[语法][cudaTile 编程][传统软件工程师转行 AI 需要掌握的一千个知识点]
- 2026-07-14 13:14:31
经典模型+ Python cuda编程
一手理论+一手实践→天下我有
列个提纲,一壶酒,一个手机,上班路上一小时,一写写一年👌🥊🥊
没有牛逼的人,只有坚持到底的人
这篇文章估计要写好久…
不对,写一点,发一点
简单,才足以坚持,坚持才足以完成
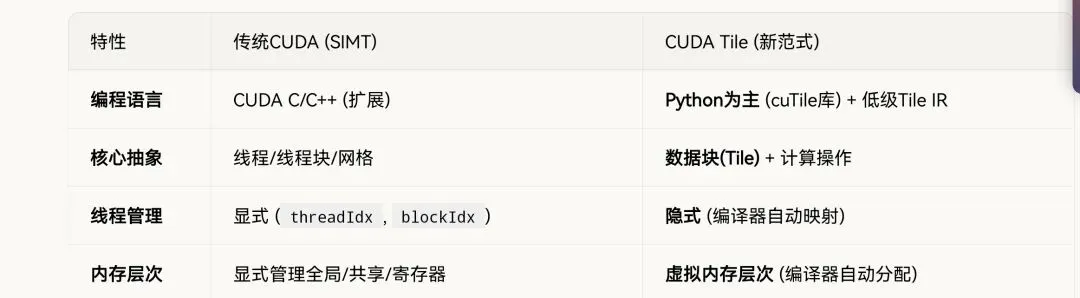

// 明确指定线程组织dim3 gridSize(blocksX, blocksY);dim3 blockSize(threadsPerBlockX, threadsPerBlockY);matmul_kernel<<<gridSize, blockSize>>>(A, B, C, M, N, K);
# cuTile Python - 只需描述数据分块@cutile.primitivedef matmul(M: cutile.dim, N: cutile.dim, K: cutile.dim,A: cutile.tensor[M, K], B: cutile.tensor[K, N], C: cutile.tensor[M, N]):# 定义Tile大小tile_m = cutile.constant(128)tile_n = cutile.constant(128)tile_k = cutile.constant(32)# 自动生成分块计算for i in cutile.axis(0, M, tile_m): # 外层循环自动并行化for j in cutile.axis(0, N, tile_n): # 编译器决定并行策略accum = cutile.allocate((tile_m, tile_n), "float32")for k in cutile.axis(0, K, tile_k):a_tile = A[i:i+tile_m, k:k+tile_k]b_tile = B[k:k+tile_k, j:j+tile_n]accum = cutile.dot(a_tile, b_tile, accum)C[i:i+tile_m, j:j+tile_n] = accum
// 需要显式管理共享内存__shared__ float tileA[TILE_SIZE][TILE_SIZE];__shared__ float tileB[TILE_SIZE][TILE_SIZE];// 手动加载到共享内存int tx = threadIdx.x, ty = threadIdx.y;tileA[ty][tx] = A[row * K + col];tileB[ty][tx] = B[row * N + col];__syncthreads(); // 必须显式同步
# 编译器自动处理内存层次@cutile.primitivedef conv2d(input: cutile.tensor[N, H, W, C],filter: cutile.tensor[Fh, Fw, C, M],output: cutile.tensor[N, H_out, W_out, M]):# 编译器决定何时使用共享内存、寄存器tile_n = 8 # batch维度分块tile_h = 16 # 高度分块tile_w = 16 # 宽度分块tile_c = 32 # 通道分块# 自动生成内存层次代码for n, h, w, m in cutile.grid(N, H_out, W_out, M):for fh, fw, c in cutile.reduction(Fh, Fw, C):# 编译器决定内存放置策略in_tile = input[n, h*stride+fh, w*stride+fw, c]filter_tile = filter[fh, fw, c, m]output[n, h, w, m] += in_tile * filter_tile
// 网格/线程块映射int row = blockIdx.y * blockDim.y + threadIdx.y;int col = blockIdx.x * blockDim.x + threadIdx.x;// 并行循环需要手动展开if (row < M && col < N) {float sum = 0.0f;for (int k = 0; k < K; k++) {sum += A[row * K + k] * B[k * N + col];}C[row * N + col] = sum;}
# 声明并行维度@cutile.primitivedef batched_gemm(batch: cutile.dim, M: cutile.dim, N: cutile.dim, K: cutile.dim,A: cutile.tensor[batch, M, K], B: cutile.tensor[batch, K, N],C: cutile.tensor[batch, M, N]):# cutile.axis 定义并行维度for b in cutile.axis(0, batch, 8): # batch维度并行for i in cutile.axis(0, M, 128): # M维度并行for j in cutile.axis(0, N, 128): # N维度并行# reduction维度自动处理accum = cutile.sum_reduce(K, 32,lambda k: A[b, i, k] * B[b, k, j])C[b, i, j] = accum
DeepSeek R1
传统软件工程师转行 AI 需要掌握的一千个知识点→神经网络→强化学习 DeepSeek :R1
强化学习
传统软件工程师转行 AI 需要掌握的一千个知识点→神经网络→ 强化学习 Q-Learning、DQN、PG、PPO
多模态
传统软件工程师转行 AI 需要掌握的一千个知识点→神经网络→ 多模态 CLIP
Diffusion
GPT 系列
GPT1 GPT2 GPT3 GPT3.5 GPT4
终于到了这个跨时代的GPT了,足以记录在人类文明史的一页
GPT1
传统软件工程师转行 AI 需要掌握的一千个知识点→神经网络→ GPT1
GPT2 、GPT3
传统软件工程师转行 AI 需要掌握的一千个知识点→神经网络→ GPT2、3
GPT3.5 、GPT4
传统软件工程师转行 AI 需要掌握的一千个知识点→神经网络→ GPT3.5、4
Transformer传统软件工程师转行 AI 需要掌握的一千个知识点→神经网络→ Transformers
GAN
传统软件工程师转行 AI 需要掌握的一千个知识点→神经网络→ GAN
AlphaGo
传统软件工程师转行 AI 需要掌握的一千个知识点→神经网络→ AlphaGo
传统软件工程师转行 AI 需要掌握的一千个知识点→神经网络→ ResNet
CNN AlexNet VGG
传统软件工程师转行 AI 需要掌握的一千个知识点→神经网络→ CNN AlexNet VGG
VAE
传统软件工程师转行 AI 需要掌握的一千个知识点→神经网络→ VAE
深度信念网络
传统软件工程师转行 AI 需要掌握的一千个知识点→神经网络→深度信念网络
RNN Lstm传统软件工程师转行 AI 需要掌握的一千个知识点→神经网络→RNN
CNN Lenet-5传统软件工程师转行 AI 需要掌握的一千个知识点→神经网络→CNN
Hopfield网络&&玻尔兹曼机传统软件工程师转行 AI 需要掌握的一千个知识点→神经网络→ Hopfield网络&玻尔兹曼机
反向传播传统软件工程师转行 AI 需要掌握的一千个知识点→神经网络→反向传播
多层感知机
传统软件工程师转行 AI 需要掌握的一千个知识点→神经网络→多层感知机
感知机
传统软件工程师转行 AI 需要掌握的一千个知识点→神经网络→感知机
MP 神经元
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 2026 独立开发真相:写代码是最简单的,找流量才是地狱模式
- 最新!兰陵县行政区划代码公布
- 新赛道OI 2026年“英才杯”跨年编程赛:中学组文字题解
- 最新!兰陵县行政区划代码公布
- 安卓手机Shell编程实现自动点击器完全指南
- 2025全国大学生高新技术竞赛——算法编程能力大赛
- 最新发布!泰安市行政区划代码来了!3709……来看看你老家是哪串数字?
- 实验室同门还在跑代码,我已靠这个工具悄悄写完第二篇生信SCI了…(附免费工具)
- 最新发布!泰安市行政区划代码来了!3709……来看看你老家是哪串数字?
- 新赛道OI 2026年“英才杯”跨年编程赛:获奖名单及排名公布
