在Linux系统运维与应用开发场景中,磁盘IO延迟过高是典型的性能瓶颈问题,其排查需结合多元工具,从现象到本质层层拆解。本文将复盘一次真实的磁盘IO延迟高问题定位全流程,清晰呈现从常规工具排查遇阻,到借助动态追踪工具实现突破的实战思路,为运维及开发人员提供可复用的问题解决参考。
为更清晰地梳理排查逻辑,先给出本次磁盘IO延迟高问题的整体排查框架,具体如下:
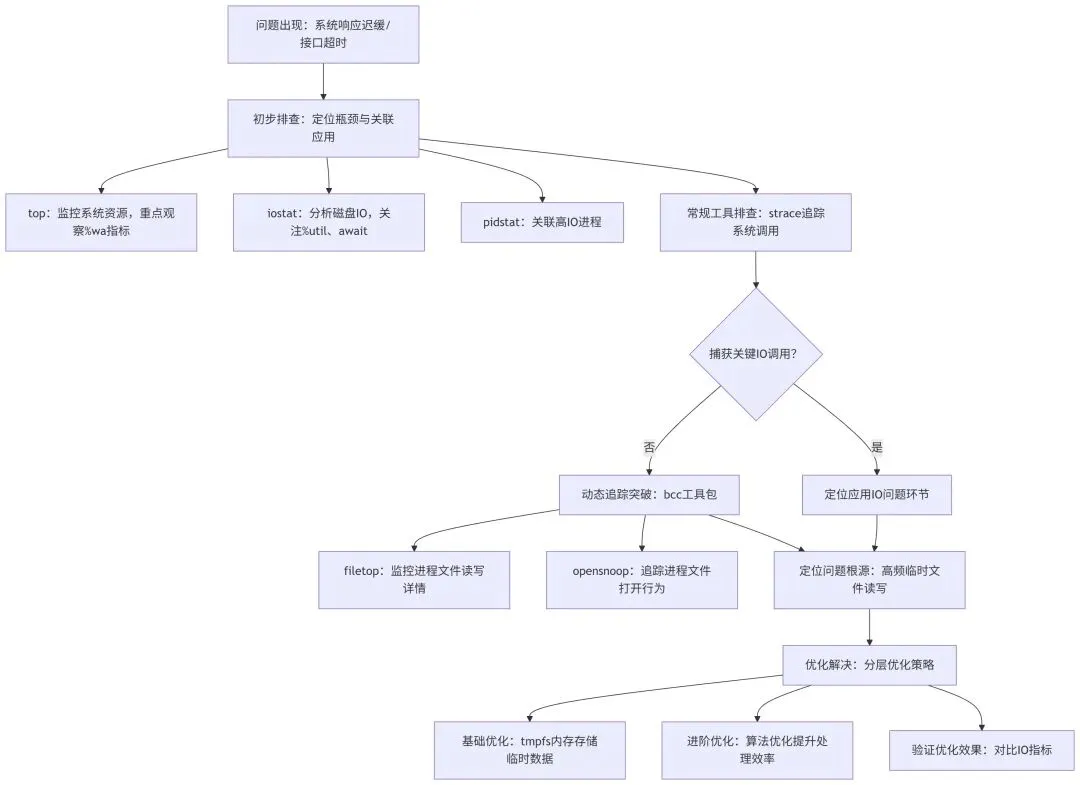
后续将围绕该框架,结合实验复现过程,详细拆解每个环节的实操方法与排查思路。
一、实验准备与环境说明
本次实验基于CentOS 7.9系统,服务器配置为4核8G内存,磁盘为机械硬盘(HDD)。实验目的是复现并定位“应用高频读写临时文件导致磁盘IO延迟高”的问题,核心工具包括top、iostat、pidstat、strace及bcc工具包(含filetop、opensnoop)。
1. 实验代码(模拟高频读写临时文件的应用)
编写Python代码模拟案例应用的核心行为——循环创建临时文件、写入随机字符串、读取文件内容后删除文件,以此复现高频临时文件读写场景。代码如下:
import osimport tempfileimport randomimport stringdefgenerate_random_string(length=1024):"""生成随机字符串,模拟业务数据"""return''.join(random.choice(string.ascii_letters + string.digits) for _ in range(length))defsimulate_temp_file_io(loop_count=10000):"""模拟高频读写临时文件"""for _ in range(loop_count):# 创建临时文件(默认存储在/tmp目录)with tempfile.NamedTemporaryFile(mode='w+', delete=True) as tmp_file:# 写入随机数据(1KB) tmp_file.write(generate_random_string())# 刷新缓冲区,确保数据写入磁盘 tmp_file.flush() os.fsync(tmp_file.fileno())# 读取文件内容 tmp_file.seek(0) content = tmp_file.read() print(f"完成{loop_count}次临时文件读写循环")if __name__ == "__main__": simulate_temp_file_io()
代码说明:通过tempfile.NamedTemporaryFile创建临时文件,默认存储在/tmp目录(磁盘分区);每次循环执行“写入1KB随机数据→强制刷盘→读取数据”操作,共执行10000次循环,以此模拟高频临时文件IO场景。
2. 实验流程
- 环境检查:确认系统已安装必要工具(top、iostat、pidstat、strace),并安装bcc工具包(安装方法:
yum install -y bcc bcc-tools)。 - 启动问题模拟:运行上述实验代码,触发高频临时文件读写行为。
- 初步排查:使用top、iostat命令定位磁盘IO瓶颈,结合pidstat关联至实验代码进程。
- 常规工具排查:使用strace追踪实验代码进程的write系统调用,观察是否能捕获关键IO操作。
- 动态追踪排查:使用bcc工具包的filetop、opensnoop工具,定位实验代码的临时文件读写行为。
- 验证优化效果:实施内存存储临时数据的优化方案,重新运行实验代码,对比优化前后的磁盘IO指标。
二、初遇问题:定位磁盘IO瓶颈与关联应用
运行实验代码后,系统响应明显迟缓,符合业务侧反馈的问题现象。基于经验判断,优先排查系统资源瓶颈,因此选用最常用的系统监控工具开展初步诊断。
第一步通过top命令监控系统整体资源占用。分析发现,系统CPU整体使用率处于低位,各进程CPU分配均衡,可排除CPU瓶颈;但关键指标%wa(IO等待时间占比)持续飙升至30%以上,明确指向系统存在严重的IO等待问题。
为精准定位磁盘IO状况,进一步执行iostat -x 1命令(-x参数用于输出详细IO统计信息,1表示每秒刷新一次)。结果显示,目标磁盘的%util(磁盘繁忙度)接近100%饱和,同时await(IO请求平均等待时间)远超正常阈值,直接验证了磁盘IO存在严重瓶颈的判断。
结合top与iostat的输出结果,进一步关联定位至具体进程:先通过iostat锁定高IO负载的磁盘,再利用pidstat -d 1命令监控各进程的磁盘IO行为,最终精准锁定业务反馈对应的案例应用进程——该进程的磁盘读写请求量远超其他进程,初步判定磁盘IO瓶颈由该应用引发。
三、常规排查遇阻:strace未捕获关键write调用
明确瓶颈源头后,下一步需定位应用内部触发大量磁盘IO的具体环节。参考上一案例中通过strace追踪进程系统调用的排查思路,执行strace -p <应用PID> -e trace=write命令,专门追踪该应用的write系统调用,期望定位到频繁写入磁盘的核心代码逻辑。
然而排查陷入僵局:持续追踪数分钟后,strace输出中未捕获到任何write系统调用。这与预期相悖——既然磁盘IO繁忙由该应用导致,理论上应存在高频写入操作。推测可能的原因:应用的IO操作未通过常规write系统调用实现,或存在其他未覆盖的IO场景。
常规strace追踪已无法推进排查,亟需借助更强大的工具挖掘应用底层IO行为。
四、动态追踪突破:bcc工具包锁定临时文件读写问题
常规工具排查遇阻后,转向动态追踪工具——bcc工具包。bcc基于eBPF(扩展Berkeley包过滤器)实现,可高效追踪系统与应用的各类行为(含文件IO、网络通信等),且对系统性能影响极小。其中,filetop与opensnoop工具专为文件IO排查设计,是定位此类问题的利器。
首先启用filetop工具(实时展示系统内进程的文件读写详情,包括进程名、文件名、读写大小、IO速率等核心信息)。运行后很快发现异常:案例应用进程频繁对/tmp目录下的多个临时文件执行读写操作,虽单次读写量不大,但高频次循环导致累计IO负载激增,正是磁盘IO繁忙的根源。
为验证结论,进一步使用opensnoop工具(专注追踪进程文件打开行为)针对性监控目标应用,执行命令opensnoop -p <应用PID>。追踪结果印证:该应用运行期间会循环执行“创建临时文件→打开文件→高频读写→删除文件”的操作,此过程产生的大量磁盘IO请求,直接导致磁盘IO延迟居高不下。
至此,问题根源彻底明确:案例应用的高频临时文件读写操作,是引发磁盘IO瓶颈的核心原因。此前strace未捕获到write调用,推测因应用对临时文件的写入操作通过封装库函数实现,或采用了writev等未追踪的IO相关系统调用;而bcc工具依托eBPF的底层追踪能力,可覆盖更全面的IO行为,最终实现排查突破。
五、问题优化:从简单到进阶的解决方案
问题根源明确后,优化方向清晰。针对“高频临时文件读写导致磁盘IO瓶颈”,可采用“从简单到进阶”的分层优化策略,优先解决核心瓶颈,再逐步提升整体性能。
1. 基础优化:内存替代磁盘存储临时数据
若服务器内存资源充足,最简洁高效的优化方案是将临时文件存储从磁盘(/tmp目录默认位于磁盘分区)迁移至内存。Linux系统的tmpfs文件系统可直接将数据存储于内存,读写速度较磁盘提升一个数量级,能彻底消除临时文件读写带来的磁盘IO瓶颈。
具体实施方式:一是将应用临时文件目录指定为tmpfs挂载点(需提前创建并挂载);二是直接修改应用配置,将临时数据在内存中缓存处理,避免写入磁盘。示例操作:通过mount -t tmpfs -o size=10G tmpfs /app/tmp命令创建tmpfs挂载点,再将应用临时文件目录配置为/app/tmp,即可实现临时数据的内存存储。
2. 进阶优化:算法优化提升数据处理效率
解决磁盘IO瓶颈后,可进一步优化应用数据处理逻辑,提升整体性能。结合应用场景(从临时文件读写特征推测涉及大量单词处理、数据匹配等操作),引入Trie树等高效数据结构与算法,优化数据处理流程。
例如,若应用需执行大量单词查找、匹配或去重操作,Trie树(前缀树)可显著提升查询效率,降低数据处理的时间开销。通过算法优化,不仅能减少CPU资源占用,还可进一步提升应用响应速度,从根源上优化系统性能。
六、关键工具常见参数说明
本次排查过程中用到的核心工具各有侧重,以下整理了关键工具的常见参数及说明,方便后续同类问题排查参考:
| | | |
|---|
| | | |
| | | |
| | 输出详细的IO统计信息,含%util、await等关键指标 | |
| | | |
| | 设置刷新间隔和刷新次数,如iostat -x 1 10表示每秒刷新1次,共10次 | |
| | 显示进程的磁盘IO统计信息,含读写字节数、IO请求数等 | |
| | | |
| | | |
| | 仅追踪指定的系统调用,如write、read、open等 | |
| | | |
| | | |
| | | |
| | | |
| | | |
七、总结与经验沉淀
本次基于实验复现的磁盘IO延迟高问题定位过程,充分凸显“工具选型”在问题排查中的核心作用:常规工具(top、iostat)适用于初步定位瓶颈与关联进程,但面对复杂应用IO行为时,需借助bcc等动态追踪工具的底层能力实现突破。
同时沉淀两大核心经验:
其一,IO问题排查需避免单一工具依赖,应结合各类工具的优势形成互补(如本次通过top/iostat定位瓶颈、pidstat关联进程、strace初步追踪、bcc突破瓶颈);
其二,优化工作需遵循“先解决核心瓶颈,再进阶优化”的原则,优先采用低成本、高效率的方案(如tmpfs内存存储)快速解决问题,再根据业务需求开展深度优化(如算法优化)。

