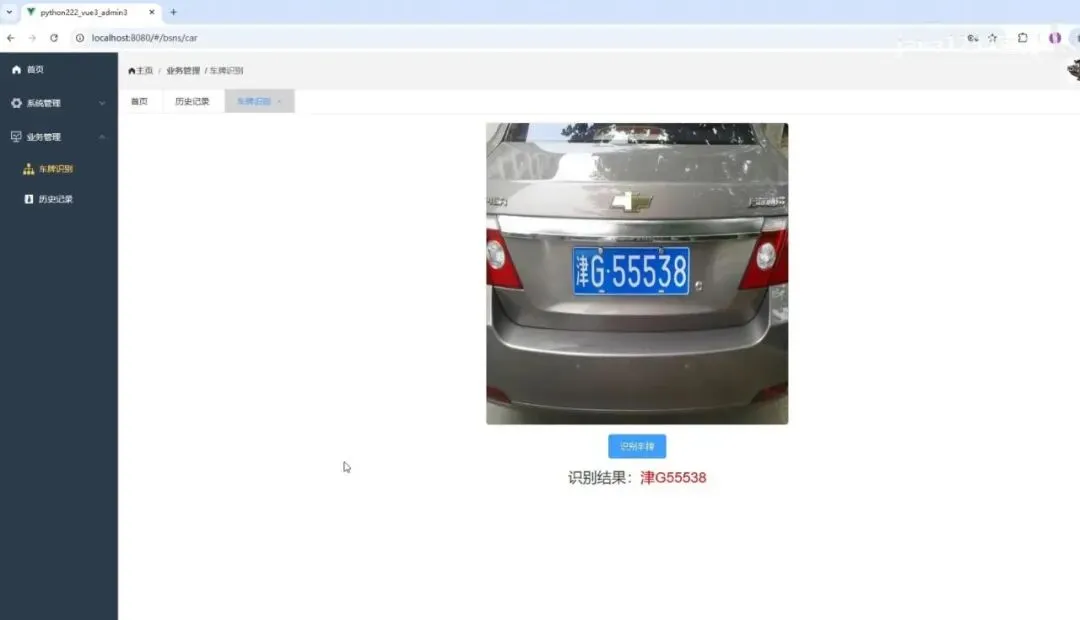
基于Python深度学习的车辆车牌识别系统(PyTorch2卷积神经网络CNN+OpenCV4实现)- 车辆识别字符模型定义与训练
大家好,我是python222_锋哥,最近更新基于Python深度学习的车辆车牌识别系统(PyTorch2卷积神经网络CNN+OpenCV4实现)视频教程系列课程,感谢大家支持。
B站连载更新地址:
https://www.bilibili.com/video/BV1BdUnBLE6N/
本课程采用主流的Python技术栈实现,分两套系统讲解,一套是专门讲PyTorch2卷积神经网络CNN训练模型,识别车牌,当然实现过程中还用到OpenCV实现图像格式转换,裁剪,大小缩放等。另外一套是基于前面Django+Vue通用权限系统基础上(https://www.bilibili.com/video/BV19spseGE9Y/),加了车辆识别业务模型,Mysql8数据库,Django后端,Vue前端,后端集成训练好的模型,实现车牌识别。
1,卷积神经网络定义
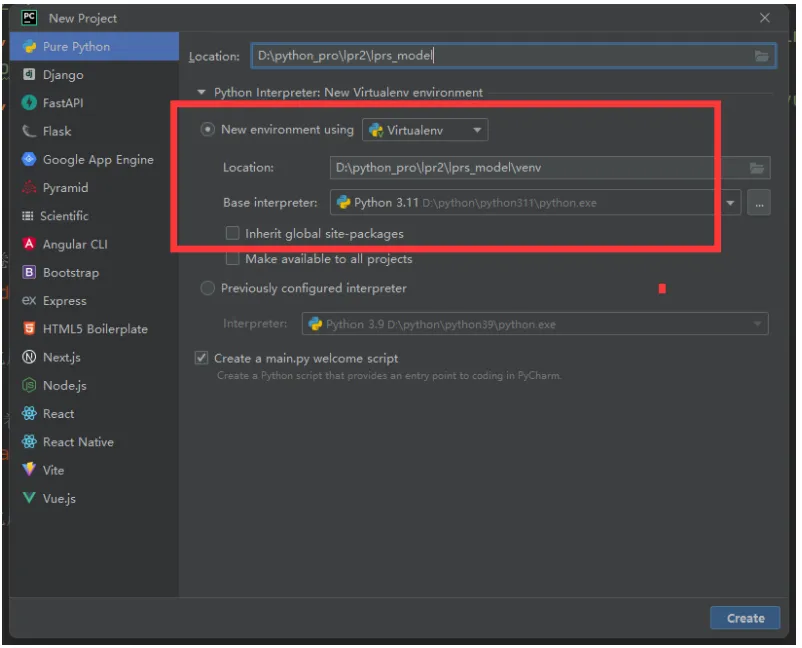
首先新建一个纯净版项目lprs_model,选虚拟环境,python版本3.11
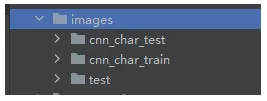
把images目录放到项目里,cnn_char_train是训练集字符图片,cnn_char_test是测试集字符图片。test下面是项目最终测试牌照图片。
字符都是20*20像素的图像。
项目里贴下 requirements.txt 依赖文本:安装pytorch,opencv等核心库。
colorama==0.4.6filelock==3.20.0fsspec==2025.10.0Jinja2==3.1.6MarkupSafe==3.0.3mpmath==1.3.0networkx==3.5numpy==2.2.6opencv-python==4.12.0.88pillow==12.0.0sympy==1.14.0torch==2.9.0torchvision==0.24.0tqdm==4.67.1typing_extensions==4.15.0
运行安装命令:
pip install -r requirements.txt -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
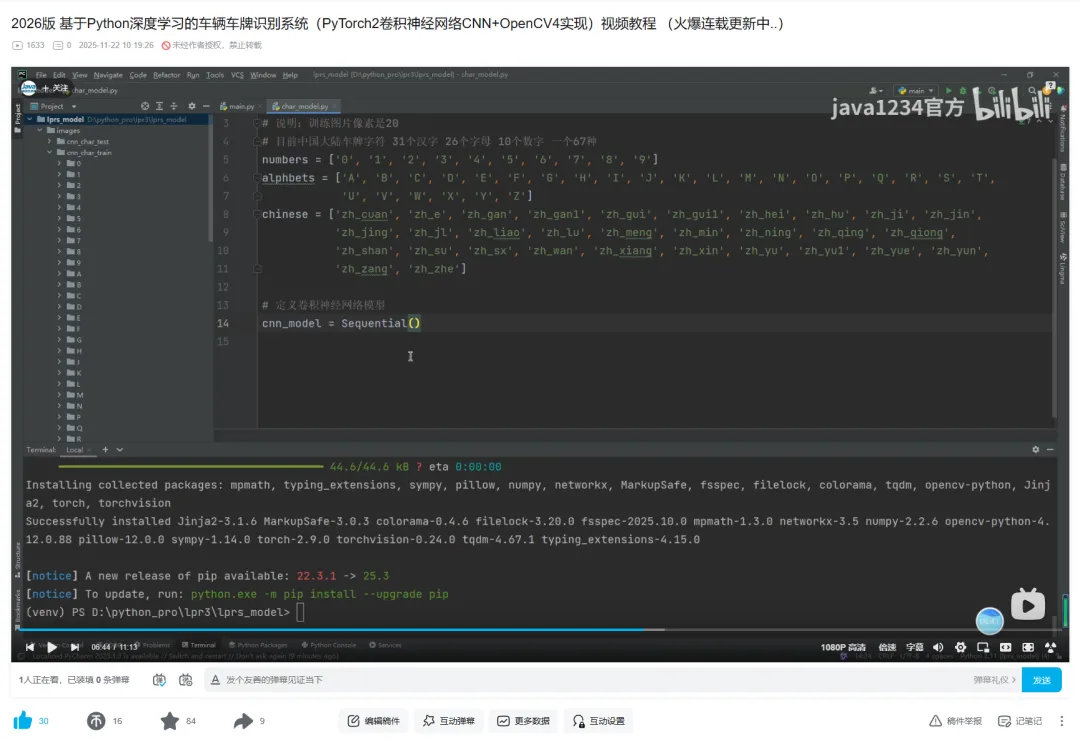
新建char_model.py,定义模型
fromtorchimportnn# 说明:训练图片像素是20# 目前中国大陆车牌字符 31个汉字 26个字母 10个数字 一个67种numbers = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']alphbets = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T','U', 'V', 'W', 'X', 'Y', 'Z']chinese = ['zh_cuan', 'zh_e', 'zh_gan', 'zh_gan1', 'zh_gui', 'zh_gui1', 'zh_hei', 'zh_hu', 'zh_ji', 'zh_jin','zh_jing', 'zh_jl', 'zh_liao', 'zh_lu', 'zh_meng', 'zh_min', 'zh_ning', 'zh_qing', 'zh_qiong','zh_shan', 'zh_su', 'zh_sx', 'zh_wan', 'zh_xiang', 'zh_xin', 'zh_yu', 'zh_yu1', 'zh_yue', 'zh_yun','zh_zang', 'zh_zhe']# 定义卷积神经网络模型cnn_model = nn.Sequential(# 第一层卷积层,输入1通道,输出32通道,卷积核大小3x3,填充1,nn.Conv2d(1, 32, kernel_size=3, padding=1),nn.ReLU(),nn.MaxPool2d(2, 2), # 卷积层后接池化层 池化核大小2x2,步长2# 第二层卷积层,输入32通道,输出64通道,卷积核大小3x3,填充1,nn.Conv2d(32, 64, kernel_size=3, padding=1),nn.ReLU(),nn.MaxPool2d(2, 2), # 卷积层后接池化层 池化核大小2x2,步长2# 展平操作,将数据从二维转为一维nn.Flatten(),# 第一个全连接层,输入64 * 5 * 5通道,输出512通道 像素20*20 经过2次卷积,得到64 * 5 * 5nn.Linear(64*5*5, 512),nn.ReLU(),# 第二全连接层,输入512通道,输出256通道nn.Linear(512, 256),nn.ReLU(),# 第三全连接层,输入256通道,输出67通道nn.Linear(256, 67))
2,自定义字符图片数据集
之前学习Pytorch2的时候,我们用得数据集都是库自带的。但是我们这边的数据集需要自定义。
可以继承data.Dataset,实现 __init__初始化方法,__len__返回长度方法,__getitem__根据索引获取元素方法。因为数据集内容是图片,所以定义X属性,作为训练数据,定义y属性,作为目标数据
# 字符图片数据集classCharPicDataset(data.Dataset):# 根据路径获取所有文件deflist_all_files(self, root):files = []list = os.listdir(root) # 获取根目录下的所有文件名foriinrange(len(list)):element = os.path.join(root, list[i]) # 获取文件路径ifos.path.isfile(element): # 判断是否是文件files.append(element)elifos.path.isdir(element): # 递归判断子目录files.extend(self.list_all_files(element))returnfilesdef__init__(self, data_dir):super().__init__()ifnotos.path.exists(data_dir):raiseException("数据目录不存在")files = self.list_all_files(data_dir)self.X = []self.y = []self.dataset = numbers+alphbets+chineseforfileinfiles:src_img = cv2.imread(file, cv2.IMREAD_GRAYSCALE) # 读取灰度图resize_img = cv2.resize(src_img, (20, 20)) # 改变图片大小self.X.append(resize_img)dir = os.path.dirname(file) # 获取文件的目录 结果类似 ./images/cnn_char_train\Adir_name = os.path.split(dir)[-1] # 获取目录名 结果类似 0 或者 1 或者 A 或者 苏index_y = self.dataset.index(dir_name) # 获取标签索引self.y.append([index_y])self.X = np.array(self.X)self.y = np.array(self.y)def__len__(self):returnlen(self.X)def__getitem__(self, index):""" 这段代码的作用是: - 创建一个 `transforms.ToTensor()` 转换对象,用于将 PIL 图像或 numpy 数组转换为 PyTorch 张量(tensor) - 该转换会自动将像素值从 [0, 255] 范围缩放到 [0, 1] 范围 归一化处理 - 同时会将图像的通道顺序从 HWC (Height-Width-Channel) 调整为 CHW (Channel-Height-Width),这是 PyTorch 所要求的格式 这个转换通常用于深度学习训练中,将图像数据预处理成适合神经网络输入的格式。 """tf = transforms.ToTensor()returntf(self.X[index]), torch.LongTensor(self.y[index])图片我们要处理下,先用opencv转成灰度图,0到255大小。20*20的二维数组。
定义main方法:
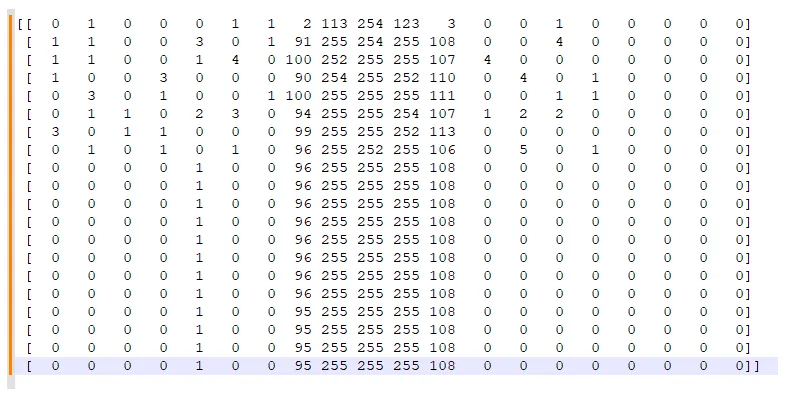
if__name__ == '__main__':train_data_dir = './images/cnn_char_train'traindataset = CharPicDataset(train_data_dir)print(traindataset.X)print(traindataset.y)
运行输出:
D:\python_pro\lpr2\lprs_model\venv\Scripts\python.exe D:\python_pro\lpr2\lprs_model\char_model.py [[[1 0 1 ... 0 0 0] [0 1 1 ... 0 0 0] [0 2 0 ... 0 0 0] ... [0 0 2 ... 0 0 0] [1 0 0 ... 0 0 0] [0 0 4 ... 0 0 0]] [[0 1 0 ... 0 0 0] [0 1 1 ... 0 0 0] [1 0 1 ... 0 0 0] ... [1 0 2 ... 0 0 0] [0 0 0 ... 0 0 0] [0 4 1 ... 0 0 0]] [[0 3 0 ... 0 0 0] [2 0 1 ... 0 0 0] [1 0 0 ... 0 0 0] ... [0 0 2 ... 0 0 0] [1 0 0 ... 0 0 0] [0 5 1 ... 0 0 0]] ... [[0 2 0 ... 0 0 2] [0 0 0 ... 1 1 0] [0 2 2 ... 0 1 0] ... [0 3 0 ... 0 0 0] [1 0 0 ... 0 0 0] [2 0 0 ... 0 0 0]] [[0 1 3 ... 0 0 0] [2 0 0 ... 0 0 0] [0 5 1 ... 0 0 0] ... [1 0 0 ... 0 0 0] [0 1 1 ... 0 0 0] [1 0 0 ... 0 0 0]] [[0 0 2 ... 0 0 0] [2 0 0 ... 0 0 0] [0 2 2 ... 0 0 0] ... [4 0 1 ... 0 0 0] [0 0 1 ... 0 0 0] [0 3 0 ... 0 0 0]]][[ 0] [ 0] [ 0] ... [66] [66] [66]]Process finished with exit code 0
3,训练模型
前面我们定义好了神经网络和自定义好了数据集,然后我们来训练模型:
# 定义损失函数criterion = nn.CrossEntropyLoss() # 交叉熵损失函数optimizer = torch.optim.Adam(cnn_model.parameters(), lr=0.001) # 优化器deftrain(epochs):cnn_model.train() # 训练模式forepochinrange(epochs):loss = 0forimage, targetintrain_loader:target = Variable(target).reshape(1, )# 前向传播output = cnn_model(image)loss = criterion(output, target) # 计算损失# 反向传播和优化optimizer.zero_grad() # 清空梯度loss.backward() # 反向传播optimizer.step() # 更新参数print(f'Epoch [{epoch + 1}/{epochs}], Loss: {loss.item():.4f}')if__name__ == '__main__':train_data_dir = './images/cnn_char_train'train_model_path = 'char.pth'print('开始训练模型...')traindataset = CharPicDataset(train_data_dir)train_loader = data.DataLoader(traindataset, batch_size=1, shuffle=True)epochs = 3train(epochs)torch.save(cnn_model, train_model_path) # 保存模型运行输出:
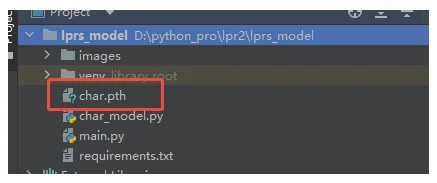
开始训练模型...Epoch [1/3], Loss: 0.0028Epoch [2/3], Loss: 0.0000Epoch [3/3], Loss: 0.0000
生成了char.pth模型文件
4,测试集验证模型
我们可以对之前训练的模型用测试数据进行测试,看看准确率如何。
deftest():cnn_model.eval() # 测试模式correct = 0total = 0withtorch.no_grad(): # 不计算梯度forimage, targetintest_loader:target = Variable(target).reshape(1, ) # 转换为1维向量output = cnn_model(image) # 预测_, predicted = torch.max(output.data, 1) # 获取预测结果total += target.size(0)correct += (predicted == target).sum().item()print('测试集总样本数:', total)print('测试集正确数:', correct)print(f'Accuracy: {100 * correct / total:.2f}%')if__name__ == '__main__':train_data_dir = './images/cnn_char_train'test_data_dir = './images/cnn_char_test'train_model_path = 'char.pth'print('开始训练模型...')traindataset = CharPicDataset(train_data_dir)testdataset = CharPicDataset(test_data_dir)train_loader = data.DataLoader(traindataset, batch_size=1, shuffle=True)test_loader = data.DataLoader(testdataset, batch_size=1, shuffle=True)epochs = 3train(epochs)torch.save(cnn_model, train_model_path) # 保存模型test()print('模型训练完毕')运行输出:
开始训练模型...Epoch [1/3], Loss: 0.0000Epoch [2/3], Loss: 3.4180Epoch [3/3], Loss: 0.0877测试集总样本数: 1784测试集正确数: 1740Accuracy: 97.53%模型训练完毕