Linux 服务器抢救实录:一次 EXT4 文件系统损坏的完整修复过程
- 2026-07-04 11:25:37
EXT4-fs error 错误。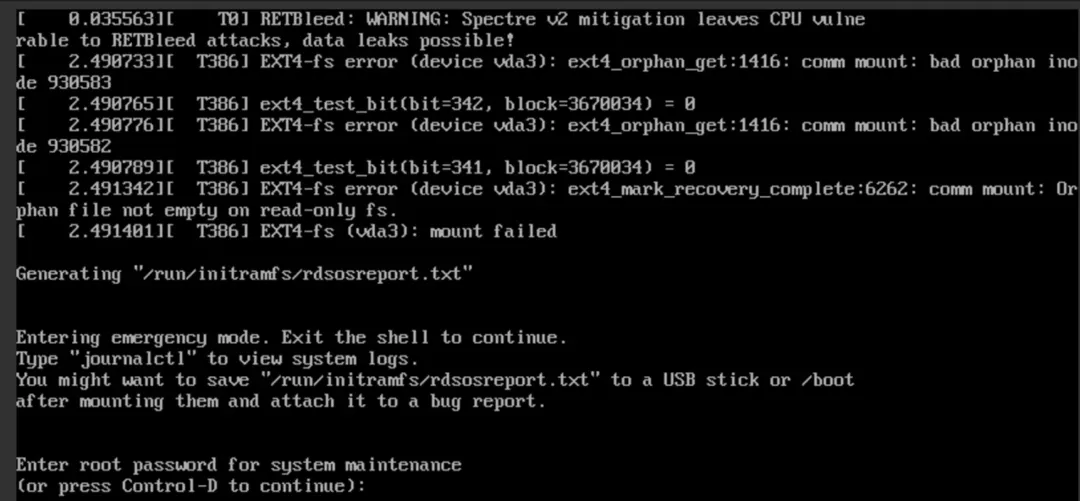
今天就把这次完整的排查和修复过程记录下来,希望能帮到遇到类似问题的朋友。
一、故障现象
当你通过阿里云 VNC 管理终端连接到服务器时,看到的不是熟悉的登录提示符,而是这样的画面:
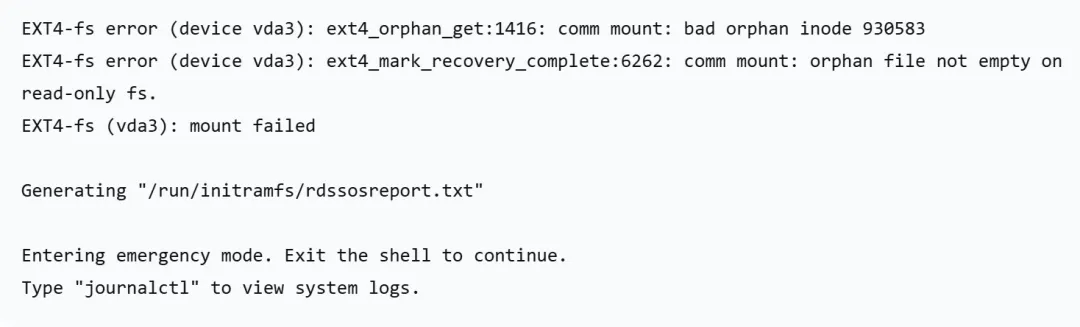
关键信息解读:

二、为什么会发生这种问题?
根据我的排查和分析,可能的原因有:
非正常关机:比如强制断电、虚拟机热迁移失败、
reboot命令卡住后硬重启磁盘空间写满:根分区被写满 100% 时,文件系统可能强制进入只读状态
底层存储故障:云盘偶尔的 I/O 延迟或逻辑错误
三、修复过程详解
3.1 进入紧急模式
系统进入 Emergency Mode 后,会提示输入 root 密码:
Enter root password for system maintenance
(or press Control-D to continue):
dracut:/root#
3.2 查看磁盘分区信息
首先确认受损的磁盘分区是哪个:
cat /proc/partitions
major minor #blocks name
254 0 20971520 vda
254 1 8192 vda1
254 2 204800 vda2
254 3 20757487 vda3
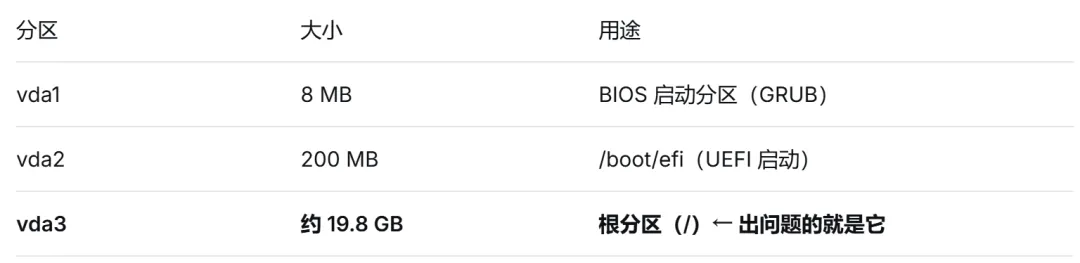
vda 也可能是 wda,这是因为内核驱动加载顺序的差异,不用纠结,直接修复对应的分区号即可。3.3 执行文件系统修复
使用 e2fsck 命令对根分区进行修复:
e2fsck-y /dev/vda3
-y参数:对所有修复问题自动回答 “yes”这是 ext4 文件系统的专用修复工具
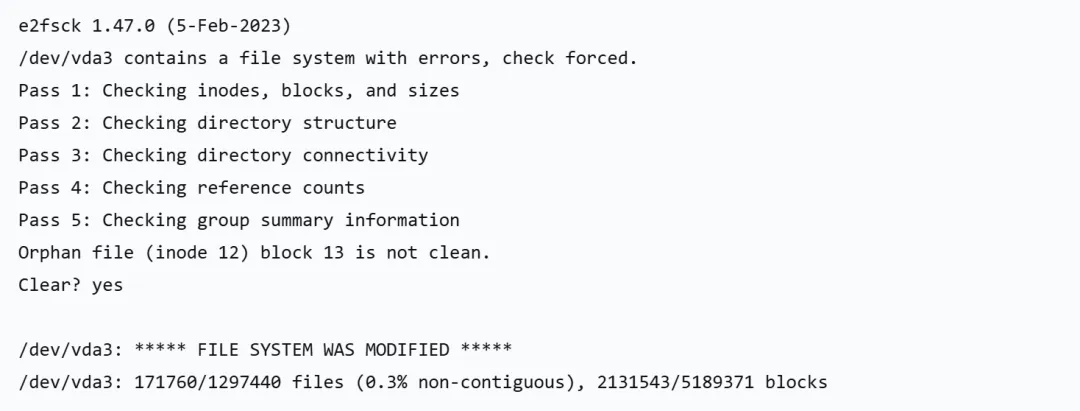
五个 Pass 分别做了什么:
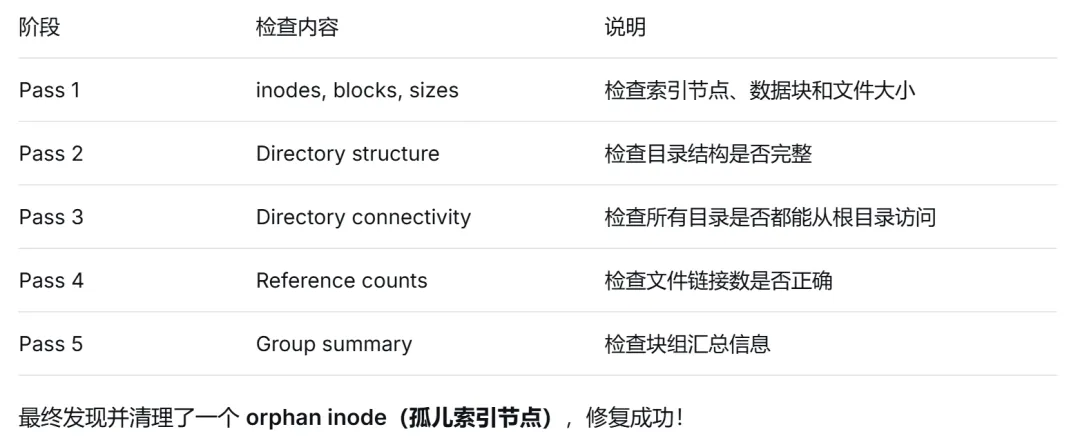
3.4 重启系统
reboot -f
使用
-f参数强制重启,因为救援环境没有完整的 init 系统,普通reboot可能卡住。四、修复后验证
重启后,系统正常进入启动流程,所有服务都显示
[OK]:
随后通过 SSH 成功登录:

五、预防建议
经过这次教训,我总结了几个重要建议:

六、常用命令速查表
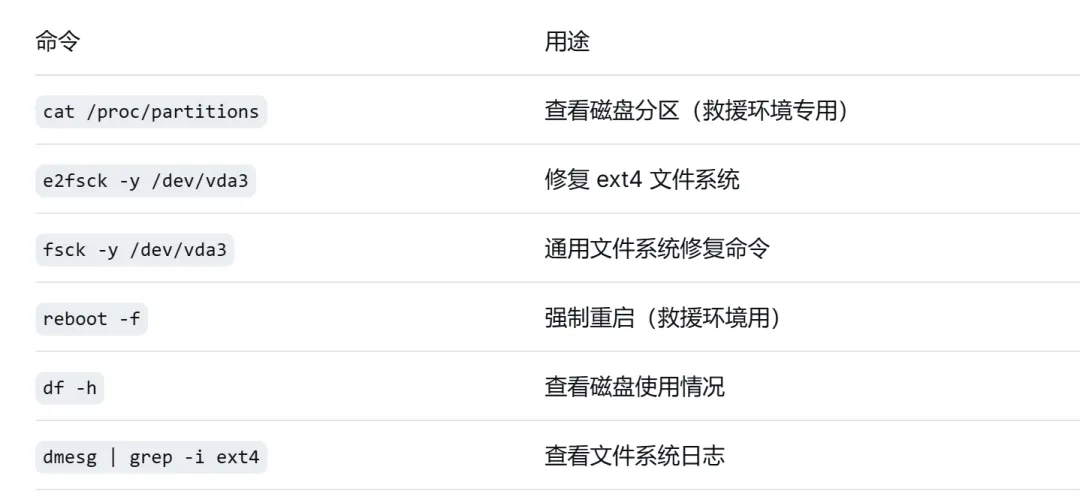
七、总结
这次服务器故障排查过程,总共经历了以下几个阶段:
发现故障 → 进入紧急模式 → 确认问题分区 → 执行 e2fsck 修复 → 重启验证 → 恢复正常
核心经验:
希望这篇文章能帮助到遇到类似问题的运维同行。如果你有更好的修复经验,欢迎在评论区分享交流
不要慌。 Emergency Mode 看着吓人,但其实绝大多数文件系统问题都能通过
e2fsck修复。设备名可能变化。 在救援环境中,
vda可能变成wda,关注分区号(如vda3)比关注设备名更重要。检查 /proc/partitions。 这个文件在任何 Linux 环境都存在,是救援模式的“救命稻草”。
善用云平台的控制台。 VNC 管理终端是最后一层保障,即使 SSH 完全连不上,还能通过它操作。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- Python数据可视化:3个库让你的论文图表从凑合到顶刊级别
- TwinCAT、Python、EEL、HTML/JS——四层架构,打通自动化HMI
- 【好书推荐】基于Python的金融分析与风险管理 畅享版 基础卷+应用卷+拓展卷 全3册 斯文
- 2024年全国青少年信息素养大赛python复赛真题+解析
- ffmpeg+python可视化分割视频
- 别再浪费Token!这8个Python调用大模型API的实战技巧,帮你避开99%的坑
- Linux 7.2-rc1 释出
- Linux 内核升级与旧内核清理实战指南(以 Debian/Ubuntu 系为例)
- linux运维指令,被它打下来
- Azure Linux 4.0深度解析:微软首个通用Linux发行版的技术架构与战略意图
