最近,我常被同行问起一个问题:“供应链人掌握Excel之后,下一步该学什么工具?”
我的答案始终如一:Python。但这句话需要更完整的注解:
“并非所有工作都要从Excel迁移到Python。Excel在灵活构建计算逻辑、处理确定性场景时依然无可替代。但当不确定性成为决策的核心挑战时,Python将为你打开一扇全新的大门。”
本文将通过一个库存模拟案例,拆解这两类工具的差异化定位,并展示如何用Python构建面向不确定性的决策引擎。
一、工具选择的误区:Excel与Python不是替代关系
1. Excel的杀手锏:确定性场景的“速写能力”
看过去的数据:历史销量统计、固定交期的补货计划、确定BOM的物料需求展开...
强项场景:规则清晰、输入输出明确、无需概率计算的线性问题
典型应用:安全库存公式计算、经济订单批量(EOQ)、ABC分类报表
这些场景的共性是**“已知的已知”**——变量间关系确定,最优解可通过公式直接求得。
2. Python的破局点:不确定性世界的“推演能力”
问未来的问题:如果需求波动加剧20%会怎样?如果供应商交货延迟概率上升如何应对?
核心价值:通过蒙特卡洛模拟生成数千种可能场景,量化风险与机会
不可替代性:当问题涉及**“已知的未知”(概率分布已知)或“未知的未知”**(黑天鹅事件),Excel的计算效率与模型复杂度将遇到瓶颈
常见的需要“推演能力”的供应链问题包括:生产排程优化、预测与分析,以及库存模拟。
本文旨在探讨库存模拟的背景:其含义、适用场景以及从简单到复杂的实现层次。后续文章将讨论其他主题,如生产排程优化和预测。
本文不提供下载链接、代码或具体实现细节。在构建模拟之前,明确目标至关重要。任何系统开发的成功关键,在于对功能与特性的清晰规划。模拟是对现实的抽象,无法涵盖所有细节。我将提出一些核心功能作为起点,并分享构建基础模拟的思路。
我建议分阶段开发此类项目:从简单模型入手,逐步迭代。与其纠结于包含哪些功能,不如专注于简化初始版本。被排除的功能将成为后续改进的清单。以下将探讨不同层次的模拟设计,从Level 0(网络研讨会中的简单示例)到Level 1(基准模型),并展望Level 2的可能方向。
库存模拟是什么?为何需要它?
库存模拟是一种通过建模库存系统来确定最佳补货策略的方法。此处的“系统”指一套流程,而非软件。库存包括为满足客户需求而持有的成品、半成品或采购件。
传统库存规划是确定性的——使用固定需求值和交货周期。例如,某商品每周需求设为10件,交货周期固定为5天。然而现实并非如此。若需求与供应完全可预测,库存本可趋近于零,规划也不会如此复杂。但企业无法基于概率下订单(例如“50%可能需要某物”)。决策需确定性,但规划必须考虑不确定性。
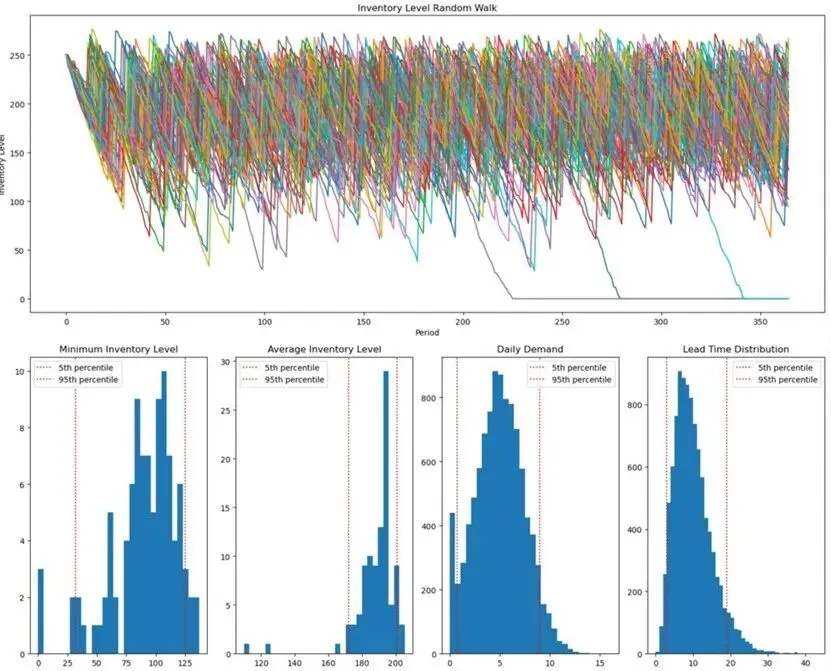
模拟的价值在于:通过运行数千种随机场景(而非单一假设),量化策略效果。例如,若某商品周需求均值为10,但实际可能为0、11或15,模拟可评估不同补货策略下的缺货概率与库存波动范围。
通过这种方式,企业能以科学方法测试策略,而无需高深统计学知识。每次模拟的机制是确定性的,但输入是概率性的,输出则是统计结果。这相当于在数千次“平行运营”中验证策略,最终选择最优方案。
蒙特卡洛模拟
蒙特卡洛方法通过随机采样分析不确定性。以轮盘赌为例:若赌局概率已知(如1/37中奖率),玩家可计算期望收益。但若轮盘被操纵,某些数字出现概率异常,玩家需通过观察历史数据(如1000次旋转结果)制定策略。
库存规划类似赌局:企业将有限资金投入库存,期望快速周转获利。但库存滞销或报废将导致损失。模拟相当于免费运行数千次“轮盘旋转”,量化策略风险。
库存优化
需澄清“库存优化”的定义。传统方法(如ABC-XYZ分析、安全库存公式)虽有一定作用,但存在缺陷:
- 基于规则而非数学优化:策略通过经验或分段制定,缺乏全局视角。
- 假设局限性:例如,安全库存公式假设需求服从正态分布,而实际需求常为偏态分布(如伽马分布)。
科学意义上的优化指通过数学方法找到满足约束的最优解。例如:“在库存天数≤60、服务水平≥99%的条件下,寻找最优策略。” 若问题不可行,优化将指出最佳近似解。
随机优化(Stochastic Optimization)需结合模拟处理不确定性。库存模拟可从小规模起步(如Level 0),逐步升级至前沿技术(如Level 8的随机优化)。
Excel中的库存模拟
Excel可构建基础模型,例如:
- 单SKU、日需求服从正态分布(均值=10,标准差=5)
但Excel的局限性明显:
- 大规模数据或多场景模拟时性能低下(如1000次年度模拟耗时过长)
Python中的库存模拟
Python的优势包括:
- 高效计算:千次模拟仅需数秒,支持多策略对比。
- 灵活建模:可逐步扩展模型复杂度(如添加需求趋势、供应链中断等)。
- 丰富生态:借助NumPy、Pandas等库处理统计与数据,scipy支持概率分布生成。
模拟的层次设计
Level 0(基础版)
- 单SKU:仅支持单个库存项
- 需求分布:正态分布(可能生成负值,需截断处理)
- 补货策略:固定再订货点与订货量
- 供应限制:仅允许单笔在途订单
Level 1(基准版)
改进方向:
- 需求分布:改用伽马分布或对数正态分布(避免负值,更贴近实际)
- 补货策略:支持Min-Max策略、周期盘点
- 需求预测:引入移动平均等基准方法
- 在途订单:允许多笔订单在途(适应长交货周期)
Level 2+(高阶扩展)
- 多SKU与分类:按需求模式(如SBC方法:平稳型、间断型、波动型)分类模拟
- 复杂需求分解:使用ETS(误差-趋势-季节性)或ARIMA模型捕捉趋势与季节性
- BOM关联需求:考虑生产计划对组件需求的影响
- 策略优化:网格搜索评估参数组合成本(如库存持有成本 vs 缺货成本)
- 供应链风险:模拟供应中断、多源采购、紧急补货
总结
库存模拟需循序渐进:从单物品确定性模型,逐步引入随机性、多策略优化和供应链复杂性。Python的高效与灵活性使其成为理想工具,而Excel适合快速验证思路。
通过分阶段开发(如先实现Level 1基准模型),企业可逐步积累经验,再扩展至Level 2+的高阶功能。关键在于:
- 清晰的需求定义:明确每个阶段的目标与取舍
- 模块化设计:确保功能可扩展(如替换需求分布仅需修改少量代码)
- 数据驱动验证:基于历史数据校准模型参数(如需求分布形状、交货周期变异)
让工具回归工具
Excel与Python的本质差异不在技术,而在思维模式:
- Excel是确定性思维的结晶——通过公式链表达因果逻辑
- Python是概率思维的载体——通过模拟推演理解系统韧性
供应链人真正的进阶,不在于掌握某个工具,而在于建立分层的决策框架:
当你能清晰回答“这个问题的不确定性来自哪里?”,工具的选择将自然浮现。
👍 点个赞 | ⭐ 收藏一下 | 💬 评论区聊聊你的想法

联系我们
官网:https://www.rscp.com.cn/业务咨询: yechen@production-scheduling.com
扫码关注我们小红书



 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
