你有没有过这种崩溃时刻?
团队分组整理、项目人员台账的你,是不是经常遇到这种头疼的 Excel 表格?
或者突然丢给你一个 Excel 表格,说:“把这里面的人员信息整理一下,我要做系统导入。”
你满心欢喜打开文件,结果定睛一看,心态炸裂:
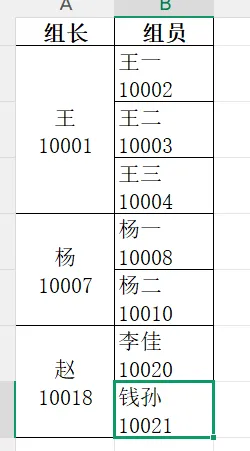
- “组长”这一列,全是合并值! 因为 Excel 用了“合并单元格”,只有第一行有名字,下面全是空的。
- “组员”这一列,名字和编号死死粘在一起! 比如
王一10002。 - 最要命的是,如果你仔细看,或者用代码一跑,发现它们中间居然还藏着**“换行符”**!导致你手动分离根本分不开。
😭 此时,如果数据只有几行,还能靠 Ctrl+C、Ctrl+V 拼手速。如果是几千行、几万行呢?
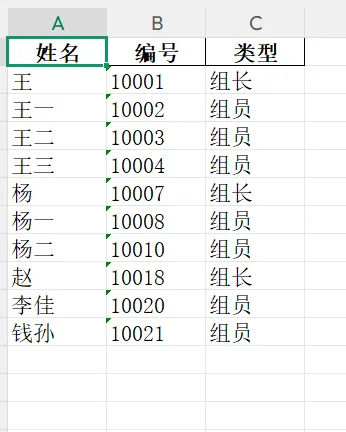
别急,今天我们就用 Python 的 Pandas 配合 正则表达式(Re),三步带你把这个“垃圾数据”清洗成标准的**“姓名+编号+类型”**明细表!
最终效果预览
清洗前(这是地狱):
清洗后(这是天堂):
是不是很心动?下面直接上干货!
🛠️ 实现步骤拆解
我们要解决的问题主要有三个:填充空值、拆分字符串、去除隐形换行符。
第一步:暴力读取,解决“合并单元格”
首先,我们用 Pandas 读取文件。遇到合并单元格,Pandas 读进来后,对应的位置全是 NaN(空值)。
这时候,有一个神操作叫 ffill (forward fill)。它的意思是:“下面的格子如果是空的,就抄上面的内容”。
import pandas as pd
import re
# 1. 读取 Excel
file_path = '分组结果_自动处理.xlsx'# 替换你的文件名
df_raw = pd.read_excel(file_path, engine='openpyxl')
col_leader = "组长"
col_member = "组员"
# 2. 填充空值 (关键步骤!)
# 所有的空格子,都会变成上一行非空格子的内容
df_raw[col_leader] = df_raw[col_leader].fillna(method='ffill')
这一步之后,表格里就没有“合并单元格”的阴影了,每一行都有对应的组长名字。
第二步:核心清洗,正则表达式“大显神通”
这是最关键的一步。我们要处理 王一\n10002 这种乱七八糟的字符串。
普通的 split 分列很容易被换行符 \n 搞混,导致错位。所以我们需要写一个强大的函数 extract_persons:
- 去掉
\n:先把所有换行符替换掉,让数据连成一条线。 - 正则提取:用
([^\d]+?)(\d+)) 这个公式,翻译成人话就是:“找出一段非数字的内容(姓名),后面紧跟着一段数字的内容(编号)”。
defextract_persons(text, person_type):
"""
智能提取函数:能处理带换行符、多人混合的情况
"""
result = []
if pd.isna(text):
return result
# 关键修正:先干掉所有换行符!
clean_text = str(text).replace('\n', '').replace('\r', '').strip()
ifnot clean_text or clean_text == 'nan':
return result
# 核心正则:匹配 "非数字姓名" + "数字编号"
# [^\d]+? -> 姓名 (懒惰匹配)
# \d+ -> 编号
matches = re.findall(r"([^\d]+?)(\d+)", clean_text)
if matches:
for name, uid in matches:
result.append({
"姓名": name.strip(), # 去掉名字周围多余的空格
"编号": uid,
"类型": person_type
})
else:
# 兜底:万一没匹配到,原样保留
result.append({"姓名": clean_text, "编号": "", "类型": person_type})
return result
有了这个函数,无论单元格里是一个人 王一10002,还是挤着两个人 王一10002 王二10003,它都能精准抓出来!
第三步:循环生成,去重完善
现在我们遍历每一行,把组长和组员分别丢进上面的函数里提取。最后别忘了,因为 Excel 合并单元格展开后,组长会重复出现,我们要用 drop_duplicates 把重复的组长删掉,只留一条。
final_data = []
# 遍历每一行数据
for index, row in df_raw.iterrows():
leader_text = row[col_leader]
member_text = row[col_member]
# 提取组长
final_data.extend(extract_persons(leader_text, "组长"))
# 提取组员
final_data.extend(extract_persons(member_text, "组员"))
# 生成最终 DataFrame
df_final = pd.DataFrame(final_data)
# 关键:去重!
# 合并单元格展开会导致组长在每一行都出现一次,去重后数据才干净
df_final = df_final.drop_duplicates(subset=['姓名', '编号'])
# 导出结果
output_file = "最终人员明细表_修正版.xlsx"
df_final.to_excel(output_file, index=False)
print(f"搞定!文件已保存为:{output_file}")
你看,面对这种充满“坑”的 Excel 表,如果你还在用肉眼识别、手动复制粘贴,不仅效率低,还容易出错。
Python 的魅力就在于,它不嫌麻烦,逻辑一旦写好,无论是一万行还是十万行数据,都是一秒钟的事。
把上面的代码保存下来,下次再遇到这种“奇葩”表格,直接运行,就能在同事面前露一手了!
觉得有用的话,点个“在看”分享给更多被Excel折磨的朋友吧!
🔮 获取和交流
需要源码和数据的同学,关注+三连,加下面微信,发你!也可以拉你进群交流学习,加群备注:IT小本本学习
为了能随时获取最新动态,大家可以动动小手将公众号添加到“星标⭐”哦,点赞 + 关注,用时不迷路!!!!
关注公众号:IT小本本 👇