调度器扩展:sched_ext 与未来
Linux 调度子系统技术文档系列 · 第 15 篇
作为 Linux 内核中最复杂的子系统之一,调度器长期处于一种矛盾状态:开发者迫切需要为特定场景定制调度策略——数据中心的批处理任务需要高吞吐,AI 训练集群需要 GPU 与 CPU 的协同调度,实时音视频服务要求微秒级的延迟保证——但面对调度器数十万行代码和精密的优先级体系,几乎没有人能轻易修改内核调度器。传统的做法是提交补丁,等待漫长的代码审查,再等下一个内核版本发布。sched_ext 的诞生彻底打破了这个困境:它通过 eBPF 技术,让开发者在不修改、不重新编译内核的前提下,运行自定义的调度器。
为什么需要可编程调度器
sched_ext 要解决的问题并非"调度器不够好",而是"调度器不够灵活"。CFS 作为通用调度器,在大多数工作负载下表现优异,但它本质上是一种折中设计:vruntime 机制追求的是通用公平性,无法针对某一类特定工作负载做极端优化。
社区面临的现实矛盾是:内核主线不能接受过于特殊的调度逻辑,而开发者又无法容忍调度策略的僵化。eBPF 提供了一条中间道路——用户态编写调度逻辑,内核态执行调度决策,验证器保障安全边界。sched_ext 将这条道路从理论变成了可落地的基础设施。
sched_ext 的核心架构是什么样的
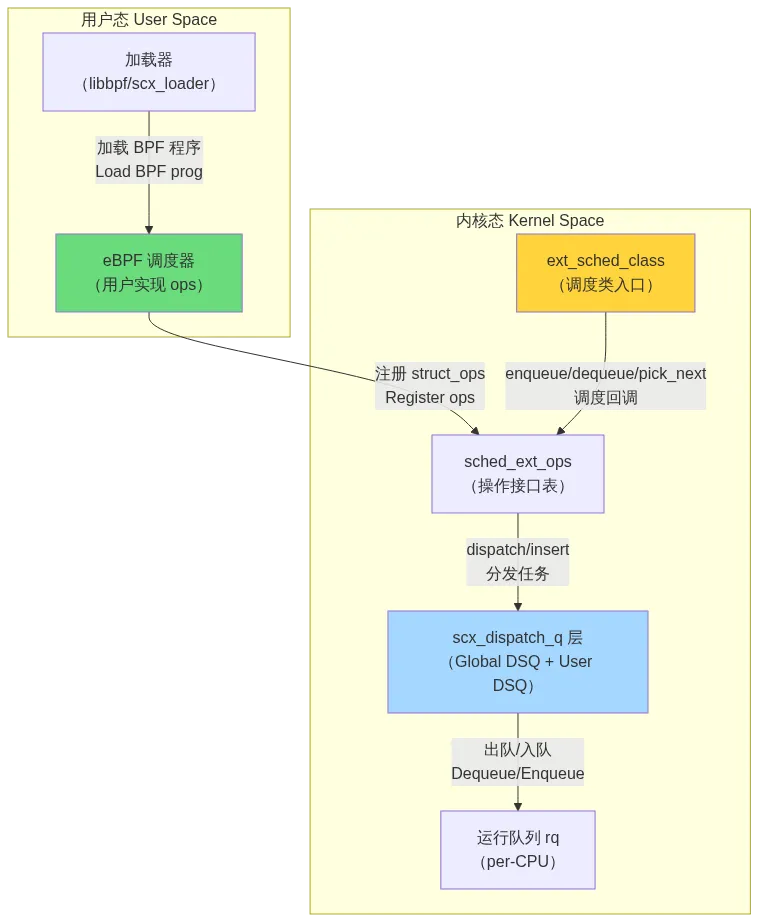
sched_ext 在内核中注册为一个独立的调度类 ext_sched_class,与 CFS、RT 等调度类并列。当进程被标记为 SCHED_EXT 策略时,内核会将调度决策权委托给 sched_ext 框架,框架则通过 sched_ext_ops 操作表回调用户加载的 eBPF 程序。
整个架构可以概括为以下组件:
| |
|---|
ext_sched_class | 内核调度类入口,注册 enqueue/dequeue/pick_next 等回调 |
sched_ext_ops | BPF 操作接口表,用户实现 select_cpu、enqueue、dispatch 等钩子 |
scx_dispatch_q | 分发队列,分全局 DSQ 和用户自定义 DSQ 两层 |
scx_sched | 调度器实例结构,承载 ops、DSQ 哈希表、事件统计等 |
| |
| kfunc 上下文权限控制,限制 BPF 函数只能从允许的 ops 调用 |
scx_dispatch_q 是 sched_ext 的核心数据结构,承载了任务分发的全部逻辑。全局 DSQ 按 NUMA 节点拆分以避免竞争,用户自定义 DSQ 通过 rhashtable 管理,支持开发者实现任意多队列模型。调度器通过 scx_bpf_dispatch() 将任务放入目标队列,通过 scx_bpf_dsq_move_to_local() 将任务从用户 DSQ 转移到 CPU 本地队列。
ext_sched_class 是如何工作的
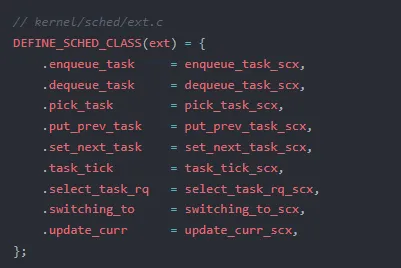
ext_sched_class 以 DEFINE_SCHED_CLASS(ext) 宏定义,将调度器核心回调全部指向 scx 实现。当调度器需要做出决策时,内核调用这些回调函数,回调函数再通过 SCX_CALL_OP 宏将控制权转移到 BPF 程序。
ext.c 展示了 ext_sched_class 的完整定义:
调度类优先级关系是 stop > dl > rt > ext > fair > idle,这意味着 sched_ext 始终优先于 CFS 运行。当一个任务被加入运行队列时,enqueue_task_scx 不仅设置任务的 QUEUED 标志,还会根据 enq_flags 决定是否调用 BPF 的 runnable 回调,最终通过 do_enqueue_task() 将任务分发到目标队列。
sched_ext 设计了一个精巧的 ops_state 状态机来跟踪任务所有权:
NONE→QUEUEING→QUEUED→DISPATCHING→NONE
这个状态机让 scx 核心能够可靠判断任意任务当前归谁所有,即使 BPF 调度器尝试错误地分发任务,内核也能安全拒绝。这种容错设计大幅降低了编写 BPF 调度器的门槛。
BPF 调度器注册与任务分发的完整路径
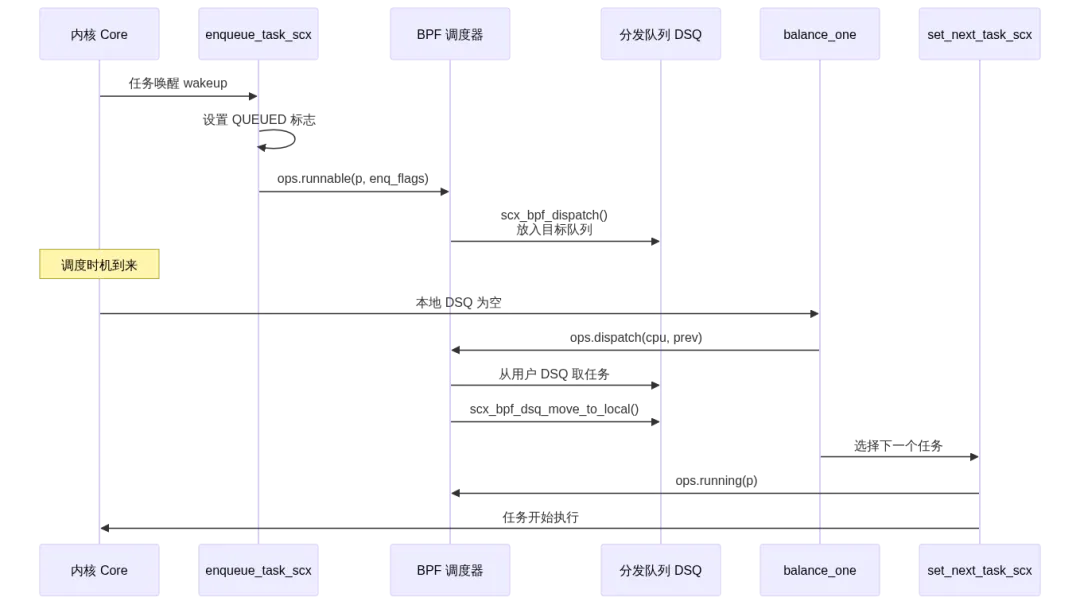
理解 sched_ext 的关键在于追踪两条核心路径:BPF 调度器如何加载注册,以及任务如何从唤醒到执行。
BPF 调度器注册路径
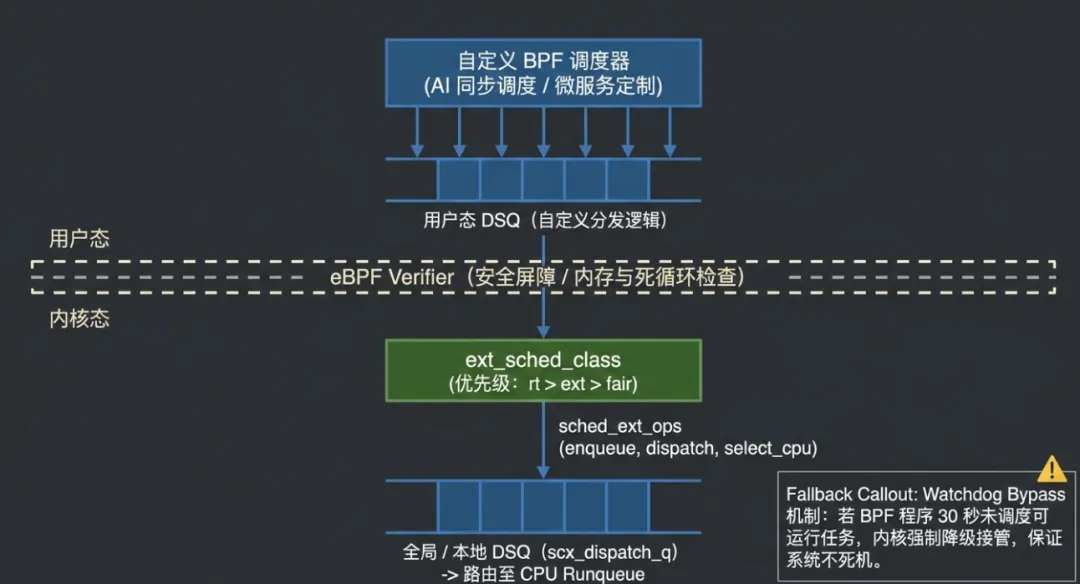
用户态程序通过 libbpf 加载 eBPF 调度器,struct sched_ext_ops 通过 struct_ops 机制注册到内核。内核收到注册请求后,执行初始化序列:首先调用 ops.init() 完成 BPF 调度器的初始化,然后建立 DSQ 哈希表、分配 per-CPU 分发缓冲区、启动看门狗定时器。看门狗的任务是监控任务是否被 BPF 调度器"遗忘"——如果一个任务在可运行状态下超过设定时间(默认 30 秒)仍未被调度,看门狗将触发错误并回退到 bypass 模式。
注册完成后,scx_enable_state_var 从 SCX_DISABLED 切换到 SCX_ENABLED,所有符合策略的进程立即迁移到 ext_sched_class 下。
任务分发路径
任务分发是 sched_ext 的核心执行路径,涉及从唤醒到上 CPU 的完整流程:
当 balance_one() 发现本地 DSQ 为空时,它会调用 BPF 调度器的 ops.dispatch() 钩子,要求 BPF 调度器提供可运行的任务。BPF 调度器可以从自己的队列中取任务,也可以通过 scx_bpf_dsq_move_to_local() 将用户 DSQ 中的任务转移到当前 CPU 的本地队列。set_next_task_scx() 随后从本地队列取出任务,调用 ops.running() 通知 BPF 调度器,最后将任务切换到 CPU 上运行。
这套机制的精妙之处在于:内核不假设 BPF 调度器的队列实现方式,它只关心"本地 DSQ 是否有任务可运行"。BPF 调度器可以在用户态实现任意复杂的队列模型——优先级队列、时间片轮转、甚至是基于机器学习的预测调度。
sched_ext 对内核生态意味着什么
sched_ext 的深远影响不在于它提供了一种新的调度器实现方式,而在于它重新定义了内核与用户态之间的信任边界。过去,调度逻辑必须在内核中实现,因为内核不能信任用户态的调度决策。eBPF 验证器的出现打破了这个假设:验证后的 BPF 程序可以在内核态安全运行,同时保持用户态的开发便利性。
这种范式转变催生了几个重要场景:
在 AI 训练集群中,调度器需要考虑 GPU 任务的协同性——多个进程共同训练一个模型时,它们需要尽可能在同一时间片内运行,以减少 GPU 空闲等待。sched_ext 允许开发者实现这种"同步感知调度",通过 eBPF 跟踪 GPU 任务间的依赖关系,动态调整调度时机。
在 微服务架构中,不同服务对延迟的敏感度差异巨大。API 网关需要毫秒级响应,后台批处理任务则可以容忍秒级延迟。sched_ext 使开发者能够按 cgroup 实现分层调度策略,而不必等待内核主线接受这些特殊需求。
sched_ext 更像是一个调度器的"实验沙盒"。开发者可以先用 BPF 验证调度算法的有效性,如果算法被证明具有通用价值,再考虑合入内核主线。这种渐进式创新模式降低了内核接受的门槛,加速了调度算法的迭代周期。
总结
sched_ext 的本质是用 eBPF 技术在内核调度框架上开了一个"可编程窗口"。它通过 ext_sched_class 作为入口,通过 sched_ext_ops 提供操作接口,通过 scx_dispatch_q 管理任务分发,通过 ops_state 状态机确保安全性。整个设计既保持了内核调度核心的稳定性,又赋予了用户态极大的灵活性。
理解 sched_ext 的价值,需要从"调度器是内核固定的核心组件"这个传统观念中跳出来。sched_ext 告诉我们:调度器可以是用户定义的,内核只需提供安全框架和执行平台。这不仅是技术上的进步,更是设计哲学上的演进。
思考与互动
如果让你为 AI 训练场景设计一个 BPF 调度器,你会如何跟踪 GPU 任务间的依赖关系,并实现"同步调度"?
sched_ext 的 bypass 机制在 BPF 调度器出错时自动回退。你认为这种"安全网"设计会不会让开发者过于激进地实验不成熟的调度算法?
本系列文章基于 Linux 6.19.13 内核源码采用 CC BY-NC-SA 4.0 协议,转载请注明出处
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
