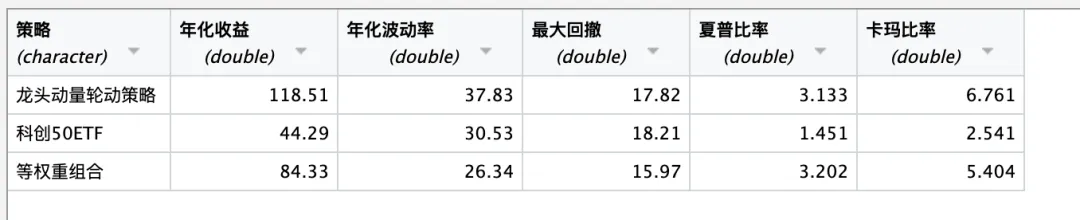
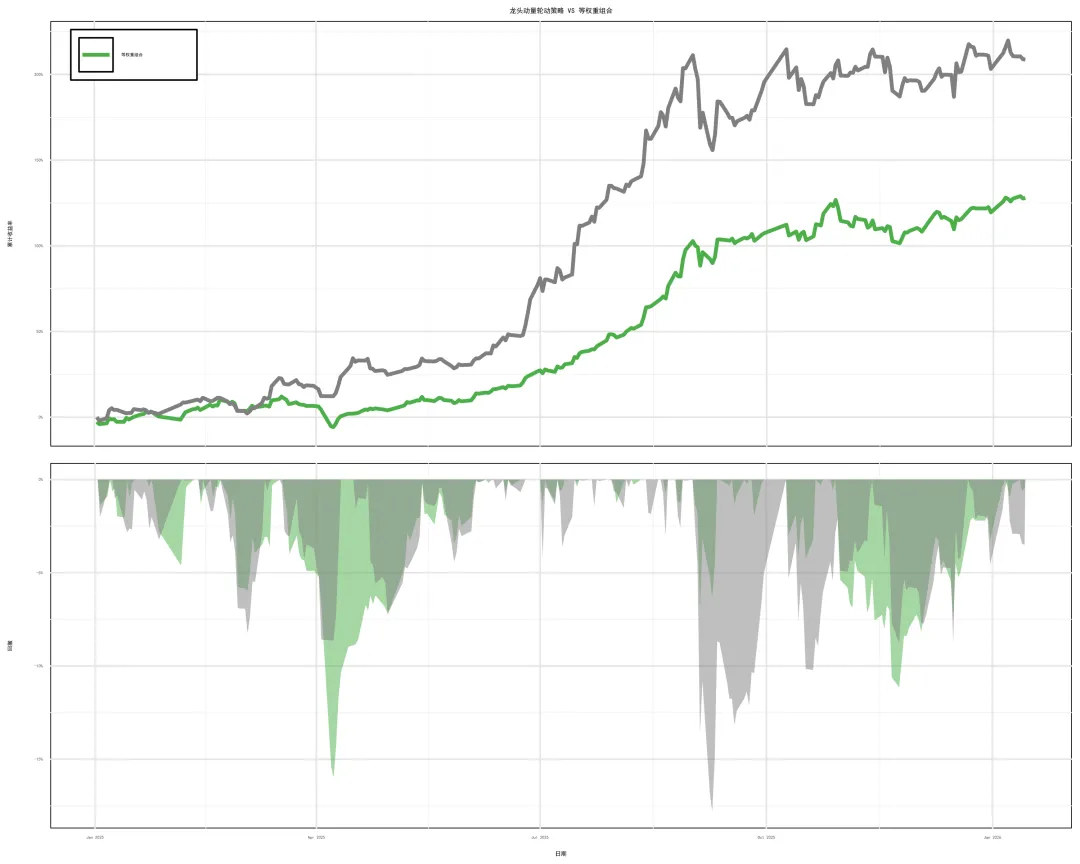
# ==================== 第一部分:加载软件包 ====================if (!require("quantmod")) install.packages("quantmod")if (!require("PerformanceAnalytics")) install.packages("PerformanceAnalytics")if (!require("ggplot2")) install.packages("ggplot2")if (!require("dplyr")) install.packages("dplyr")if (!require("tidyr")) install.packages("tidyr")if (!require("scales")) install.packages("scales")if (!require("patchwork")) install.packages("patchwork")if (!require("cowplot")) install.packages("cowplot")if (!require("RColorBrewer")) install.packages("RColorBrewer")if (!require("knitr")) install.packages("knitr")if (!require("showtext")) install.packages("showtext")library(quantmod) # 金融数据获取与分析library(PerformanceAnalytics) # 投资组合绩效分析library(ggplot2) # 高级绘图library(dplyr) # 数据处理library(tidyr) # 数据整理library(scales) # 图形标度调整library(patchwork) # 图形组合library(cowplot) # 图形组合(更精细的控制)library(RColorBrewer) # 颜色调色板library(knitr) # 报表输出library(showtext) # 字体支持# 添加中文字体支持font_add("simhei", "simhei.ttf")showtext_auto()theme_set(theme_bw(base_family = "simhei")) # 使用bw主题# ==================== 第二部分:配置参数 ====================# 回测时间段backtest_start <- "2024-01-01"backtest_end <- Sys.Date()# 动量计算参数N <- 20 # 动量计算周期(默认20天)K <- 5 # 调仓间隔天数(默认5天,表示每5个交易日调仓一次)L <- 5 # 选择标的数量(默认选择前5名)# 基准参数benchmark_symbol <- "588000.SS" # 科创50ETFbenchmark_name <- "科创50ETF"# 转换为日期类型start_date <- as.Date(backtest_start)end_date <- as.Date(backtest_end)# 定义股票代码和名称(龙头股票)- 使用更常见的股票stock_symbols <- c( "600111.SS", "002460.SZ", "601899.SS", "600988.SS", "002230.SZ", "300750.SZ", "002594.SZ", "603259.SS", "601939.SS", "688256.SS", "601606.SS", "688981.SS", "300502.SZ", "601138.SS", "300308.SZ", "300476.SZ", "300394.SZ", "688041.SS", "601336.SS", "600519.SS", "601288.SS", "601319.SS")stock_names <- c( "北方稀土", "赣锋锂业", "紫金矿业", "赤峰黄金", "科大讯飞", "宁德时代", "比亚迪", "药明康德", "建设银行", "寒武纪", "长城军工", "中芯国际", "新易盛", "工业富联", "中际旭创", "胜宏科技", "天孚通信", "海光信息", "新华保险", "贵州茅台", "农业银行", "中国人保")# 将基准加入股票列表all_symbols <- c(stock_symbols, benchmark_symbol)all_names <- c(stock_names, benchmark_name)cat("==================== 参数设置 ====================\n")cat(sprintf("动量计算周期 N = %d 天\n", N))cat(sprintf("调仓间隔 K = %d 天\n", K))cat(sprintf("选择标的数量 L = %d 只\n", L))cat(sprintf("回测期间: %s 至 %s\n", backtest_start, as.character(end_date)))cat(sprintf("股票数量: %d 只龙头股票\n", length(stock_symbols)))cat(sprintf("基准: %s (%s)\n", benchmark_name, benchmark_symbol))cat("================================================\n\n")# ==================== 第三部分:下载和清洗数据 ====================cat("正在从Yahoo Finance获取数据...\n")# 设置下载重试机制download_data <- function(symbols, from_date, to_date, max_retries = 3) { price_list <- list() for (i in 1:length(symbols)) { symbol <- symbols[i] retry_count <- 0 success <- FALSE while (retry_count < max_retries && !success) { tryCatch( { symbol_data <- getSymbols(symbol, from = from_date, to = to_date, src = "yahoo", auto.assign = FALSE, warnings = FALSE ) # 使用调整后收盘价 price_list[[i]] <- Ad(symbol_data) colnames(price_list[[i]]) <- all_names[i] success <- TRUE cat(sprintf(" √ 成功下载: %s (%s)\n", all_names[i], symbol)) }, error = function(e) { retry_count <- retry_count + 1 if (retry_count == max_retries) { cat(sprintf(" × 下载失败: %s (%s) - %s\n", all_names[i], symbol, e$message)) price_list[[i]] <- NULL } else { cat(sprintf(" ! 重试下载: %s (%s) 第%d次\n", all_names[i], symbol, retry_count)) Sys.sleep(1) # 等待1秒后重试 } } ) } } # 过滤掉NULL值 price_list <- price_list[!sapply(price_list, is.null)] return(price_list)}# 下载数据price_list <- download_data(all_symbols, start_date, end_date)# 检查是否成功下载数据if (length(price_list) == 0) { stop("未能下载任何数据,请检查网络连接和股票代码")}# 合并所有价格数据cat("正在合并数据...\n")price_xts <- do.call(merge, price_list)# 检查数据cat(sprintf("价格数据维度: %d 行 × %d 列\n", nrow(price_xts), ncol(price_xts)))cat(sprintf( "数据时间范围: %s 至 %s\n", as.character(index(price_xts)[1]), as.character(index(price_xts)[nrow(price_xts)])))cat("\n")# ==================== 第四部分:计算每日动量数据 ====================# 动量计算函数calculate_momentum <- function(price_series, window = N) { # 计算日收益率 returns <- dailyReturn(price_series, type = "arithmetic") colnames(returns) <- "Return" # 计算N日平均收益率(动量) momentum <- rollapply(returns, width = window, FUN = mean, align = "right", fill = NA ) colnames(momentum) <- "Momentum" # 计算N日收益率方差(波动率) volatility <- rollapply(returns, width = window, FUN = var, align = "right", fill = NA ) colnames(volatility) <- "Volatility" # 计算调整动量(动量/波动率,使用标准差进行标准化) adj_momentum <- momentum / sqrt(volatility) colnames(adj_momentum) <- "Adj_Momentum" return(list( returns = returns, momentum = momentum, volatility = volatility, adj_momentum = adj_momentum ))}# 为每个股票计算动量指标,以list形式存储cat(sprintf("正在计算%d日动量指标...\n", N))momentum_list <- list()for (stock in colnames(price_xts)) { momentum_list[[stock]] <- calculate_momentum(price_xts[, stock])}# 提取所有股票的调整动量和动量,用于后续选股adj_momentum_all <- do.call(merge, lapply(momentum_list, function(x) x$adj_momentum))momentum_all <- do.call(merge, lapply(momentum_list, function(x) x$momentum))colnames(adj_momentum_all) <- colnames(price_xts)colnames(momentum_all) <- colnames(price_xts)cat(sprintf("动量数据维度: %d 行 × %d 列\n", nrow(adj_momentum_all), ncol(adj_momentum_all)))cat("\n")# ==================== 第五部分:生成每日权重和组合收益率 ====================# 生成每日权重的函数generate_daily_weights <- function(adj_momentum_df, momentum_df, rebalance_freq = K, select_count = L) { # 初始化权重数据框 weights_df <- as.data.frame(adj_momentum_df) weights_df[] <- 0 # 所有值初始化为0 # 获取所有交易日日期 all_dates <- index(adj_momentum_df) # 确定调仓日:从第N个交易日开始,每隔K个交易日调仓一次 if (length(all_dates) < N) { stop(sprintf("数据不足,需要至少%d个交易日的数据,当前只有%d个", N, length(all_dates))) } # 确定所有可能的调仓日 start_idx <- N # 从第N天开始(因为需要N天数据计算动量) rebalance_indices <- seq(start_idx, length(all_dates), by = rebalance_freq) cat(sprintf("总交易日数: %d\n", length(all_dates))) cat(sprintf("调仓日数量: %d\n", length(rebalance_indices))) cat(sprintf("首次调仓日: %s\n", as.character(all_dates[start_idx]))) cat(sprintf("最后调仓日: %s\n", as.character(all_dates[rebalance_indices[length(rebalance_indices)]]))) cat(sprintf("每期选择标的数量: %d\n", select_count)) # 对每个调仓日计算权重 for (rebalance_idx in rebalance_indices) { # 获取当日的调整动量值和动量值 current_adj_momentum <- as.numeric(adj_momentum_df[rebalance_idx, ]) current_momentum <- as.numeric(momentum_df[rebalance_idx, ]) # 筛选动量为正数的标的(排除基准) # 假设基准是最后一列 selectable_idx <- 1:(ncol(adj_momentum_df) - 1) # 排除最后一个(基准) selectable_momentum <- current_momentum[selectable_idx] positive_momentum_idx <- selectable_idx[which(selectable_momentum > 0 & !is.na(selectable_momentum))] if (length(positive_momentum_idx) > 0) { # 获取正动量标的的调整动量值 positive_adj_momentum <- current_adj_momentum[positive_momentum_idx] # 如果正动量标的超过select_count个,选择调整动量排名前select_count的 if (length(positive_momentum_idx) > select_count) { adj_momentum_rank <- order(positive_adj_momentum, decreasing = TRUE) top_idx <- adj_momentum_rank[1:select_count] selected_idx <- positive_momentum_idx[top_idx] selected_adj_momentum <- positive_adj_momentum[top_idx] } else { # 如果不超过select_count个,全部选择 selected_idx <- positive_momentum_idx selected_adj_momentum <- positive_adj_momentum } # 按调整动量大小归一化计算权重 normalized_weights <- selected_adj_momentum / sum(selected_adj_momentum) # 确定该权重生效的日期范围:从当前调仓日到下一个调仓日前一天 if (rebalance_idx == rebalance_indices[length(rebalance_indices)]) { end_idx <- length(all_dates) # 最后一个调仓日 } else { next_rebalance_idx <- rebalance_indices[which(rebalance_indices == rebalance_idx) + 1] end_idx <- next_rebalance_idx - 1 } end_idx <- min(end_idx, length(all_dates)) # 应用权重到该调仓周期内的所有交易日 for (i in rebalance_idx:end_idx) { weights_df[i, selected_idx] <- normalized_weights } } } # 转换为时间序列 weights_xts <- xts(weights_df, order.by = all_dates) colnames(weights_xts) <- colnames(adj_momentum_df) return(weights_xts)}# 生成权重序列cat(sprintf("正在计算每日权重(调仓间隔K=%d天,选择标的L=%d只)...\n", K, L))weights <- generate_daily_weights(adj_momentum_all, momentum_all, K, L)# 将每日权重以list形式存储 - 只保留权重不为0的记录cat("正在创建每日权重列表(只保留权重大于0的记录)...\n")daily_weights_list <- list()weights_df <- as.data.frame(weights) # 转换为数据框# 使用整数索引循环,只保存权重大于0的记录for (i in 1:nrow(weights_df)) { date <- index(weights)[i] # 从原始的xts对象获取日期 # 获取当日的权重向量 weight_vector <- as.numeric(weights_df[i, ]) # 找出权重大于0的股票 positive_weights_idx <- which(weight_vector > 0) if (length(positive_weights_idx) > 0) { # 只保存权重大于0的记录 weight_df <- data.frame( Stock = colnames(weights)[positive_weights_idx], Weight = weight_vector[positive_weights_idx], Date = as.Date(date), stringsAsFactors = FALSE ) # 按日期字符串作为列表的键 daily_weights_list[[as.character(date)]] <- weight_df }}cat(sprintf("成功创建每日权重列表,包含 %d 个交易日的权重数据\n", length(daily_weights_list)))# 如果没有权重数据,创建空的列表if (length(daily_weights_list) == 0) { cat("警告: 没有找到权重大于0的记录\n")}# 计算投资组合每日收益率(权重滞后一天,按次日开盘价买入)cat("正在计算投资组合每日收益率...\n")returns_all <- do.call(merge, lapply(momentum_list, function(x) x$returns))colnames(returns_all) <- colnames(price_xts)# 检查returns_all的列名cat("收益率数据列名:\n")print(colnames(returns_all))cat("\n")# 调整权重的时间索引,确保与收益率对齐lagged_weights <- lag(weights, 1) # 权重滞后一天# 检查权重和收益率的日期范围cat(sprintf( "权重数据日期范围: %s 至 %s\n", as.character(index(weights)[1]), as.character(index(weights)[nrow(weights)])))cat(sprintf( "收益率数据日期范围: %s 至 %s\n", as.character(index(returns_all)[1]), as.character(index(returns_all)[nrow(returns_all)])))# 对齐索引:使用公共日期common_dates <- intersect(index(lagged_weights), index(returns_all))cat(sprintf("公共日期数量: %d\n", length(common_dates)))if (length(common_dates) == 0) { stop("权重和收益率数据没有公共日期,无法计算策略收益率")}# 使用公共日期提取数据lagged_weights_aligned <- lagged_weights[common_dates, ]returns_all_aligned <- returns_all[common_dates, ]# 处理缺失值lagged_weights_aligned[is.na(lagged_weights_aligned)] <- 0# 计算策略日收益率(只计算龙头股票的加权收益率,排除基准)# 假设基准是最后一列strategy_stocks_returns <- returns_all_aligned[, -ncol(returns_all_aligned)] # 排除基准strategy_stocks_weights <- lagged_weights_aligned[, -ncol(lagged_weights_aligned)] # 排除基准strategy_returns <- rowSums(strategy_stocks_returns * strategy_stocks_weights, na.rm = TRUE)strategy_returns <- xts(strategy_returns, order.by = index(returns_all_aligned))colnames(strategy_returns) <- "龙头动量轮动策略"cat(sprintf("策略收益率数据长度: %d\n", length(strategy_returns)))cat("策略收益率数据预览:\n")print(head(strategy_returns, 5))cat("\n")# ==================== 第六部分:计算等权重组合收益率 ====================cat("正在计算等权重组合收益率...\n")# 计算等权重组合(龙头股票等权重)num_stocks <- ncol(returns_all_aligned) - 1 # 排除基准equal_weights <- matrix(1 / num_stocks, nrow = nrow(returns_all_aligned), ncol = num_stocks)equal_weights <- xts(equal_weights, order.by = index(returns_all_aligned))colnames(equal_weights) <- colnames(returns_all_aligned)[1:num_stocks]equal_returns <- rowSums(returns_all_aligned[, 1:num_stocks] * equal_weights, na.rm = TRUE)equal_returns <- xts(equal_returns, order.by = index(returns_all_aligned))colnames(equal_returns) <- "等权重组合"cat("等权重组合收益率数据预览:\n")print(head(equal_returns, 5))cat("\n")# ==================== 第七部分:计算基准收益率 ====================cat("正在计算基准收益率...\n")# 检查基准名称是否在收益率数据列名中if (benchmark_name %in% colnames(returns_all_aligned)) { benchmark_returns <- returns_all_aligned[, benchmark_name] colnames(benchmark_returns) <- benchmark_name} else { # 如果基准名称不在列名中,尝试使用最后一列 cat(sprintf("警告: 基准名称 '%s' 不在收益率数据列名中,使用最后一列作为基准\n", benchmark_name)) benchmark_returns <- returns_all_aligned[, ncol(returns_all_aligned)] colnames(benchmark_returns) <- benchmark_name}cat("基准收益率数据预览:\n")print(head(benchmark_returns, 5))cat("\n")# ==================== 第八部分:绘制图表 ====================# 1. 计算累计收益率cat("正在计算累计收益率和最大回撤...\n")calculate_cumulative_returns <- function(returns) { # 用0填充NA值 returns_filled <- na.fill(returns, 0) cumprod(1 + returns_filled) - 1}strategy_cumulative <- calculate_cumulative_returns(strategy_returns)benchmark_cumulative <- calculate_cumulative_returns(benchmark_returns)equal_cumulative <- calculate_cumulative_returns(equal_returns)# 合并累计收益率cumulative_all <- merge(strategy_cumulative, benchmark_cumulative, equal_cumulative)colnames(cumulative_all) <- c("龙头动量轮动策略", benchmark_name, "等权重组合")# 转换为数据框用于ggplotcumulative_df <- data.frame( Date = index(cumulative_all), as.data.frame(cumulative_all))# 2. 计算最大回撤calculate_drawdown <- function(returns) { returns_filled <- na.fill(returns, 0) cum_returns <- cumprod(1 + returns_filled) drawdown <- cum_returns / cummax(cum_returns) - 1 return(drawdown)}strategy_dd <- calculate_drawdown(strategy_returns)benchmark_dd <- calculate_drawdown(benchmark_returns)equal_dd <- calculate_drawdown(equal_returns)# 合并回撤数据drawdown_all <- merge(strategy_dd, benchmark_dd, equal_dd)colnames(drawdown_all) <- c("龙头动量轮动策略", benchmark_name, "等权重组合")# 转换为数据框用于ggplotdrawdown_df <- data.frame( Date = index(drawdown_all), as.data.frame(drawdown_all))# 3. 创建组合图函数create_combined_plot <- function(cumulative_data, drawdown_data, strategy1, strategy2, title, colors) { # 准备累计收益率数据 cumulative_long <- cumulative_data %>% select(Date, all_of(c(strategy1, strategy2))) %>% pivot_longer(cols = -Date, names_to = "策略", values_to = "累计收益率") # 准备回撤数据 drawdown_long <- drawdown_data %>% select(Date, all_of(c(strategy1, strategy2))) %>% pivot_longer(cols = -Date, names_to = "策略", values_to = "回撤") # 累计收益率图 - 使用bw主题,删除X轴标题,图例无边框且背景透明 p_cumulative <- ggplot(cumulative_long, aes(x = Date, y = 累计收益率, color = 策略)) + geom_line(size = 1.2) + labs(title = title, subtitle = "累计收益率", y = "累计收益率", x = "") + scale_y_continuous(labels = percent_format()) + scale_color_manual(values = colors) + theme_bw(base_family = "simhei") + # 使用bw主题 theme( legend.position = c(0.02, 0.98), legend.justification = c(0, 1), legend.direction = "vertical", legend.title = element_blank(), # 图例无边框,背景透明 legend.background = element_blank(), # 透明背景 legend.key = element_blank(), # 图例键无边框 legend.box.background = element_blank(), # 图例框背景透明 legend.box.margin = margin(5, 5, 5, 5), legend.spacing.y = unit(0.2, "cm"), legend.text = element_text(size = 10), plot.title = element_text(hjust = 0.5, size = 14, face = "bold"), plot.subtitle = element_text(hjust = 0.5, size = 12), axis.title.x = element_blank(), # 删除X轴标题 axis.text.x = element_blank(), axis.ticks.x = element_blank() ) # 最大回撤图 - 使用bw主题,删除图例 p_drawdown <- ggplot(drawdown_long, aes(x = Date, y = 回撤, fill = 策略)) + geom_area(position = "identity", alpha = 0.3) + labs(y = "回撤", x = "日期") + scale_y_continuous(labels = percent_format()) + scale_fill_manual(values = colors) + theme_bw(base_family = "simhei") + # 使用bw主题 theme( legend.position = "none", # 删除图例 plot.title = element_blank(), axis.title.x = element_text(size = 12) ) # 组合两个图 plot_grid(p_cumulative, p_drawdown, ncol = 1, align = "v", rel_heights = c(1, 0.9) )}# 4. 绘制组合和基准的对比图cat("正在生成组合和基准的对比图...\n")colors_vs_benchmark <- c( "龙头动量轮动策略" = "#E41A1C", # 红色 "科创50ETF" = "#377EB8" # 蓝色)p1 <- create_combined_plot( cumulative_df, drawdown_df, "龙头动量轮动策略", "科创50ETF", sprintf("龙头动量轮动策略 vs 科创50ETF (N=%d, K=%d, L=%d)", N, K, L), colors_vs_benchmark)# 5. 绘制组合和等权重组合的对比图cat("正在生成组合和等权重组合的对比图...\n")colors_vs_equal <- c( "龙头动量轮动策略" = "#E41A1C", # 红色 "等权重组合" = "#4DAF4A" # 绿色)p2 <- create_combined_plot( cumulative_df, drawdown_df, "龙头动量轮动策略", "等权重组合", sprintf("龙头动量轮动策略 vs 等权重组合 (N=%d, K=%d, L=%d)", N, K, L), colors_vs_equal)# 6. 显示图表cat("\n正在显示图表...\n")print(p1)cat("\n\n")print(p2)# 7. 计算并显示绩效指标汇总 - 计算五个核心指标cat("\n正在计算绩效指标...\n")calculate_performance <- function(returns, name) { # 检查收益率数据 if (length(returns) == 0 || all(is.na(returns))) { return(data.frame( 策略 = name, 年化收益 = NA, 年化波动率 = NA, 最大回撤 = NA, 夏普比率 = NA, 卡玛比率 = NA )) } # 移除NA值 returns_clean <- na.omit(returns) if (length(returns_clean) < 2) { return(data.frame( 策略 = name, 年化收益 = NA, 年化波动率 = NA, 最大回撤 = NA, 夏普比率 = NA, 卡玛比率 = NA )) } # 计算年化收益率、年化波动率和夏普比率 perf <- tryCatch( { table.AnnualizedReturns(returns_clean) }, error = function(e) { cat(sprintf("计算%s绩效指标时出错: %s\n", name, e$message)) return(matrix(NA, nrow = 3, ncol = 1)) } ) # 计算最大回撤 max_dd <- tryCatch( { maxDrawdown(returns_clean) }, error = function(e) { cat(sprintf("计算%s最大回撤时出错: %s\n", name, e$message)) return(NA) } ) # 计算卡玛比率(卡尔马比率) calmar <- tryCatch( { CalmarRatio(returns_clean) }, error = function(e) { cat(sprintf("计算%s卡玛比率时出错: %s\n", name, e$message)) return(NA) } ) df <- data.frame( 策略 = name, 年化收益 = if (!all(is.na(perf))) round(perf[1, 1] * 100, 2) else NA, 年化波动率 = if (!all(is.na(perf))) round(perf[2, 1] * 100, 2) else NA, 最大回撤 = if (!is.na(max_dd)) round(abs(max_dd) * 100, 2) else NA, # 取绝对值,以正数显示 夏普比率 = if (!all(is.na(perf))) round(perf[3, 1], 3) else NA, 卡玛比率 = if (!is.na(calmar)) round(calmar, 3) else NA ) colnames(df) <- c("策略", "年化收益", "年化波动率", "最大回撤", "夏普比率", "卡玛比率") row.names(df) <- NULL return(df)}# 计算各策略绩效strategy_perf <- calculate_performance(strategy_returns, "龙头动量轮动策略")benchmark_perf <- calculate_performance(benchmark_returns, benchmark_name)equal_perf <- calculate_performance(equal_returns, "等权重组合")# 合并绩效指标 - 使用dplyr的bind_rows处理列名不一致问题performance_summary <- rbind(strategy_perf, benchmark_perf, equal_perf)cat("\n==================== 绩效指标汇总 ====================\n\n")print(performance_summary)cat("\n")# ==================== 保存结果到文件 ====================cat("正在保存结果到文件...\n")output_dir <- sprintf("龙头动量轮动策略_N%d_K%d_L%d", N, K, L)if (!dir.exists(output_dir)) { dir.create(output_dir)}# 保存绩效指标write.csv(performance_summary, file = paste0(output_dir, "/performance_summary.csv"), row.names = FALSE, fileEncoding = "UTF-8")# 保存累计收益率数据write.csv(cumulative_df, file = paste0(output_dir, "/cumulative_returns.csv"), row.names = FALSE, fileEncoding = "UTF-8")# 保存回撤数据write.csv(drawdown_df, file = paste0(output_dir, "/drawdowns.csv"), row.names = FALSE, fileEncoding = "UTF-8")# 保存每日权重列表(将列表转换为数据框保存)- 只保存权重大于0的记录if (length(daily_weights_list) > 0) { daily_weights_df <- do.call(rbind, daily_weights_list) write.csv(daily_weights_df, file = paste0(output_dir, "/daily_weights_nonzero.csv"), row.names = FALSE, fileEncoding = "UTF-8" ) # 保存每日权重汇总(每个交易日权重合计和选中标的数) daily_summary <- data.frame( Date = as.Date(names(daily_weights_list)), 权重合计 = sapply(daily_weights_list, function(df) sum(df$Weight)), 选中标的数 = sapply(daily_weights_list, function(df) nrow(df)) ) write.csv(daily_summary, file = paste0(output_dir, "/daily_summary.csv"), row.names = FALSE, fileEncoding = "UTF-8" ) # 计算每个股票被选中的总天数和平均权重 stock_summary <- daily_weights_df %>% group_by(Stock) %>% summarise( 选中天数 = n(), 平均权重 = round(mean(Weight, na.rm = TRUE) * 100, 3), 选中比例 = round(n() / length(daily_weights_list) * 100, 1) ) %>% arrange(desc(选中天数)) write.csv(stock_summary, file = paste0(output_dir, "/stock_selection_summary.csv"), row.names = FALSE, fileEncoding = "UTF-8" ) cat("股票选中频率排名(前10名):\n") print(head(stock_summary, 10)) cat("\n")} else { cat("警告: 没有权重大于0的记录,跳过保存权重文件\n")}# 保存动量数据(前5个股票作为示例)momentum_samples <- list()sample_stocks <- colnames(price_xts)[1:min(5, ncol(price_xts))]for (stock in sample_stocks) { momentum_samples[[stock]] <- data.frame( Date = index(momentum_list[[stock]]$momentum), Stock = stock, Momentum = as.numeric(momentum_list[[stock]]$momentum), Volatility = as.numeric(momentum_list[[stock]]$volatility), Adj_Momentum = as.numeric(momentum_list[[stock]]$adj_momentum) )}momentum_samples_df <- do.call(rbind, momentum_samples)write.csv(momentum_samples_df, file = paste0(output_dir, "/momentum_samples.csv"), row.names = FALSE, fileEncoding = "UTF-8")# 保存图表ggsave(paste0(output_dir, "/momentum_vs_benchmark.png"), p1, width = 10, height = 8, dpi = 300)ggsave(paste0(output_dir, "/momentum_vs_equal_weight.png"), p2, width = 10, height = 8, dpi = 300)cat("==================== 回测完成 ====================\n")cat("结果已保存到文件夹:", output_dir, "\n")cat("包含文件:\n")cat("1. performance_summary.csv - 绩效指标汇总\n")cat("2. cumulative_returns.csv - 累计收益率数据\n")cat("3. drawdowns.csv - 回撤数据\n")if (length(daily_weights_list) > 0) { cat("4. daily_weights_nonzero.csv - 每日权重数据(只包含权重大于0的记录)\n") cat("5. daily_summary.csv - 每日权重汇总\n") cat("6. stock_selection_summary.csv - 股票选中频率汇总\n")}cat("7. momentum_samples.csv - 动量数据示例(前5个股票)\n")cat("8. momentum_vs_benchmark.png - 组合和基准对比图\n")cat("9. momentum_vs_equal_weight.png - 组合和等权重组合对比图\n")cat("\n")cat("运行时间统计:\n")cat(sprintf("股票数量: %d\n", ncol(price_xts)))cat(sprintf("交易日数量: %d\n", nrow(price_xts)))cat(sprintf("公共日期数量: %d\n", length(common_dates)))if (length(daily_weights_list) > 0) { cat(sprintf("有权重分配的交易日数: %d\n", length(daily_weights_list)))}cat(sprintf("策略开始日期: %s\n", as.character(index(strategy_returns)[1])))cat(sprintf("策略结束日期: %s\n", as.character(index(strategy_returns)[length(strategy_returns)])))cat("\n")
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
