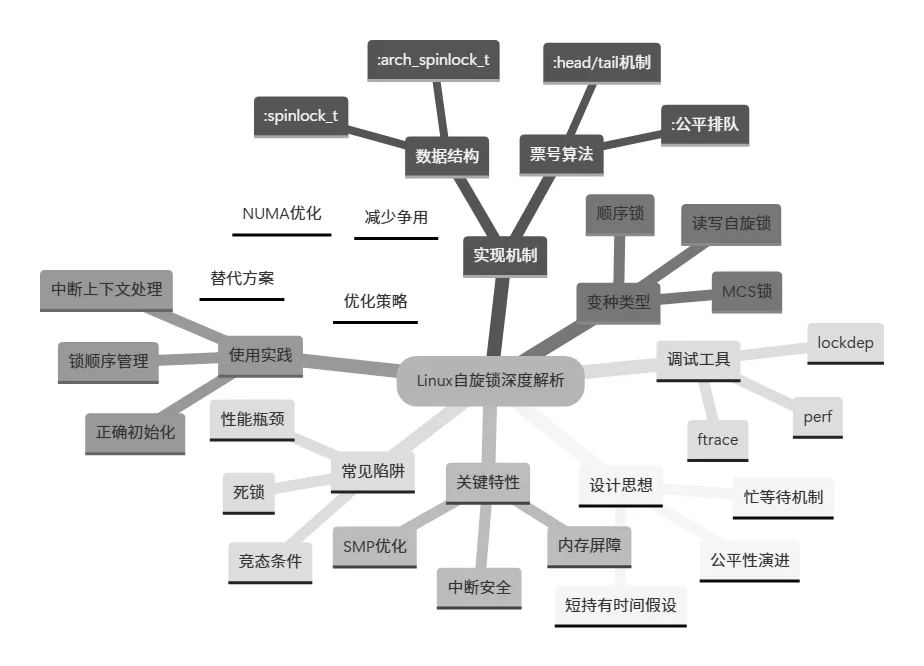
Linux自旋锁深度解析: 从设计思想到实战应用
引言: 为什么需要自旋锁?
在多核处理器成为主流的今天, 操作系统内核面临着前所未有的并发挑战. 想象一下, 一个繁忙的十字路口, 如果没有交通信号灯, 车辆就会陷入混乱. Linux内核中的共享数据就像是这个十字路口, 而自旋锁(Spinlock)就是那个维持秩序的交通信号灯. 但与红绿灯不同的是, 自旋锁采用了一种独特的工作方式——它让等待的CPU“原地踏步”(自旋), 而不是“去休息”(睡眠)
第一章: 自旋锁的核心设计思想
1.1 基本概念与设计哲学
自旋锁是一种忙等待锁, 当线程尝试获取锁而锁已被占用时, 它不会立即放弃CPU, 而是在一个紧凑的循环中不断检查锁的状态. 这种设计基于一个关键假设: 锁的持有时间非常短暂
设计权衡:
短持有时间 → 自旋等待(开销小)
长持有时间 → 睡眠等待(避免CPU浪费)
1.2 与互斥锁的对比
生活中的比喻:
- • 自旋锁: 就像在超市收银台前, 看到前面只有1-2个人, 你选择在原地踱步等待
- • 互斥锁: 就像前面有20个人排队, 你选择先去逛商店, 过会儿再来查看
1.3 自旋锁的演进历程
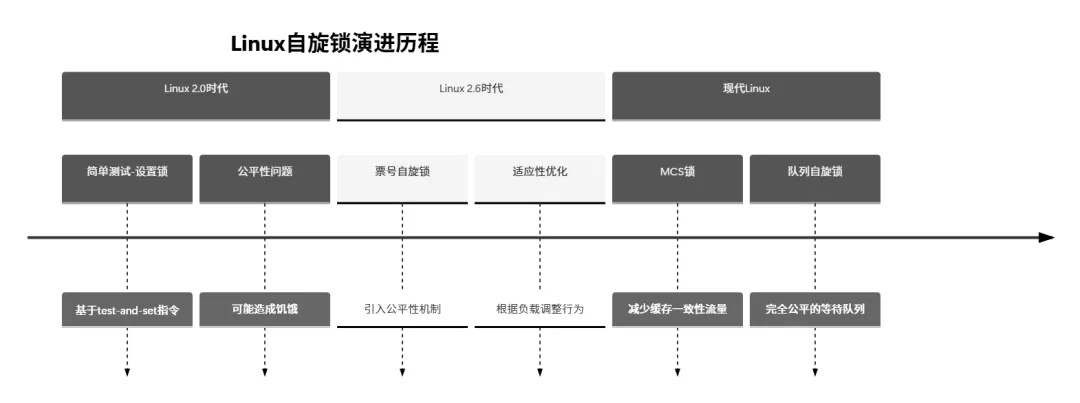
第二章: 自旋锁的数据结构与实现机制
2.1 核心数据结构
让我们深入Linux内核源码, 看看自旋锁是如何定义的:
// include/linux/spinlock_types.h
typedefstruct spinlock {
union {
struct raw_spinlock rlock;
#ifdef CONFIG_DEBUG_LOCK_ALLOC
# define LOCK_PADSIZE (offsetof(struct raw_spinlock, dep_map))
struct {
u8 __padding[LOCK_PADSIZE];
struct lockdep_map dep_map;
};
#endif
};
} spinlock_t;
// include/linux/spinlock_types_raw.h
typedefstruct raw_spinlock {
arch_spinlock_t raw_lock;
#ifdef CONFIG_DEBUG_SPINLOCK
unsigned int magic, owner_cpu;
void *owner;
#endif
#ifdef CONFIG_DEBUG_LOCK_ALLOC
struct lockdep_map dep_map;
#endif
} raw_spinlock_t;
// 架构相关定义(以x86为例)
// arch/x86/include/asm/spinlock_types.h
typedefstruct arch_spinlock {
union {
__ticketpair_t head_tail;
struct __raw_tickets {
__ticket_t head, tail;
} tickets;
};
} arch_spinlock_t;
2.2 票号自旋锁的工作原理
现代Linux默认使用票号自旋锁(Ticket Spinlock), 它解决了传统自旋锁的公平性问题
数据结构解析:

工作流程:
- 1. 获取锁: 线程读取当前的
tail值作为自己的票号, 然后原子地将tail+1 - 3. 进入: 当
head == 我的票号时, 获得锁进入临界区 - 4. 释放: 退出临界区时, 将
head+1, 让下一个票号的线程获得锁
2.3 核心操作源码分析
2.3.1 自旋锁初始化
// include/linux/spinlock.h
#define DEFINE_SPINLOCK(x) spinlock_t x = __SPIN_LOCK_UNLOCKED(x)
#define __SPIN_LOCK_UNLOCKED(lockname) \
(spinlock_t) __SPIN_LOCK_INITIALIZER(lockname)
#define __SPIN_LOCK_INITIALIZER(lockname) \
{ { .rlock = __RAW_SPIN_LOCK_INITIALIZER(lockname) } }
#define __RAW_SPIN_LOCK_INITIALIZER(lockname) \
{ \
.raw_lock = __ARCH_SPIN_LOCK_UNLOCKED, \
SPIN_DEBUG_INIT(lockname) \
SPIN_DEP_MAP_INIT(lockname) \
}
2.3.2 加锁操作(x86架构)
// arch/x86/include/asm/spinlock.h
static __always_inline void arch_spin_lock(arch_spinlock_t *lock)
{
registerstruct __raw_tickets inc = { .tail = 1 };
// 原子地获取当前票号并递增tail
inc = xadd(&lock->tickets, inc);
// 如果head == tail, 说明锁是空闲的, 直接获得
if (likely(inc.head == inc.tail))
goto out;
// 否则, 循环等待直到轮到自己
for (;;) {
unsigned count = SPIN_THRESHOLD;
do {
// 检查是否轮到自己
if (ACCESS_ONCE(lock->tickets.head) == inc.tail)
goto out;
cpu_relax(); // 降低CPU能耗的等待
} while (--count);
// 长时间等待后的优化处理
__ticket_lock_spinning(lock, inc.tail);
}
out:
barrier(); // 内存屏障, 确保临界区代码不会乱序到加锁之前
}
2.3.3 解锁操作
static __always_inline void arch_spin_unlock(arch_spinlock_t *lock)
{
__ticket_t next = lock->tickets.head + 1;
// 增加head, 让下一个等待者获得锁
__add(&lock->tickets.head, next, UNLOCK_LOCK_PREFIX);
}
2.4 内存屏障的重要性
自旋锁实现中大量使用内存屏障来保证内存访问的顺序性:
// 加锁后的屏障
#define spin_lock(lock) \
do { \
raw_spin_lock(&(lock)->rlock); \
barrier(); \
} while (0)
// 解锁前的屏障
#define spin_unlock(lock) \
do { \
barrier(); \
raw_spin_unlock(&(lock)->rlock); \
} while (0)
屏障的作用:
- • 加锁后屏障: 确保临界区内的读写操作不会重排到加锁之前
- • 解锁前屏障: 确保临界区内的所有操作在释放锁之前完成
第三章: 自旋锁的变种与优化
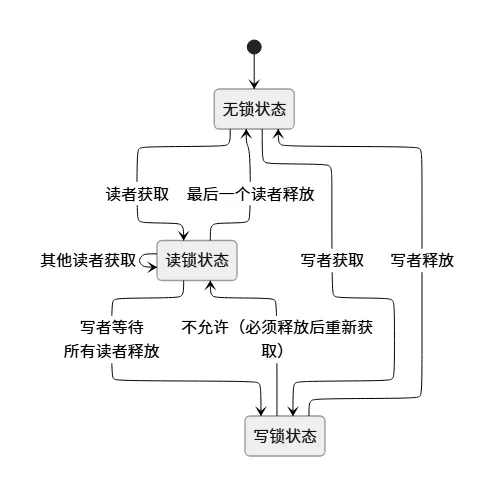
3.1 读写自旋锁(rwlock_t)
当读操作远多于写操作时, 使用读写自旋锁可以大幅提升并发性能
// include/linux/rwlock_types.h
typedefstruct {
arch_rwlock_t raw_lock;
#ifdef CONFIG_DEBUG_SPINLOCK
unsigned int magic, owner_cpu;
void *owner;
#endif
#ifdef CONFIG_DEBUG_LOCK_ALLOC
struct lockdep_map dep_map;
#endif
} rwlock_t;
工作规则:
3.2 顺序锁(seqlock_t)
适用于读多写少, 且读者可以容忍读到稍旧数据的场景
// include/linux/seqlock.h
typedefstruct {
struct seqcount seqcount;
spinlock_t lock;
} seqlock_t;
工作原理:
- 1. 写者: 获取自旋锁, 递增序列号, 修改数据, 再次递增序列号, 释放锁
- 2. 读者: 读取序列号, 读取数据, 再次读取序列号, 如果两次序列号相同且为偶数, 数据有效
3.3 MCS锁与队列自旋锁
传统自旋锁在大量CPU竞争时会产生严重的缓存一致性风暴. MCS锁通过每个CPU在本地自旋解决这个问题
// kernel/locking/mcs_spinlock.h
struct mcs_spinlock {
struct mcs_spinlock *next;
int locked; /* 1 if lock acquired */
};
第四章: 自旋锁的使用模式与最佳实践
4.1 基本使用模式
#include <linux/spinlock.h>
// 定义自旋锁
static DEFINE_SPINLOCK(my_lock);
// 使用自旋锁保护临界区
void modify_shared_data(void)
{
unsigned long flags;
// 获取锁(禁用本地中断)
spin_lock_irqsave(&my_lock, flags);
// 临界区代码
shared_data++;
// 释放锁(恢复中断状态)
spin_unlock_irqrestore(&my_lock, flags);
}
4.2 中断上下文中的使用
// 中断处理程序中使用
irqreturn_t interrupt_handler(int irq, void *dev_id)
{
unsigned long flags;
// 必须使用禁止中断的版本
spin_lock_irqsave(&device_lock, flags);
// 处理中断
process_interrupt();
spin_unlock_irqrestore(&device_lock, flags);
return IRQ_HANDLED;
}
4.3 嵌套锁的处理
// 错误的嵌套顺序 - 可能导致死锁
void wrong_nesting(void)
{
spin_lock(&lock_a);
spin_lock(&lock_b); // 如果其他线程以相反顺序获取, 可能死锁
// ...
spin_unlock(&lock_b);
spin_unlock(&lock_a);
}
// 正确的做法: 始终以固定顺序获取锁
void correct_nesting(void)
{
// 先获取lock_a, 再获取lock_b
spin_lock(&lock_a);
spin_lock(&lock_b);
// ...
spin_unlock(&lock_b);
spin_unlock(&lock_a);
}
第五章: 调试与性能分析工具
5.1 Lockdep死锁检测器
Linux内核的lockdep子系统可以动态检测潜在的锁顺序问题
# 启用lockdep
echo 1 > /proc/sys/kernel/lockdep
# 查看锁依赖信息
dmesg | grep lockdep
# 常见的lockdep警告
# 1. 循环等待死锁
# 2. 违反锁获取顺序
# 3. 在错误上下文中使用锁(如中断中不使用_irqsave版本)
5.2 自旋锁调试选项
# 编译时开启调试
CONFIG_DEBUG_SPINLOCK=y
CONFIG_DEBUG_LOCK_ALLOC=y
# 运行时检测
# 检查未初始化锁的使用
# 检测双重释放
# 验证锁的持有者
5.3 性能分析工具
# perf分析锁竞争
perf lock record -a -- sleep 10
perf lock report
# 使用ftrace跟踪锁事件
echo 1 > /sys/kernel/debug/tracing/events/lock/enable
cat /sys/kernel/debug/tracing/trace_pipe
# lockstat统计
echo 1 > /proc/sys/kernel/lock_stat
# 运行测试
echo 0 > /proc/sys/kernel/lock_stat
dmesg | tail -100 # 查看统计信息
5.4 常见的调试场景
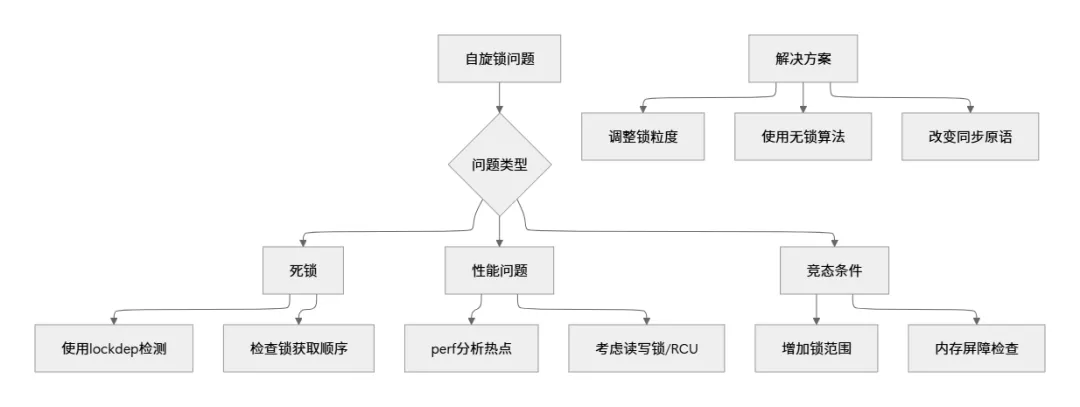
第六章: 实战案例: 实现简单的自旋锁保护的数据结构
6.1 线程安全的计数器
#include <linux/spinlock.h>
#include <linux/kernel.h>
#include <linux/module.h>
// 线程安全的计数器
struct safe_counter {
int count;
spinlock_t lock;
char name[32];
};
// 初始化计数器
void counter_init(struct safe_counter *counter, const char *name)
{
counter->count = 0;
spin_lock_init(&counter->lock);
strncpy(counter->name, name, sizeof(counter->name) - 1);
counter->name[sizeof(counter->name) - 1] = '\0';
printk(KERN_INFO "Counter %s initialized\n", name);
}
// 增加计数
int counter_increment(struct safe_counter *counter)
{
unsigned long flags;
int new_count;
spin_lock_irqsave(&counter->lock, flags);
counter->count++;
new_count = counter->count;
spin_unlock_irqrestore(&counter->lock, flags);
return new_count;
}
// 减少计数
int counter_decrement(struct safe_counter *counter)
{
unsigned long flags;
int new_count;
spin_lock_irqsave(&counter->lock, flags);
if (counter->count > 0)
counter->count--;
new_count = counter->count;
spin_unlock_irqrestore(&counter->lock, flags);
return new_count;
}
// 获取当前计数
int counter_get(struct safe_counter *counter)
{
unsigned long flags;
int count;
spin_lock_irqsave(&counter->lock, flags);
count = counter->count;
spin_unlock_irqrestore(&counter->lock, flags);
return count;
}
// 示例使用
staticstruct safe_counter my_counter;
static int __init test_module_init(void)
{
counter_init(&my_counter, "global_counter");
// 模拟并发访问
counter_increment(&my_counter);
counter_increment(&my_counter);
counter_decrement(&my_counter);
printk(KERN_INFO "Counter value: %d\n", counter_get(&my_counter));
return 0;
}
6.2 生产者-消费者队列
#include <linux/spinlock.h>
#include <linux/slab.h>
#define QUEUE_SIZE 100
// 简单的线程安全队列
struct safe_queue {
void *items[QUEUE_SIZE];
int head;
int tail;
int count;
spinlock_t lock;
};
// 初始化队列
int queue_init(struct safe_queue *queue)
{
queue->head = 0;
queue->tail = 0;
queue->count = 0;
spin_lock_init(&queue->lock);
return 0;
}
// 入队(生产者)
int queue_enqueue(struct safe_queue *queue, void *item)
{
unsigned long flags;
int ret = -1; // 队列满
spin_lock_irqsave(&queue->lock, flags);
if (queue->count < QUEUE_SIZE) {
queue->items[queue->tail] = item;
queue->tail = (queue->tail + 1) % QUEUE_SIZE;
queue->count++;
ret = 0; // 成功
}
spin_unlock_irqrestore(&queue->lock, flags);
return ret;
}
// 出队(消费者)
void *queue_dequeue(struct safe_queue *queue)
{
unsigned long flags;
void *item = NULL;
spin_lock_irqsave(&queue->lock, flags);
if (queue->count > 0) {
item = queue->items[queue->head];
queue->head = (queue->head + 1) % QUEUE_SIZE;
queue->count--;
}
spin_unlock_irqrestore(&queue->lock, flags);
return item;
}
第七章: 高级主题与优化策略
7.1 锁争用优化策略
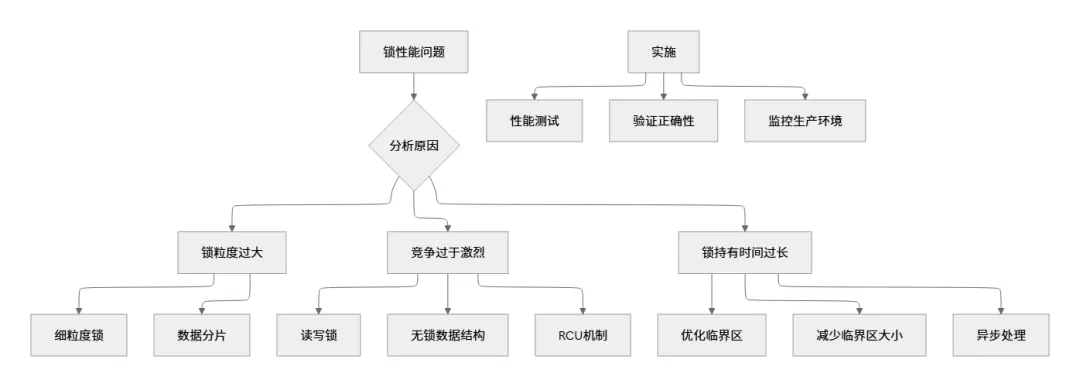
7.2 无锁编程替代方案
当自旋锁成为瓶颈时, 可以考虑以下替代方案:
7.3 NUMA架构下的优化
在NUMA系统中, 自旋锁需要考虑内存位置:
// NUMA感知的自旋锁初始化
spinlock_t numa_lock;
void init_numa_lock(void)
{
// 将锁数据放在访问最频繁的节点上
spin_lock_init(&numa_lock);
// 或者使用NUMA API优化
#ifdef CONFIG_NUMA
set_memory_numa(&numa_lock, numa_node_of_cpu(smp_processor_id()));
#endif
}
第八章: 常见陷阱与解决方案
8.1 死锁场景分析
// 场景1: 中断上下文死锁
void process_data(void)
{
spin_lock(&data_lock);
// 如果中断在这里发生, 并且中断处理程序也尝试获取data_lock
// 就会导致死锁
spin_unlock(&data_lock);
}
// 解决方案: 使用spin_lock_irqsave
void process_data_safe(void)
{
unsigned long flags;
spin_lock_irqsave(&data_lock, flags);
// 现在本地中断被禁用, 中断处理程序不会执行
spin_unlock_irqrestore(&data_lock, flags);
}
// 场景2: 锁顺序死锁
void thread1(void)
{
spin_lock(&lock_a);
spin_lock(&lock_b); // 可能死锁
// ...
spin_unlock(&lock_b);
spin_unlock(&lock_a);
}
void thread2(void)
{
spin_lock(&lock_b);
spin_lock(&lock_a); // 与thread1顺序相反
// ...
spin_unlock(&lock_a);
spin_unlock(&lock_b);
}
8.2 性能陷阱
- 2. 锁粒度过粗: 一个大锁保护多个独立数据 → 多个细粒度锁
- 3. 错误的使用场景: 长持有时间使用自旋锁 → 改用互斥锁
总结与展望
全文核心要点总结
| | |
|---|
perf lock | | perf lock record -a -- sleep 5 |
dmesg | | dmesg | grep -i spinlock |
trace-cmd | | trace-cmd record -e lock* |
cat /proc/lockdep_chains | | cat /proc/lockdep_chains |
echo 1 > /proc/sys/kernel/lock_stat | | |

