一、Background
页面通过page fault用户层页面的申请,在实际应用中我们会产生很多疑问,带着这些疑问展开对page access的分析。
申请后的页面一定被访问吗?什么场景中页面才会被访问?被访问后会设置什么标签吗?
被访问的页面能被回收吗?如果被访问页面不能被回收那么在什么场景中清除被访问标签?
二、Source code analysis
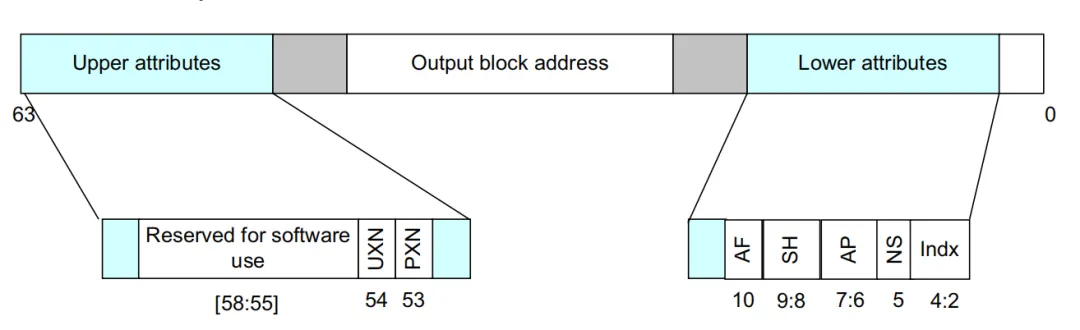
页面分为两种类型anonymous folio、file-backed folio两种不同类型页面的访问查询方式是存在差异的,基于此从整体描述后在细节中进行区分,更好的理解页面访问,回收过程。无论什么页面的访问核心判断依据是 Access Flag (AF)。
Check access
通过AF位,判断改地址是否被访问,在功过MMU机制将虚拟地址转化为PTE,通过判断改PTE即可获取改页面的访问状态。
#define PTE_AF (_AT(pteval_t, 1) << 10) /* Access Flag *///直观判断该pte对应的AF bit是否被访问,是判断pte是否被访问的最常用方式。#define pte_young(pte) (!!(pte_val(pte) & PTE_AF))static inline int __ptep_test_and_clear_young(struct vm_area_struct *vma, unsigned long address, pte_t *ptep){pte_t old_pte, pte;//获取pte,防止被优化采用READ_ONCE方式读区 pte = __ptep_get(ptep);do { //保存pte,保存源数据,为后续可能的数据变化保存初始值 old_pte = pte; //清除AF,无论源AF参数如何强制AF = 0 pte = pte_mkold(pte); /* 原子比较并交换: * 若*ptep == old_pte,说明改数据并没有被其他并发的操作修改数据是一致的, * 则将*ptep更新为pte完成更新(clear AF, AF = 0), 返回操作前内存中的实际值(也就是old_pte); * * 若*ptep != old_pte,说明数据已经被更新(数据一致性发生变化),则不做任何修改,直接返回当前实际值(被并发修改后的实际值) */pte_val(pte) = cmpxchg_relaxed(&pte_val(*ptep), pte_val(old_pte), pte_val(pte)); } while (pte_val(pte) != pte_val(old_pte));//当pte数值完成更新后直接跳出循环,结束自旋. /* * 循环退出时不变式:pte == old_pte(CAS 成功前内存中的旧值) * 返回的是清除 AF 之前 PTE 的 young 状态: * true → 页面在上个扫描周期内被访问过 * false → 未被访问,回收路径可考虑回收该页 * * 注意:此时 *ptep 已被更新为 AF=0(新值), * 但 pte 变量持有的是旧值,两者不同。 */return pte_young(pte);}
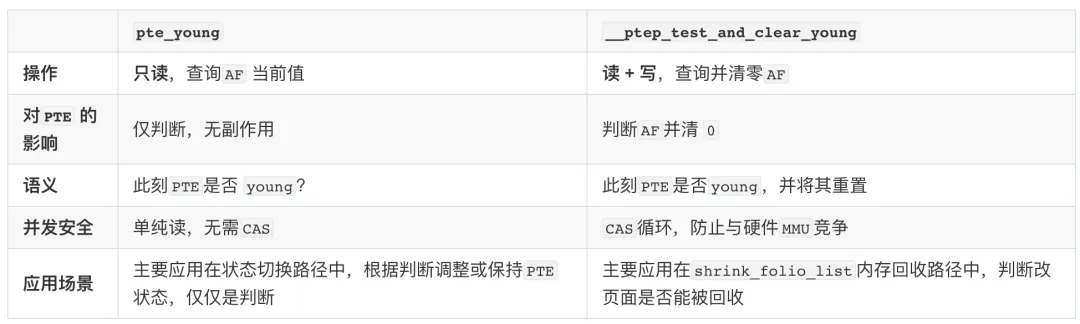
判断PTE是否被访问存在两种常用方式pte_young、__ptep_test_and_clear_young,二者存在一定的差异,故此在应用场景中也有所差异。pte_young VS __ptep_test_and_clear_young的本质区别,差异导致应用场景不同。
//判断pte是否被访问,如果被访问则return true,并清除AF BIT;如果该pte未被访问则return false;//如果此时不清除该状态则对应的pte将一直处在被访问状态,从系统内存循环使用的角度是不合理的:假设一个address被访问//但是也仅仅是被访问过一次系统内存是有限的,如果不清除该状态则导致该页面一直无法被回收,这显然是不合理的。static inline int __ptep_clear_flush_young(struct vm_area_struct *vma, unsigned long address, pte_t *ptep){int young = __ptep_test_and_clear_young(vma, address, ptep);if (young) {flush_tlb_page_nosync(vma, address); }return young;}#define ptep_clear_flush_young __ptep_clear_flush_young#define ptep_clear_flush_young_notify ptep_clear_flush_young
该判断的经典应用场景就是:在shrink_folio_list内存回收过程folio_check_references检测改页面是否被访问,判断改页面是否能够被回收。该过程在[[Linux Rmap]]文档中将做详细的介绍。这里引入出一个问题为什么要采用test-and-clear模式?
若页面对应的PTE被访问后如果不做clear pte动作,随着下一轮的扫描无法反应该PTE 在本轮扫描中是否被访问,则改页面将无法被"观测",故此本轮扫描记录下访问状态(返回值),同时归零 AF, 使下一轮扫描能独立判断"两次扫描之间是否有新的访问,观测出改页面的被访问的频次反应出页面的冷热。
若页面对应的PTE被访问后如果不做clear pte动作,随着系统的运行页面将无法被回收导致其他应用的内存申请受到严重的限制导致系统的异常。
Set access
PTE被访问存在两种路径:硬件设置、软件设置;两种不同的方式在不同的应用场景中发挥重要作用。
Hardware set
阅读ARM Architecture Reference Manual官方手册可知ARM架构存在Hardware management of the Access flag模式,如下描述:
zcat /proc/config.gz | grep ARM64_HW_AFDBMCONFIG_ARM64_HW_AFDBM=y
结合Linux kernel源码如下:Hardware management of the Access flag is enabled
根据信息描述大致做如下汇总:
TCR_EL1.HA 字段定义:
HA, bit[39]:Hardware management of the Access flag0b0:Hardware management of the Access flag is disabled0b1:Hardware management of the Access flag is enabled
When enabled, a translation table entry Access flag that is 0 will be set to 1 by the hardware on an access, rather than causing an Access flag fault.
Access Flag 置位时机:
When TCR_ELx.HA = 1, when a translation table walk accesses a translation table entry with the Access flag set to 0, the translation hardware:
Performs an atomic read-modify-write to set the Access flag to 1Does not generate an Access flag fault
在系统启动阶段通过proc.S:检测硬件是否支持Hardware update of the Access Flags,若支持则通过置位TCR_EL1.HA开启Hardware management of the Access flag功能, 让MMU自动维护页表项的AF。
#ifdef CONFIG_ARM64_HW_AFDBM/* * Enable hardware update of the Access Flags bit. * Hardware dirty bit management is enabled later, * via capabilities. */ mrs x9, ID_AA64MMFR1_EL1 ubfx x9, x9, ID_AA64MMFR1_EL1_HAFDBS_SHIFT, #4 cbz x9, 1f orr tcr, tcr, #TCR_EL1_HA // hardware Access flag update
通过MMU进行PTE检索过程中,访问地址的对应PGD -> PUD -> PMD -> PTE地址对应的PTE AF会被硬件自动更新,标记被访问过。
/* * On arm64 without hardware Access Flag, copying from user will fail because * the pte is old and cannot be marked young. So we always end up with zeroed * page after fork() + CoW for pfn mappings. We don't always have a * hardware-managed access flag on arm64. */#define arch_has_hw_pte_young cpu_has_hw_af/* Check whether hardware update of the Access flag is supported */staticinlineboolcpu_has_hw_af(void){ u64 mmfr1;//编译时未开启,直接返回false,硬件管理AF功能不支持if (!IS_ENABLED(CONFIG_ARM64_HW_AFDBM))return false;/* * Use cached version to avoid emulated msr operation on KVM * guests. */ //读缓存的CPU特性寄存器, 提取HAFDBS字段是否非零 mmfr1 = read_sanitised_ftr_reg(SYS_ID_AA64MMFR1_EL1);return cpuid_feature_extract_unsigned_field(mmfr1, ID_AA64MMFR1_EL1_HAFDBS_SHIFT);}
在内核软件开发设计中,通过arch_has_hw_pte_young可判断hardware Access Flag功能是否支持并开启,如果是则该过程中硬件在MMU过程中会自动设置PTE AF = 1标记页面被访问。
/* * On some architectures hardware does not set page access bit when accessing * memory page, it is responsibility of software setting this bit. It brings * out extra page fault penalty to track page access bit. For optimization page * access bit can be set during all page fault flow on these arches. * To be differentiate with macro pte_mkyoung, this macro is used on platforms * where software maintains page access bit. * * The default implementation is a no-op, suitable for architectures where * hardware automatically sets the access/young bit (arch_has_hw_pte_young() * returns true, e.g. ARM64 with FEAT_HAFDBS, x86). On such platforms the MMU * sets AF atomically during the translation table walk, so software does not * need to set it explicitly on the fault path. * * Architectures that lack hardware AF support (e.g. MIPS) must override this * by defining their own pte_sw_mkyoung (typically aliased to pte_mkyoung) so * that the access bit is set in software during page fault handling. */#ifndef pte_sw_mkyoungstaticinlinepte_tpte_sw_mkyoung(pte_t pte){return pte;}#define pte_sw_mkyoung pte_sw_mkyoung#endif
通过函数可以看到pte_sw_mkyoung仅仅获取pte也就是一个nop操作,为保持逻辑的一致性调用该函数,硬件会自动完成AF设置,或则可以理解为pte_sw_mkyoung只是代码兼容封装,不产生任何AF位修改动作,不能误认为是软件设置AF的逻辑。
Software set
根据当前内核设计,常用的设置方式pte_mkyoung,通过该函数可以设置AF = 1标记PTE被访问。该函数在page fault 过程中该函数得到广泛应用。
staticinlinepte_tpte_mkyoung(pte_t pte){return set_pte_bit(pte, __pgprot(PTE_AF));}
虽然软件设置仅存在一种方式,但是在实际应用中根据场景的不同与ptep_set_access_flags、set_pte_at存在多中组合,确保AF的正确设定。在ARM64框架中硬件会自动设置AF = 1,这样就存在一个问题软件与硬件竞争导致一致性问题:pte_mkyoung往往操作的是一个副本,最终决定是否真的将AF = 1写入需要进行原子的校验(cmpxchg_relaxed)防止与硬件自动设置冲突。这里引申出一个重大的区别:PTE && PAGE已经建立映射关系的场景、PTE && PAGE未建立映射关系的场景。 当PTE、PAGE已经建立映射关系,在进行MMU过程中硬件存在自动设置AF 的可能则采用pte_mkyoung、ptep_set_access_flags配合的方式完成AF的设置。
#define ptep_set_access_flags __ptep_set_access_flagsstatic inline int __ptep_set_access_flags(struct vm_area_struct *vma, unsigned long address, pte_t *ptep, pte_t entry, int dirty){return __ptep_set_access_flags_anysz(vma, address, ptep, entry, dirty, PAGE_SIZE);}/* * This function sets the access flags (dirty, accessed), as well as write * permission, and only to a more permissive setting. * * It needs to cope with hardware update of the accessed/dirty state by other * agents in the system and can safely skip the __sync_icache_dcache() call as, * like __set_ptes(), the PTE is never changed from no-exec to exec here. * * Returns whether or not the PTE actually changed. */int __ptep_set_access_flags_anysz(struct vm_area_struct *vma, unsigned long address, pte_t *ptep, pte_t entry, int dirty, unsigned long pgsize){pteval_t old_pteval, pteval;pte_t pte = __ptep_get(ptep);int level;if (pte_same(pte, entry))return 0;/* only preserve the access flags and write permission */pte_val(entry) &= PTE_RDONLY | PTE_AF | PTE_WRITE | PTE_DIRTY;/* * Setting the flags must be done atomically to avoid racing with the * hardware update of the access/dirty state. The PTE_RDONLY bit must * be set to the most permissive (lowest value) of *ptep and entry * (calculated as: a & b == ~(~a | ~b)). */pte_val(entry) ^= PTE_RDONLY; pteval = pte_val(pte);do { old_pteval = pteval; pteval ^= PTE_RDONLY; pteval |= pte_val(entry); pteval ^= PTE_RDONLY; pteval = cmpxchg_relaxed(&pte_val(*ptep), old_pteval, pteval); } while (pteval != old_pteval); ...return 1;}
如果未建立映射关系是否就不存在MMU自动设置AF = 1的过程,该过程不存在软件与硬件的竞争关系,故此可以采用非原子的方式进行设置。
staticinlinevoidset_ptes(struct mm_struct *mm, unsignedlong addr,pte_t *ptep, pte_t pte, unsigned int nr){page_table_check_ptes_set(mm, addr, ptep, pte, nr);for (;;) {set_pte(ptep, pte);if (--nr == 0)break; ptep++; pte = pte_next_pfn(pte); }}#endif#define set_pte_at(mm, addr, ptep, pte) set_ptes(mm, addr, ptep, pte, 1)
结合分析,整理pte_mkyoung、ptep_set_access_flags、set_pte_at的应用场景大致如下:
核心区别:已有映射时必须用 ptep_set_access_flags(内部用 cmpxchg),因为硬件MMU可能同时在原子置AF;新建映射时用普通set_pte_at即可,因为此前PTE不存在,不存在竞争。
Set AF
了解完software、hardware set方式后,系统的梳理两个问题:
- 在__handle_mm_fault过程中AF如何设置,在什么场景中(timing时机),采用什么方式设置,采用HW set OR SW set?
- 在shrink_folio_list过程中clear AF但是pte、page的映射关系还在的情况下,如何重新Re-set AF,在什么场景(时机),采用HW set OR SW set?
若PTE、PAGE未建立映射,当虚拟地址被访问时发生page fault,从这个场景作为切入点,针对文件映射、匿名映射进行分析:
staticvm_fault_tdo_anonymous_page(struct vm_fault *vmf){struct vm_area_struct *vma = vmf->vma;unsigned long addr = vmf->address;struct folio *folio;pte_t entry; .../* * Use pte_alloc() instead of pte_alloc_map(), so that OOM can * be distinguished from a transient failure of pte_offset_map(). */if (pte_alloc(vma->vm_mm, vmf->pmd))return VM_FAULT_OOM; .../* Returns NULL on OOM or ERR_PTR(-EAGAIN) if we must retry the fault */ folio = alloc_anon_folio(vmf);if (IS_ERR(folio))return 0;if (!folio)goto oom; ...map_anon_folio_pte_pf(folio, vmf->pte, vma, addr, vmf_orig_pte_uffd_wp(vmf)); ...}staticvoidmap_anon_folio_pte_pf(struct folio *folio, pte_t *pte,struct vm_area_struct *vma, unsigned long addr, bool uffd_wp){const unsigned int order = folio_order(folio);map_anon_folio_pte_nopf(folio, pte, vma, addr, uffd_wp);add_mm_counter(vma->vm_mm, MM_ANONPAGES, 1L << order); ...}voidmap_anon_folio_pte_nopf(struct folio *folio, pte_t *pte,struct vm_area_struct *vma, unsigned long addr,bool uffd_wp){const unsigned int nr_pages = folio_nr_pages(folio);pte_t entry = folio_mk_pte(folio, vma->vm_page_prot); entry = pte_sw_mkyoung(entry); ...set_ptes(vma->vm_mm, addr, pte, entry, nr_pages);}
可以看到do_anonymous_page匿名页在fault过程中调用pte_sw_mkyoung, 该函数实际上并没有设置PTE AF,而是通过硬件方式设置AF完成了访问标记的设置。再通过文件映射进行梳理:
staticvm_fault_tdo_fault(struct vm_fault *vmf){struct vm_area_struct *vma = vmf->vma;struct mm_struct *vm_mm = vma->vm_mm;vm_fault_t ret;/* * The VMA was not fully populated on mmap() or missing VM_DONTEXPAND */if (!vma->vm_ops->fault) { ... } else if (!(vmf->flags & FAULT_FLAG_WRITE)) ret = do_read_fault(vmf);else if (!(vma->vm_flags & VM_SHARED)) ret = do_cow_fault(vmf);else ret = do_shared_fault(vmf); ...return ret;}staticvm_fault_tdo_read_fault(struct vm_fault *vmf){vm_fault_t ret = 0;struct folio *folio; ... ret = __do_fault(vmf);if (unlikely(ret & (VM_FAULT_ERROR | VM_FAULT_NOPAGE | VM_FAULT_RETRY)))return ret; ret |= finish_fault(vmf); ...return ret;}staticvm_fault_tdo_cow_fault(struct vm_fault *vmf){struct vm_area_struct *vma = vmf->vma;struct folio *folio;vm_fault_t ret; ... ret = __do_fault(vmf); ... __folio_mark_uptodate(folio); ... ret |= finish_fault(vmf); ...return ret;}staticvm_fault_tdo_shared_fault(struct vm_fault *vmf){struct vm_area_struct *vma = vmf->vma; ... ret = __do_fault(vmf);if (unlikely(ret & (VM_FAULT_ERROR | VM_FAULT_NOPAGE | VM_FAULT_RETRY)))return ret; ... ret |= finish_fault(vmf); ...return ret;}finish_fault| set_pte_range| | pte_t entry;| | entry = mk_pte(page, vma->vm_page_prot);| | entry = pte_sw_mkyoung(entry);
通过分析可以看到file-backed fault调用pte_sw_mkyoung,该函数实际上并没有设置PTE AF,而是通过硬件方式设置AF完成了访问标记的设置。
当PTE、PAGE存在映射关系时,该过程存在一定的差异,在handle_pte_fault过程中pte_none()为假,pte_present()为真
spin_lock(vmf->ptl);entry = vmf->orig_pte; // PTE 存在但 AF=0...entry = pte_mkyoung(entry); //设置副本将,将副本AF无条件置1(软件构造新值)if (ptep_set_access_flags(vmf->vma, vmf->address, vmf->pte, entry, vmf->flags & FAULT_FLAG_WRITE)) update_mmu_cache_range(...);else fix_spurious_fault(vmf, PGTABLE_LEVEL_PTE);
__ptep_set_access_flags_anysz 通过CAS策略检查数据没有被硬件修改的前提下,将上文中设置的pte_mkyoung强制写入到结构体中,完成PTE AF的软件标记。该策略的核心在于通过软件方式完成AF设定,但为了方式数据被MMU硬件修改则通过CAS进行保护(由此可以看出该模式下存在硬件设置的可能性)。
//Step1:只保留需要更新的访问权限字段pte_val(entry) &= PTE_RDONLY | PTE_AF | PTE_WRITE | PTE_DIRTY;pte_val(entry) ^= PTE_RDONLY;//Step2:CAS loop 原子 OR 进现有 PTEpteval = pte_val(pte);do { old_pteval = pteval; pteval ^= PTE_RDONLY; pteval |= pte_val(entry); //OR:只升权限,不降权 pteval ^= PTE_RDONLY; pteval = cmpxchg_relaxed(&pte_val(*ptep), old_pteval, pteval);} while (pteval != old_pteval);
FEAT_HAFDBS系统中,在shrink_folio_list当中当检测到page对应的PTE YOUNG则SW Clear Young,完成PTE AF bit的清理,此时PTE PAGE Mapped映射关系正常存在。页面再次被访问时通过MMU机制若检测到PTE对应的AF = 0硬件会自动将PTE对应的AF = 1标记访问,重新完成设置。
Clear access
通过pte_mkold清除访问标签,在实际操作中因存在硬件设置AF功能的存在我们往往不能直接调用pte_mkold函数,避避免硬件设置后我们强制清除AF导致一致性问题出现。
staticinlinepte_tpte_mkold(pte_t pte){return clear_pte_bit(pte, __pgprot(PTE_AF));}
正确的操作是采用cmpxchg_relaxed方式,清除PTE(PMD等更高级的接口此处不谈)级别的接口如下
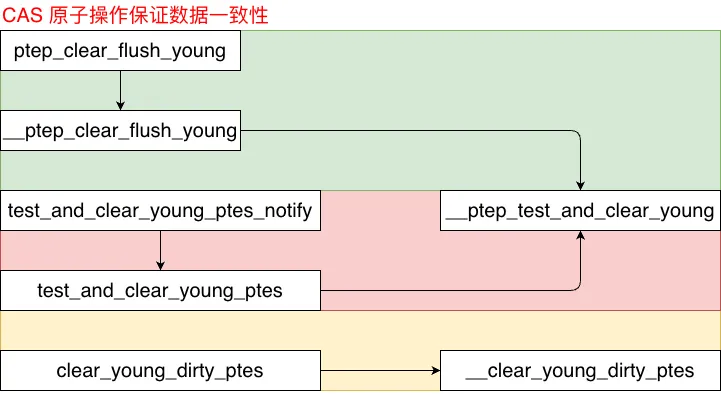
#define clear_flush_young_ptes_notify clear_flush_young_ptesclear_flush_young_ptes| __ptep_clear_flush_young| | __ptep_test_and_clear_young#define test_and_clear_young_ptes_notify test_and_clear_young_ptestest_and_clear_young_ptes| __ptep_test_and_clear_young| | __ptep_test_and_clear_youngstatic inline int __ptep_test_and_clear_young(struct vm_area_struct *vma, unsigned long address, pte_t *ptep){pte_t old_pte, pte;//获取pte,防止被优化采用READ_ONCE方式读区 pte = __ptep_get(ptep);do { //保存pte,保存源数据,为后续可能的数据变化保存初始值 old_pte = pte; //清除AF,无论源AF参数如何强制AF = 0 pte = pte_mkold(pte); /* 原子比较并交换: * 若*ptep == old_pte,说明改数据并没有被其他并发的操作修改数据是一致的, * 则将*ptep更新为pte完成更新(clear AF, AF = 0), 返回操作前内存中的实际值(也就是old_pte); * * 若*ptep != old_pte,说明数据已经被更新(数据一致性发生变化),则不做任何修改,直接返回当前实际值(被并发修改后的实际值) */pte_val(pte) = cmpxchg_relaxed(&pte_val(*ptep), pte_val(old_pte), pte_val(pte)); } while (pte_val(pte) != pte_val(old_pte));//当pte数值完成更新后直接跳出循环,结束自旋. /* * 循环退出时不变式:pte == old_pte(CAS 成功前内存中的旧值) * 返回的是清除 AF 之前 PTE 的 young 状态: * true → 页面在上个扫描周期内被访问过 * false → 未被访问,回收路径可考虑回收该页 * * 注意:此时 *ptep 已被更新为 AF=0(新值), * 但 pte 变量持有的是旧值,两者不同。 */return pte_young(pte);}#define clear_young_dirty_ptes __clear_young_dirty_ptes__clear_young_dirty_ptes| __clear_young_dirty_ptestatic inline void __clear_young_dirty_ptes(struct vm_area_struct *vma, unsigned long addr, pte_t *ptep, unsigned int nr, cydp_t flags){pte_t pte;for (;;) { pte = __ptep_get(ptep);/*当flags 同时包含CYDP_CLEAR_YOUNG、CYDP_CLEAR_DIRTY直接set_pte * 快速清除dirty, Access */if (flags == (CYDP_CLEAR_YOUNG | CYDP_CLEAR_DIRTY)) __set_pte(ptep, pte_mkclean(pte_mkold(pte)));else//若flags仅包含一个标志则走慢速路径,精准清除dirty or Access标签 __clear_young_dirty_pte(vma, addr, ptep, pte, flags);if (--nr == 0)break; ptep++; addr += PAGE_SIZE; }}//实现与__ptep_test_and_clear_young类似,增加了清除dirty的功能static inline void __clear_young_dirty_pte(struct vm_area_struct *vma, unsigned long addr, pte_t *ptep, pte_t pte, cydp_t flags){pte_t old_pte;do { old_pte = pte;if (flags & CYDP_CLEAR_YOUNG) pte = pte_mkold(pte);if (flags & CYDP_CLEAR_DIRTY) pte = pte_mkclean(pte);pte_val(pte) = cmpxchg_relaxed(&pte_val(*ptep), pte_val(old_pte), pte_val(pte)); } while (pte_val(pte) != pte_val(old_pte));}
通过原子及非原子操作完成PTE AF 的清理,能够正确的清除PTE AF保证系统的正常运行,同时在内存管理过程中能够正确识别被访问页面,提高页面内存管理的正确性以及内存管理效率。
三、Think and Verify
系统判断页面回收存在多种途径,站在页面page角度可以通过PG_referenced进行判断,站在PTE角度可以通过AF进行判断,二者存在什么关联与差异?
如上文分析PTE是基于虚拟地址的角度进行判断,而PG_referenced是基于物理页面判断,在内存回收过程中通过判断PageReferenced判断页面在LRU的状态,决定页面是否能被流转,是否能被回收。在shrink_folio_list流程中通过folio_check_references判断页面是否被访问,当检查page对应的PTE被访问时设置PG_referenced将页面重新流转到active进行保护,给了页面"二次机会",详细的[[Linux Rmap]] 流程参考该文档。
staticenum folio_references folio_check_references(struct folio *folio, struct scan_control *sc){int referenced_ptes, referenced_folio;vm_flags_t vm_flags; referenced_ptes = folio_referenced(folio, 1, sc->target_mem_cgroup, &vm_flags); referenced_folio = folio_test_clear_referenced(folio);if (referenced_ptes) {/* * All mapped folios start out with page table * references from the instantiating fault, so we need * to look twice if a mapped file/anon folio is used more * than once. * * Mark it and spare it for another trip around the * inactive list. Another page table reference will * lead to its activation. * * Note: the mark is set for activated folios as well * so that recently deactivated but used folios are * quickly recovered. */folio_set_referenced(folio);if (referenced_folio || referenced_ptes > 1)return FOLIOREF_ACTIVATE; ... } ...}
PTE作为瞬间的状态值、PG_referenced作为持久的状态值,通过二者的结合将页面访问与页面检查结合起来,共同地维护了系统页面的相对精确的流转与回收。
四、Reference
https://lore.kernel.org/linux-mm/



 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
