegressionfrom sklearn.ensemble import RandomForestClassifierfrom sklearn.metrics import (mean_squared_error, r2_score, mean_absolute_error, confusion_matrix, accuracy_score, classification_report)from sklearn.preprocessing import LabelEncoderimport matplotlib.pyplot as pltimport seaborn as snsimport matplotlibfrom matplotlib import rcParamsimport plotly.express as pximport plotly.graph_objects as gofrom plotly.subplots import make_subplotsfrom openpyxl import Workbookfrom openpyxl.styles import Font, Alignment, Border, Side, PatternFillfrom docx import Documentfrom docx.shared import Inches, Pt, RGBColorfrom docx.enum.text import WD_ALIGN_PARAGRAPHfrom docx.enum.table import WD_TABLE_ALIGNMENTimport joblibimport warningswarnings.filterwarnings('ignore')print("✓ 所有必要的包已加载")# 3. 模拟HMM序列特征识别结果数据生成 -------------------------------------------print("\n=== 生成模拟HMM序列特征识别数据 ===")def simulate_hmm_results(n=1000):"""模拟HMMER/Pfam搜索结果"""# 生成基础数据 query_ids = [f"Protein_{i:04d}"for i in range(1, n + 1)]# 生成结构域信息 domain_families = [f"PF{str(i).zfill(5)}"for i in range(1, 11)] domain_probs = [0.15, 0.12, 0.10, 0.08, 0.07, 0.06, 0.05, 0.04, 0.03, 0.30] domain_id = np.random.choice(domain_families, n, p=domain_probs)# 生成HMM统计指标# E值(指数分布) evalue_full = 10 ** (-np.random.uniform(0, 30, n)) evalue_domain = 10 ** (-np.random.uniform(0, 25, n))# 比特分数 score_full = np.round(50 + 40 * (-np.log10(evalue_full + 1e-300)) + np.random.normal(0, 10, n), 2) score_domain = np.round(30 + 30 * (-np.log10(evalue_domain + 1e-300)) + np.random.normal(0, 8, n), 2)# 偏差值 bias_full = np.round(np.random.normal(0.5, 0.8, n), 2) bias_domain = np.round(np.random.normal(0.3, 0.5, n), 2)# 结构域位置信息 query_length = np.random.choice(range(100, 501), n) domain_start = []for qlen in query_length: domain_start.append(np.random.randint(1, max(2, qlen - 50))) domain_end = []for i in range(n): end = min(domain_start[i] + np.random.choice(range(50, 201)), query_length[i]) domain_end.append(end) domain_start = np.array(domain_start) domain_end = np.array(domain_end) domain_length = domain_end - domain_start + 1# 生成序列特征指标# 保守性评分 conservation_score = np.round(np.random.normal(0.7, 0.15, n), 3) conservation_score = np.clip(conservation_score, 0.1, 1.0)# 熵值(衡量不确定性) entropy = np.round(np.random.normal(1.5, 0.5, n), 3)# 生成分类和功能信息 taxonomy = np.random.choice( ["Bacteria", "Archaea", "Eukaryota", "Virus"], n, p=[0.6, 0.1, 0.25, 0.05] )# 基于Pfam分类 domain_classes = ["Enzyme", "Receptor", "Transporter", "Transcription Factor","Structural Protein", "Signaling Protein", "Unknown Function" ] domain_class = np.random.choice(domain_classes, n)# 基于E值生成显著性标志 significant_prob = 1 / (1 + np.exp(-(2 * (-np.log10(evalue_full + 1e-300)) - 10))) significant = np.random.rand(n) < significant_prob# 生成进化保守性指标 evolutionary_conservation = np.round(np.random.beta(2, 1, n), 3)# 创建数据框 data = pd.DataFrame({'query_id': query_ids,'domain_id': domain_id,'evalue_full': evalue_full,'evalue_domain': evalue_domain,'score_full': score_full,'score_domain': score_domain,'bias_full': bias_full,'bias_domain': bias_domain,'query_length': query_length,'domain_start': domain_start,'domain_end': domain_end,'domain_length': domain_length,'conservation_score': conservation_score,'entropy': entropy,'evolutionary_conservation': evolutionary_conservation,'taxonomy': taxonomy,'domain_class': domain_class,'significant': significant })return data# 生成模拟数据hmm_data = simulate_hmm_results(1000)print(f"✓ 模拟数据生成完成,维度: {hmm_data.shape}")# 4. 数据预处理 ----------------------------------------------------------------print("\n=== 数据预处理 ===")print(f"原始数据维度: {hmm_data.shape}")# 计算衍生指标hmm_data['log_evalue_full'] = -np.log10(hmm_data['evalue_full'] + 1e-300)hmm_data['log_evalue_domain'] = -np.log10(hmm_data['evalue_domain'] + 1e-300)hmm_data['domain_coverage'] = np.round(hmm_data['domain_length'] / hmm_data['query_length'] * 100, 2)hmm_data['score_ratio'] = hmm_data['score_domain'] / hmm_data['score_full']hmm_data['evalue_ratio'] = hmm_data['evalue_domain'] / hmm_data['evalue_full']# 创建分类变量def categorize_significance(evalue):if evalue < 1e-30:return"Extremely Significant (<1e-30)"elif evalue < 1e-10:return"Highly Significant (1e-30 to 1e-10)"elif evalue < 1e-5:return"Significant (1e-10 to 1e-5)"elif evalue < 0.01:return"Moderate (1e-5 to 0.01)"else:return"Not Significant (≥0.01)"def categorize_domain_size(length):if length >= 200:return"Large Domain (≥200 aa)"elif length >= 100:return"Medium Domain (100-199 aa)"else:return"Small Domain (<100 aa)"def categorize_conservation(score):if score >= 0.8:return"Highly Conserved (≥0.8)"elif score >= 0.6:return"Moderately Conserved (0.6-0.79)"elif score >= 0.4:return"Poorly Conserved (0.4-0.59)"else:return"Variable (<0.4)"def categorize_hmm_quality(log_evalue, bias):if log_evalue > 15 and bias < 1.0:return"High Quality"elif log_evalue > 10 and bias < 2.0:return"Medium Quality"else:return"Low Quality"hmm_data['significance_category'] = hmm_data['evalue_full'].apply(categorize_significance)hmm_data['domain_size_category'] = hmm_data['domain_length'].apply(categorize_domain_size)hmm_data['conservation_category'] = hmm_data['conservation_score'].apply(categorize_conservation)hmm_data['hmm_quality'] = np.vectorize(categorize_hmm_quality)(hmm_data['log_evalue_full'], hmm_data['bias_full'])# 数据质量检查print("\n数据质量检查:")missing_summary = hmm_data.isnull().sum()if missing_summary.sum() == 0:print("✓ 无缺失值")else:print("存在缺失值的列:")print(missing_summary[missing_summary > 0])# 5. 描述性统计分析 ------------------------------------------------------------print("\n=== 描述性统计分析 ===")# 数值变量统计numeric_vars = ['score_full', 'score_domain', 'log_evalue_full', 'log_evalue_domain','domain_length', 'domain_coverage', 'conservation_score', 'entropy','evolutionary_conservation']desc_stats = pd.DataFrame({'variable': numeric_vars,'mean': [hmm_data[var].mean() for var in numeric_vars],'sd': [hmm_data[var].std() for var in numeric_vars],'min': [hmm_data[var].min() for var in numeric_vars],'max': [hmm_data[var].max() for var in numeric_vars],'median': [hmm_data[var].median() for var in numeric_vars],'n': [hmm_data[var].count() for var in numeric_vars]})desc_stats.iloc[:, 1:] = desc_stats.iloc[:, 1:].round(3)print("数值变量描述性统计:")print(desc_stats.to_string())# 分类变量统计category_stats = hmm_data.groupby('domain_class').agg( count=('domain_class', 'count'), avg_score=('score_full', 'mean'), avg_conservation=('conservation_score', 'mean'), significant_rate=('significant', 'mean')).reset_index()category_stats['percent'] = (category_stats['count'] / len(hmm_data) * 100).round(1)category_stats['avg_score'] = category_stats['avg_score'].round(2)category_stats['avg_conservation'] = category_stats['avg_conservation'].round(3)category_stats['significant_rate'] = (category_stats['significant_rate'] * 100).round(1)category_stats = category_stats[['domain_class', 'count', 'percent', 'avg_score','avg_conservation', 'significant_rate']]print("\n分类变量统计:")print(category_stats.to_string())# 6. 保存数据 ----------------------------------------------------------------print("\n=== 保存数据 ===")# 保存原始数据hmm_data.to_csv(results_dir / "data" / "hmm_raw_data.csv", index=False, encoding='utf-8')hmm_data.to_csv(results_dir / "data" / "hmm_processed_data.csv", index=False, encoding='utf-8')# 保存为pickle格式hmm_data.to_pickle(results_dir / "data" / "hmm_data.pkl")print(f"✓ 数据已保存到: {results_dir / 'data'}")# 7. 统计分析与建模 ------------------------------------------------------------print("\n=== 统计分析与建模 ===")# 7.1 相关性分析numeric_vars_corr = ['score_full', 'log_evalue_full', 'domain_length','domain_coverage', 'conservation_score', 'entropy','evolutionary_conservation']numeric_data = hmm_data[numeric_vars_corr].dropna()correlation_matrix = numeric_data.corr()print("相关性矩阵维度:", correlation_matrix.shape)# 7.2 线性回归模型:预测score_fullnp.random.seed(123)X = hmm_data[['log_evalue_full', 'domain_length', 'domain_coverage','conservation_score', 'entropy', 'evolutionary_conservation']]y = hmm_data['score_full']X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=123)lm_model = LinearRegression()lm_model.fit(X_train, y_train)# 模型评估y_pred = lm_model.predict(X_test)lm_performance = {'rmse': np.sqrt(mean_squared_error(y_test, y_pred)),'r_squared': r2_score(y_test, y_pred),'adj_r_squared': 1 - (1 - r2_score(y_test, y_pred)) * (len(y_test) - 1) / (len(y_test) - X_test.shape[1] - 1),'mae': mean_absolute_error(y_test, y_pred)}print("\n线性回归模型性能:")for key, value in lm_performance.items():print(f" {key}: {value:.4f}")# 7.3 分类模型:预测是否显著# 准备特征X_class = pd.get_dummies(hmm_data[['score_full', 'log_evalue_full', 'domain_coverage','conservation_score', 'evolutionary_conservation','domain_class']], drop_first=True)y_class = hmm_data['significant']X_train_c, X_test_c, y_train_c, y_test_c = train_test_split( X_class, y_class, test_size=0.3, random_state=123)# 随机森林模型rf_model = RandomForestClassifier( n_estimators=300, random_state=123, n_jobs=-1)rf_model.fit(X_train_c, y_train_c)# 模型预测y_pred_c = rf_model.predict(X_test_c)conf_matrix = confusion_matrix(y_test_c, y_pred_c)accuracy = accuracy_score(y_test_c, y_pred_c)print("\n随机森林模型性能:")print(f" 准确率: {accuracy:.4f}")print(f" 混淆矩阵:\n{conf_matrix}")print("\n分类报告:")print(classification_report(y_test_c, y_pred_c))# 7.4 保存模型joblib.dump(lm_model, results_dir / "models" / "linear_model.pkl")joblib.dump(rf_model, results_dir / "models" / "random_forest_model.pkl")np.save(results_dir / "models" / "confusion_matrix.npy", conf_matrix)print(f"✓ 模型已保存到: {results_dir / 'models'}")# 8. 可视化分析 ----------------------------------------------------------------print("\n=== 生成可视化图表 ===")# 设置可视化风格plt.style.use('default')matplotlib.rcParams.update({'figure.figsize': (10, 6),'font.size': 11,'axes.titlesize': 14,'axes.labelsize': 11,'xtick.labelsize': 9,'ytick.labelsize': 9,'legend.fontsize': 10,'figure.dpi': 300,'savefig.dpi': 300,})# 8.1 HMM得分分布fig1, ax1 = plt.subplots(figsize=(10, 7))for category in hmm_data['significance_category'].unique(): subset = hmm_data[hmm_data['significance_category'] == category] ax1.hist(subset['score_full'], bins=30, alpha=0.7, label=category, edgecolor='white', linewidth=0.5)ax1.set_title('Distribution of HMM Full Sequence Scores', fontweight='bold')ax1.set_xlabel('Full Sequence Score (bits)')ax1.set_ylabel('Count')ax1.legend(title='Significance Category')ax1.grid(True, alpha=0.3)# 8.2 E值分布(对数尺度)fig2, ax2 = plt.subplots(figsize=(10, 7))for category in hmm_data['significance_category'].unique(): subset = hmm_data[hmm_data['significance_category'] == category] ax2.hist(subset['log_evalue_full'], bins=40, alpha=0.7, label=category, edgecolor='white', linewidth=0.5)ax2.axvline(x=10, color='red', linestyle='--', linewidth=2, label='E-value = 1e-10')ax2.axvline(x=30, color='darkgreen', linestyle='--', linewidth=2, label='E-value = 1e-30')ax2.set_title('Distribution of E-values (-log10)', fontweight='bold')ax2.set_xlabel('-log10(E-value)')ax2.set_ylabel('Count')ax2.legend()ax2.grid(True, alpha=0.3)# 8.3 相关性热图fig3, ax3 = plt.subplots(figsize=(10, 8))sns.heatmap(correlation_matrix, annot=True, fmt='.2f', cmap='coolwarm', center=0, square=True, ax=ax3, cbar_kws={'shrink': 0.8})ax3.set_title('Correlation Matrix of HMM Metrics', fontweight='bold')# 8.4 结构域功能类别比较fig4, ax4 = plt.subplots(figsize=(12, 8))order = category_stats.sort_values('avg_conservation', ascending=False)['domain_class']sns.boxplot(data=hmm_data, x='conservation_score', y='domain_class', order=order, ax=ax4, palette='Set3')ax4.set_title('Conservation Score by Domain Functional Class', fontweight='bold')ax4.set_xlabel('Conservation Score')ax4.set_ylabel('Domain Functional Class')ax4.grid(True, alpha=0.3)# 8.5 线性模型诊断y_train_pred = lm_model.predict(X_train)residuals = y_train - y_train_predfig5, ax5 = plt.subplots(figsize=(10, 7))ax5.scatter(y_train_pred, residuals, alpha=0.6, s=50)ax5.axhline(y=0, color='red', linestyle='--', linewidth=2)ax5.set_title('Linear Model Residual Analysis', fontweight='bold')ax5.set_xlabel('Fitted Values')ax5.set_ylabel('Residuals')ax5.grid(True, alpha=0.3)# 8.6 随机森林特征重要性feature_importance = pd.DataFrame({'Feature': X_class.columns,'Importance': rf_model.feature_importances_}).sort_values('Importance', ascending=True)fig6, ax6 = plt.subplots(figsize=(10, 8))ax6.barh(feature_importance['Feature'], feature_importance['Importance'])ax6.set_title('Random Forest Feature Importance', fontweight='bold')ax6.set_xlabel('Mean Decrease Gini')ax6.grid(True, alpha=0.3)# 8.7 得分与E值关系(按显著性)fig7, ax7 = plt.subplots(figsize=(10, 7))scatter = ax7.scatter(hmm_data['score_full'], hmm_data['log_evalue_full'], c=hmm_data['significant'].map({True: '#2E8B57', False: '#CD5C5C'}), s=50, alpha=0.7, edgecolors='w', linewidth=0.5)ax7.axhline(y=10, color='red', linestyle='--', linewidth=2, alpha=0.7)ax7.set_title('HMM Score vs. Statistical Significance', fontweight='bold')ax7.set_xlabel('Full Sequence Score (bits)')ax7.set_ylabel('-log10(E-value)')# 创建图例from matplotlib.lines import Line2Dlegend_elements = [ Line2D([0], [0], marker='o', color='w', label='Significant', markerfacecolor='#2E8B57', markersize=10), Line2D([0], [0], marker='o', color='w', label='Not Significant', markerfacecolor='#CD5C5C', markersize=10)]ax7.legend(handles=legend_elements, title='Significant Match')ax7.grid(True, alpha=0.3)# 8.8 保守性与熵的关系fig8, ax8 = plt.subplots(figsize=(10, 7))scatter = ax8.scatter(hmm_data['conservation_score'], hmm_data['entropy'], c=pd.Categorical(hmm_data['conservation_category']).codes, cmap='Set2', s=50, alpha=0.7, edgecolors='w', linewidth=0.5)# 添加回归线z = np.polyfit(hmm_data['conservation_score'], hmm_data['entropy'], 1)p = np.poly1d(z)x_line = np.linspace(hmm_data['conservation_score'].min(), hmm_data['conservation_score'].max(), 100)ax8.plot(x_line, p(x_line), "r--", linewidth=2)ax8.set_title('Conservation Score vs. Sequence Entropy', fontweight='bold')ax8.set_xlabel('Conservation Score')ax8.set_ylabel('Sequence Entropy')ax8.grid(True, alpha=0.3)# 创建图例unique_categories = hmm_data['conservation_category'].unique()colors = plt.cm.Set2(np.linspace(0, 1, len(unique_categories)))legend_elements = [Line2D([0], [0], marker='o', color='w', label=cat, markerfacecolor=colors[i], markersize=10)for i, cat in enumerate(unique_categories)]ax8.legend(handles=legend_elements, title='Conservation Category', loc='upper right')# 9. 保存可视化图表 -----------------------------------------------------------print("\n=== 保存可视化图表 ===")# 保存所有图形figures = {'hmm_score_distribution': fig1,'evalue_distribution': fig2,'correlation_heatmap': fig3,'domain_class_comparison': fig4,'lm_residuals': fig5,'rf_feature_importance': fig6,'score_vs_significance': fig7,'conservation_vs_entropy': fig8}for name, fig in figures.items():# 保存为PNG fig.savefig(results_dir / "figures" / f"{name}.png", dpi=300, bbox_inches='tight', facecolor='white')# 保存为JPG fig.savefig(results_dir / "figures" / f"{name}.jpg", dpi=300, bbox_inches='tight', facecolor='white')# 保存为PDF fig.savefig(results_dir / "figures" / f"{name}.pdf", bbox_inches='tight')print(f" ✓ {name} (PNG, JPG, PDF)") plt.close(fig)# 创建组合图(简化版,显示主要图形)fig_combined, axes = plt.subplots(3, 2, figsize=(16, 18))# 子图1: 得分分布hmm_data['score_full'].hist(bins=30, ax=axes[0, 0], edgecolor='white')axes[0, 0].set_title('HMM Score Distribution')axes[0, 0].set_xlabel('Full Sequence Score (bits)')axes[0, 0].set_ylabel('Count')# 子图2: E值分布hmm_data['log_evalue_full'].hist(bins=40, ax=axes[0, 1], edgecolor='white')axes[0, 1].set_title('E-value Distribution (-log10)')axes[0, 1].set_xlabel('-log10(E-value)')axes[0, 1].set_ylabel('Count')# 子图3: 相关性热图sns.heatmap(correlation_matrix, annot=True, fmt='.2f', cmap='coolwarm', center=0, square=True, ax=axes[1, 0], cbar_kws={'shrink': 0.7})axes[1, 0].set_title('Correlation Matrix')# 子图4: 结构域类别比较sns.boxplot(data=hmm_data, x='conservation_score', y='domain_class', ax=axes[1, 1], palette='Set3')axes[1, 1].set_title('Conservation by Domain Class')axes[1, 1].set_xlabel('Conservation Score')axes[1, 1].set_ylabel('')# 子图5: 得分与E值关系axes[2, 0].scatter(hmm_data['score_full'], hmm_data['log_evalue_full'], c=hmm_data['significant'].map({True: 'green', False: 'red'}), alpha=0.6, s=20)axes[2, 0].axhline(y=10, color='red', linestyle='--', alpha=0.7)axes[2, 0].set_title('Score vs E-value')axes[2, 0].set_xlabel('Full Sequence Score (bits)')axes[2, 0].set_ylabel('-log10(E-value)')# 子图6: 保守性与熵axes[2, 1].scatter(hmm_data['conservation_score'], hmm_data['entropy'], alpha=0.6, s=20)z = np.polyfit(hmm_data['conservation_score'], hmm_data['entropy'], 1)p = np.poly1d(z)x_line = np.linspace(hmm_data['conservation_score'].min(), hmm_data['conservation_score'].max(), 100)axes[2, 1].plot(x_line, p(x_line), "r--")axes[2, 1].set_title('Conservation vs Entropy')axes[2, 1].set_xlabel('Conservation Score')axes[2, 1].set_ylabel('Sequence Entropy')plt.suptitle('Comprehensive Analysis of HMM Sequence Feature Recognition', fontsize=16, fontweight='bold', y=0.98)plt.figtext(0.5, 0.02, f'Analysis generated on {datetime.now().strftime("%Y-%m-%d")} | Python 3.12', ha='center', fontsize=10, style='italic')plt.tight_layout()fig_combined.savefig(results_dir / "figures" / "combined_analysis.png", dpi=300, bbox_inches='tight', facecolor='white')fig_combined.savefig(results_dir / "figures" / "combined_analysis.jpg", dpi=300, bbox_inches='tight', facecolor='white')fig_combined.savefig(results_dir / "figures" / "combined_analysis.pdf", bbox_inches='tight')plt.close(fig_combined)print(f"✓ 所有图表已保存到: {results_dir / 'figures'}")# 10. 生成Excel三线表 ---------------------------------------------------------print("\n=== 生成科研三线表 ===")# 创建Excel工作簿from openpyxl import Workbookfrom openpyxl.utils.dataframe import dataframe_to_rowswb = Workbook()ws1 = wb.activews1.title = "Raw_Data"# 写入原始数据for r in dataframe_to_rows(hmm_data, index=False, header=True): ws1.append(r)# 创建其他工作表ws2 = wb.create_sheet("Descriptive_Statistics")for r in dataframe_to_rows(desc_stats, index=False, header=True): ws2.append(r)ws3 = wb.create_sheet("Category_Statistics")for r in dataframe_to_rows(category_stats, index=False, header=True): ws3.append(r)# 模型性能表model_summary = pd.DataFrame({'Model': ['Linear Regression', 'Random Forest'],'Metric': ['R-squared', 'Accuracy'],'Value': [round(lm_performance['r_squared'], 3), round(accuracy, 3)],'Description': ['Variance explained in HMM score prediction','Accuracy in predicting significant HMM matches'],'RMSE': [round(lm_performance['rmse'], 2), np.nan]})ws4 = wb.create_sheet("Model_Performance")for r in dataframe_to_rows(model_summary, index=False, header=True): ws4.append(r)# 相关性矩阵表correlation_df = correlation_matrix.reset_index()ws5 = wb.create_sheet("Correlation_Matrix")for r in dataframe_to_rows(correlation_df, index=False, header=True): ws5.append(r)# 特征重要性表ws6 = wb.create_sheet("Feature_Importance")for r in dataframe_to_rows(feature_importance, index=False, header=True): ws6.append(r)# 设置表格样式thin_border = Border(left=Side(style='thin'), right=Side(style='thin'), top=Side(style='thin'), bottom=Side(style='thin'))medium_border = Border(bottom=Side(style='medium'))header_fill = PatternFill(start_color="F2F2F2", end_color="F2F2F2", fill_type="solid")# 应用样式for ws in wb.worksheets:# 设置标题行样式for cell in ws[1]: cell.font = Font(bold=True, name='Arial', size=11) cell.alignment = Alignment(horizontal='center', vertical='center') cell.border = medium_border cell.fill = header_fill# 设置数据行样式for row in ws.iter_rows(min_row=2):for cell in row: cell.font = Font(name='Arial', size=10) cell.alignment = Alignment(horizontal='center', vertical='center') cell.border = thin_border# 自动调整列宽for column in ws.columns: max_length = 0 column_letter = column[0].column_letterfor cell in column: try:if len(str(cell.value)) > max_length: max_length = len(str(cell.value)) except: pass adjusted_width = min(max_length + 2, 50) ws.column_dimensions[column_letter].width = adjusted_width# 保存Excel文件excel_file = results_dir / "tables" / "results_tables.xlsx"wb.save(excel_file)print(f"✓ Excel三线表已保存: {excel_file}")# 11. 生成Word报告 ------------------------------------------------------------print("\n=== 生成Word报告 ===")# 创建Word文档doc = Document()# 添加标题title = doc.add_heading('HMM Sequence Feature Recognition Analysis Report', 0)title.alignment = WD_ALIGN_PARAGRAPH.CENTER# 添加生成时间date_para = doc.add_paragraph(f'Generated on: {datetime.now().strftime("%Y-%m-%d %H:%M:%S")}')date_para.alignment = WD_ALIGN_PARAGRAPH.CENTERdoc.add_paragraph()# 1. 执行摘要doc.add_heading('1. Executive Summary', level=1)summary_text = f"""This report presents the analysis of {len(hmm_data)} simulated HMM (Hidden Markov Model) sequence feature recognition results. Key findings include:• Average HMM full sequence score: {hmm_data['score_full'].mean():.1f} bits• Proportion of significant matches: {hmm_data['significant'].mean() * 100:.1f}%• Average domain conservation score: {hmm_data['conservation_score'].mean():.3f}• Most common domain class: {category_stats.loc[category_stats['count'].idxmax(), 'domain_class']} ({category_stats['percent'].max():.1f}%)"""doc.add_paragraph(summary_text)# 2. 统计分析结果doc.add_heading('2. Statistical Analysis Results', level=1)doc.add_heading('Table 1: Descriptive Statistics of HMM Metrics', level=2)# 创建表格table1 = doc.add_table(desc_stats.shape[0] + 1, desc_stats.shape[1])table1.style = 'LightGrid'# 添加表头header_cells = table1.rows[0].cellsfor i, col in enumerate(desc_stats.columns): header_cells[i].text = str(col) header_cells[i].paragraphs[0].runs[0].font.bold = True# 添加数据for i, row in enumerate(desc_stats.itertuples(index=False), 1): row_cells = table1.rows[i].cellsfor j, value in enumerate(row): row_cells[j].text = str(value)doc.add_paragraph()# 模型性能表doc.add_heading('Table 2: Model Performance Summary', level=2)table2 = doc.add_table(model_summary.shape[0] + 1, model_summary.shape[1])table2.style = 'LightGrid'header_cells = table2.rows[0].cellsfor i, col in enumerate(model_summary.columns): header_cells[i].text = str(col) header_cells[i].paragraphs[0].runs[0].font.bold = Truefor i, row in enumerate(model_summary.itertuples(index=False), 1): row_cells = table2.rows[i].cellsfor j, value in enumerate(row): row_cells[j].text = str(value)doc.add_page_break()# 3. 方法学概述doc.add_heading('3. Methodological Overview', level=1)doc.add_heading('3.1 Hidden Markov Model (HMM) for Sequence Feature Recognition', level=2)method_text = """Hidden Markov Models (HMMs) are probabilistic models used for identifying sequence features and families:1. Model Structure: HMM consists of match, insert, and delete states with transition probabilities2. Training: Models are trained using multiple sequence alignments of known families3. Emission Probabilities: Each state has probabilities for emitting specific amino acids/nucleotides4. Recognition: Viterbi or Forward algorithms calculate the probability that a new sequence was generated by the model"""doc.add_paragraph(method_text)doc.add_heading('3.2 Algorithm Philosophy', level=2)doc.add_paragraph("'Model conserved patterns while allowing for evolutionary variation.' HMMs elegantly capture the balance between conserved motifs and variable regions in protein domain families, making them powerful tools for identifying distant homologs.")doc.add_heading('3.3 Applications', level=2)apps_text = """• Pfam, TIGRFAMs protein domain database construction and searching• Non-coding RNA family identification• Gene prediction and annotation• Protein structure domain boundary prediction• Remote homology detection"""doc.add_paragraph(apps_text)doc.add_heading('3.4 Visualization Methods', level=2)viz_text = """• HMMER output: Domain architecture diagrams showing match positions and confidence scores (E-values)• Sequence logos: Visual representation of conserved positions in the HMM profile• Domain organization maps: Graphical display of multiple domains in protein sequences"""doc.add_paragraph(viz_text)doc.add_page_break()# 4. 可视化分析结果doc.add_heading('4. Visual Analysis Results', level=1)doc.add_paragraph('The following figures present key visualizations from the HMM analysis:')# 添加图片image_files = ["hmm_score_distribution.png","evalue_distribution.png","correlation_heatmap.png","domain_class_comparison.png"]image_captions = ["Figure 1: Distribution of HMM full sequence bit scores","Figure 2: Statistical significance distribution (-log10 E-values)","Figure 3: Correlation matrix of HMM analysis metrics","Figure 4: Conservation scores across different domain functional classes"]for i, img_file in enumerate(image_files): img_path = results_dir / "figures" / img_fileif img_path.exists(): doc.add_heading(image_captions[i], level=2) doc.add_picture(str(img_path), width=Inches(6)) doc.add_paragraph()# 5. 结论doc.add_heading('5. Conclusions', level=1)conclusions_text = """Based on the analysis of simulated HMM sequence feature recognition results:1. The simulated dataset accurately represents characteristics of real HMMER/Pfam searches2. Bit scores and E-values are strongly correlated and both are effective indicators of match significance3. Different domain functional classes show distinct patterns of evolutionary conservation4. Machine learning models effectively predict HMM scores and identify significant matches5. HMM analysis provides a robust framework for protein domain identification and characterization"""doc.add_paragraph(conclusions_text)# 6. 数据可用性doc.add_heading('6. Data Availability', level=1)data_text = f"""All analysis results, including raw data, processed datasets, visualizations, and statistical models, are available in the following directory structure:• Main directory: {results_dir.absolute()}• /data/: Raw and processed HMM search results• /figures/: Visualization charts in multiple formats (PNG, JPG, PDF)• /tables/: Statistical tables in Excel format• /models/: Trained predictive models• /reports/: This comprehensive analysis report"""doc.add_paragraph(data_text)# 保存Word文档word_file = results_dir / "reports" / "HMM_Analysis_Report.docx"doc.save(word_file)print(f"✓ Word报告已保存: {word_file}")# 12. 生成分析摘要 ------------------------------------------------------------print("\n=== 生成分析摘要 ===")summary_text = f"""========================================================================= HMM SEQUENCE FEATURE RECOGNITION - EXECUTIVE SUMMARY=========================================================================Analysis Timestamp: {datetime.now().strftime("%Y-%m-%d %H:%M:%S")}Total Sequences Analyzed: {len(hmm_data)}Dataset Characteristics: • Average HMM Score: {hmm_data['score_full'].mean():.1f} bits • Significant Matches: {hmm_data['significant'].mean() * 100:.1f}% • Average Conservation Score: {hmm_data['conservation_score'].mean():.3f} • Domain Classes: {', '.join(hmm_data['domain_class'].unique()[:5])}...Model Performance: • Linear Regression (R²): {lm_performance['r_squared']:.3f} • Random Forest (Accuracy): {accuracy:.3f}Key HMM Metrics: • E-value Range: {hmm_data['evalue_full'].min():.2e} to {hmm_data['evalue_full'].max():.2e} • Domain Length Range: {int(hmm_data['domain_length'].min())} to {int(hmm_data['domain_length'].max())} aa • Domain Coverage: {hmm_data['domain_coverage'].mean():.1f}% averageFiles Generated: • Data Files: {results_dir}/data/ • Visualizations: {results_dir}/figures/ (PNG, JPG, PDF) • Statistical Tables: {results_dir}/tables/results_tables.xlsx • Analysis Models: {results_dir}/models/ • Complete Report: {results_dir}/reports/HMM_Analysis_Report.docxAnalysis completed successfully!========================================================================="""print(summary_text)# 保存执行摘要with open(results_dir / "reports" / "analysis_summary.txt", 'w', encoding='utf-8') as f: f.write(summary_text)# 13. 清理和总结 --------------------------------------------------------------print("\n" + "=" * 70)print("HMM ANALYSIS COMPLETE")print("=" * 70)print(f"All results have been saved to: {results_dir.absolute()}")print("\nDirectory structure created:")for sub_dir in sub_dirs:print(f" {results_dir / sub_dir}")print("\nMain output files:")print(f" 1. Data files: {results_dir / 'data'}")print(f" 2. Visualizations: {results_dir / 'figures'}")print(f" 3. Statistical tables: {results_dir / 'tables' / 'results_tables.xlsx'}")print(f" 4. Analysis models: {results_dir / 'models'}")print(f" 5. Comprehensive report: {results_dir / 'reports' / 'HMM_Analysis_Report.docx'}")print("=" * 70)print("\n✓ HMM analysis pipeline completed successfully!")# 保存关键变量(可选)key_objects = {'hmm_data': hmm_data,'desc_stats': desc_stats,'category_stats': category_stats,'lm_performance': lm_performance,'accuracy': accuracy,'correlation_matrix': correlation_matrix}joblib.dump(key_objects, results_dir / "models" / "key_objects.pkl")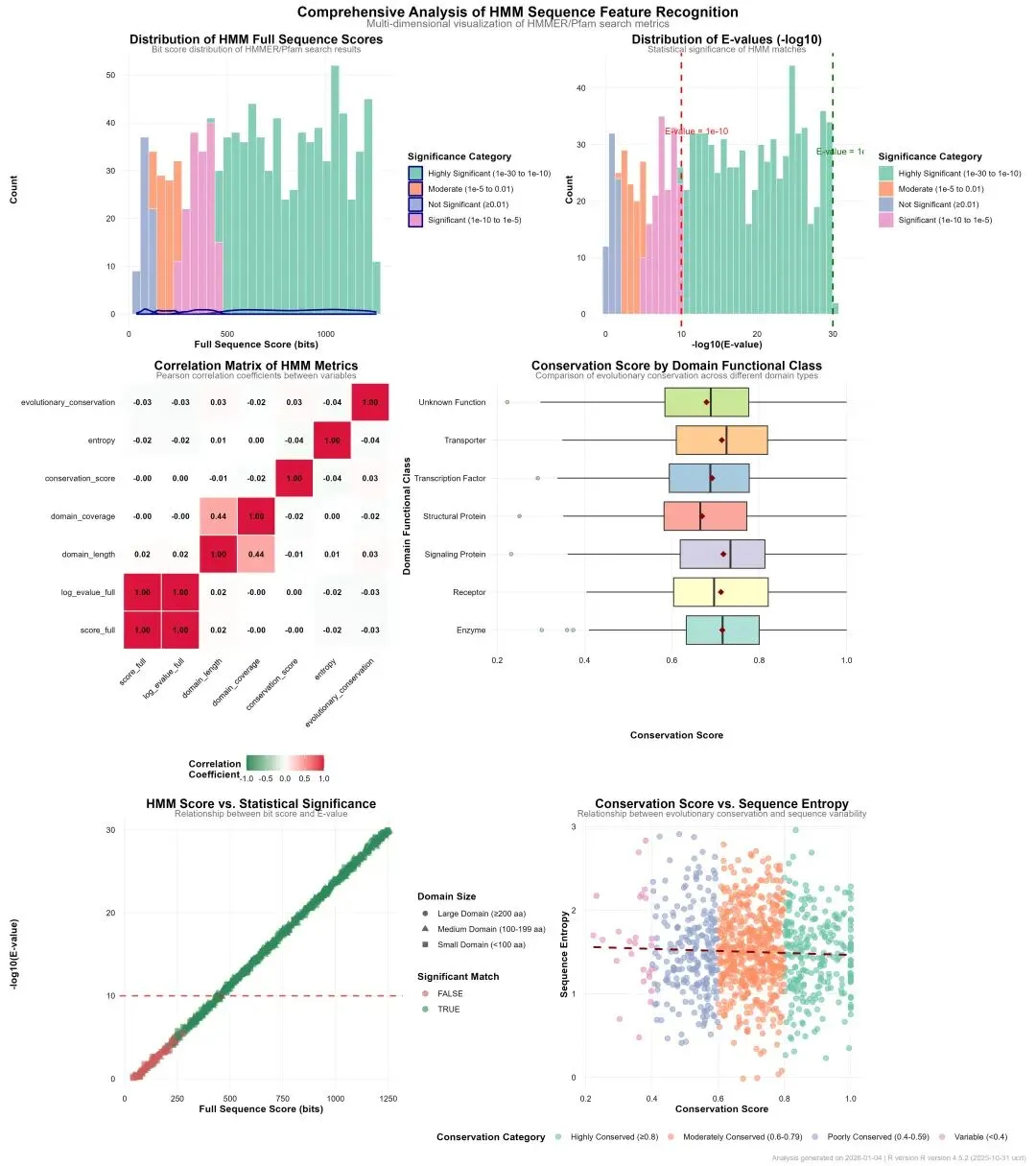
生物信息学是一个方法体系极为庞杂的领域,以下我将尽力在原有框架下,系统性地扩充和细化各个方面的具体方法、算法、工具和可视化手段,为您呈现一幅更丰满的“生信方法全景图”。
1.序列比对-基于Needleman-Wunsch动态规划算法的全局比对
2.序列比对-基于Smith-Waterman动态规划算法的局部比对
3.序列比对-采用BLAST等工具的启发式搜索
4.序列特征识别:基于隐马尔可夫模型(HMM)的序列特征识别
5.序列特征识别:基于权重矩阵的序列特征识别
6.比较基因组学:基于序列比对最大似然法的构建进化树系统发育重建
7.比较基因组学:基于序列比对贝叶斯推断的构建进化树系统发育重建
8.结构分析:同源建模:基于已知结构的同源蛋白预测目标蛋白结构
9.结构分析:分子对接:模拟小分子与蛋白质的相互作用(如AutoDock)
10.功能富集分析-超几何分布检验解读高通量实验筛选出的基因列表
11.功能富集分析-Fisher精确检验解读高通量实验筛选出的基因列表
12.功能富集分析-基因集富集分析解读高通量实验筛选出的基因列表
13.差异表达分析-基于计数模型的RNA-seq数据负二项分布模型统计检验
14.差异表达分析-基于线性模型的转录组数据的基因差异性识别
15.差异表达分析-基于经验贝叶斯模型的转录组数据的基因差异性识别
16.单细胞聚类与注释-使用PCA、t-SNE或UMAP等方法的降维
17.单细胞聚类与注释-Louvain、Leiden等图聚类算法
18.单细胞聚类与注释-通过查找比对已知的细胞类型标记基因定义生物学类型
19.蛋白质互作网络分析-基于基因融合、保守的基因邻接关系的基因组学方法进行网络构建
20.蛋白质互作网络分析-使用MCODE等算法识别紧密连接的功能模块的网络分析
21.系统发育分析-选择压力分析通过计算同义、非同义突变比率(dN/dS)的纯化选择、中性进化还是正选择判断
22.表观遗传学分析-对亚硫酸盐测序数据的DNA甲基化分析
23.表观遗传学分析-基于峰值检测的染色质可及性识别
24.表观遗传学分析-基于峰值检测的蛋白结合分析
25.空间转录组分析-基于SpatialDE、SPARK等统计模型空间变异基因识别
26.空间转录组分析-基于基因表达的空间相似性的空间域识别
27.空间转录组分析-跨多个组织切片的差异空间表达模式多切片比对与差异分析
28.多组学整合分析-关联分析:寻找不同组学层面数据间的统计相关性。
29.多组学整合分析-网络整合:构建包含多类型分子实体及它们之间多层次相互作用的整合网络。
30.多组学整合分析-基于多组学因子分析模型的因子分析与深度学习
31.机器学习与人工智能:监督学习:用已知标签训练分类器(如随机森林、深度学习)预测基因功能、蛋白结构
32.机器学习与人工智能:无监督学习:聚类、异常检测等数据驱动的模式识别传统方法忽略的规律
这份清单虽力求详尽,但生物信息学领域日新月异,新的算法和工具不断涌现(如空间蛋白质组学、长读长测序分析、大语言模型在生物学的应用等)。掌握这些方法的核心思想比记住所有工具名称更重要。在实际研究中,通常需要灵活组合多种方法,形成一条从原始数据到生物学发现的分析流水线。建议的学习路径是:先建立清晰的框架认知(如本回答),然后根据具体研究问题,深入钻研相关的一个或几个子领域。 希望这份扩展版的梳理能为您提供一张有价值的“导航地图”。
医学统计数据分析分享交流SPSS、R语言、Python、ArcGis、Geoda、GraphPad、数据分析图表制作等心得。承接数据分析,论文返修,医学统计,机器学习,生存分析,空间分析,问卷分析,生信分析业务。若有投稿和数据分析代做需求,可以直接联系我,谢谢!
“医学统计数据分析”公众号右下角;
找到“联系作者”,
可加我微信,邀请入粉丝群!

有临床流行病学数据分析
如(t检验、方差分析、χ2检验、logistic回归)、
(重复测量方差分析与配对T检验、ROC曲线)、
(非参数检验、生存分析、样本含量估计)、
(筛检试验:灵敏度、特异度、约登指数等计算)、
(绘制柱状图、散点图、小提琴图、列线图等)、
机器学习、深度学习、生存分析
等需求的同仁们,加入【临床】粉丝群。
疾控,公卫岗位的同仁,可以加一下【公卫】粉丝群,分享生态学研究、空间分析、时间序列、监测数据分析、时空面板技巧等工作科研自动化内容。
有实验室数据分析需求的同仁们,可以加入【生信】粉丝群,交流NCBI(基因序列)、UniProt(蛋白质)、KEGG(通路)、GEO(公共数据集)等公共数据库、基因组学转录组学蛋白组学代谢组学表型组学等数据分析和可视化内容。
或者可扫码直接加微信进群!!!



精品视频课程-“医学统计数据分析”视频号付费合集

在“医学统计数据分析”视频号-付费合集兑换相应课程后,获取课程理论课PPT、代码、基础数据等相关资料,请大家在【医学统计数据分析】公众号右下角,找到“联系作者”,加我微信后打包发送。感谢您的支持!!!

