32岁零基础学Python量化 第8周 复现深层神经网络,成功识别了自己拍的猫图
- 2026-07-03 20:58:55
构建深层神经网络模型(Deep Neural Network 简称DNN)
前言
上篇讲述了构建深层神经网络需要的函数模块,本篇重点讲述如何借助模块构建深层神经网络模型(DNN),用以对图片进行识别预测。训练过程就是教会电脑如何识别猫,给电脑209张包括但不仅限于猫咪的图片,每一张它读取后经过模型处理得到预测结果,将预测结果和实际结论进行比较并反向优化,将预测和实际间的差距逐渐缩小,最终经过反复迭代训练,给它一张之前没看过的图片,它能够判断该图片中是否含有猫咪。
类比到世界杯比赛结果预测,给模型输入历史上很多场比赛的赛前已知的相关信息,例如两支球队阵容,两队大名单球员历史数据,预选赛赛果,场馆位置,气候条件...等等,然后得到一个初步预测结果,将模型预测结果和实际结果进行比较,以缩小预测与实际结果为目标对模型进行优化,经过多轮迭代优化,最终得到一个优化好的模型,然后将需要预测的比赛的两队大名单球员历史数据,预选赛赛果,场馆位置,气候条件等等最新信息输入训练好的模型,最终得出比赛的预测结果。
我们下面就对之前有讲述过的两层的浅层神经网络和L层深层神经网络进行构建,两种模型相似度很高,因此放在一起讲。
模型构建前的准备
导入各种包:
import time # 导入 time 模块,通常用于计算代码运行耗时import numpy as np # 导入 numpy 并简写为 np,用于高效的矩阵和数值计算import h5py # 导入 h5py 库,用于读取和写入 HDF5 格式的数据集文件import matplotlib.pyplot as plt # 导入 matplotlib 的 pyplot 模块并简写为 plt,用于数据可视化绘图import scipy # 导入 scipy 科学计算库from PIL import Image # 从 PIL (Pillow) 库导入 Image 模块,用于图像的读取和处理from scipy import ndimage # 从 scipy 导入 ndimage 模块,常用于图像旋转、缩放等空间操作from dnn_app_utils_v2 import * # 导入当前目录下的自定义工具脚本 dnn_app_utils_v2 中的所有函数(包含我们上一篇构建的那些基础函数)from matplotlib.pyplot import imread # 从 matplotlib 导入 imread 函数,用于直接读取图片文件为数组(注:新版 matplotlib 已弃用此方法)%matplotlib inline # Jupyter Notebook 魔法命令:让图表直接内嵌显示在代码单元格下方,无需单独弹窗plt.rcParams['figure.figsize'] = (5.0, 4.0) # 设置 matplotlib 全局默认图表尺寸为宽 5.0、高 4.0 英寸plt.rcParams['image.interpolation'] = 'nearest' # 设置图像插值方式为 'nearest'(最近邻),避免图像缩放时产生模糊plt.rcParams['image.cmap'] = 'gray' # 设置图像默认颜色映射为灰度图(grayscale)%load_ext autoreload # Jupyter 魔法命令:加载 autoreload 扩展,用于自动重载外部模块%autoreload 2 # 设置 autoreload 模式为 2:在运行代码前自动重载所有已导入的外部模块,修改外部 .py 文件后无需重启内核np.random.seed(1) # 设置 numpy 随机数种子为 1,确保每次运行代码时生成的随机数序列相同,保证实验结果可复现载入数据:
train_x_orig, train_y, test_x_orig, test_y, classes = load_data()#载入数据显示数据集尺寸:
m_train = train_x_orig.shape[0]num_px = train_x_orig.shape[1]m_test = test_x_orig.shape[0]print ("Number of training examples: " + str(m_train))print ("Number of testing examples: " + str(m_test))print ("Each image is of size: (" + str(num_px) + ", " + str(num_px) + ", 3)")print ("train_x_orig shape: " + str(train_x_orig.shape))print ("train_y shape: " + str(train_y.shape))print ("test_x_orig shape: " + str(test_x_orig.shape))print ("test_y shape: " + str(test_y.shape))数据集预处理:将64*64*3 RGB图像数据处理为扁平化(Flatten)的12288*1的数据,然后整体除以255(像素值范围是0~255),让数据的特征值限定在0和1之间,也就是之前讲的归一化处理。
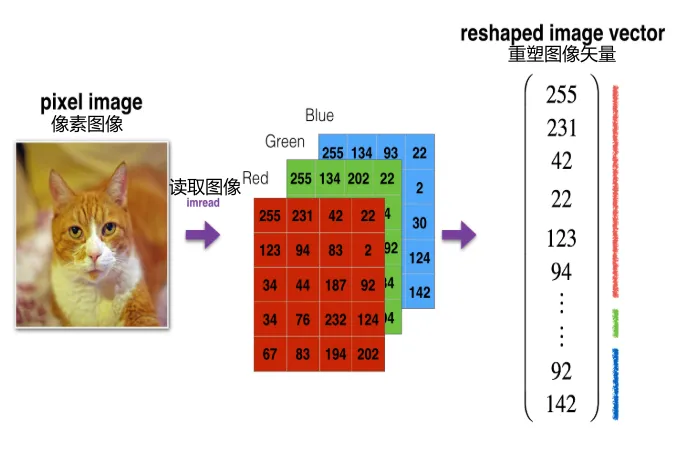
# 训练测试集数据预处理train_x_flatten = train_x_orig.reshape(train_x_orig.shape[0], -1).T # 209行,列根据数组自行展开64*64*3=12288列 ,然后整体转置成12288行209列test_x_flatten = test_x_orig.reshape(test_x_orig.shape[0], -1).T# 数据标准化:让数据的特征值限定在0和1之间train_x = train_x_flatten/255.#将数组范围限定在0到1之间test_x = test_x_flatten/255.print ("train_x's shape: " + str(train_x.shape))print ("test_x's shape: " + str(test_x.shape))两层神经网络的构建
• 原理:输入 -> 线性变换 -> ReLU激活 -> 线性变换 -> Sigmoid激活 -> 输出。 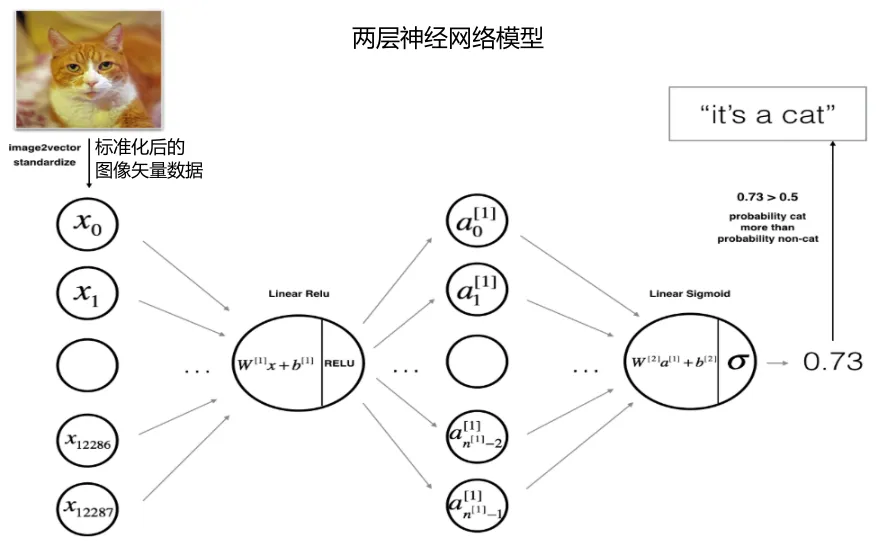
• 已准备好的模块(可以直接使用以下函数进行模型构建)
#1.参数初始化def initialize_parameters(n_x, n_h, n_y): ... return parameters#2.前向传播def linear_activation_forward(A_prev, W, b, activation): ... return A, cache# 3.计算成本函数costdef compute_cost(AL, Y): ... return cost#4.反向传播计算梯度def linear_activation_backward(dA, cache, activation): ... return dA_prev, dW, db#5.更新参数def update_parameters(parameters, grads, learning_rate): ... return parameters• 代码逻辑模型输入:X,Y,layer_dims(各层节点数,由自己定义,输入输出层需根据实际数据确认),learning_rate(学习率,也就是步长),num_iterations(迭代次数,也就是循环迭代多少次)模型输出:parameters(训练好的模型参数)1.参数初始化for 循环num_iterations次(梯度下降法):2.前向传播(输入X -> 线性变换 -> ReLU激活 -> 线性变换 -> Sigmoid激活 -> 输出A2)3.计算成本函数cost4.反向传播计算梯度dW1,db1,dW2,db25.更新参数 W1,b1,W2,b26.用最后更新好的参数构建模型用于预测。 • 构建代码
#定义模型各层节点数n_x = 12288 # num_px * num_px * 3n_h = 7n_y = 1layers_dims = (n_x, n_h, n_y)#构建2层神经网络def two_layer_model(X, Y, layers_dims, learning_rate = 0.0075, num_iterations = 3000, print_cost=False): """ 实现一个两层神经网络,结构:线性层 -> ReLU激活 -> 线性层 -> Sigmoid激活。 形参: X:输入数据,形状为 (n_x, 样本数量) Y:真实的“标签”向量(0 代表猫,1 代表非猫),形状为 (1, 样本数量) layers_dims:各层的维度,格式为 (n_x, n_h, n_y) num_iterations:优化循环的迭代次数 learning_rate:梯度下降更新规则的学习率 print_cost:如果设为 True,则每迭代 100 次打印一次损失值(cost) 返回值: parameters -- 一个包含 W1、W2、b1 和 b2 的字典 """ np.random.seed(1) grads = {} #存储梯度的字典 costs = [] # 存储cost的列表 m = X.shape[1] # 样本数量 (n_x, n_h, n_y) = layers_dims #获取各层节点数 # 1.参数初始化 parameters = initialize_parameters(n_x, n_h, n_y) # Get W1, b1, W2 and b2 from the dictionary parameters. W1 = parameters["W1"] b1 = parameters["b1"] W2 = parameters["W2"] b2 = parameters["b2"] # 循环 (梯度下降法) for i in range(0, num_iterations): #2.前向传播(输入X -> 线性变换 -> ReLU激活 -> 线性变换 -> Sigmoid激活 -> 输出A2) A1, cache1 = linear_activation_forward(X, W1, b1, activation = 'relu') A2, cache2 = linear_activation_forward(A1, W2, b2, activation = 'sigmoid') #3.计算成本函数cost cost = compute_cost(A2, Y) # 初始化反向传播 dA2 = - (np.divide(Y, A2) - np.divide(1 - Y, 1 - A2)) # 4.反向传播计算梯度dW1,db1,dW2,db2 dA1, dW2, db2 = linear_activation_backward(dA2, cache2, activation = 'sigmoid') dA0, dW1, db1 = linear_activation_backward(dA1, cache1, activation = 'relu') # 计算出的梯度更新进梯度字典 grads['dW1'] = dW1 grads['db1'] = db1 grads['dW2'] = dW2 grads['db2'] = db2 #5.更新参数 W1,b1,W2,b2 parameters = update_parameters(parameters, grads, learning_rate = 0.0075) # 从 parameters 中提取 W1, b1, W2, b2 W1 = parameters["W1"] b1 = parameters["b1"] W2 = parameters["W2"] b2 = parameters["b2"] # 每训练 100 个样本,打印一次损失值(cost) if print_cost and i % 100 == 0: print("Cost after iteration {}: {}".format(i, np.squeeze(cost))) if print_cost and i % 100 == 0: costs.append(cost) # 绘制损失值(cost)的变化曲线(画出代价函数图) plt.plot(np.squeeze(costs)) plt.ylabel('cost') plt.xlabel('iterations (per tens)') plt.title("Learning rate =" + str(learning_rate)) plt.show() return parameters• 结果输出
parameters = two_layer_model(train_x, train_y, layers_dims = (n_x, n_h, n_y), num_iterations = 2500, print_cost=True)
predictions_test = predict(test_x, test_y, parameters)
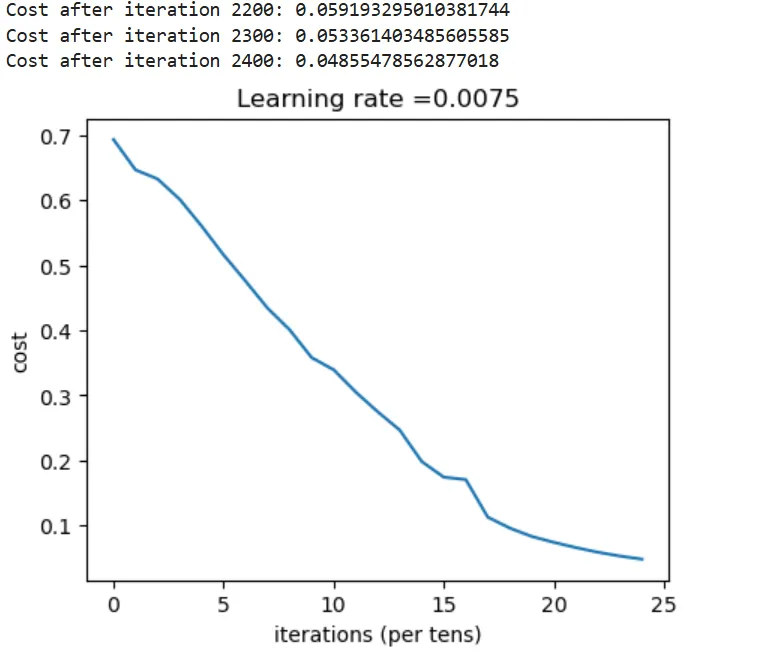
输出:Accuracy: 0.72 (测试集预测准确率72%)
L层神经网络的构建
• 原理:[LINEAR -> RELU](L-1) -> LINEAR -> SIGMOID 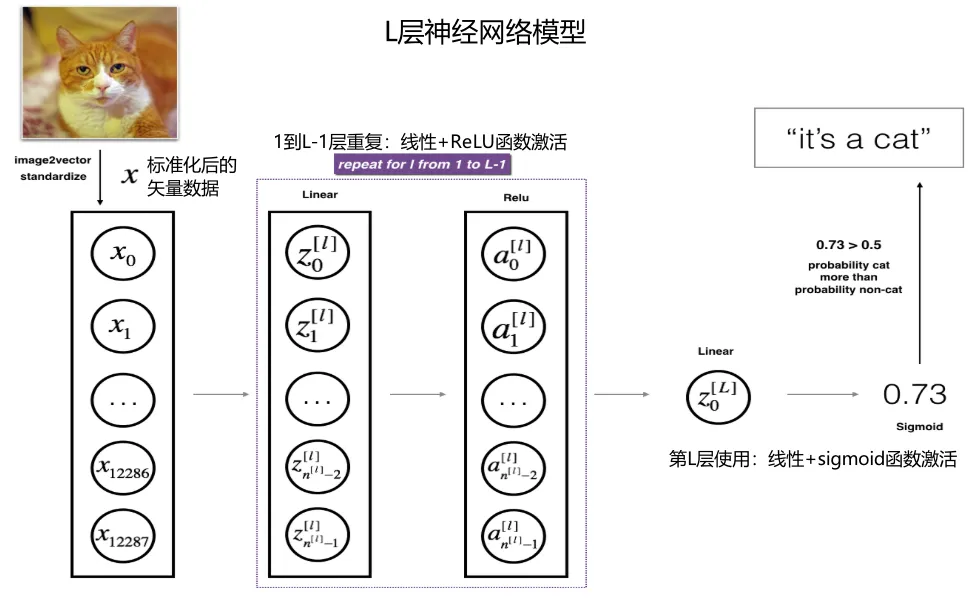
• 准备好的模块
#1.参数初始化def initialize_parameters_deep(layer_dims): ... return parameters#2.前向传播def L_model_forward(X, parameters): ... return AL, caches#3.计算成本函数costdef compute_cost(AL, Y): ... return cost#4.反向传播计算梯度def L_model_backward(AL, Y, caches): ... return grads#5.更新参数 W1,b1,W2,b2def update_parameters(parameters, grads, learning_rate): ... return parameters• 代码逻辑模型输入:X,Y,layer_dims(各层节点数,由自己定义,输入输出层需根据实际数据确认),learning_rate(学习率,也就是步长),num_iterations(迭代次数,也就是循环迭代多少次)模型输出:parameters(训练好的模型参数)1.参数初始化for 循环num_iterations次(梯度下降法):2.前向传播([LINEAR -> RELU](L-1) -> LINEAR -> SIGMOID)3.计算成本函数cost4.反向传播计算梯度grads5.使用计算好的梯度更新参数parameters6.用最后更新好的参数构建模型用于预测。 • 构建代码
#定义模型各层节点数layers_dims = [12288, 20, 7, 5, 1] # 定义5层神经网络各层节点数# 构建 L层神经网络模型def L_layer_model(X, Y, layers_dims, learning_rate = 0.0075, num_iterations = 3000, print_cost=False):#lr was 0.009 """ 实现一个 L 层神经网络:[LINEAR->RELU]*(L-1)->LINEAR->SIGMOID。 形参: X:输入数据,形状为 (样本数量, num_px * num_px * 3) 的 numpy 数组。 Y:真实的“标签”向量(0 代表猫,1 代表非猫),形状为 (1, 样本数量)。 layers_dims:一个列表,包含输入层大小以及每一层的大小,总长度为 (层数 + 1)。 learning_rate:梯度下降更新规则的学习率。 num_iterations:优化循环的迭代次数。 print_cost:如果设为 True,则每 100 步打印一次损失值(cost)。 返回值: parameters:模型学习到的参数,后续可用于进行预测。 """ np.random.seed(1) costs = [] # keep track of cost # 1.参数初始化 parameters = initialize_parameters_deep(layers_dims) #for循环num_iterations次(梯度下降法) for i in range(0, num_iterations): #2.前向传播 输入:parameters,X 输出:caches,AL AL, caches = L_model_forward(X, parameters) #3.计算成本函数cost 输入:AL,Y 输出 cost cost = compute_cost(AL, Y) #4.反向传播计算梯度 输入:AL,Y,caches 输出:grads 错误写法:输入:dAL,caches 输出:grads grads = L_model_backward(AL, Y, caches) #5.使用计算好的梯度更新参数 输入:grads parameters 输出:parameters parameters = update_parameters(parameters, grads, learning_rate = 0.0075) # 每一百次循环打印一次cost if print_cost and i % 100 == 0: print ("Cost after iteration %i: %f" %(i, cost)) if print_cost and i % 100 == 0: costs.append(cost) # 绘出成本函数图 plt.plot(np.squeeze(costs)) plt.ylabel('cost') plt.xlabel('iterations (per tens)') plt.title("Learning rate =" + str(learning_rate)) plt.show() return parameters• 结果输出
parameters = L_layer_model(train_x, train_y, layers_dims, num_iterations = 2500, print_cost = True)pred_train = predict(train_x, train_y, parameters)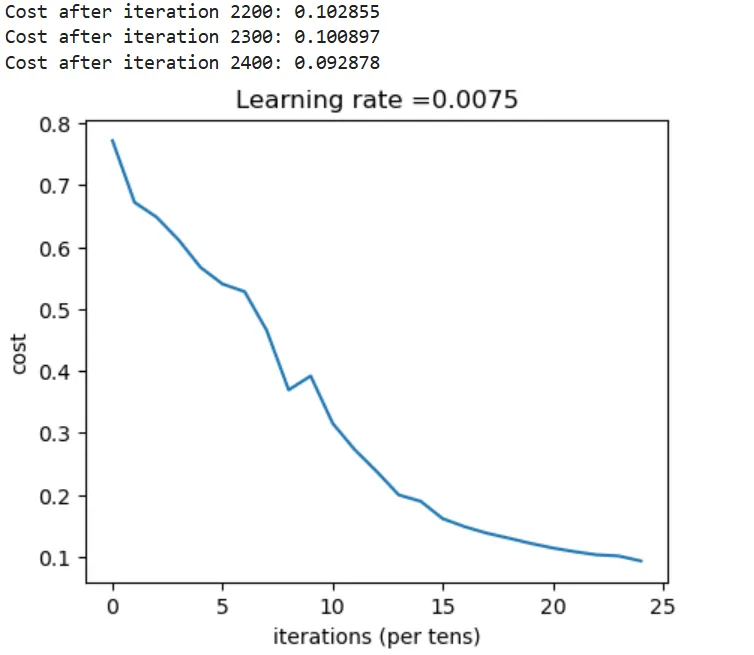
输出:Accuracy: 0.98 (测试集预测准确率98%)
实际预测能力
使用我自己的实拍图看下L层神经网络训练出来的模型真实预测效果:
my_image = "my_image.jpg" # 修改为我的图片文件名my_label_y = [1] # 图片的真实类别 (1 -> cat, 0 -> non-cat)import imageiofrom PIL import Imagefname = "images/" + my_image# 1. 使用 imageio 替代 ndimage.imreadimage = np.array(imageio.imread(fname))# 2. 使用 PIL 替代 scipy.misc.imresizemy_image_resized = np.array(Image.fromarray(image).resize((num_px, num_px)))my_image_processed = my_image_resized.reshape((num_px * num_px * 3, 1))my_image_processed = my_image_processed / 255.0# 3. 调用预测函数my_predicted_image = predict(my_image_processed, my_label_y, parameters)# 4. 显示图片plt.figure(figsize=(6, 4))plt.imshow(image)plt.show()# 5. 优化打印语句,避免 decode 报错predicted_class = int(np.squeeze(my_predicted_image))print("y = " + str(np.squeeze(my_predicted_image)) + ", your L-layer model predicts a \"" + classes[predicted_class].decode("utf-8") + "\" picture.") # 加上 .decode("utf-8")最终预测结果正确:


